物流实时数仓:数仓搭建(DIM)
系列文章目录
物流实时数仓:采集通道搭建
物流实时数仓:数仓搭建
物流实时数仓:数仓搭建(DIM)
文章目录
- 系列文章目录
- 前言
- 一、文件编写
-
- 1.pom.xml
- 2.目录创建
- 3.DimApp.java
- 4.KafkaUtil.java
- 5.CreateEnvUtil.java
- 6.HbaseUtil.java
- 7.TmsConfigDimBean.java
- 8.MyBroadcastProcessFunction.java
- 9.DimSinkFunction.java
- 10.TmsConfig.java
- 二、代码测试
-
- 1.环境启动
- 2.清除hbase数据(新安装的不需要)
- 3.程序启动
- 总结
前言
这次博客记录一下有关数仓的DIM层建设,不知道一次能不能完成
这时目前的大概流程。

红框中就是我们要完成的DIM操作。
我们需要从Kafka中读取数据,和配置表信息进行比较和处理进而传递到下游写入hbase。
一、文件编写
1.pom.xml
我们在之前的基础上添加几个依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
2.目录创建

3.DimApp.java
package com.atguigu.tms.realtime.app.dim;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.tms.realtime.app.func.DimSinkFunction;
import com.atguigu.tms.realtime.app.func.MyBroadcastProcessFunction;
import com.atguigu.tms.realtime.beans.TmsConfigDimBean;
import com.atguigu.tms.realtime.commom.TmsConfig;
import com.atguigu.tms.realtime.utils.CreateEnvUtil;
import com.atguigu.tms.realtime.utils.HbaseUtil;
import com.atguigu.tms.realtime.utils.KafkaUtil;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class DimApp {
public static void main(String[] args) throws Exception {
// 1.基本环境准备
StreamExecutionEnvironment env = CreateEnvUtil.getStreamEnv(args);
env.setParallelism(4);
// 2.从Kafka的tms_ods主题中读取业务数据
String topic = "tms_ods";
String groupID = "dim_app_group";
KafkaSource<String> kafkaSource = KafkaUtil.getKafkaSource(topic, groupID, args);
SingleOutputStreamOperator<String> kafkaStrDS = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source")
.uid("kafka source");
// kafkaStrDS.print(">>>");
// 3.对读取的数据进行类型转换并过滤掉不需要传递json属性
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaStrDS.map(
(MapFunction<String, JSONObject>) jsonStr -> {
JSONObject jsonObj = JSON.parseObject(jsonStr);
String table = jsonObj.getJSONObject("source").getString("table");
jsonObj.put("table", table);
jsonObj.remove("before");
jsonObj.remove("source");
jsonObj.remove("transaction");
return jsonObj;
}
);
// 4.使用FlinkCDC读取配置表数据
MySqlSource<String> mysqlSource = CreateEnvUtil.getMysqlSource("config_dim", "6000", args);
SingleOutputStreamOperator<String> mysqlDS = env.fromSource(mysqlSource, WatermarkStrategy.noWatermarks(), "mysql_source")
.setParallelism(1)
.uid("mysql_source");
// 5.提前将hbase中的维度表创建出来
SingleOutputStreamOperator<String> createTableDS = mysqlDS.map(
(MapFunction<String, String>) jsonStr -> {
// 将jsonStr转换成jsonObj
JSONObject jsonObj = JSON.parseObject(jsonStr);
// 获取对配置表的操作
String op = jsonObj.getString("op");
if ("r".equals(op) || "c".equals(op)) {
// 获取after属性的值
JSONObject afterObject = jsonObj.getJSONObject("after");
String sinkTable = afterObject.getString("sink_table");
String sinkFamily = afterObject.getString("sink_family");
if (StringUtils.isEmpty(sinkFamily)) {
sinkFamily = "info";
}
System.out.println("在Hbase中创建表:" + sinkTable);
HbaseUtil.createTable(TmsConfig.HBASE_NAMESPACE, sinkTable, sinkFamily.split(","));
}
return jsonStr;
});
// 6.对配置数据进行广播
MapStateDescriptor<String, TmsConfigDimBean> mapStateDescriptor
= new MapStateDescriptor<>("mapStateDescriptor", String.class, TmsConfigDimBean.class);
BroadcastStream<String> broadcastDS = createTableDS.broadcast(mapStateDescriptor);
// 7.将主流和广播流进行关联--connect
BroadcastConnectedStream<JSONObject, String> connectDS = jsonObjDS.connect(broadcastDS);
// 8.对关联之后的数据进行处理
SingleOutputStreamOperator<JSONObject> dimDS = connectDS.process(
new MyBroadcastProcessFunction(mapStateDescriptor, args)
);
// 9.将数据保存到Hbase中
dimDS.print(">>>");
dimDS.addSink(new DimSinkFunction());
env.execute();
}
}
我们根据dim的调用顺序,来展示需要的代码。
4.KafkaUtil.java
第一步我们从kafka读取数据,之前我们已经在KafkaUtil中完成的sink函数的抽取,现在我们完成source的操作
package com.atguigu.tms.realtime.utils;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.io.IOException;
public class KafkaUtil {
private static final String KAFKA_SERVER = "hadoop102:9092,hadoop103:9092,hadoop104:9092";
public static KafkaSink<String> getKafkaSink(String topic, String transIdPrefix, String[] args) {
// 将命令行参数对象封装为 ParameterTool 类对象
ParameterTool parameterTool = ParameterTool.fromArgs(args);
// 提取命令行传入的 key 为 topic 的配置信息,并将默认值指定为方法参数 topic
// 当命令行没有指定 topic 时,会采用默认值
topic = parameterTool.get("topic", topic);
// 如果命令行没有指定主题名称且默认值为 null 则抛出异常
if (topic == null) {
throw new IllegalArgumentException("主题名不可为空:命令行传参为空且没有默认值!");
}
// 获取命令行传入的 key 为 bootstrap-servers 的配置信息,并指定默认值
String bootstrapServers = parameterTool.get("bootstrap-severs", KAFKA_SERVER);
// 获取命令行传入的 key 为 transaction-timeout 的配置信息,并指定默认值
String transactionTimeout = parameterTool.get("transaction-timeout", 15 * 60 * 1000 + "");
return KafkaSink.<String>builder()
.setBootstrapServers(bootstrapServers)
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic(topic)
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setTransactionalIdPrefix(transIdPrefix)
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, transactionTimeout)
.build();
}
public static KafkaSink<String> getKafkaSink(String topic, String[] args) {
return getKafkaSink(topic, topic + "_trans", args);
}
//获取KafkaSource(新增代码)
public static KafkaSource<String> getKafkaSource(String topic,String groupID,String[] args){
// 将命令行参数对象封装为 ParameterTool 类对象
ParameterTool parameterTool = ParameterTool.fromArgs(args);
// 提取命令行传入的 key 为 topic 的配置信息,并将默认值指定为方法参数 topic
// 当命令行没有指定 topic 时,会采用默认值
topic = parameterTool.get("topic", topic);
// 如果命令行没有指定主题名称且默认值为 null 则抛出异常
if (topic == null) {
throw new IllegalArgumentException("主题名不可为空:命令行传参为空且没有默认值!");
}
// 获取命令行传入的 key 为 bootstrap-servers 的配置信息,并指定默认值
String bootstrapServers = parameterTool.get("bootstrap-severs", KAFKA_SERVER);
// 获取命令行传入的 key 为 transaction-timeout 的配置信息,并指定默认值
return KafkaSource.<String>builder()
.setBootstrapServers(KAFKA_SERVER)
.setTopics(topic)
.setGroupId(groupID)
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
// 注意SimpleStringSchema无法处理空值,需要自定义反序列化
//.setValueOnlyDeserializer(new SimpleStringSchema())
.setValueOnlyDeserializer(new DeserializationSchema<String>() {
@Override
public String deserialize(byte[] message) throws IOException {
if (message != null) {
return new String(message);
}
return null;
}
@Override
public boolean isEndOfStream(String s) {
return false;
}
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(String.class);
}
})
.build();
}
}
5.CreateEnvUtil.java
配置表信息我们存储在MySQL中,所以我们要先写入数据库
创建一个新数据库。

运行sql文件
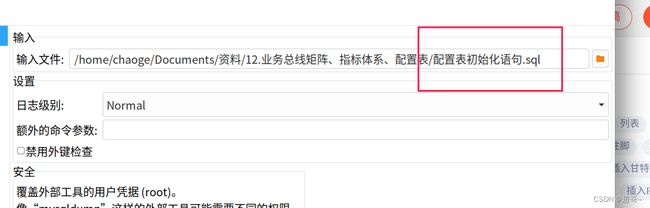

然后我们从MySQL中读取配置表信息
package com.atguigu.tms.realtime.utils;
import com.esotericsoftware.minlog.Log;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.source.MySqlSourceBuilder;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.connect.json.DecimalFormat;
import org.apache.kafka.connect.json.JsonConverterConfig;
import java.util.HashMap;
public class CreateEnvUtil {
public static StreamExecutionEnvironment getStreamEnv(String[] args) {
// 1.1 指定流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.检查点相关设置
// 2.1 开启检查点
env.enableCheckpointing(6000L, CheckpointingMode.EXACTLY_ONCE);
// 2.2 设置检查点的超时时间
env.getCheckpointConfig().setCheckpointTimeout(120000L);
// 2.3 设置job取消之后 检查点是否保留
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 2.4 设置两个检查点之间的最小时间间隔
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000L);
// 2.5 设置重启策略
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.days(1), Time.seconds(3)));
// 2.6 设置状态后端
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("hdfs://hadoop102:8020/tms/ck");
// 2.7 设置操作hdfs用户
// 获取命令行参数
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hdfsUserName = parameterTool.get("hadoop-user-name", "atguigu");
System.setProperty("HADOOP_USER_NAME", hdfsUserName);
return env;
}
// 修改后的函数 添加了config_dim读取
public static MySqlSource<String> getMysqlSource(String option, String serverId, String[] args) {
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String mysqlHostname = parameterTool.get("hadoop-user-name", "hadoop102");
int mysqlPort = Integer.parseInt(parameterTool.get("mysql-port", "3306"));
String mysqlUsername = parameterTool.get("mysql-username", "root");
String mysqlPasswd = parameterTool.get("mysql-passwd", "000000");
option = parameterTool.get("start-up-option", option);
serverId = parameterTool.get("server-id", serverId);
// 创建配置信息 Map 集合,将 Decimal 数据类型的解析格式配置 k-v 置于其中
HashMap config = new HashMap<>();
config.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, DecimalFormat.NUMERIC.name());
// 将前述 Map 集合中的配置信息传递给 JSON 解析 Schema,该 Schema 将用于 MysqlSource 的初始化
JsonDebeziumDeserializationSchema jsonDebeziumDeserializationSchema =
new JsonDebeziumDeserializationSchema(false, config);
MySqlSourceBuilder<String> builder = MySqlSource.<String>builder()
.hostname(mysqlHostname)
.port(mysqlPort)
.username(mysqlUsername)
.password(mysqlPasswd)
.deserializer(jsonDebeziumDeserializationSchema);
switch (option) {
// 读取事实数据
case "dwd":
String[] dwdTables = new String[]{
"tms.order_info",
"tms.order_cargo",
"tms.transport_task",
"tms.order_org_bound"};
return builder
.databaseList("tms")
.tableList(dwdTables)
.startupOptions(StartupOptions.latest())
.serverId(serverId)
.build();
// 读取维度数据
case "realtime_dim":
String[] realtimeDimTables = new String[]{
"tms.user_info",
"tms.user_address",
"tms.base_complex",
"tms.base_dic",
"tms.base_region_info",
"tms.base_organ",
"tms.express_courier",
"tms.express_courier_complex",
"tms.employee_info",
"tms.line_base_shift",
"tms.line_base_info",
"tms.truck_driver",
"tms.truck_info",
"tms.truck_model",
"tms.truck_team"};
return builder
.databaseList("tms")
.tableList(realtimeDimTables)
.startupOptions(StartupOptions.initial())
.serverId(serverId)
.build();
case "config_dim":
return builder
.databaseList("tms_config")
.tableList("tms_config.tms_config_dim")
.startupOptions(StartupOptions.initial())
.serverId(serverId)
.build();
}
Log.error("不支持操作类型");
return null;
}
}
6.HbaseUtil.java
我们获取到配置表信息后,根据配置表信息,把需要的hbase表创建出来
package com.atguigu.tms.realtime.utils;
import com.atguigu.tms.realtime.commom.TmsConfig;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HbaseUtil {
private static Connection conn;
static {
try {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", TmsConfig.hbase_zookeeper_quorum);
conn = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 创建表
public static void createTable(String nameSpace, String tableName, String... families) {
Admin admin = null;
try {
if (families.length < 1) {
System.out.println("至少需要一个列族");
return;
}
admin = conn.getAdmin();
// 判断表是否存在
if (admin.tableExists(TableName.valueOf(nameSpace, tableName))) {
System.out.println(nameSpace + ":" + tableName + "已存在");
return;
}
TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(TableName.valueOf(nameSpace, tableName));
// 指定列族
for (String family : families) {
ColumnFamilyDescriptor familyDescriptor = ColumnFamilyDescriptorBuilder
.newBuilder(Bytes.toBytes(family)).build();
builder.setColumnFamily(familyDescriptor);
}
admin.createTable(builder.build());
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
// 向hbase插入对象
public static void putPow(String namespace, String tableName, Put put) {
BufferedMutator mutator = null;
try {
BufferedMutatorParams params = new BufferedMutatorParams(TableName.valueOf(namespace, tableName));
params.writeBufferSize(5 * 1024 * 1024);
params.setWriteBufferPeriodicFlushTimeoutMs(3000L);
mutator = conn.getBufferedMutator(params);
mutator.mutate(put);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if (mutator != null) {
try {
mutator.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
7.TmsConfigDimBean.java
我们将需要的dim层的TmsConfig抽取成一个Bean方便后边多次调用
package com.atguigu.tms.realtime.beans;
import lombok.Data;
@Data
public class TmsConfigDimBean {
// 数据源表表名
String sourceTable;
// 目标表表名
String sinkTable;
// 目标表表名
String sinkFamily;
// 需要的字段列表
String sinkColumns;
// 需要的主键
String sinkPk;
}
这里使用了lombok函数代替set/get操作,所以需要安装一个插件。
8.MyBroadcastProcessFunction.java
MyBroadcastProcessFunction继承了BroadcastProcessFunction,并进行了更多的自定义编写
package com.atguigu.tms.realtime.app.func;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.tms.realtime.beans.TmsConfigDimBean;
import com.atguigu.tms.realtime.utils.DateFormatUtil;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
import java.sql.*;
import java.util.*;
// 自定义类 完成主流和广播流的处理
public class MyBroadcastProcessFunction extends BroadcastProcessFunction<JSONObject, String, JSONObject> {
private MapStateDescriptor<String, TmsConfigDimBean> mapStateDescriptor;
private Map<String, TmsConfigDimBean> configMap = new HashMap<>();
private String username;
private String password;
public MyBroadcastProcessFunction(MapStateDescriptor<String, TmsConfigDimBean> mapStateDescriptor, String[] args) {
this.mapStateDescriptor = mapStateDescriptor;
ParameterTool parameterTool = ParameterTool.fromArgs(args);
this.username = parameterTool.get("mysql-username", "root");
this.password = parameterTool.get("mysql-password", "000000");
}
@Override
public void open(Configuration parameters) throws Exception {
// 将配置表中的数据进行预加载-JDBC
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://hadoop102:3306/tms_config?useSSL=false&useUnicode=true" +
"&user=" + username + "&password=" + password +
"&charset=utf8&TimeZone=Asia/Shanghai";
Connection conn = DriverManager.getConnection(url);
PreparedStatement ps = conn.prepareStatement("select * from tms_config.tms_config_dim");
ResultSet rs = ps.executeQuery();
ResultSetMetaData metaData = rs.getMetaData();
while (rs.next()) {
JSONObject jsonObj = new JSONObject();
for (int i = 1; i <= metaData.getColumnCount(); i++) {
String columnName = metaData.getColumnName(i);
Object columValue = rs.getObject(i);
jsonObj.put(columnName, columValue);
}
TmsConfigDimBean tmsConfigDimBean = jsonObj.toJavaObject(TmsConfigDimBean.class);
configMap.put(tmsConfigDimBean.getSourceTable(), tmsConfigDimBean);
}
rs.close();
ps.close();
conn.close();
super.open(parameters);
}
@Override
public void processElement(JSONObject jsonObj, BroadcastProcessFunction<JSONObject, String, JSONObject>.ReadOnlyContext ctx, Collector<JSONObject> out) throws Exception {
// 获取操作的业务数据库的表名
String table = jsonObj.getString("table");
// 获取广播状态
ReadOnlyBroadcastState<String, TmsConfigDimBean> broadcastState = ctx.getBroadcastState(mapStateDescriptor);
// 根据操作的业务数据库的表名 到广播状态中获取对应的配置信息
TmsConfigDimBean tmsConfigDimBean;
if ((tmsConfigDimBean = broadcastState.get(table)) != null || (tmsConfigDimBean = configMap.get(table)) != null) {
// 如果对应的配置信息不为空 是维度信息
// 获取after对象,对应的是影响的业务数据表中的一条记录
JSONObject afterJsonObj = jsonObj.getJSONObject("after");
// 数据脱敏
switch (table) {
// 员工表信息脱敏
case "employee_info":
String empPassword = afterJsonObj.getString("password");
String empRealName = afterJsonObj.getString("real_name");
String idCard = afterJsonObj.getString("id_card");
String phone = afterJsonObj.getString("phone");
// 脱敏
empPassword = DigestUtils.md5Hex(empPassword);
empRealName = empRealName.charAt(0) +
empRealName.substring(1).replaceAll(".", "\\*");
//知道有这个操作 idCard是随机生成的,和标准的格式不一样 所以这里注释掉
// idCard = idCard.matches("(^[1-9]\\d{5}(18|19|([23]\\d))\\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\\d{3}[0-9Xx]$)|(^[1-9]\\d{5}\\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\\d{2}$)")
// ? DigestUtils.md5Hex(idCard) : null;
phone = phone.matches("^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$")
? DigestUtils.md5Hex(phone) : null;
afterJsonObj.put("password", empPassword);
afterJsonObj.put("real_name", empRealName);
afterJsonObj.put("id_card", idCard);
afterJsonObj.put("phone", phone);
break;
// 快递员信息脱敏
case "express_courier":
String workingPhone = afterJsonObj.getString("working_phone");
workingPhone = workingPhone.matches("^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$")
? DigestUtils.md5Hex(workingPhone) : null;
afterJsonObj.put("working_phone", workingPhone);
break;
// 卡车司机信息脱敏
case "truck_driver":
String licenseNo = afterJsonObj.getString("license_no");
licenseNo = DigestUtils.md5Hex(licenseNo);
afterJsonObj.put("license_no", licenseNo);
break;
// 卡车信息脱敏
case "truck_info":
String truckNo = afterJsonObj.getString("truck_no");
String deviceGpsId = afterJsonObj.getString("device_gps_id");
String engineNo = afterJsonObj.getString("engine_no");
truckNo = DigestUtils.md5Hex(truckNo);
deviceGpsId = DigestUtils.md5Hex(deviceGpsId);
engineNo = DigestUtils.md5Hex(engineNo);
afterJsonObj.put("truck_no", truckNo);
afterJsonObj.put("device_gps_id", deviceGpsId);
afterJsonObj.put("engine_no", engineNo);
break;
// 卡车型号信息脱敏
case "truck_model":
String modelNo = afterJsonObj.getString("model_no");
modelNo = DigestUtils.md5Hex(modelNo);
afterJsonObj.put("model_no", modelNo);
break;
// 用户地址信息脱敏
case "user_address":
String addressPhone = afterJsonObj.getString("phone");
addressPhone = addressPhone.matches("^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$")
? DigestUtils.md5Hex(addressPhone) : null;
afterJsonObj.put("phone", addressPhone);
break;
// 用户信息脱敏
case "user_info":
String passwd = afterJsonObj.getString("passwd");
String realName = afterJsonObj.getString("real_name");
String phoneNum = afterJsonObj.getString("phone_num");
String email = afterJsonObj.getString("email");
// 脱敏
passwd = DigestUtils.md5Hex(passwd);
if (StringUtils.isNotEmpty(realName)) {
realName = DigestUtils.md5Hex(realName);
afterJsonObj.put("real_name", realName);
}
phoneNum = phoneNum.matches("^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\\d{8}$")
? DigestUtils.md5Hex(phoneNum) : null;
email = email.matches("^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\\.[a-zA-Z0-9_-]+)+$")
? DigestUtils.md5Hex(email) : null;
afterJsonObj.put("birthday", DateFormatUtil.toDate(afterJsonObj.getInteger("birthday") * 24 * 60 * 60 * 1000L));
afterJsonObj.put("passwd", passwd);
afterJsonObj.put("phone_num", phoneNum);
afterJsonObj.put("email", email);
break;
}
// 过滤不需要的维度属性
String sinkColumns = tmsConfigDimBean.getSinkColumns();
filterColum(afterJsonObj, sinkColumns);
// 补充输出目的的表名
String sinkTable = tmsConfigDimBean.getSinkTable();
afterJsonObj.put("sink_table", sinkTable);
// 补充rowKey
String sinkPk = tmsConfigDimBean.getSinkPk();
afterJsonObj.put("sink_pk", sinkPk);
// 将维度数据传递
out.collect(afterJsonObj);
}
}
private void filterColum(JSONObject afterJsonObj, String sinkColumns) {
String[] fieldArr = sinkColumns.split(",");
List<String> fieldList = Arrays.asList(fieldArr);
Set<Map.Entry<String, Object>> entrySet = afterJsonObj.entrySet();
entrySet.removeIf(entry -> !fieldList.contains(entry.getKey()));
}
@Override
public void processBroadcastElement(String jsonStr, BroadcastProcessFunction<JSONObject, String, JSONObject>.Context ctx, Collector<JSONObject> out) throws Exception {
JSONObject jsonObj = JSON.parseObject(jsonStr);
// 获取广播状态
BroadcastState<String, TmsConfigDimBean> broadcastState = ctx.getBroadcastState(mapStateDescriptor);
// 获取对配置表的操作类型
String op = jsonObj.getString("op");
if ("d".equals(op)) {
String sourceTable = jsonObj.getJSONObject("before").getString("source_table");
broadcastState.remove(sourceTable);
configMap.remove(sourceTable);
} else {
TmsConfigDimBean configDimBean = jsonObj.getObject("after", TmsConfigDimBean.class);
String sourceTable = configDimBean.getSourceTable();
broadcastState.put(sourceTable, configDimBean);
configMap.put(sourceTable, configDimBean);
}
}
}
9.DimSinkFunction.java
DimSinkFunction实现了SinkFunction接口。重写了SinkFunction函数。
package com.atguigu.tms.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.tms.realtime.commom.TmsConfig;
import com.atguigu.tms.realtime.utils.HbaseUtil;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.hadoop.hbase.client.Put;
import java.util.Map;
import java.util.Set;
public class DimSinkFunction implements SinkFunction<JSONObject> {
public void invoke(JSONObject jsonObj, Context context) throws Exception {
// 获取输出目的地表名和rowKey
String sinkTable = jsonObj.getString("sink_table");
String sinkPk = jsonObj.getString("sink_pk");
jsonObj.remove("sink_table");
jsonObj.remove("sink_pk");
// 获取json中的每一个键值对
Set<Map.Entry<String, Object>> entrySet = jsonObj.entrySet();
Put put = new Put(jsonObj.getString(sinkPk).getBytes());
for (Map.Entry<String, Object> entry : entrySet) {
if (!sinkPk.equals(entry.getKey())) {
put.addColumn("info".getBytes(),entry.getKey().getBytes(),entry.getValue().toString().getBytes());
}
}
System.out.println("向hbase表中插入数据");
HbaseUtil.putPow(TmsConfig.HBASE_NAMESPACE,sinkTable,put);
}
}
10.TmsConfig.java
TmsConfig存储一些,以上代码常用的常量参数。
package com.atguigu.tms.realtime.commom;
// 物流实时数仓常量类
public class TmsConfig {
// zk的地址
public static final String hbase_zookeeper_quorum="hadoop102,hadoop103,hadoop104";
// hbase的namespace
public static final String HBASE_NAMESPACE="tms_realtime";
}
至此,所有的代码部分编写完成。
二、代码测试
1.环境启动
先启动HDFS、ZK、Kafka。
2.清除hbase数据(新安装的不需要)
因为我之前运行过多次,所以数据库里已经有数据了,我的清除掉(生产环境千万不敢这样做)。
删除hdfs的/hbase目录

在zk也删除/hbase
/opt/module/zookeeper/bin/zkCli.sh

现在我们就可以启动hbase了。
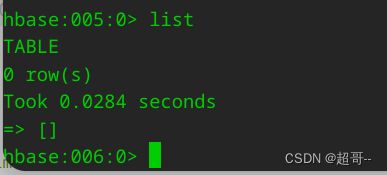
用hbase shell 看一眼

创建我们需要的namespace
create_namespace "tms_realtime"

可以看到现在表是空的。
3.程序启动
我们先启动DIM层,因为第一次启动需要创建hbase表和加载配置表信息。

等他停止打印输出后,代表创建完毕,就可以启动ODS层了。
启动ODS层后,如果Kafka有之前积压的数据,程序会自动拉取,如果没有,我们可以在生成一些。

我在程序写入hbase前添加了一个打印输出,出现这个,代表通道正常,我们在hbase看一下能不能看到数据。
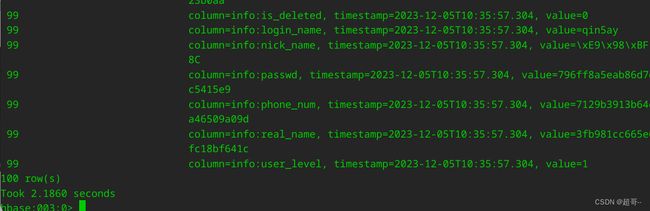
hbase可以正常接受数据。
总结
至此DIM层的搭建已经完成。