【论文】 虚拟机 和 Linux容器 的 最新性能比较
虚拟机 和 Linux容器 的 最新性能比较
An Updated Performance Comparison of Virtual Machines and Linux Containers
借助DeepL辅助翻译 + 校准
摘要
云计算广泛使用虚拟机(VM),因为它们允许工作负载相互隔离,并在一定程度上控制资源使用。然而,虚拟化所涉及的额外抽象层次会降低工作负载的性能,而这种性能会以更低的性价比转嫁给客户。基于容器的虚拟化的最新进展简化了应用程序的部署,同时继续允许控制分配给不同应用程序的资源。
在本文中,我们探讨了传统虚拟机部署的性能,并将其与 Linux 容器的使用进行了对比。我们使用了一套对 CPU、内存、存储和网络资源有压力的工作负载。**我们使用 KVM 作为代表性管理程序,使用 Docker 作为容器管理器。**我们的结果表明,几乎在所有情况下,容器的性能都与虚拟机相当或更好。虚拟机和容器都需要调整才能支持 I/O 密集型应用。我们还讨论了我们的性能结果对未来云架构的影响。
Introduction
虚拟机在云计算中被广泛使用。特别是,**基础设施即服务(IaaS)的最先进技术在很大程度上就是虚拟机的代名词。亚马逊 EC2 等云平台向客户提供虚拟机,并在虚拟机中运行数据库等服务。许多平台即服务(PaaS)和软件即服务(SaaS)**提供商都建立在 IaaS 的基础上,其所有工作负载都在虚拟机内运行。由于目前几乎所有云工作负载都在虚拟机中运行,因此虚拟机性能是整体云性能的重要组成部分。**一旦管理程序增加了开销,任何上层都无法将其移除。**这些开销就会对云工作负载的性能造成普遍影响。有许多研究显示了虚拟机执行与本地执行的对比情况,这些研究是普遍提高虚拟机技术质量的推动因素。
基于容器的虚拟化为云中的虚拟机提供了一种有趣的替代方案[46]。虚拟专用服务器提供商(可视为云计算的前身)使用容器已有十多年的历史,但其中许多提供商转而使用虚拟机,以提供更稳定的性能。虽然命名空间等容器的基本概念已广为人知[34],但容器技术却一直处于停滞状态,直到对快速部署的渴望促使 PaaS 提供商采用容器技术并将其标准化,这才导致使用容器提供隔离和资源控制的复兴。Linux 因其零价格、庞大的生态系统、良好的硬件支持、出色的性能和可靠性而成为云计算的首选操作系统。在 Linux 中实现容器所需的内核命名空间功能自首次讨论以来,直到最近几年才逐渐成熟[17]。在过去两年中,Docker [45] 已经成为一个 容器的标准运行时、映像格式和构建系统。容器的标准运行时、映像格式和构建系统。
本文探讨了目前实现资源控制的两种不同方式,即容器和虚拟机,并比较了这两种环境中一组工作负载的性能与在硬件上原生执行工作负载的性能。除了一组强调不同方面(如计算、内存带宽、内存延迟、网络带宽和 I/O 带宽)的基准测试外,我们还探讨了两个实际应用(即 Redis 和 MySQL)在不同环境下的性能。和 MySQL 在不同环境下的性能。
我们的目标是隔离并了解虚拟机(特别是 KVM)和容器(特别是 Docker)相对于非虚拟化 Linux 所带来的开销。鉴于 Xen、VMware ESX 和 Microsoft Hyper-V 等其他虚拟机管理程序使用相同的硬件加速功能,我们希望它们能提供与 KVM 类似的性能。同样,如果其他容器工具使用相同的机制,其性能也应与 Docker 相当。我们不评估容器在虚拟机内运行或虚拟机在容器内运行的情况,因为我们认为这种双重虚拟化是多余的(至少从性能角度看是多余的)。事实上,Linux 既能托管虚拟机,也能托管容器,这为这两种技术之间进行 apples-to-apples 比较(同类事务物的比较)提供了机会,而且比以往的许多比较少了混淆变量。变量。
我们做出了以下贡献:
- 我们使用最新的硬件和软件,通过与云计算相关的一系列有趣的基准和工作负载,对本地、容器和虚拟机环境进行了最新的比较。
- 我们确定了当前虚拟化选项对高性能计算HPC和服务器工作负载的主要性能影响。
- 我们阐述了一些影响虚拟化性能的非显而易见的实际问题。
- 我们表明,即使在整个服务器的规模上,容器也是可行的,而且对性能的影响极小。
本文接下来的内容安排如下。第二节介绍了 Docker 和 KVM,为理解本文的其余部分提供了必要的背景。第三节介绍并评估了这三种环境下的不同工作负载。我们在第四节回顾了相关工作,最后,第五节对本文进行了总结。
Background
A. 云虚拟化的动机和要求
Unix 传统上并不严格执行最小权限原则,即 “系统中的每个程序和每个用户都应使用完成工作所需的最小权限集进行操作”,以及最小共用机制原则,即 “每个共用机制…都代表着用户之间的潜在信息路径,因此在设计时必须非常谨慎,以确保不会无意中损害安全性”。[42]. Unix 中的大多数对象,包括文件系统、进程和网络堆栈,对所有用户都是全局可见的。
Unix 共享全局文件系统造成的一个问题是缺乏配置隔离。多个应用程序对全系统配置设置的要求可能相互冲突。共享库的依赖性尤其容易造成问题,因为现代应用程序使用许多库,而且不同的应用程序往往需要同一库的不同版本。在一个操作系统上安装多个应用程序时,系统管理成本可能会超过软件本身的成本。
普通服务器操作系统的这些弱点导致管理员和开发人员通过将每个应用程序安装在单独的操作系统副本上(专用服务器或虚拟机)来简化部署。与共享服务器相比,应用程序之间共享任何代码、数据或配置都需要明确的操作,这种隔离方式颠覆了共享服务器的现状。
无论环境如何,客户都希望获得他们所支付的性能。与基础设施和工作负载由同一家公司拥有的企业整合方案不同,在 IaaS 和 PaaS 中,提供商和客户之间存在着一种 "不相干 "的关系。这就很难解决性能异常问题,因此 *aaS 提供商通常会提供固定的容量单位(CPU 内核和内存),且不会超额订购。虚拟化系统需要执行这种资源隔离,才能适合云基础设施的使用。
B. KVM
内核虚拟机(KVM)[25] 是 Linux 的一项功能,它允许 Linux 充当 Type 1 管理程序[36],在 Linux 进程内运行未经修改的客户操作系统(OS)。KVM 使用最新处理器的硬件虚拟化功能来降低复杂性和开销;例如,英特尔 VT-x 硬件消除了对复杂的环形压缩方案的需求,而这种方案是 Xen [9] 和 VMware [8] 等早期管理程序首创的。KVM 通过 QEMU [16] 支持仿真 I/O 设备,通过 virtio [40] 支持准虚拟 I/O 设备。硬件加速和准虚拟 I/O 的结合旨在将虚拟化开销降到非常低的水平[31]。KVM 支持实时迁移,允许物理服务器甚至整个数据中心在不中断客户操作系统的情况下进行维护[14]。通过 libvirt 等管理工具,KVM 也很容易使用 [18]。
由于虚拟机有固定数量的虚拟 CPU(vCPU)和固定数量的 RAM,因此其资源消耗自然是有限制的。KVM 可以在运行时通过 "热插拔 "和 "膨胀 "虚拟 CPU 和虚拟 RAM 来调整虚拟机的大小,不过这需要客户操作系统的支持,在云计算中很少使用。
由于每个虚拟机都是一个进程,所有普通的 Linux 资源管理设施,如 scheduling 和 cgroups(稍后将详细介绍),都适用于虚拟机。这简化了管理程序的实施和管理,但却使客户操作系统内部的资源管理变得复杂。操作系统通常假定 CPU 始终在运行,内存的访问时间相对固定,但在 KVM 下,虚拟 CPU 可以在没有通知的情况下被调度,虚拟内存可以被换出,从而导致难以调试的性能异常。虚拟机也有两层分配和调度:一层在管理程序中,一层在客户操作系统中。许多云提供商通过避免过度分配资源、将每个 vCPU 固定在物理 CPU 上以及将所有虚拟 RAM 锁定在真实 RAM 上,来消除这些问题。(遗憾的是,OpenStack 尚未启用 vCPU 固定,导致性能与专有公共云相比参差不齐)。这基本上消除了管理程序中的调度。这种固定的资源分配也简化了计费。
虚拟机因其狭小的接口而自然地提供了一定程度的隔离性和安全性;虚拟机与外界通信的唯一方式是通过数量有限的超级调用或仿真设备,这两种方式都由管理程序控制。这并不是万能的,因为已经发现了一些管理程序权限升级漏洞,可以让客户操作系统 "冲出 "虚拟机 “沙盒”。
虽然虚拟机在隔离方面表现出色,但它们在客户机之间或客户机与管理程序之间共享数据时会增加开销。通常,这种共享需要相当昂贵的 marshaling 和 hypercalls。在云中,虚拟机通常通过由映像文件支持的仿真块设备访问存储;创建、更新和部署此类磁盘映像可能非常耗时,而且内容大多重复的磁盘映像集合可能会浪费存储空间。
C. Linux 容器
基于容器的虚拟化不是在虚拟硬件上运行完整的操作系统,而是修改现有的操作系统以提供额外的隔离。一般来说,这涉及为每个进程添加一个容器 ID,并为每个系统调用添加新的访问控制检查。因此,容器可被视为用户和组权限系统之外的另一种访问控制级别。在实践中,Linux 使用了一种更复杂的实现方式,具体如下。
Linux 容器是建立在内核命名空间功能基础上的一个概念,最初的动机是处理高性能计算集群时遇到的困难[17]。通过 clone() 系统调用访问该功能,可以为以前的全局命名空间创建独立实例。Linux 实现了文件系统、PID、网络、用户、IPC 和主机名命名空间。例如,每个文件系统命名空间都有自己的根目录和挂载表,类似于 chroot(),但功能更强大。
命名空间有多种不同的使用方法,但最常见的方法是创建一个孤立的容器,该容器对容器外的对象没有可见性或访问权。在容器内运行的进程看起来就像在一个正常的 Linux 系统上运行,尽管它们与位于其他命名空间的进程共享底层内核。容器可以分层嵌套 [19],但对这种功能的探索还不多。
与运行完整操作系统的虚拟机不同,容器可以只包含一个进程。像完整操作系统一样运行 init、inetd、sshd、syslogd、cron 等进程的容器称为系统容器,而只运行应用程序的容器称为应用程序容器。这两种类型在不同情况下都很有用。由于应用容器不会在冗余管理进程上浪费 RAM,因此它消耗的 RAM 通常比同等的系统容器或虚拟机要少。应用容器通常没有独立的 IP 地址,这在地址稀缺的环境中是一个优势。
如果不希望完全隔离,在容器之间共享某些资源也很容易。例如,绑定挂载允许一个目录出现在多个容器中,而且可能位于不同的位置。Linux VFS 层可以有效地实现这一点。容器之间或容器与主机(实际上只是父命名空间)之间的通信与普通 Linux IPC 一样高效。
Linux 控制组(cgroups)子系统用于对进程进行分组,并管理它们的总体资源消耗。它通常用于限制容器的内存和 CPU 消耗。只需更改相应 cgroup 的限制,就能调整容器的大小。Cgroups 还提供了终止容器内所有进程的可靠方法。由于容器化 Linux 系统只有一个内核,而且内核对容器具有完全可见性,因此只有一个资源分配和调度级别。
容器资源管理尚未解决的一个问题是,在容器内运行的进程并不知道它们的资源限制[27]。例如,一个进程可以看到系统中的所有 CPU,即使它只能在其中的一个子集上运行;内存也是如此。如果应用程序试图根据可用的系统资源总量分配资源来自动调整自己,那么当它在资源受限的容器中运行时,就可能会过度分配资源。随着容器的成熟,这一限制可能会得到解决。
与管理 Unix 权限相比,确保容器的安全往往更简单,因为容器无法访问它看不到的东西,从而大大降低了意外过度扩展权限的可能性。使用用户命名空间时,容器内的根用户不会被视为容器外的根用户,从而增加了额外的安全性。容器中的主要安全漏洞类型是系统调用,这些调用无法感知命名空间,因此会在容器之间造成意外泄漏。由于 Linux 系统调用 API 集非常庞大,因此对每个系统调用的名称空间相关漏洞进行审计的工作仍在进行中。使用 seccomp [5],将系统调用列入白名单,可以减少此类漏洞(代价是可能造成应用程序不兼容)。
Linux 容器有多种管理工具,包括 LXC [48]、systemd-nspawn [35]、lmctfy [49]、Warden [2] 和 Docker [45]。(有些人将 Linux 容器称为 “LXC”,但这会造成混淆,因为 LXC 只是众多管理容器的工具之一)。**由于其功能集和易用性,Docker 已迅速成为容器的标准管理工具和映像格式。**Docker 的一个关键功能是分层文件系统镜像,通常由 AUFS(Another UnionFS)[12]提供支持,这是大多数其他容器工具所不具备的。AUFS 提供了分层的文件系统堆栈,并允许在容器之间重复使用这些层,从而减少了空间使用并简化了文件系统管理。单个操作系统映像可用作多个容器的基础,同时允许每个容器拥有自己的覆盖修改文件(如应用程序二进制文件和配置文件)。在许多情况下,Docker 容器镜像所需的磁盘空间和 I/O 都比同等的虚拟机磁盘镜像少。这就加快了云计算的部署速度,因为在虚拟机或容器启动之前,通常需要通过网络将镜像复制到本地磁盘。
尽管本文关注的是稳态性能、 其他测量[39]显示,容器的启动速度比虚拟机快得多(不到 1 秒,而我们的硬件上需要 11 秒),因为容器与虚拟机不同,不需要启动操作系统的另一个副本。理论上,CRIU [1] 可以执行容器的实时迁移,但杀死容器并启动新容器可能更快。
Evaluation
性能涉及多个方面。我们重点关注与本地非虚拟化执行相比的开销问题,因为它会减少可用于生产性工作的资源。因此,我们研究了一种或多种硬件资源得到充分利用的情况,并测量了吞吐量和延迟等工作负载指标,以确定虚拟化的开销。
我们的所有测试都是在 IBM System x3650 M4 服务器上进行的,该服务器配备两颗 2.4-3.0 GHz 英特尔 Sandy Bridge-EP 至强 E5-2665 处理器,共 16 个内核(加上超线程技术)和 256 GB 内存。两个处理器/插槽通过 QPI 链接连接,使其成为一个非统一内存访问 (NUMA) 系统。这是一种主流服务器配置,与流行的云提供商使用的配置非常相似。我们使用的是 Ubuntu 13.10 (Saucy) 64 位,内核为 Linux 3.11.0、Docker 1.0、QEMU 1.5.0 和 libvirt 1.1.1。为保持一致性,所有 Docker 容器都使用 Ubuntu 13.10 基本镜像,所有虚拟机都使用 Ubuntu 13.10 云镜像。
在测试中,使用性能 cpufreq 管理器禁用了电源管理。Docker 容器不受 cgroups 的限制,因此可以使用测试系统的全部资源。同样,虚拟机也配置了 32 个 vCPU 和足够的内存来容纳基准的工作集。在一些测试中,我们探讨了 KVM(类似于 OpenStack 的默认配置)和高度调整的 KVM 配置(类似于 EC2 等公共云)之间的差异。我们使用微基准测试来单独测量 CPU、内存、网络和存储开销。我们还测量了两个真实的服务器应用程序: Redis 和 MySQL。
A. CPU-PXZ
压缩是云工作负载中经常使用的组件。PXZ [11] 是一种使用 LZMA 算法的并行无损数据压缩工具。我们使用 PXZ 4.999.9beta(build 20130528)来压缩 enwik9 [29],这是一个 1 GB 的维基百科转储,经常用于压缩基准测试。为了专注于压缩而非 I/O,我们使用 32 个线程,将输入文件缓存在 RAM 中,并将输出导入 /dev/null。我们使用 2 级压缩。
表 I 显示了 PXZ 在不同配置下的吞吐量。不出所料,本机和 Docker 的性能非常接近,而 KVM 则要慢 22%。我们注意到,通过 vCPU pinning 和暴露缓存拓扑来调整 KVM 对性能的影响不大。虽然需要进一步实验才能确定 KVM 开销的来源,但我们怀疑是嵌套分页的额外 TLB 压力造成的。PXZ 可能会从使用大分页中受益。

B. HPC-Linpack
Linpack 采用一种带部分透视的 LU 因式分解算法求解密集线性方程组[21]。绝大多数计算操作都是将一个标量与一个向量进行双精度浮点乘法运算,并将结果加到另一个向量上。基准通常基于线性代数库,该库针对当前特定的机器架构进行了大量优化。我们使用基于英特尔数学内核库(MKL)的优化 Linpack 二进制库(版本 11.1.2.005)[3]。英特尔 MKL 具有高度自适应能力,可根据可用浮点资源(如可用的多媒体操作形式)以及系统的缓存拓扑结构进行自我优化。默认情况下,KVM 不会向虚拟机公开拓扑信息,因此客户操作系统会认为自己运行在一个统一的 32 插槽系统上,每个插槽一个内核。
表 I 显示了 Linpack 在 Linux、Docker 和 KVM 上的性能。Linux 和 Docker 上的性能几乎完全相同,这并不奇怪,因为在执行过程中操作系统的参与很少。不过,未经调整的 KVM 性能明显较差,这表明了从可利用硬件细节的工作负载中抽象/隐藏硬件细节的代价。**由于无法检测系统的确切性质,执行过程中采用了更通用的算法,从而导致性能下降。**对 KVM 进行调整,将 vCPU 固定到相应的 CPU 上,并公开底层缓存拓扑结构,可将性能提高到几乎与本机相当的水平。
我们预计,除非系统拓扑结构被忠实地移植到虚拟化环境中,否则这种行为将成为其他类似调整的自适应执行的常态。
C. Memory bandwidth-Stream
STREAM 基准是一个简单的合成基准程序,用于测量对向量进行简单操作时的可持续内存带宽[21]。性能主要取决于系统的内存带宽,工作集的设计明显大于缓存。性能的主要决定因素是主内存带宽,其次是处理 TLB 未命中的成本(我们使用大页面进一步降低了这一成本)。内存访问模式是有规律的,硬件预取器通常会锁定访问模式,并在需要之前预取数据。因此,性能取决于内存带宽而非延迟。该基准有四个组成部分: COPY、SCALE、ADD 和 TRIAD,如表 II 所示。

表 I 显示了 Stream 在三种执行环境下的性能。Stream 的所有四个组件都执行常规内存访问,一旦页表条目安装到 TLB 中,就会先访问页内的所有数据,然后再访问下一页。硬件 TLB 预取也能很好地处理这种工作负载。因此,Linux、Docker 和 KVM 上的性能几乎完全相同,三种执行环境的数据中位数仅相差 1.4%。
D. Random Memory Access-RandomAccess
Stream 基准以常规方式对内存子系统施加压力,允许硬件预取器在计算中使用数据前从内存中引入数据。与此相反,RandomAccess 基准[21]是专门为强调随机存储器性能而设计的。该基准将一大段内存初始化为工作集,其数量级大于高速缓存或 TLB 的覆盖范围。读取、修改(通过简单的 XOR 操作)和写回这段内存中的随机 8 字节字。随机位置是通过线性反馈移位寄存器生成的,无需进行任何内存操作。因此,连续操作之间没有依赖性,允许多个独立操作通过系统进行。RandomAccess 是具有大型工作集和最小计算量的工作负载的典型行为,例如具有内存散列表和内存数据库的工作负载。
与 Stream 一样,RandomAccess 使用大页面来减少 TLB 错失开销。由于 RandomAccess 采用随机内存访问模式,且工作集比 TLB 所及范围更大,因此大大减少了处理 TLB 未命中的硬件页表步行器的开销。如表 I 所示,在我们的双插槽系统中,虚拟化和非虚拟化环境的开销相同。
E. Network bandwidth-nuttcp
我们使用 nuttcp 工具[7]来测量被测系统与使用两个 Mellanox ConnectX-2 EN 网卡之间的直接 10 Gbps 以太网链接连接的相同机器之间的网络带宽。我们对 10 Gbps 网络进行了标准的网络调整,如启用 TCP 窗口缩放和增加套接字缓冲区大小。如图 1 所示,Docker 将主机上的所有容器连接到网桥,并通过 NAT 将网桥连接到网络。在 KVM 配置中,我们使用 virtio 和 vhost 来尽量减少虚拟化开销。

我们使用 nuttcp 测量了单个 TCP 连接上单向大容量数据传输的良好吞吐量,该连接具有标准的 1500 字节 MTU。在客户端到服务器的情况下,被测系统(SUT)充当发送器,而在服务器到客户端的情况下,SUT 充当接收器;由于 TCP 的发送和接收代码路径不同,因此有必要同时测量两个方向。所有三种配置在发送和接收方向的速度都达到了 9.3 Gbps,由于数据包头的原因,非常接近 9.41 Gbps 的理论极限。由于分段卸载,即使考虑到不同形式的虚拟化所产生的额外层,批量数据传输也非常高效。该测试的瓶颈在于网卡,其他资源大多处于闲置状态。在这种 I/O 受限的情况下,我们通过测量发送和接收数据所需的 CPU 周期来确定开销。图 2 显示了使用 perf stat -a 测量的该测试的全系统 CPU 利用率。Docker 对桥接和 NAT 的使用明显增加了传输路径长度;vhost-net 的传输效率相当高,但接收端的开销很大。不使用 NAT 的容器性能与本地 Linux 完全相同。在实际的网络密集型工作负载中,我们预计这种 CPU 开销会降低整体性能。
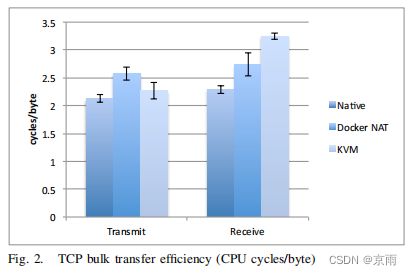
一直以来,Xen 和 KVM 都很难提供线速网络,因为它们的 I/O 路径迂回曲折,每个数据包都要经过用户空间。因此,人们对轮询驱动程序或管理程序旁路等复杂的网络加速技术进行了大量研究。我们的研究结果表明,允许虚拟机直接与主机内核通信的 vhost 可以直接解决网络吞吐量问题。如果有更多的网卡,我们预计这台服务器无需使用任何特殊技术,就能驱动超过 40 Gbps 的网络流量。
F. Network latency-netperf
我们使用 netperf 请求-响应基准来测量往返网络延迟,其配置与上一节中的 nuttcp 测试类似。在这种情况下,被测系统运行 netperf 服务器(netserver),另一台机器运行 netperf 客户端。客户端发送一个 100 字节的请求,服务器发送一个 200 字节的响应,客户端等待响应后再发送另一个请求。因此,每次只有一个事务在运行。
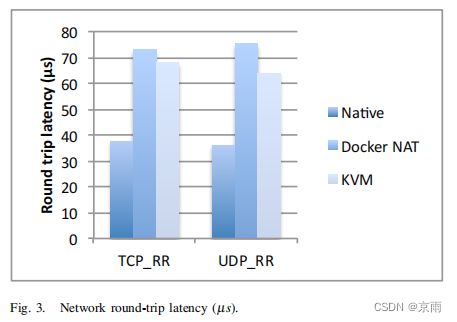
图 3 显示了该基准的 TCP 和 UDP 变体的实测事务延迟。Docker 中使用的 NAT 使该测试中的延迟延长了一倍。与非虚拟化网络协议栈相比,KVM 为每个事务增加了 30µs 的开销,增加了 80%。TCP 和 UDP 的延迟非常相似,因为在这两种情况下,每个方向的事务都由一个数据包组成。与吞吐量测试不同,虚拟化开销在这种情况下无法摊销。
G. Block I/O-fio
云中通常使用类似于 SAN 的块存储来提供高性能和高一致性。为了测试虚拟化块存储的开销,我们将 20 TB 的 IBM FlashSystem 840 闪存固态硬盘连接到测试服务器,使用两个 8 Gbps 光纤通道链接到基于 QLogic ISP2532 的双端口 HBA,并使用 dm_multipath 结合两个链接。我们使用默认设置在其上创建了一个 ext4 文件系统。在本机情况下,文件系统被正常挂载,而在 Docker 测试中,文件系统被使用 -v 选项映射到容器中(避免了 AUFS 的开销)。在虚拟机情况下,块设备使用 virtio 映射到虚拟机中,并在虚拟机内挂载。这些配置如图 4 所示。我们在 O DIRECT 模式下使用了带有 libaio 后端的 fio [13] 2.0.8,对存储在固态硬盘上的 16 GB 文件进行了多次测试。使用 O DIRECT 允许绕过操作系统缓存进行访问。
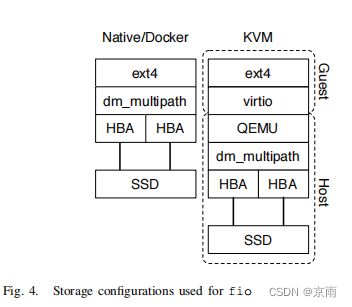
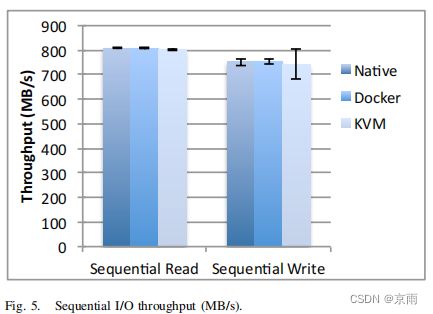
图 5 显示了使用典型的 1 MB I/O 大小在 60 秒内的平均连续读写性能。在这种情况下,Docker 和 KVM 带来的开销可以忽略不计,不过 KVM 的性能差异大约是其他情况下的四倍。与网络类似,光纤通道 HBA 似乎也是本次测试的瓶颈。
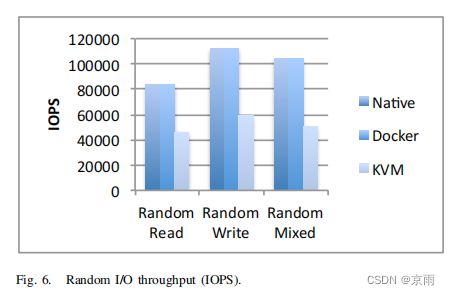
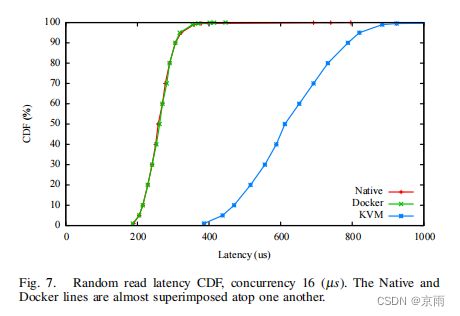
图 6 显示了随机读取、写入和混合(70% 读取、30% 写入)工作负载的性能,使用的是 4 kB 块大小和 128 并发量,我们通过实验确定了这一特定 SSD 的最高性能。正如我们所预期的那样,与 Linux 相比,Docker 不会带来任何开销,但 KVM 只提供了一半的 IOPS,因为每个 I/O 操作都必须经过 QEMU。虽然虚拟机的绝对性能仍然很高,但每次 I/O 操作会占用更多的 CPU 周期,从而减少了可用于应用程序工作的 CPU。图 7 显示,KVM 将读取延迟增加了 2-3 倍,这对某些实际工作负载来说是一个关键指标。
我们还注意到,这种硬件配置的连续 I/O 速度应该可以超过 1.5 GB/s,随机 I/O 速度应该可以超过 350,000 IOPS。因此,即使是原生案例也有很大的未开发潜力,而我们在硬件借给我们时并没有设法利用这些潜力。
H. Redis
基于内存的键值存储通常用于云缓存、存储会话信息,以及作为维护热门非结构化数据集的便捷方法。操作性质往往比较简单,需要在客户端和服务器之间进行网络往返。这种使用模式使应用程序对网络延迟普遍敏感。由于并发客户端数量众多,每个客户端都要向多个服务器发送非常小的网络数据包,因此这一挑战变得更加复杂。因此,服务器在网络堆栈中花费了大量时间。
这类服务器有好几种,在我们的评估中,我们选择了 Redis [43],因为它性能高、应用程序接口丰富,而且在 PaaS 提供商(如 Amazon Elasticache、Google Compute Engine)中使用广泛。我们从 GitHub 主仓库获取了 Redis 2.8.13,并在 Ubuntu 13.10 平台上构建了它。生成的二进制文件将用于每种部署模式:本地、Docker 和 KVM。为了提高性能,同时考虑到 Redis 是一个单线程应用程序,我们将容器或虚拟机亲和到靠近网络接口的内核上。测试包括多个客户端向服务器发送请求。读取和写入各占 50%。每个客户端与服务器保持一个持久的 TCP 连接,并可通过该连接发送多达 10 个并发请求。因此,飞行中的请求总数是客户端数量的 10 倍。键值长度为 10 个字符,生成的值平均为 50 字节。这种数据集形状代表了 Steinberg 等人 [47] 所描述的 Redis 生产用户。每次运行时,先清除数据集,然后发出确定的操作序列,逐步创建 1.5 亿个密钥。在执行过程中,Redis 服务器的内存消耗峰值为 11 GB。

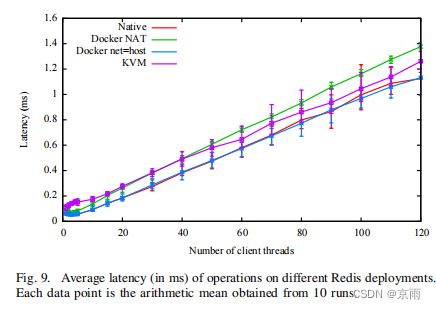
图 8 显示了不同部署模型的吞吐量(以每秒请求数为单位)与客户端连接数的关系。图 9 显示了每个实验的相应平均延迟(以微秒为单位)。在本机部署中,网络子系统足以处理负载。因此,随着客户端连接数的增加,限制 Redis 服务器吞吐量的主要因素是 CPU 饱和–请注意,Redis 是基于事件的单线程应用。在我们的平台上,这种情况很快就会出现,每秒约有 110 k 个请求。增加客户端会导致请求排队和平均延迟增加。
Redis 服务器给网络和内存子系统带来了很大压力。使用带有主机网络堆栈的 Docker 时,我们可以看到吞吐量和延迟几乎与本地情况相同。如图 1 所示,在启用 NAT 的情况下使用 Docker,情况就完全不同了。在这种情况下,延迟会随着网络接收数据包数量的增加而增加。在 4 个并发连接的情况下,延迟时间与本机相当(51µs 或本机的 1.05 倍),但一旦连接数增加,延迟时间就会迅速增长(100 个连接时超过 1.11 倍)。此外,NAT 会消耗 CPU 周期,从而使 Redis 部署无法达到使用本地网络栈的部署所能达到的峰值性能。
同样,在 KVM 中运行时,Redis 似乎也受网络限制。KVM 为每个事务增加了约 83µs 的延迟。我们看到,虚拟机在低并发时吞吐量较低,但随着并发量的增加,吞吐量逐渐接近本机性能。超过 100 个连接后,两种部署的吞吐量几乎相同。这可以用利特尔定律来解释:由于 KVM 下的网络延迟较高,Redis 需要更多并发量才能充分利用系统。这可能是一个问题,取决于云计算场景中终端用户期望的并发水平。

I. MySQL
MySQL 是一种流行的关系数据库,广泛应用于云计算,通常会对内存、IPC、文件系统和网络子系统造成压力。我们针对 MySQL 5.5.37 的单个实例运行了 SysBench [6] oltp 基准。MySQL 被配置为使用 InnoDB 作为后端存储,并启用了 3GB 缓存;该缓存足以缓存基准运行期间的所有读取。oltp 基准使用预载了 200 万条记录的数据库,并执行一组固定的读/写事务,在五个 SELECT 查询、两个 UPDATE 查询、一个 DELETE 查询和一个 INSERT 查询之间进行选择。SysBench 提供的测量结果是事务延迟和吞吐量(以每秒事务计算)的统计数据。客户端数量一直变化到饱和为止,每个数据点使用十次运行。测量了五种不同的配置: 在 Linux 上正常运行的 MySQL(原生)、在 Docker 下使用主机网络和卷的 MySQL(Docker net=host volume)、使用卷但使用正常 Docker 网络的 MySQL(Docker NAT volume)、在容器文件系统中存储数据库的 MySQL(Docker NAT AUFS)以及在 KVM 下运行的 MySQL;表 III 总结了这些不同的配置。虽然 MySQL 会访问文件系统,但我们的配置有足够的缓存,几乎不执行实际的磁盘 I/O,因此不同的 KVM 存储选项都没有实际意义。

图 10 显示了事务吞吐量与 SysBench 模拟的用户数量的函数关系。右侧 Y 轴显示的是与本机相比吞吐量的损失。这条曲线的大致形状符合我们的预期:吞吐量随着负载的增加而增加,直到机器达到饱和,然后趋于平稳,在超载时由于争用而造成少量损失。Docker 的性能与本机类似,在并发量较高时,两者的差距逐渐接近 2%。KVM 的开销要高得多,在所有测量案例中都高于 40%。通过比较 Docker NAT volume 和 Docker NAT AUFS 的结果可以看出,AUFS 带来了巨大的开销,这并不奇怪,因为 I/O 要经过多个层。AUFS 的开销显示了 Docker 在文件系统上方进行虚拟化与 KVM 在块层文件系统下方进行虚拟化之间的差异。我们测试了不同的 KVM 存储协议,发现它们对缓存内工作负载(如本测试)的性能没有影响。NAT 也会带来一些开销,但这种工作负载并不是网络密集型的。KVM 显示了一个有趣的结果,即网络达到饱和,但 CPU 没有达到饱和(图 11)。该基准测试生成了大量小数据包,因此即使网络带宽很小,网络协议栈也无法承受每秒所需的数据包数量。由于该基准测试使用同步请求,延迟的增加也会降低给定并发级别下的吞吐量。
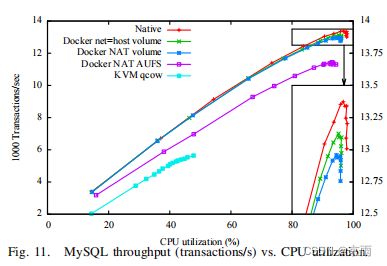


图 12 显示了延迟与 SysBench 模拟的用户数量的函数关系。正如预期的那样,延迟会随着负载的增加而增加,但有趣的是,Docker 在中等负载下的延迟增加得更快,这也是低并发水平下吞吐量较低的原因。图表的扩展部分显示,本地 Linux 能够达到更高的 CPU 利用率峰值,而 Docker 却无法达到相同的水平,两者相差约 1.5%。这一结果表明,Docker 的影响虽小,但可以衡量。
图 11 是吞吐量与 CPU 利用率的对比图。对比图 10 到图 12,我们注意到,在相同并发量下,Docker 和带 NAT 的 Docker 的吞吐量较低,但 CPU 消耗并没有相应增加。当使用相同数量的 CPU 时,吞吐量的差异微乎其微。在其他方面,Docker 的延迟也不相同,在并发量较低时,Docker 的延迟要高得多。在所有情况下,互斥争用也会阻止 MySQL 充分利用 CPU,但在 Docker 情况下更为明显,因为事务需要更长的时间。图 11 清楚地表明,在虚拟机的情况下,限制因素不是 CPU 而是网络,但即使客户端数量较少,KVM 的开销也很明显。
图 13 中的吞吐量-延迟曲线便于在目标延迟或吞吐量条件下比较各种方案。该曲线的一个有趣方面是,当饱和后引入更多客户端时,在某些情况下,较高的上下文切换会导致吞吐量下降。由于在 Docker 情况下空闲时间较多,因此对于基准测试中使用的客户端数量而言,较高的开销不会影响吞吐量。
J. Discussion
我们从这些结果中看到了几个总体趋势。正如我们所预期的那样,容器和虚拟机对 CPU 和内存的使用几乎不产生任何开销;它们只会影响 I/O 和操作系统的交互。这种开销以每次 I/O 操作额外周期的形式出现,因此小型 I/O 比大型 I/O 所受的影响要大得多。这种开销会增加 I/O 延迟,减少可用于有用工作的 CPU 周期,从而限制吞吐量。遗憾的是,实际应用往往无法将工作批量转化为大型 I/O。
Docker 增加了分层镜像和 NAT 等功能,使其比 LXC 类型的原始容器更易于使用,但这些功能需要付出性能代价。因此,使用默认设置的 Docker 可能并不比 KVM 快。文件系统或磁盘密集型应用程序应使用卷来绕过 AUFS。使用 -net=host 可以轻松消除 NAT 开销,但这样做会放弃网络命名空间的优势。最终,我们认为 Kubernetes 项目提出的每个容器一个 IP 地址的模式可以提供灵活性和性能。
虽然 KVM 可以提供非常好的性能,但其可配置性是一个弱点。良好的 CPU 性能需要对大页面、CPU 型号、vCPU 针脚和缓存拓扑进行仔细配置;这些功能的文档很少,需要反复试验才能配置。我们建议读者避免直接使用 qemu kvm,而是使用 libvirt,因为它简化了 KVM 配置。即使在最新版本的 Ubuntu 上,我们也无法让 vhost-scsi 正常工作,因此仍有改进的余地。这种复杂性对任何有抱负的云计算运营商(无论是公共云还是私有云)来说都是一个准入门槛。
Related Work
20 世纪 60 年代,Multics [32] 项目着手建立实用计算基础设施。虽然 Multics 一直没有得到广泛应用,云计算也要等到互联网普及后才能起飞,但该项目提出的端到端论证[41]和一系列安全原则[42]等理念至今仍具有现实意义。
20 世纪 70 年代,虚拟机被引入 IBM 大型机[20],20 世纪 90 年代末,VMware[38]在 x86 上重新发明了虚拟机。2000 年代,Xen [15] 和 KVM [25] 将虚拟机带入开源世界。虚拟机的开销最初很高,但多年来由于硬件和软件的优化,开销稳步降低[25, 31]。
操作系统级虚拟化也有着悠久的历史。从某种意义上说,操作系统的目的是虚拟化硬件资源,使其可以共享,但由于文件系统、进程和网络的全局命名空间,Unix 传统上提供的隔离性很差。基于能力的操作系统[22]由于一开始就没有任何全局命名空间,因此提供了类似于容器的隔离性,但它们在 20 世纪 80 年代就在商业上消亡了。Plan 9 引入了每个进程的文件系统命名空间[34]和绑定挂载,为 Linux 容器的命名空间机制提供了灵感。
长期以来,Unix 的 chroot() 功能一直被用于实现基本的 “jails”,而 BSD 的 jails 功能则扩展了这一概念。Solaris 10 于 2004 年引入并大力推广 Zones [37],它是容器的一种现代实现方式。云提供商 Joyent 自 2008 年以来一直提供基于 Zones 的 IaaS,但并未对整个云市场产生影响。
Linux 容器的历史悠久而曲折。Linux-VServer [46] 项目是 2001 年 "虚拟专用服务器 "的最初实施方案,从未并入主流 Linux,但在 PlanetLab 中得到了成功应用。商业产品 Virtuozzo 及其开源版本 OpenVZ [4] 被广泛用于虚拟主机,但也没有并入 Linux。从 2007 年开始,Linux 终于以内核命名空间和管理命名空间的 LXC 用户空间工具的形式添加了本地容器化功能。
Heroku 等平台即服务提供商提出了使用容器高效、可重复地部署应用程序的理念[28]。Heroku 并未将容器视为虚拟服务器,而是将其视为具有额外隔离功能的进程。由此产生的应用容器开销极小,具有与虚拟机类似的隔离性,但可以像普通进程一样共享资源。谷歌也在其内部基础设施中普遍采用了应用容器[19]。Heroku 的竞争对手 DotCloud(现名为 Docker 公司)推出了 Docker [45],作为这些应用容器的标准映像格式和管理系统。
对虚拟机管理程序进行了大量性能评估,但大多是与其他虚拟机管理程序或非虚拟化执行进行比较。[23, 24, 31]
以往的虚拟机与容器对比[30、33、44、46、50]大多使用 Xen 等旧软件和树外容器补丁。
Conclusions And Future Work
虚拟机和容器都是成熟的技术,得益于十年来硬件和软件的逐步优化。一般来说,在我们测试的每种情况下,Docker 的性能都相当于或超过 KVM。我们的结果表明,KVM 和 Docker 在 CPU 和内存性能方面的开销几乎可以忽略不计(极端情况除外)。对于 I/O 密集型工作负载,这两种形式的虚拟化都应谨慎使用。
我们发现,自 KVM 诞生以来,它的性能已经有了显著提高。过去被认为极具挑战性的工作负载,如线路速率为 10 Gbps 的网络,现在只需使用单核心和 2013 年的硬件和软件即可实现。即使使用现有最快的准虚拟化形式,KVM 仍会在每次 I/O 操作中增加一些开销;这些开销在执行小型 I/O 时非常可观,而在大型 I/O 上摊销后则可以忽略不计。因此,KVM 不太适合对延迟敏感或具有高 I/O 速率的工作负载。这些开销严重影响了我们测试的服务器应用程序。
虽然容器本身几乎没有开销,但 Docker 也不是没有性能问题。Docker 卷的性能明显优于存储在 AUFS 中的文件。Docker 的 NAT 也会为数据包速率较高的工作负载带来开销。这些功能是在管理方便性和性能之间的权衡,应根据具体情况加以考虑。
从某种意义上说,这种比较对容器来说只会更糟,因为容器一开始的开销几乎为零,而虚拟机随着时间的推移速度越来越快。如果要广泛采用容器,它们必须提供稳态性能以外的优势。我们相信,在不久的将来,便利性、更快的部署、弹性和性能的结合很可能会变得引人注目。
我们的研究结果可以为如何构建云基础设施提供一些指导。传统智慧(在年轻的云生态系统中存在这种智慧)认为,IaaS 应使用虚拟机来实现,而 PaaS 则应使用容器来实现。我们认为从技术上讲没有理由一定要这样,尤其是在基于容器的 IaaS 可以提供更好的性能或更容易部署的情况下。容器还可以消除 IaaS 与 "裸机 "非虚拟化服务器之间的区别 [10,26],因为它们既能提供虚拟机的控制和隔离功能,又能提供裸机的性能。无需为虚拟化和非虚拟化服务器维护不同的镜像,同一个 Docker 镜像可以高效地部署在从一小部分内核到整台机器上。
我们还对在虚拟机内部署容器的做法提出质疑,因为这不仅会带来虚拟机的性能开销,而且与直接在非虚拟化 Linux 上部署容器相比也毫无益处。如果必须使用虚拟机,那么在容器内运行虚拟机可以创建额外的安全层,因为可以利用 QEMU 的攻击者仍然会在容器内。
虽然当今的典型服务器都是 NUMA,但我们认为,试图在云中利用 NUMA 可能会得不偿失。将每个工作负载限制在单个插槽上可大大简化性能分析和调整。鉴于云应用程序通常设计为可扩展的,并且每个插槽的内核数量会随着时间的推移而增加,因此扩展单位可能应该是插槽而不是服务器。这也是反对裸机的一个理由,因为在每个插槽上运行一个容器的服务器实际上可能比将工作负载分散到各个插槽上更快,因为交叉流量减少了。
在本文中,我们创建了占用整台服务器的单个虚拟机或容器;而在云计算中,将服务器划分为更小的单元更为常见。这又引出了几个值得研究的课题:在同一服务器上运行多个工作负载时的性能隔离、容器和虚拟机的实时大小调整、扩展和缩小之间的权衡以及实时迁移和重新启动之间的权衡。
Source Code
运行本文实验的脚本可在 https://github.com/thewmf/kvm-docker-comparison 网站上获取。