【论文阅读笔记】NeRF+Mip-NeRF+Instant-NGP
目录
- 前言
- NeRF
-
- 神经辐射场
- 体渲染
-
- 连续体渲染
- 体渲染离散化
- 方法
-
- 位置编码
- 分层采样
- 体渲染推导公式(1)到公式(2)
- 部分代码解读
-
- 相机变换(重要!)
- Mip-Nerf
-
- 存在什么问题
-
- 混叠
- 抗混叠
- 发现和思考
- 方法
- To do
- Instant-NGP
-
- To do
前言
NeRF是NeRF系列的开山之作,将三维场景隐式的表达为神经网络的权重用于新视角合成。
MipNeRF和Instant NGP分别代表了NeRF的两个研究方向,前者是抗锯齿,代表着渲染质量提升方向;后者是采用多分辨率哈希表用于加速NeRF的训练与推理速度。

NeRF
Title:NeRF: Representing Scenes asNeural Radiance Fields for View Synthesis
Code:nerf-pytorch
From:ECCV 2020 Oral - Best Paper Honorable Mention
神经辐射场

辐射场可以理解光线场,给定多张带有相机内外参的二维图片,从摄像机出发,引出到每一个像素的光线,通过对这条光线经历过的空间点的颜色 c c c和体密度体密度 σ \sigma σ进行累积,以得到二维图片上像素点的颜色,从而实现端到端训练。在这个过程中,没有显式的三维结构,如点云、体素或者Mesh,而是通过神经网络的权重 F θ F_{\theta} Fθ将三维场景连续的存储起来,通过空间位置(三维点 [ x , y , z ] [x,y,z] [x,y,z])和视角方向(球坐标系下的极角和方位角 [ θ , ϕ ] [\theta,\phi] [θ,ϕ])作为查询条件,查询出给定摄像机下的光线所经过的空间点颜色 c c c和体密度 σ \sigma σ,通过**体渲染(Volume Rendering)**得到该条光线对应像素点的颜色。
体渲染

沿着视角方向的光线上的点P可以用上图来表示,尽管论文中提到视角方向是使用 θ , ϕ \theta,\phi θ,ϕ来表示的,但代码中还是使用单位向量 d d d来表示的。
连续体渲染
体渲染实际上就是将视线r上所有的点通过某种方式累计投射到图像上形成像素颜色 C ( r ) C(r) C(r)的过程:
C ( r ) = ∫ t n t f T ( t ) σ ( r ( t ) ) c ( r ( t ) , d ) d t where T ( t ) = exp ( − ∫ t n t σ ( r ( s ) ) d s ) (1) {C}(\boldsymbol{r})=\int_{t_n}^{t_f} T(t) \sigma(\boldsymbol{r}(t)) \boldsymbol{c}(\boldsymbol{r}(t), \boldsymbol{d}) dt \\ \text{where } T(t)=\exp \left(-\int_{t_n}^t \sigma(\boldsymbol{r}(s)) d s\right)\tag{1} C(r)=∫tntfT(t)σ(r(t))c(r(t),d)dtwhere T(t)=exp(−∫tntσ(r(s))ds)(1)
其中, c ( r ( t ) , d ) \boldsymbol{c}(\boldsymbol{r}(t), \boldsymbol{d}) c(r(t),d)为三维点 r ( t ) r(t) r(t)从 d d d这个方向看到的颜色值; σ ( r ( t ) ) \sigma(\boldsymbol{r}(t)) σ(r(t))为体密度函数,反映的是该三维点的物理材质吸收光线的能力; T ( t ) T(t) T(t)反映的是射线上从 t n t_n tn到 t t t的累积透射率。tn和tf首先确定了nerf的边界,而不至于学习到无穷远;其次避免了光心到近景范围内无效采样。
直观上理解σ,可以解释为每个三维点吸收光线的能力,光经过该点,一部分被吸收,一部分透射,光的强度(可以理解为 T ( t ) T(t) T(t)) 在逐渐减小,当光强为0时,后面的三维点即便可以吸收颜色,也不会对像素颜色有贡献。指数函数保证了随着σ的累积,光的强度从1逐渐减为0。
体渲染离散化
其实就是函数离散化的形式,将tn到tf拆分成N个均匀的分布空间,从每个区间中随机选取一个样本ti:
t i ∼ U [ t n + i − 1 N ( t f − t n ) , t n + i N ( t f − t n ) ] i 从1到N t_i \sim \mathcal{U}\left[t_n+\frac{i-1}{N}\left(t_f-t_n\right), t_n+\frac{i}{N}\left(t_f-t_n\right)\right] \quad i \text{ 从1到N} ti∼U[tn+Ni−1(tf−tn),tn+Ni(tf−tn)]i 从1到N
然后将连续体渲染公式离散化:
C ^ ( r ) = ∑ i = 1 N T i ( 1 − exp ( − σ i δ i ) ) c i where T i = exp ( − ∑ j = 1 i − 1 σ j δ j ) (2) \hat{C}(\mathbf{r})=\sum_{i=1}^N T_i\left(1-\exp \left(-\sigma_i \delta_i\right)\right) \mathbf{c}_i \quad \tag 2 \\ \text{where } T_i=\exp \left(-\sum_{j=1}^{i-1} \sigma_j \delta_j\right) C^(r)=i=1∑NTi(1−exp(−σiδi))ciwhere Ti=exp(−j=1∑i−1σjδj)(2)
where T i = exp ( − ∑ j = 1 i − 1 σ j δ j ) T_i=\exp \left(-\sum_{j=1}^{i-1} \sigma_j \delta_j\right) Ti=exp(−∑j=1i−1σjδj)
其中, δ i = t i + 1 − t i \delta_i=t_{i+1}-t_i δi=ti+1−ti 表示相邻采样点之间的距离

但均匀采样有明显的问题, 比如体密度较大的点如果在两个采样点之间,那么永远不可能采样到。从上图中可看出,左半张代表均匀采样,右半张代表真实分布,左边由于表面两侧被采样到,只能反应这个区间内可能存在表面,但估计的σ不一定准确。
作者提出了分层采样来试图解决这个问题。
方法
位置编码
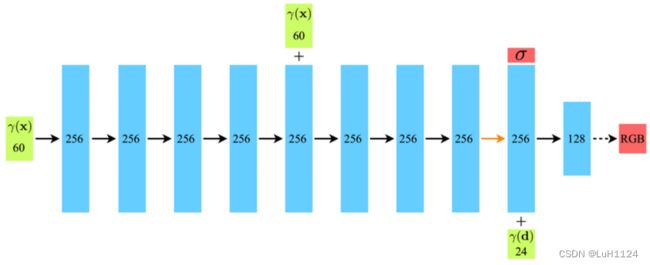
网络结构由如上图所示全连接网络组成,输入x,d分别分三维点的空间位置和视线方向。该三维点的体密度只与空间位置相关,颜色还和视角相关。
γ ( p ) = ( sin ( 2 0 π p ) , cos ( 2 0 π p ) , ⋯ , sin ( 2 L − 1 π p ) , cos ( 2 L − 1 π p ) ) \gamma(p)=\left(\sin \left(2^0 \pi p\right), \cos \left(2^0 \pi p\right), \cdots, \sin \left(2^{L-1} \pi p\right), \cos \left(2^{L-1} \pi p\right)\right) γ(p)=(sin(20πp),cos(20πp),⋯,sin(2L−1πp),cos(2L−1πp))
还可以注意到γ(x)和γ(d)分别是对位置坐标和方向坐标的位置编码(标准正余弦位置编码),这是由于单纯坐标只能体现低频信息,位置编码可以有效的区分开两个距离很近的坐标(即低频接近但高频编码分开【但或许也有问题,离得特别近的两个点或许低频信息也不相似,私以为mipnerf考虑三维点邻域的区间,在一定程度上可以缓解】),从而帮助网络学习到高频几何和纹理细节。如下图所示,视角信息有效反应高光信息,位置编码有助于恢复高频细节。

分层采样
除了上述提到的均匀采样可能导致i真实表面难以正好采样到,还有均匀采样带来了很多无意义空间的无效采样,简单来说,只有空气的地方没必要进行采样,或者被遮挡区域(可见性问题,不可见区域也没必要采样,需要提前判断累积透射率是否为降为0)。
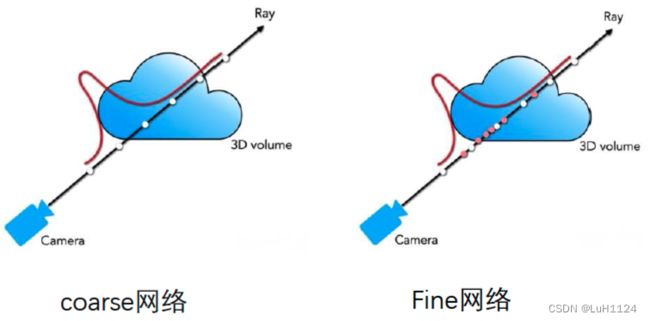
首先均匀采样可以得到crose color,wi可以理解为同条射线被采样的 N c N_c Nc个三维点颜色的权重:
C ^ c ( r ) = ∑ i = 1 N c w i c i , w i = T i ( 1 − exp ( − σ i δ i ) ) \widehat{C}_c(\mathbf{r})=\sum_{i=1}^{N_c} w_i c_i, \quad w_i=T_i\left(1-\exp \left(-\sigma_i \delta_i\right)\right) C c(r)=i=1∑Ncwici,wi=Ti(1−exp(−σiδi))
根据均匀采样点的权重值归一化后按重要性重新采样得到新的 n f n_f nf个位置
w ^ i = w i / ∑ j = 1 N c w j \widehat{w}_i=w_i / \sum_{j=1}^{N_c} w_j w i=wi/j=1∑Ncwj
最后损失函数可以表示为:
L = ∑ r ∈ R [ ∥ C ^ c ( r ) − C ( r ) ∥ 2 2 + ∥ C ^ f ( r ) − C ( r ) ∥ 2 2 ] \mathcal{L}=\sum_{\mathbf{r} \in \mathcal{R}}\left[\left\|\widehat{C}_c(\mathbf{r})-C(\mathbf{r})\right\|_2^2+\left\|\widehat{C}_f(\mathbf{r})-C(\mathbf{r})\right\|_2^2\right] L=r∈R∑[ C c(r)−C(r) 22+ C f(r)−C(r) 22]
这里为什么选用两个网络来分别做粗糙采样和精细采样,参考大佬【
】。crose网络是用于均匀采样的,包含更多的是低频信息的查询,而fine网络用于重要性采样,适用于三维点高频细节的查询,两个网络起到了类似滤波器的作用。
「待做实验验证!!!Todo」
体渲染推导公式(1)到公式(2)
首先,光线通过区间 [ 0 , t + d t ) [0, t+d t) [0,t+dt) 的概率:
光线通过区间 [ 0 , t + d t ) [0, t+d t) [0,t+dt) 的概率:
T ( t + d t ) = T ( t ) ⋅ ( 1 − d t ⋅ σ ( t ) ) \begin{aligned} \mathcal{T}(t+d t) & =\mathcal{T}(t) \cdot(1-d t \cdot \sigma(t)) \end{aligned} T(t+dt)=T(t)⋅(1−dt⋅σ(t))
可以得到
T ( t + d t ) − T ( t ) d t ≡ T ′ ( t ) = − T ( t ) ⋅ σ ( t ) \begin{aligned} \frac{\mathcal{T}(t+d t)-\mathcal{T}(t)}{d t} & \equiv \mathcal{T}^{\prime}(t)=-\mathcal{T}(t) \cdot \sigma(t) \end{aligned} dtT(t+dt)−T(t)≡T′(t)=−T(t)⋅σ(t)
1 − T ( t ) 1-\mathcal{T}(t) 1−T(t) 为光线在区间 [ 0 , t ) [0, t) [0,t) 被终止的累积分布函数(CDF);
T ( t ) σ ( t ) \mathcal{T}(t) \sigma(t) T(t)σ(t) 为其对应的概率密度函数 (PDF)
其中, T ( t ) \mathcal{T}(t) T(t) 为光线通过区间 [ 0 , t ) [0, t) [0,t) 透射率,也就是没被终止的概率,从1->0; σ ( t ) \sigma(t) σ(t) 为体密度函数; d t ⋅ σ ( t ) d t \cdot \sigma(t) dt⋅σ(t) 为光线在 [ t , t + d t ) [t, t+d t) [t,t+dt) 区间被吸收的概率,也就是被终止概率。
T ′ ( t ) = − T ( t ) ⋅ σ ( t ) T ′ ( t ) T ( t ) = − σ ( t ) ∫ a b T ′ ( t ) T ( t ) d t = − ∫ a b σ ( t ) d t log T ( t ) ∣ a b = − ∫ a b σ ( t ) d t T ( a → b ) ≡ T ( b ) T ( a ) = exp ( − ∫ a b σ ( t ) d t ) \begin{aligned} \mathcal{T}^{\prime}(t) & =-\mathcal{T}(t) \cdot \sigma(t) \\ \frac{\mathcal{T}^{\prime}(t)}{\mathcal{T}(t)} & =-\sigma(t) \\ \int_a^b \frac{\mathcal{T}^{\prime}(t)}{\mathcal{T}(t)} d t & =-\int_a^b \sigma(t) d t \\ \left.\log \mathcal{T}(t)\right|_a ^b & =-\int_a^b \sigma(t) d t \\ \mathcal{T}(a \rightarrow b) \equiv \frac{\mathcal{T}(b)}{\mathcal{T}(a)} & =\exp \left(-\int_a^b \sigma(t) d t\right) \end{aligned} T′(t)T(t)T′(t)∫abT(t)T′(t)dtlogT(t)∣abT(a→b)≡T(a)T(b)=−T(t)⋅σ(t)=−σ(t)=−∫abσ(t)dt=−∫abσ(t)dt=exp(−∫abσ(t)dt)
T ( a → b ) \mathcal{T}(a \rightarrow b) T(a→b) 表示光线通过 a a a 到 b b b 区间没被终止的概率,假设 [ a , b ) [a,b) [a,b) 共享 a a a点体密度和颜色
C = ∫ 0 D T ( t ) ⋅ σ ( t ) ⋅ c ( t ) d t + T ( D ) ⋅ c b g C=\int_0^D \mathcal{T}(t) \cdot \sigma(t) \cdot \mathbf{c}(t) d t+\mathcal{T}(D) \cdot \mathbf{c}_{\mathrm{bg}} C=∫0DT(t)⋅σ(t)⋅c(t)dt+T(D)⋅cbg
c b g c_{b g} cbg 表示背景色彩
C ( a → b ) = ∫ a b T ( a → t ) ⋅ σ ( t ) ⋅ c ( t ) d t = σ a ⋅ c a ∫ a b T ( a → t ) d t = σ a ⋅ c a ∫ a b exp ( − ∫ a t σ ( u ) d u ) d t = σ a ⋅ c a ∫ a b exp ( − σ a u ∣ a t ) d t = σ a ⋅ c a ∫ a b exp ( − σ a ( t − a ) ) d t = σ a ⋅ c a ⋅ exp ( − σ a ( t − a ) ) − σ a ∣ a b = c a ⋅ ( 1 − exp ( − σ a ( b − a ) ) ) \begin{aligned} \boldsymbol{C}(a \rightarrow b) & =\int_a^b \mathcal{T}(a \rightarrow t) \cdot \sigma(t) \cdot \mathbf{c}(t) d t \\ & =\sigma_a \cdot \mathbf{c}_a \int_a^b \mathcal{T}(a \rightarrow t) d t \\ & =\sigma_a \cdot \mathbf{c}_a \int_a^b \exp \left(-\int_a^t \sigma(u) d u\right) d t \\ & =\sigma_a \cdot \mathbf{c}_a \int_a^b \exp \left(-\left.\sigma_a u\right|_a ^t\right) d t \\ & =\sigma_a \cdot \mathbf{c}_a \int_a^b \exp \left(-\sigma_a(t-a)\right) d t \\ & =\left.\sigma_a \cdot \mathbf{c}_a \cdot \frac{\exp \left(-\sigma_a(t-a)\right)}{-\sigma_a}\right|_a ^b \\ & =\mathbf{c}_a \cdot\left(1-\exp \left(-\sigma_a(b-a)\right)\right)\end{aligned} C(a→b)=∫abT(a→t)⋅σ(t)⋅c(t)dt=σa⋅ca∫abT(a→t)dt=σa⋅ca∫abexp(−∫atσ(u)du)dt=σa⋅ca∫abexp(−σau∣at)dt=σa⋅ca∫abexp(−σa(t−a))dt=σa⋅ca⋅−σaexp(−σa(t−a)) ab=ca⋅(1−exp(−σa(b−a)))
T ( a → c ) = = exp ( − [ ∫ a b σ ( t ) d t + ∫ b c σ ( t ) d t ] ) = exp ( − ∫ a b σ ( t ) d t ) exp ( − ∫ b c σ ( t ) d t ) = T ( a → b ) ⋅ T ( b → c ) \begin{aligned} \mathcal{T}(a \rightarrow c)= & =\exp \left(-\left[\int_a^b \sigma(t) d t+\int_b^c \sigma(t) d t\right]\right) \\ & =\exp \left(-\int_a^b \sigma(t) d t\right) \exp \left(-\int_b^c \sigma(t) d t\right) \\ & =\mathcal{T}(a \rightarrow b) \cdot \mathcal{T}(b \rightarrow c)\end{aligned} T(a→c)==exp(−[∫abσ(t)dt+∫bcσ(t)dt])=exp(−∫abσ(t)dt)exp(−∫bcσ(t)dt)=T(a→b)⋅T(b→c)
T n = T ( t n ) = T ( 0 → t n ) = exp ( − ∫ 0 t n σ ( t ) d t ) = exp ( ∑ k = 1 n − 1 − σ k δ k ) \mathcal{T}_n=\mathcal{T}\left(t_n\right)=\mathcal{T}\left(0 \rightarrow t_n\right)=\exp \left(-\int_0^{t_n} \sigma(t) d t\right)=\exp \left(\sum_{k=1}^{n-1}-\sigma_k \delta_k\right) Tn=T(tn)=T(0→tn)=exp(−∫0tnσ(t)dt)=exp(k=1∑n−1−σkδk)
C ( t N + 1 ) = ∑ n = 1 N ∫ t n t n + 1 T ( t ) ⋅ σ n ⋅ c n d t = ∑ n = 1 N ∫ t n t n + 1 T ( 0 → t n ) ⋅ T ( t n → t ) ⋅ σ n ⋅ c n d t = ∑ n = 1 N T ( 0 → t n ) ∫ t n t n + 1 T ( t n → t ) ⋅ σ n ⋅ c n d t = ∑ n = 1 N T ( 0 → t n ) ⋅ ( 1 − exp ( − σ n ( t n + 1 − t n ) ) ) ⋅ c n \begin{aligned} \boldsymbol{C}\left(t_{N+1}\right) & =\sum_{n=1}^N \int_{t_n}^{t_{n+1}} \mathcal{T}(t) \cdot \sigma_n \cdot \mathbf{c}_n d t \\ & =\sum_{n=1}^N \int_{t_n}^{t_{n+1}} \mathcal{T}\left(0 \rightarrow t_n\right) \cdot \mathcal{T}\left(t_n \rightarrow t\right) \cdot \sigma_n \cdot \mathbf{c}_n d t \\ & =\sum_{n=1}^N \mathcal{T}\left(0 \rightarrow t_n\right) \int_{t_n}^{t_{n+1}} \mathcal{T}\left(t_n \rightarrow t\right) \cdot \sigma_n \cdot \mathbf{c}_n d t \\ & =\sum_{n=1}^N \mathcal{T}\left(0 \rightarrow t_n\right) \cdot\left(1-\exp \left(-\sigma_n\left(t_{n+1}-t_n\right)\right)\right) \cdot \mathbf{c}_n\end{aligned} C(tN+1)=n=1∑N∫tntn+1T(t)⋅σn⋅cndt=n=1∑N∫tntn+1T(0→tn)⋅T(tn→t)⋅σn⋅cndt=n=1∑NT(0→tn)∫tntn+1T(tn→t)⋅σn⋅cndt=n=1∑NT(0→tn)⋅(1−exp(−σn(tn+1−tn)))⋅cn
T ( 0 → t n ) ⋅ ( 1 − exp ( − σ n ( t n + 1 − t n ) ) ) \mathcal{T}\left(0 \rightarrow t_n\right) \cdot\left(1-\exp \left(-\sigma_n\left(t_{n+1}-t_n\right)\right)\right) T(0→tn)⋅(1−exp(−σn(tn+1−tn)))表示光线正好在 t N + 1 t_{N+1} tN+1位置的颜色的权重(透射率*该点的颜色吸收率=该点颜色的贡献率,对应代码中的weights,代码中的 α \alpha α指代 1 − e x p ( − σ ∗ δ ) 1-exp(-\sigma*\delta) 1−exp(−σ∗δ))
C ( t N + 1 ) = ∑ n = 1 N T n ⋅ ( 1 − exp ( − σ n δ n ) ) ⋅ c n , where T n = exp ( ∑ k = 1 n − 1 − σ k δ k ) \boldsymbol{C}\left(t_{N+1}\right)=\sum_{n=1}^N \mathcal{T}_n \cdot\left(1-\exp \left(-\sigma_n \delta_n\right)\right) \cdot \mathbf{c}_n, \quad \\ \text{where} \quad \mathcal{T}_n=\exp \left(\sum_{k=1}^{n-1}-\sigma_k \delta_k\right) C(tN+1)=n=1∑NTn⋅(1−exp(−σnδn))⋅cn,whereTn=exp(k=1∑n−1−σkδk)
部分代码解读
相机变换(重要!)
- 关于nerf相机方向的解读
- 关于llff格式数据使用的NDC空间解读
- 详解NeRF中的NDC ray space - Jermmy的文章 - 知乎
简单来说就是针对不同种类的数据在不同的空间进行计算,如360度合成数据lego(直接从相机坐标系变换到世界坐标系下)或者无界数据llff(NDC空间能将近远景0到正无穷)范围限制在0到1之间)

Mip-Nerf
存在什么问题
混叠
根据奈奎斯特采样定律,采样频率至少是模拟信号中最高频率的两倍。所谓混叠,即在对模拟信号进行采样时,高于1/2采样频率的高频信号被映射到信号的低频部分(即高频信息丢失),与原有低频信号叠加,对信号的完整性和准确性产生影响。
参考链接:
- 数字图像处理中的混叠
- GAMES101-现代计算机图形学入门-闫令琪
- 计算机图形学笔记四:光栅化(抗锯齿,反走样)
- 走样(混叠错误)常见的三种类别:锯齿样、摩尔纹(手机拍显示屏,去掉图像中的奇数行列)、车轮效应(人眼看轮子旋转出现逆向)
- MSAA()
抗混叠
参考链接:
-
图形渲染中的抗锯齿(反走样)方法 - 奇林的文章 - 知乎
-
图形学底层探秘 - 纹理采样、环绕、过滤与Mipmap的那些事 - Clawko的文章 - 知乎
-
两种思路
- 一是直接提高采样频率,以获得更高的尼奎斯特频率,但是采样频率不能无限提高。如下图所示,将原本一个像素点拆分为4个,按比例决定最终像素点的颜色

【在图形学中称为超采样抗锯齿(Super Sampling Anti-Aliasing,SSAA)是采样混合公式的完整形式,是抗锯齿的理论模型,具有极好的呈现效果。它要求我们完整的渲染出一个屏幕分辨率 n 倍的图像,然后使用采样混合公式,一个屏幕像素对应 n 个采样点计算出屏幕大小的图像。
抗锯齿的基本思想:选取某个删格覆盖区域的多个样本点的颜色并进行混合计算后的颜色作为该删格的颜色
- 实时渲染中的 AA 技术:
- MSAA 算法家族(MSAA、CSAA、EQAA)
- TAA 算法家族(TAA、TXAA、MFAA)
- 后期处理 AA 算法家族(MLAA、FXAA)
- 深度学习 AA 算法 (DLSS)】
- 二是在采样频率固定的情况下,可通过低通滤波器消除大于尼奎斯特频率的高频信号,从而消除混叠现象(最简单的先模糊去除高频信号后采样,比如高斯模糊、平均模糊)

在图形学中,还有一种被广泛使用的纹理抗锯齿技术Mipmap:【!!核心思想:纹理大小跟图形大小接近才会有好的显示效果,本质上可以理解为是经过一系列的低通滤波器预处理】

- 一是直接提高采样频率,以获得更高的尼奎斯特频率,但是采样频率不能无限提高。如下图所示,将原本一个像素点拆分为4个,按比例决定最终像素点的颜色
参考链接:PowerVR-为什么你需要使用mipmap技术 - 东汉书院的文章 - 知乎
- Mipmap抗锯齿的基本思路是利用图像金字塔的概念,在不同尺寸的纹理图像中存储同一张原始纹理的多个版本。这些不同尺寸的纹理图像被称为mipmap级别
- 当进行纹理映射时,系统根据与被渲染表面的距离来选择合适的mipmap级别。当渲染表面比纹理图像小很多时,系统选择使用更高分辨率的mipmap级别,反之则选择使用分辨率较低的mipmap级别。这样可以避免在渲染过程中出现锯齿,因为根据视角和距离的变化,始终使用适应当前场景的纹理尺寸
- 各向异性过滤指当纹理形状和图形差别较大导致纹理坐标变化率变大,需要贴不同level的mipmap。比如下图
发现和思考

作者尝试调整摄像机的距离来观察不同分辨率的结果,可以看到(SSIM作为评价指标)(a)低分辨率下出现严重的锯齿,这是典型的混叠现象,当摄像机距离拉远**,同一个像素需要表达空间中更大范围的信息**,导致失真(b)如果在训练的时候采用多分辨率混合训练,能够提升低分辨率下的渲染质量,但是Full分辨率的渲染质量出现了下降,这是由于多分辨率混合训练反而可能导致学到的是摄像机在中间位置的结果。
假设超采样方案,将一个像素点拆分为多个,会导致数倍的计算开销;本篇文章中使用的是低通滤波器方案,mipmaps。
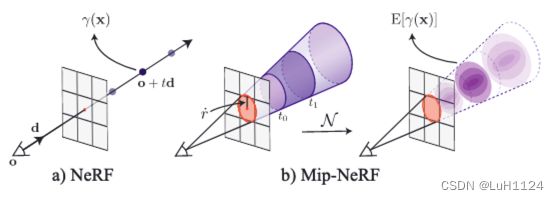
简单来说
- 将原本的光线变为圆锥体,原本的采样点变为圆椎体的截台体,以前只采样一个点,现在是采样一个圆锥体范围内的许多点,通过加权平均得到这个圆台体的体密度和颜色。这就类似于对范围内的所有点先进行了均值滤波,或者说低通滤波,然后再进行渲染。
- 但是将圆台内所有的点都去计算体密度和颜色的均值,每个点都需要经过位置编码后过一遍神经网络,带来了额外的开销。本文考虑对位置编码进行加权平均得到集成位置编码后再通过神经网络以近似平均的体密度和颜色。
方法
-
如何对位置编码进行加权平均
- 首先确保采样点位置是否在圆台范围内, r ˙ \dot{r} r˙表示像素区间投射到像素上距离像素中心位置的最大距离(圆台截面半径radius)

F ( x , o , d , r ˙ , t 0 , t 1 ) = 1 { ( t 0 < d T ( x − o ) ∥ d ∥ 2 2 < t 1 ) ∧ ( d T ( x − o ) ∥ d ∥ 2 ∥ x − o ∥ 2 > 1 1 + ( r ˙ / ∥ d ∥ 2 ) 2 ) } , \begin{gathered}\mathrm{F}\left(\mathbf{x}, \mathbf{o}, \mathbf{d}, \dot{r}, t_0, t_1\right)=\mathbb{1}\left\{\left(t_0<\frac{\mathbf{d}^{\mathrm{T}}(\mathbf{x}-\mathbf{o})}{\|\mathbf{d}\|_2^2}
前一项判断当前空间点位置是否在 t 0 , t 1 t_0,t_1 t0,t1之间, θ \theta θ为摄像机到像素中心的射线与相机到采样点对应射线之间的夹角
t x = ∥ x − o ∥ 2 cos ( θ ) = ∥ x − o ∥ 2 d T ( x − o ) ∥ d ∥ 2 ∥ x − o ∥ 2 \begin{gathered}t_x=\|x-o\|_2\cos(\theta)=\|x-o\|_2\frac{\mathbf{d}^{\mathrm{T}}(\mathbf{x}-\mathbf{o})}{\|\mathbf{d}\|_2\|x-o\|_2}\end{gathered} tx=∥x−o∥2cos(θ)=∥x−o∥2∥d∥2∥x−o∥2dT(x−o)
后一项判断采样点是否在 t 0 , t 1 t_0,t_1 t0,t1对应的圆台内,即 cos θ \cos\theta cosθ应大于 cos ϕ \cos\phi cosϕ
cos θ ≥ cos ϕ = d T ( x − o ) ∥ d ∥ 2 ∥ x − o ∥ 2 ≥ ∥ d ∥ 2 r ˙ 2 + ∥ d ∥ 2 , \begin{gathered}\cos\theta\geq\cos\phi=\frac{\mathbf{d}^{\mathrm{T}}(\mathbf{x}-\mathbf{o})}{\|\mathbf{d}\|_2\|\mathbf{x}-\mathbf{o}\|_2}\geq\frac{\|\mathbf{d}\|_2}{\sqrt{\dot{r}^2+\|\mathbf{d}\|_2}},\end{gathered} cosθ≥cosϕ=∥d∥2∥x−o∥2dT(x−o)≥r˙2+∥d∥2∥d∥2,则圆台体的位置编码的期望可以定义为
γ ∗ ( o , d , r ˙ , t 0 , t 1 ) = ∫ γ ( x ) F ( x , o , d , r ˙ , t 0 , t 1 ) d x ∫ F ( x , o , d , r ˙ , t 0 , t 1 ) d x \gamma^*\left(\mathbf{o}, \mathbf{d}, \dot{r}, t_0, t_1\right)=\frac{\int \gamma(\mathbf{x}) \mathrm{F}\left(\mathbf{x}, \mathbf{o}, \mathbf{d}, \dot{r}, t_0, t_1\right) d \mathbf{x}}{\int \mathrm{F}\left(\mathbf{x}, \mathbf{o}, \mathbf{d}, \dot{r}, t_0, t_1\right) d \mathbf{x}} γ∗(o,d,r˙,t0,t1)=∫F(x,o,d,r˙,t0,t1)dx∫γ(x)F(x,o,d,r˙,t0,t1)dx - 首先确保采样点位置是否在圆台范围内, r ˙ \dot{r} r˙表示像素区间投射到像素上距离像素中心位置的最大距离(圆台截面半径radius)
