开源 | 携程 Redis On Rocks 实践,节省 2/3 Redis成本
作者简介
patpatbear,携程软件技术专家,负责携程缓存内核的维护,热爱开源,专注于高性能、分布式NoSQL系统的建设和应用。
一、背景
redis使用内存作为存储介质,具有良好的性能和低延迟,但其内存容量通常成为瓶颈,且内存价格较高,导致redis使用成本较高。
随着SSD磁盘性能的不断提高,NVMe SSD的随机读写延迟也仅有几十微秒,与redis的固有延迟(100~200us)相当,用SSD作为存储介质也可以达到较低的延迟,同时节省成本。
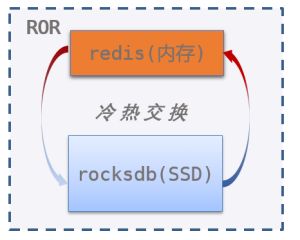
因此我们研发了ROR(Redis-On-Rocks)产品,通过对redis内核增强以支持数据冷热交换,使用磁盘扩展缓存容量,可节省约2/3成本,而性能也能满足大多数业务需求。
二、ROR简介
ROR核心思路很简单:在redis codebase基础上扩展冷热交换功能,实现redis数据冷热多级存储,降低缓存的综合使用成本。
ROR将数据分为冷热两部分:
热数据沿用redis引擎,使用内存存储,数据结构和原生redis完全一致
冷数据选用RocksDB引擎,使用磁盘存储,以subkey为粒度存储在RocksDB中
ROR负责冷热数据的交换:
换入(从RocksDB到redis):当客户端访问冷数据,则将RocksDB中的数据换入到redis中,ROR把命令依赖的数据换入到redis,后续命令执行与原生redis一致。
换出(从redis到RocksDB):当内存用量超过maxmemory之后,则将热数据换出到RocksDB中,ROR冷热交换算法采用了redis原生的LFU算法,原本被redis evict的数据将被交换到内存中。
由于ROR继承了redis的数据结构和命令实现,只负责冷热数据交换,因此可以兼容几乎所有的redis命令,可快速跟进redis官方新特性。
三、与RoF对比
从长远发展考虑,redis是事实上的缓存标准,缓存内核基于社区开源redis更便于跟进社区redis演进,因此ROR选择了基于redis基础上扩展冷热交换能力。
RedisLabs的商业产品Redis-on-Flash(RoF)与ROR设计思路类似,但是调研之后,我们发现RoF在成本、通用性、性能等方面并不能满足我们的需求。
3.1 成本
RoF把value保存在磁盘、key保留在内存主表,可以方便地兼容dbsize、scan、randomkey等命令,但占用的内存量会随着dbsize线性上升。
冷数据key保存在内存主表(hashtable),每个key的辅助指针、robj等平均占用约50B,生产String类型平均value大小为512B。从成本的角度看,按照key占内存10%,value占90%计算
换出80%value,可减少72% (80%*90%) 内存
换出80%冷key,可继续减少29% (10%*80%/(100%-72%))内存
因此ROR并不把冷数据的key保存在内存,而是保存到RocksDB中单独的meta column family。
考虑到meta column family访问比较频繁,且只存储type、expire之类的少量元数据,因此用少量内存(block cache)可以缓存多数冷key。
经验证,分配256MB block cache后,把冷数据的key存储到RocksDB并不会降低整体QPS,但会增加IO线程的CPU消耗,由于redis宿主机cpu利用率只有10%,用cpu换内存是可以接受的。
3.2 通用性
为了避免重复缓存,RoF禁用了RocksDB层的table cache和文件系统层的page cache。这意味着访问冷key时必须进行IO操作,因此冷key和热key的访问延迟会有较大区别。
为了提高通用性,ROR合理利用RocksDB层的table cache和操作系统层的page cache,尽可能利用未被占用的内存,减少访问冷key和热key之间的延迟差距。
实际上,无论是DBA还是业务方,都很难准确预测缓存集群是否存在明显的冷热特征。ROR适用于通用场景,能够大大减少沟通成本和业务方关于延迟的担忧。
在redis迁移至ROR时,我们并不评估应用程序是否具有冷热特征,只要业务QPS在redis的一半以下,对P99延迟不是非常敏感,就可以将其迁移到ROR。
3.3 性能
RoF按key粒度存储,key与RocksDB key一一对应;而ROR按subkey粒度存储,subkey都与RocksDB key一一对应。
对于HSET、HGET等聚合类型命令,RoF需要换入换出整个key,而ROR只读写必要的subkey,因此读写放大远低于RoF,QPS和延迟也优于RoF。
以下为ROR、RoF在大压力(100线程不限QPS)和普通压力(1000线程10000QPS),读写纯冷数据的QPS和延迟。可以看出:
大压力情况下,ROR HGET、HSET命令QPS约为RoF的2~3倍
普通压力情况下,ROR延迟约300~500us,远低于RoF 14~120ms 延迟
| 场景\方案 | ROR | RoF | |
| HGET | 100thd | QPS=22134 LAT(mean,p99)=4762 27495(us) |
QPS=10195 Latency(mean,p99): 9730 16521(us) |
| 1wqps | QPS=9968 LAT(mean,p99)=343 969(us) |
QPS=9956 Latency(mean,p99): 14270 100746(us) |
|
HSET |
100thd | QPS=26182 Latency(mean,p99): 4034 21802(us) |
QPS=7994 Latency(mean,p99): 12250 27492(us) |
| 1wqps | QPS=9969 Latency(mean,p99): 511 4437(us) |
QPS=7806 Latency(mean,p99): 119396 242467(us) |
|
测试说明:
数据:hash:5,000,000 (key count) * 2KB (per key,5个field,每个filed 400B)
配置:ROR的maxmemory设置为200MB;RoF有最小内存限制,设置为2G
场景:a)100thd:压力测试,100客户端并发,不限速测试;b)1wqps:模拟常规访问,1000客户端,限速1W QPS测试
对于超大的聚合key,RoF将整个key加载到内存中,会有明显的延迟尖刺(可达秒级);而ROR只将必要的subkey换入内存,则不会有明显的延迟尖刺。
多数使用redis的业务对延迟比较敏感,不能接受过大延迟尖刺。
| 场景\方案 | ROR | RoF |
HGET hugehash field |
<1ms | 1.48s |
LPOP hugelist |
<1ms | 0.704s |
测试说明:
hash:共有1,000,000个元素,每个元素128B
list:共有1,000,000个元素,每个元素128B
四、实现方案
4.1 冷热交换
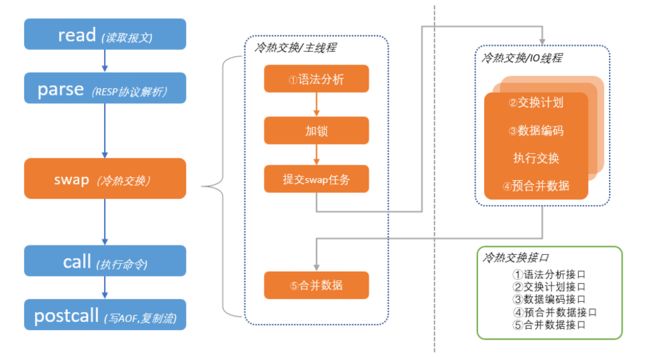
以下是客户端访问到冷key时ROR的处理过程。其中蓝色模块与原生redis相同,橙色模块为ROR新增的冷热交换功能。
总体上ROR先冷热交换(swap),再执行命令处理流程。
冷热交换(swap)过程主要分为以下步骤:
1)语法分析:分析客户端命令涉及哪些key和subkey。比如,可以分析出MGET k1 k2 k3依赖于k1,k2,k3;而HMGET h1 f1 f2 f3,依赖于 h1.{ f1, f2, f3 }。
2)加锁:根据语法分析出的结果,对命令所依赖的key加锁。值得注意的是,这里的锁并不是pthread_mutex之类的线程锁,而是ROR项目实现的一种单线程锁,本质上是一个等待队列,详细介绍参考后续并发控制章节。
3)提交SWAP任务:拿到锁之后,提交swap任务到IO线程组执行RocksDB读写。
4)执行RocksDB读写:IO线程组执行RocksDB读操作。
5)合并数据:将RocksDB读取的数据合并到redis中。
经过swap过程之后,冷数据已经换入到redis,后续执行命令与原生redis一致。
4.2 并发控制
redis架构上为单主线程,而RocksDB提供的是阻塞模式的API,直接使用redis主线程调用RocksDB将极大降低redis的性能。为了提高IO吞吐,ROR使用了额外的IO线程组执行RocksDB读写。由于增加了IO线程组,对于同一key的读写不再是单线程,如果不加控制,那么数据将变得错乱。
为了控制并发,ROR设计实现了一种单线程可重入锁来保证同一时间对同一key只有一个客户端在进行IO交换。这里的锁并不是pthread_mutex这种系统线程锁,其本质是一个等待队列:当key被锁定后,尝试获取该锁的客户端必须等待前序客户端释放锁之后才能获取到key的锁。
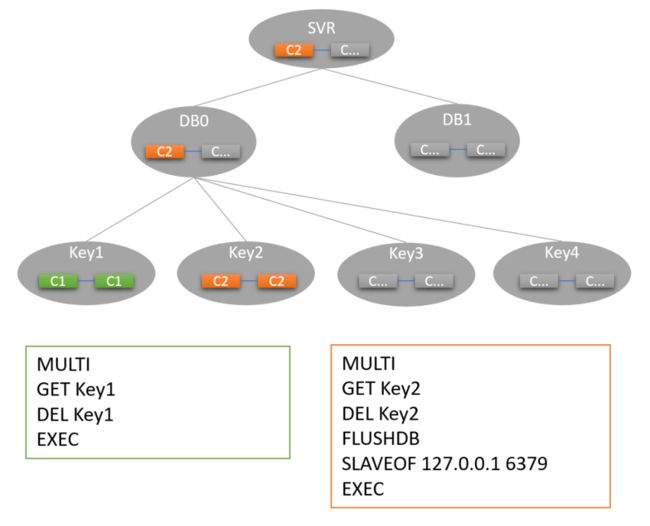
如下图所示,C1、C2、C3三个客户端先后执行了MGET命令,其中Key1、Key2、Key3均为冷数据。
C1依赖Key1、Key2,由于这2个key未被锁定且为冷,因此C1获取到Key1、Key2的锁,并触发了Key1、Key2换入;
C2依赖Key2、Key3,由于Key2被C1锁定,因此C2等待C1执行结束才能获取key2锁;Key3未被锁定且为冷,因此C2获取到了Key2的锁,并触发了Key3换入;
C3依赖Key1、key3,由于Key1、Key3分别被C1、C2锁定,因此C3等待C1、C2执行结束后才能获取Key1、Key3锁。
因此最终换入Key1、Key2、Key3换入后,客户端执行顺序为C1=>C2=>C3。

以上是一个简单的示例,ROR为了实现FLUSHDB/BGSAVE之类涉及整个keyspace的命令并发控制需求,等待队列包含KEY、DB、SVR三种粒度的锁,大粒度的锁需等待细粒度锁释放后才能获得。此外为了确保MULTI/EXEC事务不产生死锁,允许同一个事务重复锁定同一key(亦即可重入)。
如下图所示,C1、C2两个客户端先后发起2个事务。
C1依赖Key1(2次),由于C1在同一事务中依赖Key1(2次)且为冷,因此C1获得Key1锁并触发换入;
C2依赖Key2(2次)、DB0、SVR锁,由于C2在同一事务中依赖Key2(2次)且为冷,因此C2获得Key2锁并触发换入;注意由于C2依赖DB0锁,DB0锁范围大约Key1、Key2,因此只有C1释放Key1之后才能获得DB0锁。
假设Key1先于Key2被换入,Key1换入后,C1事务得到执行并释放Key1锁。
当Key2换入后,C2获得DB0锁以及SVR锁(获得所有锁),C2事务得到执行。
4.3 冷数据存储
与业界多数方案一样,ROR的冷数据存储采用了RocksDB引擎,设计上参考了kvrocks、pika等项目,主要有3个要点:
key存储到RocksDB
subkey与RocksDB KV对应(i.e. 按subkey存储)
lazy删除聚合类型key
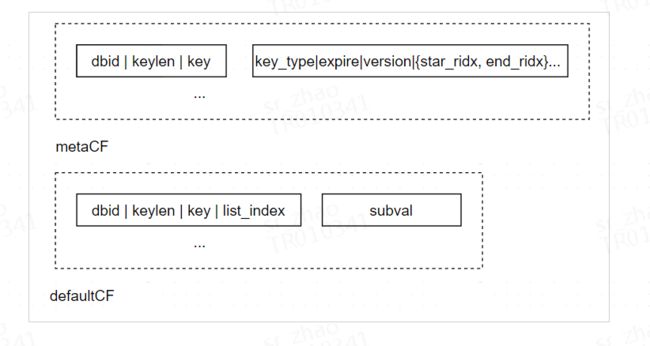
key存储到RocksDB
ROR为了做到内存消耗与dbsize无关,内存中并不会存储冷key,key类型、expire、version等信息会存储到RocksDB的metaCF中。这样设计主要是考虑每个key需要额外消耗约50B,如果dbsize为1亿则需要额外消耗约5GB内存。对dbsize大、value小的集群来讲,额外消耗的内存过多,冷热分离的性价比则不高。
因此ROR和RoF不同,不会把冷key存储在内存中,少量与key相关(scan、randomkey、dbsize)命令,则进行适配性改造。
subkey与RocksDB KV对应
RocksDB的数据类型只有KV,与redis支持hash、set、zset等聚合类型key不能一一对应,因此需要构造redis聚合类型key与RocksDB KV类型之间的对应关系。
最直接的方案是将redis的聚合类型key直接序列化单个为RocksDB KV,但这种方案的缺点非常明显,即HGET hash subkey只依赖单个subkey的命令,也需要将整个聚合类型key换入到内存,这会造成严重的读写放大。
因此ROR将聚合类型的subkey存储为RocksDB KV,换入聚合类型数据冷key只需要换入必要的subkey。
lazy删除聚合类型key
对于聚合类型key而言,每个subkey对应RocksDB KV,ROR删除聚合key需要删除掉所有的subkey,直接从RocksDB中迭代删除复杂度为O(N),会造成延迟尖刺。
参考pika、kvrocks的设计,聚合类型key都有版本号,ROR删除聚合key时,只删掉metaCF的元数据,而其他subkey则在RocksDB compaction中通过compaction filter逐渐过滤删除。
hash/set/zset编码
以下是hash/set类型的编码格式:
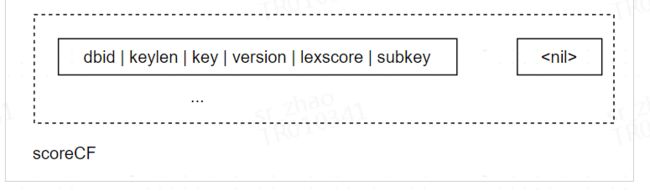
每个hash/set在metaCF有1个RocksDB KV,记录了类型、超时时间、版本以及subkey数量。
每个hash/set在defaultCF有N个RocksDB KV,每个subkey对应一个。由于每个subkey都记录了对应的version,因此删除聚合key只需要把metaCF的KV删掉即完成lazy删除。

zset类型的编码格式类似,只多了scoreCF记录zset的score排序。
list编码
由于与hash/set/zset的操作差别较大,list数据模型设计上也有所差别。设计上,ROR内存中的list仍复用redis数据结构,且list可能只有部分subkey在内存中。
模型上list的设计如下:
list为任意段rockslist(冷)和memlist(热)的组合
list元素要么在memlist、要么在rockslist,memlist没有交集
分段信息存储在listObjectMeta.segments中,segments的每个元素表示一段,记录了每段的类型以及长度。
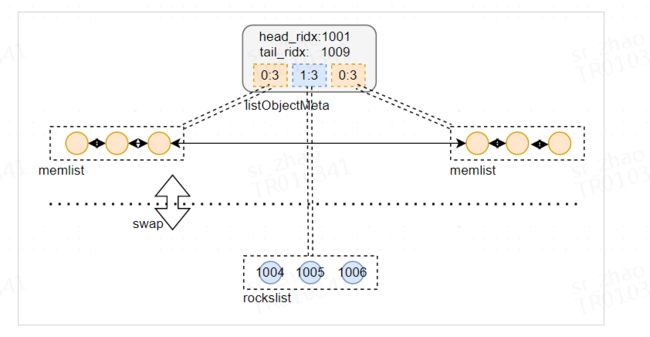
rockslist也按subkey粒度存储在RocksDB中。
4.4 cuckoo filter减少IO
前面提到ROR为了做到内存用量与dbsize无关,key元信息不存储在内存中,因此如果客户端访问的key不是热数据,则必须查询RocksDB才能确认key是否存在:对于key存在的情况,读RocksDB并换入冷数据是必要的;但如果key不存在,则读RocksDB是非必要的。特别是当业务keyspace miss率高的情况(比如重复读不存在的key),存在大量的非必要IO情况,降低了整体性能。
对于过滤不存在key问题,用bloom filter能以8~10 bit per key的内存取得很好的过滤效果,但由于bloom filter不支持删除,而ROR的keyspace始终处于动态变化中,因此bloom filter功能上无法满足需求。
经过调研之后,我们发现cuckoo filter可以很好地满足我们的需求,支持删除并且内存消耗量仅需8 bit per key即可满足ROR过滤准确度需求。
由于无法预测准确到key数量,ROR实现cuckoo filter时采用了多个容量指数增长的cuckoo filter组成的cascading cuckoo filter。
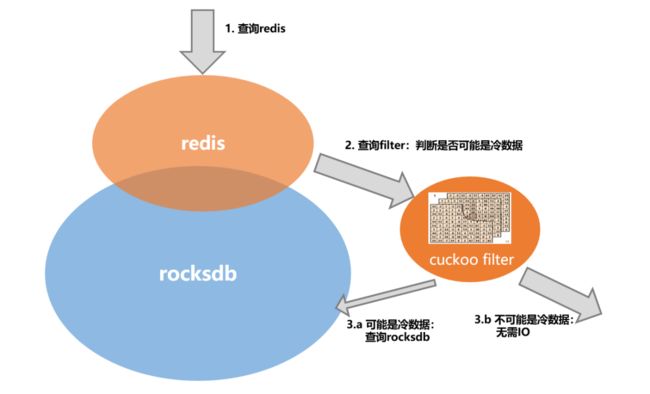
经过测试我们发现,对于keyspace miss场景,cuckoo filter可以将ROR的QPS从5W提升到6W左右,吞吐提升约20%;对于keyspace hit场景则无明显影响。
4.5 兼容redis复制
ROR的复制协议完全兼容redis原生复制,全量复制采用RDB格式,增量复制使用RESP协议。由于完全兼容redis原生复制协议,ROR可以直接对接xpipe,具备DR能力。
流式全量复制
ROR与Redis全量复制主要流程相同:master fork出child进程,由child进程打RDB。ROR由于有冷热两类数据,因此生成RDB的与原生Redis有区别:
热数据生成RDB方案不变
冷数据先获取RocksDB CHECKPOINT,然后SCAN冷数据转换为RDB格式
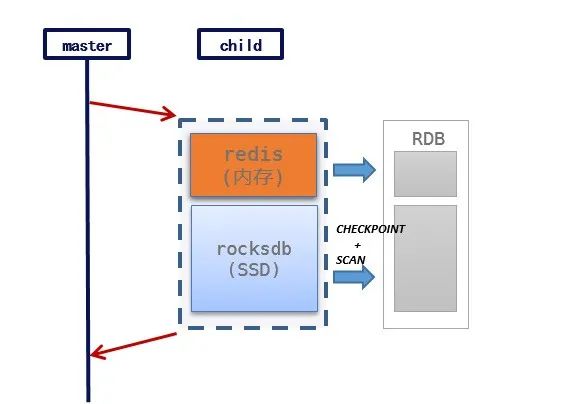
冷数据(RocksDB部分)生成RDB的一种方案是将冷key临时加载内存,复用redis的序列化方法构造RDB,但这种方案加载全部冷key会消耗大量CPU,当遇到redis宿主机宕机重启,大量redis全量同步争用CPU将导致全量同步时间过长。
出于性能考虑,ROR构造RDB并不加载冷key,而是采用了流式构造RDB的方案:使用一个IO线程迭代RocksDB全量数据,并将迭代的数据流式append到RDB中。需要注意的是,流式构造RDB依赖于ROR在存储设计上将同一个聚合类型key的subkey存储在RocksDB相邻位置。
实现层面,流式构造RDB方案避免了把key加载到内存并跳过redis层重新编码,直接将RockDB数据流式填充到rdb,全量复制速度315MB/s,可以达到redis复制性能(390MB/s)的80%左右。
并发增量复制
redis增量复制过程中,master通过单个复制客户端推送复制流到slave。由于复制客户端只有1个(冷热交换最大并发为1)如果ROR slave直接用复制客户端交换数据,会出现slave复制无法跟上master写入。
为了提高复制交换性能,ROR将从复制客户端将收到的命令分发到多个worker客户端,并发执行交换。
如果worker客户端在交换结束后直接调用命令,那么slave上命令执行的顺序可能与master不同,造成主从数据不一致。
ROR采用的方案下,worker客户端交换结束后并不立即执行命令,而是等到前序命令全部执行完之后在执行。由于slave执行增量复制命令与master向下传播的复制流的命令顺序一致,可以确保主从数据一致。
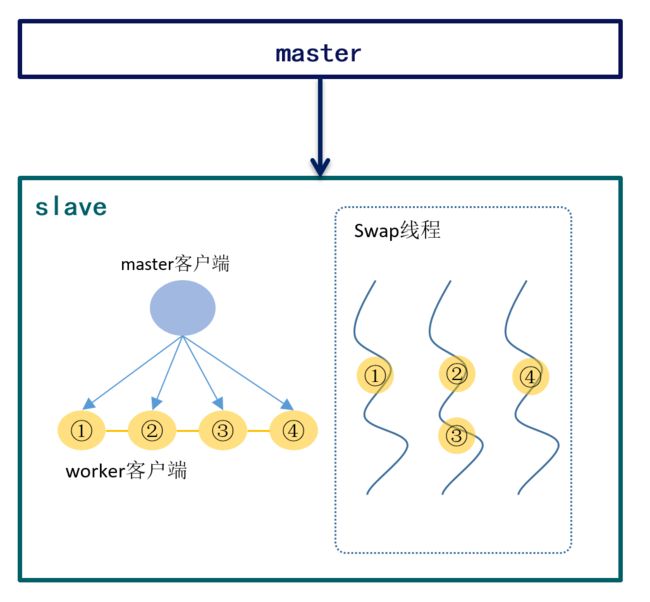
如上图所示,①、②、④在并发执行IO操作,虽然②、④可能在①之前完成数据交换,但一定会等到①完成IO后再执行命令。
ROR增量复制并发改造后,slave处理复制命令速度从几千QPS提升到大于master的最大写入速度(5~10W QPS左右,与冷热数据占比相关)。
五、生产实践
从经验来看,多数redis集群QPS较低但内存用量较大,redis宿主机通常因为达到内存上限触发扩容,但CPU资源则比较空闲,比如携程内redis宿主机平均CPU使用率约15%,但平均内存使用率达到50%。
ROR采用磁盘增加了缓存容量,能容纳更多的数据量,但RocksDB引擎的compaction和压缩会消耗更多的CPU资源,因此ROR可以认为是用空闲的CPU换内存的成本解决方案。
成本方面,经验数据显示1个ROR实例可容纳3个redis实例的数据,因此redis迁ROR能节省2/3的成本。
目前在ROR在生产部署了几万个实例。由于海外公有云内存单价高,已基本全部部署为ROR,每年可以节省成本上千万元。
性能方面,从吞吐量考虑,携程内部redis集群高QPS占比较低,远低于ROR的QPS上限(参考上文性能数据)。
从延迟考虑,ROR设计上合理利用缓存,按subkey粒度存储,且硬件上nvme SSD延迟只有几十微秒,因此与Redis相比延迟并没有特别明显的上升。
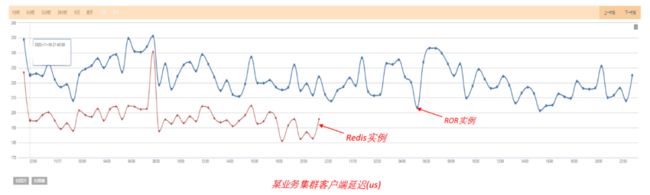
以下为一个典型redis集群迁移ROR后延迟对比,其中80%为冷数据、20%为热数据,迁移前后客户端访问延迟从200us变为220us左右。
六、项目开源与未来计划
6.1 项目开源
目前ROR(Redis-On-Rocks)已开源,采用与Redis一致的BSD协议。
6.2 未来计划
1)提升单实例QPS
部分业务场景(比如大数据相关业务)不但数据量大,而且QPS也比较高,这些集群可能出现ROR主线程100%情况。针对这些场景,我们考虑从软硬件2个层面优化,软件层面考虑减少冷热交换损耗、自动化pipeline减少网络CPU消耗;硬件层面使用更高主频的CPU提升上限。
2)完善数据结构支持
部分使用频次较少的数据结构待优化,比如:bitmap目前按照string处理,读写放大比较大,待优化性能;stream目前尚未支持,使用内存存储,待支持。
3)减少全量同步
国内与海外的带宽比较小,如果出现全量同步则海外业务受影响时间会比较久。随着随着海外部署量上升,这个问题的影响性逐步增大,后续ROR考虑提供可用性与一致性的选项,允许少量数据不一致的情况下增量同步。
【推荐阅读】
携程MySQL迁移OceanBase最佳实践
携程机票跨端 Kotlin DSL 数据库框架 SQLlin
携程酒店慢查询治理之路
携程Dynamo风格存储的落地实践

“携程技术”公众号
分享,交流,成长