【高斯】高斯模糊算法[2]
前两年我发过一文:Win32下的C++高斯模糊算法实例,里面给出了一个高斯模糊的实现,并写了粗略的简介。
不过当时内容讲得非常简单,而且附带的例子算法是有缺陷的:
- 一是对图片的边角采用“跳过”的方式处理,导致模糊后的图片有黑边;
- 二是算法本身采用的是二维矩阵,效率上不如一维高斯模糊好。
鉴于此,这里重新整理并试图完整的讲述一下高斯模糊。
一、高斯模糊是什么
模糊算法,不论是使用哪种算法,目的都是为了让图片看起来不如原来那么清晰。
清晰的图片,像素间的过渡会较为干脆利落,简而言之,就是像素之间的差距比较大。
而模糊的本质,其实就是使用某种算法把图像像素和像素之间的差距缩小,让中间点和周围点变得差不多;即,让中间点取一个范围内的平均值。
模糊到了极致,比如用于计算模糊的取值区域为整张图片,就会得到一张全图所有像素颜色都差不多的图片:
![【高斯】高斯模糊算法[2]_第1张图片](http://img.e-com-net.com/image/product/c82f322bcddf4b9fabff124a58a5e32b.jpg)
左边是原图,右边是彻底模糊之后的对比图
计算模糊的取值区域就是滤镜区域,那么关键就是,我们采用什么曲线函数来生成平均值了。
假设滤镜区域为正方形,且半径为r,我们可以用如下曲线函数来计算图片上某一个点的值:

这是一个非常简单的直线函数,求得的点值即为算术平均值,图片上某个点的值仅和模糊半径r有关,与坐标的位置无关。
由此我们可以得到用于模糊图像的滤镜算法:
void Average(filter_t& kernel, long radius) { long diamet = Diamet(radius); // (r * 2) + 1 kernel.set(radius, diamet * diamet); // kernel size is d * d double average = 1.0 / (double)kernel.size(); for(long n = 0, i = 0; i < diamet; ++i) for(long j = 0; j < diamet; ++j, ++n) kernel[n] = average; }
然后使用如下算法遍历整张图片,并使用滤镜处理像素:
void Blur2D(bitmap_t& bitmap, filter_t& kernel) { for(long inx = 0, y = 0; y < bitmap.h(); ++y) { for(long x = 0; x < bitmap.w(); ++x, ++inx) { double r = 0.0, g = 0.0, b = 0.0; for (long n = 0, j = -kernel.radius(); j <= kernel.radius(); ++j) { long j_k = Edge(j, y, bitmap.h()); for (long i = -kernel.radius(); i <= kernel.radius(); ++i, ++n) { long i_k = Edge(i, x, bitmap.w()); long inx_k = inx + j_k * bitmap.w() + i_k; r += bitmap[inx_k].r * kernel[n]; g += bitmap[inx_k].g * kernel[n]; b += bitmap[inx_k].b * kernel[n]; } } bitmap[inx].r = Clamp<bitmap_t::channel_t>(r); bitmap[inx].g = Clamp<bitmap_t::channel_t>(g); bitmap[inx].b = Clamp<bitmap_t::channel_t>(b); } } }
上面的算法,第7-19行,把滤镜范围内的像素收集起来,并按照滤镜给出的值将所有像素合并计算为中心点像素的值。
其中,Edge为边缘处理算法:
template <typename T> T Edge(T i, T x, T w) { T i_k = x + i; if (i_k < 0) i_k = -x; else if (i_k >= w) i_k = w - 1 - x; else i_k = i; return i_k; }
它将超出边界的滤镜范围档回边界之内;
Clamp为像素通道的限制算法:
template <typename T1, typename T2> T1 Clamp(T2 n) { return (T1)(n > (T1)~0 ? (T1)~0 : n); }
每个像素通道的最大值不能超过255,若赋予的值超出了通道最大值,则将通道值限制在最大值上。
使用上面的算法,设置滤镜半径为5,处理出来的图片效果如下:
![【高斯】高斯模糊算法[2]_第2张图片](http://img.e-com-net.com/image/product/55705c5408744771bcaa41bc610efa6a.jpg)
左边是原图,右边是对比图
模糊成功了,但效果有些不尽人意,图片的一些边缘细节模糊得并不柔和,感觉像没戴眼镜的近视眼看起来的效果。
从上面的算法里我们可以看出,滤镜中填充的每一个值,可以看做是一个权重。在处理图像的时候,通过它计算出滤镜范围内每个像素的权重值,最后将它们相加,得到的就是滤镜中心点的像素值。
使用上面的模糊算法,在处理图片的时候,对所有的像素点是一视同仁的。但实际上,离中心点越远的点,重要性应该越低才更合理。
也就是说,越靠近滤镜边缘的像素,权重更小才会更符合实际。
高斯分布,即正态分布曲线,形状大概如下图:
![【高斯】高斯模糊算法[2]_第3张图片](http://img.e-com-net.com/image/product/a42a8a6f97bc43548aa0e50e5d96b4cd.jpg)
图片来源: http://zh.wikipedia.org/wiki/File:Standard_deviation_diagram.svg
它就是一个可以计算出符合上面要求的权重分布的函数,对应的二维形式如下:
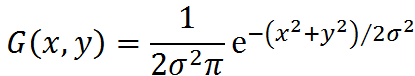
使用高斯分布曲线作为滤镜算法的模糊算法,称之为高斯模糊。
二、高斯模糊算法实现
在前文的阐述里,我们已经有了高斯模糊算法的曲线函数了。通过这个二维的曲线函数,我们可以得到与之对应的程序算法如下:
void Gauss(filter_t& kernel, long radius) { long diamet = Diamet(radius); // (r * 2) + 1 kernel.set(radius, diamet * diamet); // kernel size is d * d double sigma = (double)radius / 3.0; double sigma2 = 2.0 * sigma * sigma; double sigmap = sigma2 * PI; for(long n = 0, i = -kernel.radius(); i <= kernel.radius(); ++i) { long i2 = i * i; for(long j = -kernel.radius(); j <= kernel.radius(); ++j, ++n) kernel[n] = exp(-(double)(i2 + j * j) / sigma2) / sigmap; } }
其中第6行σ的计算,参考正态分布曲线图,可以知道 3σ 距离以外的点,权重已经微不足道了。反推即可知道当模糊半径为r时,取σ为 r/3 是一个比较合适的取值。
设置滤镜半径为5,通过与前文一样的遍历算法,我们可以得到下面的模糊效果:
左边是原图,右边是对比图
这个效果不够明显,我们可以设更大一点的滤镜,比如10,处理出来的效果如下:
![【高斯】高斯模糊算法[2]_第4张图片](http://img.e-com-net.com/image/product/4fb59bf6ca4b4fb1bb48ae19faaba2ec.jpg)
左边是原图,右边是对比图
好了,模糊成功了。效率怎么样呢?
在我的电脑上(i3M330,2.13G),使用 半径10 的滤镜处理 400 × 649 的图片,Debug版本需要大约 8s 左右,Release版本则为916ms。
这个速度就算在Release下也偏慢了。
研究一下我们的算法:
当滤镜半径为r时,算法的时间复杂度是O(x × y × (2r)²)。
能否降低一点呢?
三、高斯模糊算法优化
引用维基百科里的原文:
“除了圆形对称之外,高斯模糊也可以在二维图像上对两个独立的一维空间分别进行计算,这叫作线性可分。这也就是说,使用二维矩阵变换得到的效果也可以通过在水平方向进行一维高斯矩阵变换加上竖直方向的一维高斯矩阵变换得到。”
这个特征让我们可以使用一维的高斯函数,在横纵两个方向上分别处理一次图像,得到和二维高斯函数一样的效果。
使用一维高斯函数,算法的时间复杂度就变为O(2 × x × y × 2r),两相比较,算法效率高出r倍。
一维形式的高斯函数如下:

从而得到新的程序算法如下:
void Gauss(filter_t& kernel, long radius) { kernel.set(radius, Diamet(radius)); static const double SQRT2PI = sqrt(2.0 * PI); double sigma = (double)radius / 3.0; double sigma2 = 2.0 * sigma * sigma; double sigmap = sigma * SQRT2PI; for(long n = 0, i = -kernel.radius(); i <= kernel.radius(); ++i, ++n) kernel[n] = exp(-(double)(i * i) / sigma2) / sigmap; }
同样,算法的第7-9行,先行计算出坐标无关的值,然后在第12行中使用高斯函数计算出权重。
为了配合一维滤镜,遍历算法需改为如下形式:
void Blur1D(bitmap_t& bitmap, filter_t& kernel) { Normalization(kernel); buffer_t buff(bitmap); for(long inx = 0, y = 0; y < bitmap.h(); ++y) { for(long x = 0; x < bitmap.w(); ++x, ++inx) { for(long n = 0, i = -kernel.radius(); i <= kernel.radius(); ++i, ++n) { long i_k = Edge(i, x, bitmap.w()); long inx_k = inx + i_k; buff[inx].r += bitmap[inx_k].r * kernel[n]; buff[inx].g += bitmap[inx_k].g * kernel[n]; buff[inx].b += bitmap[inx_k].b * kernel[n]; } } } for(long inx = 0, x = 0; x < bitmap.w(); ++x) { for(long y = 0; y < bitmap.h(); ++y) { inx = y * bitmap.w() + x; double r = 0.0, g = 0.0, b = 0.0; for(long n = 0, i = -kernel.radius(); i <= kernel.radius(); ++i, ++n) { long i_k = Edge(i, y, bitmap.h()); long inx_k = inx + i_k * bitmap.w(); r += buff[inx_k].r * kernel[n]; g += buff[inx_k].g * kernel[n]; b += buff[inx_k].b * kernel[n]; } bitmap[inx].r = Clamp<bitmap_t::channel_t>(r); bitmap[inx].g = Clamp<bitmap_t::channel_t>(g); bitmap[inx].b = Clamp<bitmap_t::channel_t>(b); } } }
第3行,用于对滤镜做“归一化”处理;
第5行,对待处理的图片生成一块缓存区,用于保存处理的中间结果;
第15-17行,将第一次横方向的处理结果保存在缓存区中;
第32-34行,将第二次纵方向的处理结果保存在临时变量中;
最后,第36-38行,将最终的处理结果赋值给图片像素的每个通道。
关于第3行的归一化处理,算法如下:
void Normalization(filter_t& kernel) { double sum = 0.0; for(int n = 0; n < kernel.size(); ++n) sum += kernel[n]; if (Equal(sum, 1.0)) return; for(int n = 0; n < kernel.size(); ++n) kernel[n] = kernel[n] / sum; }
第5行及后面的图像处理算法采用了缓存区。
这是因为若不使用缓存区缓存中间的图像结果,那么第一遍处理完的图像就只能保存在bitmap里了。而bitmap的像素,每通道都是0-255的整数,如果把中间结果保存在bitmap的内存空间里,第二遍遍历的处理精度就会大大降低,最后处理出来的效果质量也将大打折扣。
同样使用半径为10的滤镜,处理后的图像效果如下:
![【高斯】高斯模糊算法[2]_第5张图片](http://img.e-com-net.com/image/product/ce31e26904854310bb3fb2127edd71a1.jpg)
从左往右,第一张为原图,第二张为一维高斯模糊的效果,第三张为二维高斯模糊的效果
虽然理论上一维和二维的处理应该是没有差别的,但是由于计算精度的原因,实际处理后的效果还是有差别的。
但是差别很细微,就上图而言,一维处理之后的图片,模糊效果更加平滑一些。
使用一维算法,处理同样图片的时间,Debug下只需要846ms,Release下仅仅78ms,差不多都是二维算法的10倍左右。效率的差距和前面计算的时间复杂度差距一致。
四、其它模糊算法
从上面的文字里,我们已经知道了高斯模糊算法其实就是利用高斯函数或者说曲线,生成模糊滤镜,然后对图像像素做处理的算法。
那么我们可以考虑使用其它曲线来作为我们的模糊曲线么?
当然是可以的。
文章的最开始就使用了最简单的算术平均值曲线作为模糊曲线,只是实际的效果较为一般。
我们可以再尝试其他的曲线函数,比如直线函数:
求绝对值是为了让函数曲线保持“中间高两边低”
使用其他函数得到的滤镜算法和处理的图片效果本文就不再一一赘述了。感兴趣的朋友可以下载文后所附的代码。
附件里的模糊算法实现在filter.h中,VC和gcc编译器下均编译通过。测试平台基于win32下的Qt 5.0.1,编译器为MinGW 4.7。
原文地址:http://blog.csdn.net/markl22222/article/details/10313565