Llama 2:新一代开源LLM,可用于研究和商业用途
一、前言
大型语言模型(LLMs)在各种复杂推理任务中表现出色,包括编程和创意写作等专业领域。LLMs通过直观的聊天界面与人类进行交互,这导致了它们在公众中的快速和广泛采用。
然而,由于训练LLMs所需的计算量较大,只有少数公司能够实现其发展。目前已经有一些公开发布的预训练LLMs,如BLOOM、LLaMa-1和Falcon,它们与闭源预训练模型如GPT-3和Chinchilla相媲美。但是,这些模型并不能完全替代闭源产品LLMs,如ChatGPT、BARD和Claude,因为后者经过大量微调以满足人类偏好,从而提高可用性和安全性。
为了解决这个问题,Meta AI开发并发布了一系列规模达到700亿参数的预训练和微调LLMs,即LLaMa 2和LLaMa 2-Chat。在测试的一系列有用性和安全性基准上,LLaMa 2-Chat模型通常优于现有的开源模型,并与某些闭源模型相当。为了提高安全性,Meta AI采取了一些措施,包括使用安全特定的数据注释和调整,并进行红队测试和迭代评估。
二、介绍
2.1、Llama 2
Meta(前身为Facebook)和 Microsoft 于2023年07月18日正式发布了Llama 2,一种新的开源大型语言模型(LLM),Llama 2 版本引入了一系列预训练和微调的LLM,参数范围从7B到70B(7B、13B、70B)。与Llama 1模型相比,预训练模型有显著改进,它的训练数据增加了 40%,上下文长度也增加了一倍(4k标记),以及使用分组查询注意力来快速推理70B模型。Llama 2 是开源的,可以免费用于研究和商业用途。
Llama 2 预训练模型经过了2万亿个标记的训练,上下文长度是Llama 1的两倍。其微调模型已经接受了超过100万个人类注释的训练。
Meta 在与 Llama 2 一起发表的研究中承认,它“落后于”GPT-4,但它仍然是 OpenAI 的免费竞争对手。
微软是OpenAI 的主要财务支持者,但仍然支持 Llama 2 的推出。LLM 可通过 Microsoft Azure、Amazon Web Services 和 Hugging Face 平台下载。

Llama 2 是在一个庞大的文本和代码数据集上训练的,可以用于多种任务,包括:
-
生成文本、翻译语言和写不同类型的创意内容。
-
以信息性的方式回答问题,即使它们是开放式的、具有挑战性的或奇怪的。
-
总结文本,并从文档中提取信息。
-
分析和理解代码。
-
编写不同类型的代码,包括Python、JavaScript和C++。
Llama 2已经被用来为聊天机器人生成逼真的对话,并以接近人类的准确度翻译语言。
2.2、Llama 2-Chat
在发布的 Llama 2 系列模型中,最厉害的还是微调模型 (Llama 2-Chat),该模型已使用人类反馈强化学习 (RLHF)针对对话应用程序进行了优化。在广泛的有用性和安全性基准中,Llama 2-Chat 模型的表现优于大多数开放模型,并且根据人类评估,其性能可与 ChatGPT 相当。您可以阅读该论文进行详细的了解。

如果你在体验了ChatGPT、Claude 2等一些闭源模型的强大之后,想在公司构建一套私有化的LLM模型,希望有一些替代品可以达到GPT相当能力的模型,不妨试试 Llama 2-Chat 目前来看这是一个不错的选择。如果对中文要求更高,也可以考虑ChatGLM 2 6B模型。

2.3、LLaMa 2和LLaMa 2-Chat之间的区别
-
LLaMa 2和LLaMa 2-Chat都是Meta(前身为Facebook)发布的大型语言模型(LLMs),它们可以用于生成文本、翻译语言、写创意内容、回答问题、总结文本、分析和理解代码等多种任务。
-
LLaMa 2是基于原始的Transformer架构的生成预训练模型,它在一个庞大的文本和代码数据集上训练,规模达到了700亿个参数,在特定方面甚至表现更好,超过了GPT-4和Claude-2。
-
LLaMa 2-Chat是LLaMa 2的聊天变体,它使用了公开可用的训练数据集和超过一百万个人类注释来微调,以提高对话的质量和多样性。它使用了人类反馈强化学习(RLHF)的方法,与OpenAI的ChatGPT使用了相同的方法。
-
LLaMa 2和LLaMa 2-Chat都是开源的,所以研究人员和爱好者可以在其基础上构建自己的应用程序。它们也支持在Azure、AWS和Hugging Face等平台上运行和部署。
-
LLaMa 2-Chat在Meta内部的“有用性”和“毒性”基准测试中表现得比LLaMa 2更好。但它们也倾向于过于谨慎,模型会倾向于拒绝某些请求或回应过多的安全细节。
2.4、与基准测试的比较
从官网发布的基准测试结果来看,这里用红色突出了最好的 Llama-2 模型,用黄色突出了每个测试的最好模型。可以看到 Llama 2 甚至超过了一些复杂的模型,如MPT和Falcon:
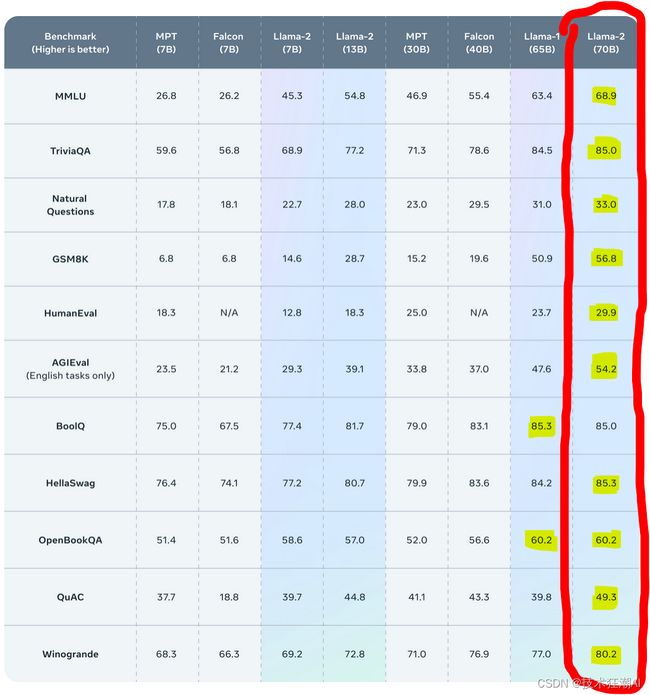
从上面的基准测试结果可以看到,Llama 2 在许多外部基准测试上都优于其他开源语言模型,包括推理、编码、熟练程度和知识测试。

从Llama 2研究论文中可以看到,图1是用人类评价的方式来比较Llama 2-Chat和其他模型的有用性。人类评价者在约4000个提示词上比较了模型的生成,这些提示对话有的是单轮的,有的是多轮的,然后比较了不同模型的回答。评估结果有95%的可能性在1%到2%的范围内。这些结果可能不太准确,因为人类评价会受到一些因素的影响,比如对话的内容、评价的标准、评价者的喜好和比较的难度。
图2是用GPT-4来比较商业许可模型和Llama 2-Chat在有用性和安全性方面的胜率。除了人类评价,使用了一个更强大的模型来做比较,这个模型不受作者自己的影响。绿色区域表示GPT-4认为Llama 2模型更好。为了去掉平局,用胜利次数除以(胜利次数+失败次数)。向GPT-4展示的模型响应的顺序是随机交换的,这样就不会有偏见。
总的来说,Llama 2-Chat在人类评价和与GPT-4的比较中表现出良好的有用性和安全性。然而,需要注意人类评价的限制和不确定性。
2.5、Llama 2 相比 GPT-4 有什么优势
Llama 2和GPT-4都是大型语言模型(LLMs),它们可以用于多种任务,如生成文本、翻译语言、写创意内容、回答问题、总结文本、分析和理解代码等。但是,Llama 2比GPT-4更有优势的原因有以下几点:
-
Llama 2是开源的,所以研究人员和爱好者可以在其基础上构建自己的应用程序。而GPT-4是闭源的,所以只有通过OpenAI的许可才能使用它。
-
Llama 2在写作方面表现得更好,它在一个庞大的文本和代码数据集上训练,规模达到了700亿个参数,超过了GPT-3和Claude-2。它还使用了人类反馈强化学习(RLHF)的方法来微调聊天变体,从而提高了对话的质量和多样性。
-
LLaMa 2和GPT-4在不同的任务上有不同的优势和劣势。根据人类评估和基准测试的结果,LLaMa 2在写作方面表现得更好,而GPT-4在编程方面表现得更好。LLaMa 2在有用性和安全性方面与GPT-4相当,甚至略胜一筹。但是,LLaMa 2在编码能力方面明显落后于GPT-4。
-
Llama 2可以在Azure、AWS和Hugging Face等平台上运行和部署。它还可以在Windows、智能手机和PC上运行,感谢Meta与Microsoft的合作。
总体来看,虽然 Llama 2 在所有基准测试中都比其前身和其他开源模型表现出更好的性能,但它仍然落后于 GPT-4 和 Google 的 PaLM 等闭源模型。然而,在大多数情况下,Llama-2 的性能与 GPT-3.5 相当。
三、如何使用Hugging Face Llama 2
Huggingface是一家领先的自然语言处理(NLP)模型平台。它提供了用户友好的界面和庞大的预训练模型库,使其成为发布Llama 2的理想平台。Meta和Hugging Face合作,第一时间顺利将 Llama 2 集成到 Hugging Face 生态系统中,使开发人员能够轻松访问和实现Llama 2。您可以在 Hub 上找到 12 个开放访问模型(3 个基本模型和 3 个带有原始元检查点的微调模型,以及它们相应的transformers模型)。
3.1、快速在Hugging Face上体验Llama 2
Llama 2模型体验地址:https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI
3.2、如何使用Hugging Face Llama 2?
3.2.1、下载模型
访问 Meta AI 官方网站并下载 Llama 2 模型。下载内容包括:
-
型号代码
-
型号重量
-
自述文件(用户指南)
-
负责任的使用指南
-
执照
-
可接受的使用政策
-
型号卡
3.2.2、安装 Huggingface Transformers
在 Transformers版本 4.31中,已经可以使用 Llama 2 并利用 HF 生态系统中的所有工具,例如:
-
训练和推理脚本和示例
-
安全文件格式 (
safetensors) -
与bitsandbytes(4位量化)和PEFT(参数高效微调)等工具集成
-
使用模型运行生成的实用程序和助手
-
导出模型以进行部署的机制
确保使用最新transformers版本并登录您的 Hugging Face 帐户。
如果尚未安装 Huggingface Transformers 库,请安装。您可以使用 pip 来完成此操作:
pip install transformers
huggingface-cli login3.2.3、加载模型
使用 Transformers 库加载模型。您可以使用以下代码执行此操作:
from transformers import AutoModel, AutoTokenizer
model_name = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)3.2.4、使用模型
现在您可以使用模型来执行各种 NLP 任务。例如,要生成文本,您可以使用以下代码:
input_text = “Hello, how are you?”
inputs = tokenizer.encode(input_text, return_tensors=’pt’)
outputs = model.generate(inputs, max_length=50, num_return_sequences=5, temperature=0.7)
print(“生成的文本:”)
for i, output in enumerate(outputs):
print(f”{i}: {tokenizer.decode(output)}”)3.3、使用PEFT进行微调
为了在简单硬件上高效地训练Llama 2并展示如何在单个NVIDIA T4(16GB - Google Colab)上对Llama 2的7B版本进行微调,我们可以利用Hugging Face生态系统中提供的工具。
一个可行的方法是使用QLoRA和trl中的SFTTrainer。通过使用SFTTrainer(https://huggingface.co/docs/trl/v0.4.7/en/sft_trainer),我们可以指导微调Llama 2。
下面是一个示例命令,演示了如何在timdettmers/openassistant-guanaco上对Llama 2 7B进行微调。脚本中的merge_and_push参数将LoRA权重合并到模型权重中,并将它们保存为safetensor权重。这样,我们可以在训练后使用文本生成推理和推理端点部署我们的微调模型。
首先使用pip安装trl并克隆脚本
pip install trl
git clone https://github.com/lvwerra/trl然后您可以运行该脚本:
python trl/examples/scripts/sft_trainer.py \
--model_name meta-llama/Llama-2-7b-hf \
--dataset_name timdettmers/openassistant-guanaco \
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2四、资源
Llama 2 官网:https://ai.meta.com/
Llama 2 论文: https://arxiv.org/pdf/2307.09288.pdf
Llama 2 Github:https://github.com/facebookresearch/llama
Hugging Face Llama 2:https://huggingface.co/meta-llama
Open LLM 排行榜:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
五、总结
Llama 2 是人工智能领域的重大进步,为其他大型语言模型提供了强大的开源替代方案。它在 Huggingface 上的发布让全世界的开发者都可以轻松使用它,为人工智能应用开辟了新的可能性。