照片视频自动按日期归档python脚本
自从智能手机流行后,一年的照片和视频能攒下不少。数年下来已有20多G了。
你知道的这么多照片靠手动归档不划算。在网上找了些python脚本的例子。做了一些修改,倒是那么回事了。
归档率90%左右,原因是有一些照片是没有时间信息,有一些视频连文件名都没有带日期,这就没法,只能收集打印报告一下。兄弟自己手工处理。
用法:
python3 img_classify.py -d src_dir -o target_dir
不会删除原文件,递归文件夹
适用范围:
小米,华为的相册处理没有什么大问题。
仅只持jpg, mp4文件。 mp4文件是从文件名提取的日期(VID_20xxxx)
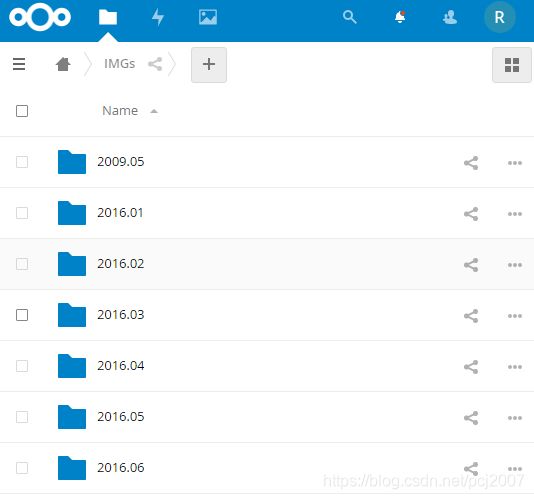
归档为年月
2020.04这样的。
操作示例:
命令
![]()
输出总结报告:完成率,未处理的文件列表

生成的归档文件夹:

配合nextcloud这样的私有云: 再也不担心手机存储不够了,操心就该是网速了。

---脚本---
import shutil
import os
import time
import exifread
import argparse
import re
class ReadFailException(Exception):
pass
def get_file_name_date(fn):
try:
m = re.match("([^_]+)[_]+([^_]+)",fn)
if m is not None:
#print(m.groups())
#print("current:%s" % m[2])
if m[1] == 'VID' and m[2].isdigit()and len(m[2])==8:
date=m[2]
year=date[:4]
month=date[4:6]
ym = "%s.%s" %(year,month)
print("get date via file name %s" % ym)
return ym
if m[1].isdigit() and len(m[1])==8:
print("get a number date? ",m[1])
date=m[1]
year=date[:4]
month=date[4:6]
ym = "%s.%s" %(year,month)
print("get date via file name %s" % ym)
return ym
except Exception as e:
print(e)
pass
return None
def get_file_date(filename):
state = os.stat(filename)
#print("get state", filename)
ym= time.strftime("%Y.%m", time.localtime(state[-2]))
print("get date via file stat %s" % ym)
return ym
def getOrignalDate(filename):
try:
fd = open(filename, 'rb')
except:
print("Cannot open: ", filename)
raise ReadFailException
data = exifread.process_file(fd)
if data:
try:
#print(data)
#t=data.get('Image DateTime').values
#t=data.get('EXIF DateTimeOriginal').values
t = data['EXIF DateTimeOriginal']
return str(t).replace(":", ".")[:7]
except:
print("get exif item failure: ", filename)
#print(data)
pass
return None
else :
t=get_file_name_date(os.path.split(filename)[1])
if t is not None:
return t
return None #get_file_date(filename)
def dump_files(files):
idx=0;
print("---dump unhandle file---")
for file in files:
print(idx,file)
idx+=1
def classifyPictures(path,out):
unhandle_files=[]
non_target_files=[]
total_file_cnt=0
handle_file_cnt=0
for root, dirs, files in os.walk(path, True):
dir = []
for filename in files:
org_filename=filename
total_file_cnt+=1
filename = os.path.join(root, filename)
f, e = os.path.splitext(filename)
if e.lower() not in ('.jpg', '.mp4'):
print("no target file type:", filename)
non_target_files.append(filename)
continue
info = "Filename: " + filename + " "
t=""
try:
t = getOrignalDate(filename)
except Exception:
print("cannot get time", filename)
unhandle_files.append(filename)
continue
if t is None :
print("cannot get time", filename)
unhandle_files.append(filename)
continue
info = info + "Taken time: " + t + " "
pwd = out +'/'+t
dst = pwd + '/'+org_filename
if not os.path.exists(pwd):
os.mkdir(pwd)
print(info, dst)
if os.path.exists(dst) is not True:
shutil.copy2(filename, dst)
handle_file_cnt+=1
print("---summary:----\nhandle %d in %d (left:%d) rate:%f" %(handle_file_cnt,total_file_cnt,total_file_cnt-handle_file_cnt,handle_file_cnt/total_file_cnt))
dump_files(unhandle_files)
dump_files(non_target_files)
#os.remove(filename)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("-d", "--dir", help="specify the image directory you want to process")
parser.add_argument("-o", "--out", help="specify the directory to store file, empty is recommended")
parser.add_argument("-remove", "--remove", help="remove the raw file or false", action="store_true")
args = parser.parse_args()
classifyPictures(args.dir, args.out)