spark 参数配置及内存模型
1 spark 提交主要参数
1.1 num-executors
此数量代表 spark的executors数量, 所有的task在executor中运行。
1.2 executor-cores
此数值代表每个 executor中可以并行运行的task数。 一般一个任务使用1核,此值等同于1个executor占用的CPU核心数。
1.3 executor-memory
此参数指定了每个 executor占用的内存。
注: 即使是executor-cores=4,并行运算的4个task也是共用此 executor的内存。
1.4 参数设置规范:
我们可以设置大量 num-executors, 但是设置executor-cores很小(如1)
也可以设置少量的num-execuotrs, 但是设置较多的executor-cores(如5)。
方案1, 有个明显缺点,当需要传递数据副本的时候,是基于executor, 太多的executor数量,会导致大量数据的网络IO,SHUFFLE。导致集群拥挤不堪,性能堪忧。特别是广播大的数据变量的时候。
方案2, 也不能设置太多的executor-cores,每个executor5、6个并发写HDFS基本上就达到满载瓶颈值。所以一般此值不要设置太大。 否则executor资源在job完成前是不会释放的(针对非动态分配资源),即时某些executor已经完成计算。 所以设置少量的num-execuotrs,有助于节省资源浪费。
综上: 一般按实际情况,num-executors不要太多(参照任务数据量及节点数),executor-cores小于等于5
1.5 设置executors数量
配置文件通过: spark-executor-instances。 未设置默认值为2
或者通过命令行: --num-executors设置。
i)在启用动态资源分配的情况下,即spark.dynamicAllocation.enabled=true:
如果配置了 spark-executor-instances参数, 则dynamic allocation 是关闭的。
则spark-executor-instances为准,即意味着spark-executor-instances参数覆盖了dynamic allocation
ii)在启用动态资源分配的情况下,即spark.dynamicAllocation.enabled=true:
如果没有配置 spark-executor-instances参数, 则dynamic allocation开启。由spark自身来动态分配 executor数量。
iii) 没有设置动态资源分配,即spark.dynamicAllocation.enabled=false, 则dynamic allocation 是关闭的。 同 i)类似
TIPS: 从上述描述可以知道:
在动态资源分配开启情况下,你可以手动在命令行设置 --num-executors或设置配置文件spark-executor-instances参数覆盖动态分配。
没启用动态分配,就更依赖这些参数了。也就是说只要指定这两个参数任一, 都将依赖静态分配的参数值。
备注: 在CDH6.3下实测, 在开启动态资源分配的情况下, spark-submit指定--num-executors参数,仍然使用的是动态分配, 执行器个数并不受控(部分受控,最小个数满足,最多由系统根据需要动态增加)。但是同时使用 executor-core和executor-memory情况下,使用的是手动配置的参数分配资源给executor运行JOB, 即内存和核数按参数设定 。
设置配置参数spark.dynamicAllocation.enabled=false, 可以完全按照配置参数覆盖全局的参数。使用静态指定参数执行。
1.6 为executor设置资源:
1) executor并行数(CPU核数)
在配置文件配置:spark-executor-cores
可以通过命令行 --executor-cores 。
2)executor JVM堆内存
在配置文件配置:spark-executor-memory 来设置
可以通过命令行 -- executor-memory。
堆内存,主要影响下属2个关键指标:
i)spark缓存数据SIZE
ii)spark shuffle能使用的最大内存(agg, group, join)
具体描述参看第2节
2 spark新版本内存模型(spark1.6.1之后的模型)。
常规或默认情况下, spark启动executor,主要耗费的内存如下:memoryOverhead + executor-memory
2.1 memoryOverhead(官方说明如下)
![]()
对应的参数就是spark.yarn.executor.memoryOverhead 这块内存是用于虚拟机的开销、内部的字符串、还有一些本地开销(比如python需要用到的内存)等。其实就是额外的内存,spark并不会对这块内存进行管理,.这部分内存是堆外内存,手动通过字节数组管控内存的分配和回收。
这部分内存,默认配置为max(executor-memory *0.10, 384M) , 因子写死不变。
因此调大executor-memory, 才能调大 memoryOverhead.
如下图错误, 基本上可以判断是数据size超过executor内存+memoryOverhead内存报错。常规方法加大 executor内存,或者优化逻辑。
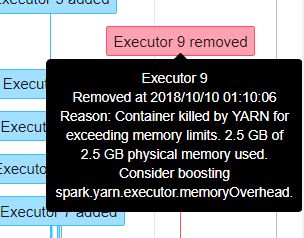
2.2 executor memory
这个内存就是我们设置的参数 executor-memory. 假定给值4G
i)reserverd memory
保留内存为固定大小300m。 4G-300M=3796M
ii)spark.memory.fraction. 1.6.1默认值为 0.75, 2.2.0后默认值为0.6
JVM可以管理的内存为 3796 * 0.6 = 2278M
III) spark.memory.storage.fraction. 默认值为0.5 ,
3796* 0.6 *0.5 = 1139M。 此部分内存用于缓存数据(如RDD)。
spark.memory.fraction对应内存的另外50%,用于执行代码所需内存特别是产生的结果数据(待shuffle)

SPARK MEMORY
系统框架运行时所需空间,由这两部份构成: Storage Memeory 和 Execution Memory。
现在 Storage 和 Execution (Shuffle) 采用了 Unified 的方式共同使用了:
(Java Heap – ReservedMemory) * spark.memory.fraction
在Spark 1.6.1中,默认为(Java Heap - 300M) * 0.75
在Spark 2.2.0中,默认为(Java Heap - 300M) * 0.6
默认情况下 Storage 和 Execution 各占该空间的 50%。你可以从图中可以看出,Storgae 和 Execution 的存储空间可以往上和往下移动。
所谓 Unified 的意思是 Storgae 和 Execution 在适当时候可以借用彼此的 Memory,需要注意的是,当 Execution 空间不足而且 Storage 空间也不足的情况下,Storage 空间如果曾经使用了超过 Unified 默认的 50% 空间的话则超过部份会被强制 drop 掉一部份数据来解决 Execution 空间不足的问题 (注意:drop 后数据会不会丢失主要是看你在程序设置的 storage_level 来决定你是 Drop 到那里,可能 Drop 到磁盘上),这是因为执行(Execution) 比缓存 (Storage) 是更重要的事情。
User Memory:
写 Spark 程序中产生的临时数据或者是自己维护的一些数据结构也需要给予它一部份的存储空间,你可以这么认为,这是程序运行时用户可以主导的空间,叫用户操作空间。它占用的空间是 :
(Java Heap - Reserved Memory) x 25% (默认是25%,可以有参数供调优)
在Spark 1.6.1中,默认占(Java Heap - 300MB) * 0.25
在Spark 2.2.0中,默认占(Java Heap - 300MB) * 0.4
这样设计可以让用户操作时所需要的空间与系统框架运行时所需要的空间分离开。假设 Executor 有 4G 的大小,那么在默认情况下 User Memory 大小是:(4G - 300MB) x 25% = 949MB,也就是说一个 Stage 内部展开后 Task 的算子在运行时最大的大小不能够超过 949MB。例如工程师使用 mapPartition 等,一个 Task 内部所有所有算子使用的数据空间的大小如果大于 949MB 的话,那么就会出现 OOM。
思考题:有 100个 Executors 每个 4G 大小,现在要处理 100G 的数据,假设这 100G 分配给 100个 Executors,每个 Executor 分配 1G 的数据,这 1G 的数据远远少于 4G Executor 内存的大小,为什么还会出现 OOM 的情况呢?那是因为在你的代码中(e.g.你写的应用程序算子)超过用户空间的限制 (e.g. 949MB),而不是 RDD 本身的数据超过了限制。
3 spark新版本内存模型总述:

第2节描述的内存主要部分,可以看上述第4和第5排(未启用off-heap)。
如果启用off-heap,则参看1-5排。
我们从下到上一层一层的解释:
第1层:整个excutor所用到的内存: 包括executor本身和相关内存。
第2层:分为jvm中的内存和jvm外的内存,这里的jvm内存在yarn的时候就是指申请的container的内存
第3层:对于spark来内存分为jvm堆内的和memoryoverhead、off-heap
memoryOverhead: 对应的参数就是spark.yarn.executor.memoryOverhead 这块内存是用于虚拟机的开销、内部的字符串、还有一些本地开销(比如python需要用到的内存)等。其实就是额外的内存,spark并不会对这块内存进行管理。
off-heap : 这里特指的spark.memory.offHeap.size这个参数指定的内存(广义上是指所有堆外的)。这部分内存的申请和释放是直接进行的不通过jvm管控所以没有GC,被spark分为storage和excution两部分和第5层讲的一同被spark统一进行管理。
第4层:jvm堆内的内存分为三个部分
reservedMemory: 预留内存300M,用于保障spark正常运行
other memory: 用于spark内部的一些元数据、用户的数据结构、防止出现对内存估计不足导致oom时的内存缓冲、占用空间比较大的记录做缓冲
memory faction: spark主要控制的内存,由参数spark.memory.fraction控制。
第5层:分成storage和execution 由参数spark.memory.storageFraction控制它两的大小,但是
execution: 用于spark的计算:shuffle、sort、aggregation等这些计算时会用到的内存,如果计算是内存不足会向storage部分借,如果还是不够就会spill到磁盘。
storage: 主要用于rdd的缓存,如果execution来借内存,可能会牺牲自己丢弃缓存来借给execution,storage也可以向execution借内存,但execution不会牺牲自己。
4 spark1.6之前的旧版本内存模型:静态管理模型。
Spark在一个Executor中的内存分为三块,一块是execution内存,一块是storage内存,一块是other内存。

1)storage内存是存储broadcast,cache,persist数据的地方。其中10%(60%10%)用于防止OOM。另外90%中的20%用于unroll,数据展开的(比如说,rdd.perist让数据序列化持久化,当要读出来的时候就需要反序列化,可以理解为解压,这就需要unroll这部分的内存空间了),其余的内存(90%80%)用于RDD缓存数据和广播变量。
2)execution内存是执行内存,文档中说join,aggregate都在这部分内存中执行,shuffle的数据也会先缓存在这.个内存中,满了再写入磁盘,能够减少IO。其实map过程也是在这个内存中执行的。
3)other内存是程序执行时预留给自己的内存,像task的执行和task执行时产生的对象。
业务逻辑需要更大的缓存空间,此时使用老版本的固定内存管理 (StaticMemoryManagement) 效果会更好。大部分复杂的情况,新版本的处理会更好。
4 开启off-heap管理:
tobe
参考文档:https://www.jianshu.com/p/b68a3a2df7a3
https://zhuanlan.zhihu.com/p/63187650