2018 ICLR | GRAPH ATTENTION NETWORKS

Paper: https://arxiv.org/pdf/1710.10903
2018 ICLR | GRAPH ATTENTION NETWORKS
摘要
作者提出了图注意网络(GATs),一种基于图结构数据的新型神经网络架构,利用隐藏的自我注意层来解决先前基于图卷积或其近似方法的缺点。通过堆叠层,节点可以参与到它们的邻域特性中,可以(隐式地)为邻域中的不同节点指定不同的权值,而不需要任何代价高昂的矩阵操作(比如倒置),也不需要预先知道图结构。通过这种方式,我们同时解决了基于频谱的图神经网络的几个关键挑战并且是模型直接推导的能力接近了递归推导的能力。论文的模型GAT获得了最优的结果,建立在四个数据集上,分别是:Cora, Citeseer 、Pubmed citation network datasets、PPI(protein-protein interaction,这个数据集在训练过程中无法获得图的结构)。
模型
GAT结构-图注意力层
输入是一组节点特征,记为 h = { h 1 ⃗ , h 2 ⃗ , . . . h N ⃗ } , h ⃗ i ∈ R F h=\{\vec{h_1}, \vec{h_2},...\vec{h_N}\}, \vec{h}_i \in R^F h={h1,h2,...hN},hi∈RF
输出是一组新的节点特征,记为 h ′ = { h 1 ′ ⃗ , h 2 ′ ⃗ , . . . h N ′ ⃗ } , h ⃗ i ′ ∈ R F ′ h'=\{\vec{h_1'}, \vec{h_2'},...\vec{h_N'}\}, \vec{h}_i' \in R^{F'} h′={h1′,h2′,...hN′},hi′∈RF′
其中 h i ⃗ \vec{h_i} hi是新的特征向量,其长度为 F ′ F' F′ 。
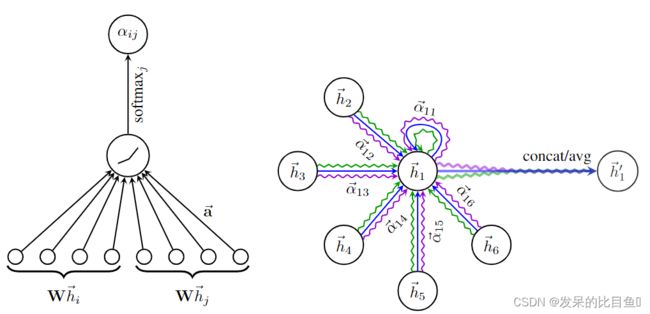
为了获得更高层级的表达能力,需要将输入的特征转换为更高级别的特征,一个可学习的线性变换是必须的,作为端到端的过程,同时需要一个初始化线性转变的矩阵 W , W ∈ R F ′ × F W, W \in R^{F' \times F} W,W∈RF′×F,这个 W W W作用于每一个节点,之后通过运用一个自我注意力(self-attention)作用于节点:一个共享的注意力机制KaTeX parse error: Double superscript at position 6: a:R^F'̲ \times R^F\rig…,结果成为注意力系数,如下表示:

使用了一阶的邻接点(包括节点i本身)来对该系数进行计算,这样做的好处是可以很容易的比较不同节点的关系,正则化所有节点j(邻接点)的注意力系数,使用了softmax方法,公式如下:
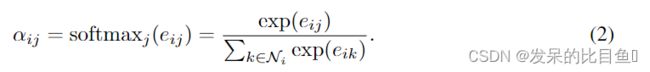
中的 α \alpha α使用了单层前馈神经网络(single-layer feedforward neural network)参数使用了一个向量 α T ⃗ ∈ R 2 F ′ \vec{\alpha^T} \in R^{2F'} αT∈R2F′ ,这样一来注意力系数公式完全展开如下所示:
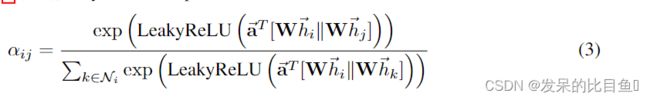
其中, T T T表示转置, ∣ ∣ || ∣∣ 表示连接操作(concatenation operation) 一旦达到(Once obtained),这个正则化的注意力系数就可以备用来计算对应特征的线性组合,作为每个节点的输出特性。(这里还需要使用一个 σ \sigma σ函数作为非线性输出),具体公式如下:

为了稳定自我学习机制,论文使用出了一种多头注意力(multi-head attention)的方法,具体的说(Specificall),就是执行 K K K次公式7,然后将执行的特征连接(concatenated)起来,具体公式如下:
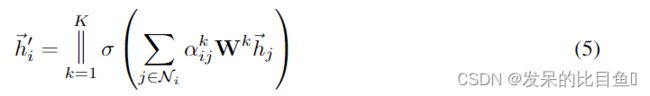
其中 ∣ | ∣|表示连接操作, α i j k \alpha_{ij}^k αijk表示第 k k k次注意力系数, w k w^k wk 表示 k k k头的线性变换矩阵,值得注意的是,在这个公式中,每个节点所输出的特征 h ′ h' h′包含 K F ′ KF' KF′ 个特征(而非 F ′ F' F′ )。特别的,如果我们在网络中使用多头的框架预测,连接操作就不是很适合了,相反的,文中采用了平均值的方法,将最终的非线性(通常是用于分类问题的softmax或logistic sigmoid)应用到多头部图的注意层的聚合过程中,图解说明为图1后部分。具体公式如下:

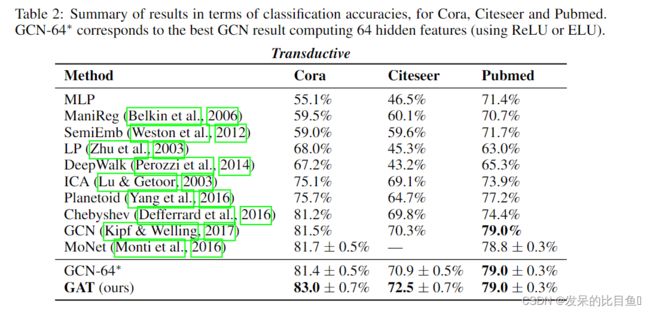
实验


在Cora数据集上预训练GAT模型的第一个隐藏层的计算特征表示的t-SNE图。
参考
https://zhuanlan.zhihu.com/p/296587158