day13 黑色星期五案例
代码,笔记,数据集文件放在gitee
点这里进入gitee
https://gitee.com/jiangxun07/python-data-analysis.git
黑色星期五(美国商场的圣诞促销)是美国人大采购的一天,让我们根据BlackFriday.csv分析数据结论。
文章目录
- 1.分析方向
-
- 1.1销售画像
- 2.原始数据
-
- 2.1数据信息
- 2.2 数据清洗
- 3.数据分析
-
- 3.1销售情况
- 4.用户画像分析
-
- 4.1性别对消费能力的影响
- 4.2年龄对消费的影响
- 4.3城市字段分析
- 4.4职业分析
- 5.总结
1.分析方向
1.1销售画像
- 销售画像
- 销售情况
- 用户情况
- 商品情况
- 用户画像
- 性别分布和消费情况
- 年龄分布和消费情况
- 不同城市用户分布和消费情况
- 商品画像
- 最受喜爱的商品分布和消费情况
- 不同年龄段喜欢的商品分布和消费情况
- 男女喜爱的商品分布和消费情况
2.原始数据
import pandas as pd
df=pd.read_csv('./BlackFriday.csv')
df
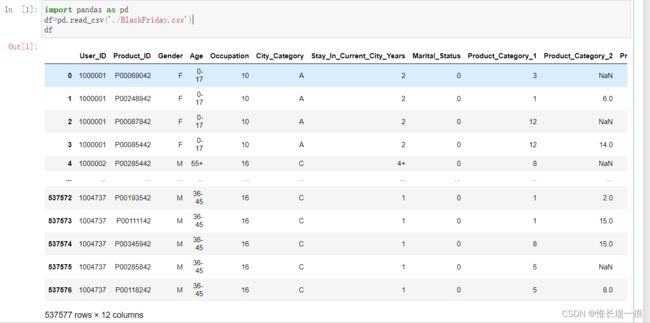
一共是五十多万行
2.1数据信息
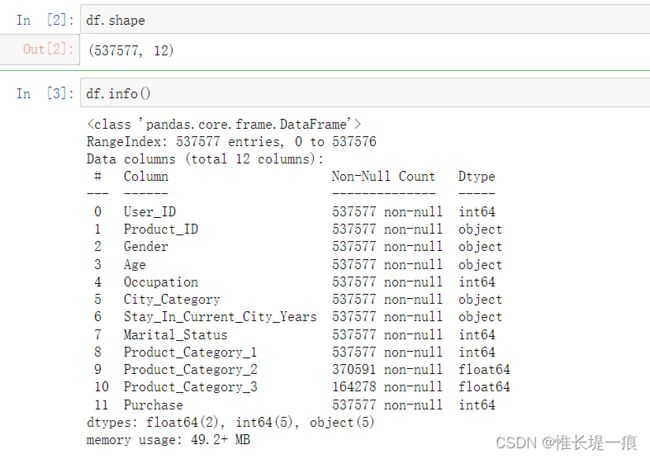
df.shape
df.info()
2.2 数据清洗
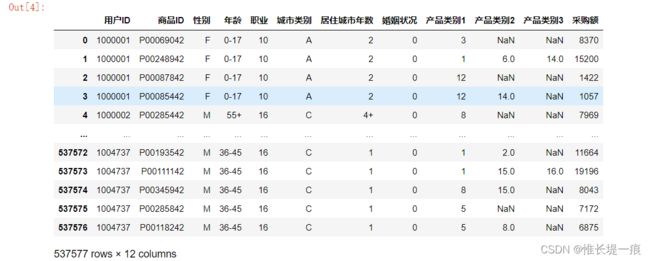
重命名第一行
df=df.rename(columns={
'User_ID': '用户ID',
'Product_ID': '商品ID',
'Gender': '性别',
'Age': '年龄',
'Occupation': '职业',
'City_Category': '城市类别',
'Stay_In_Current_City_Years': '居住城市年数',
'Marital_Status': '婚姻状况',
'Product_Category_1': '产品类别1',
'Product_Category_2': '产品类别2',
'Product_Category_3': '产品类别3',
'Purchase': '采购额'
})
df
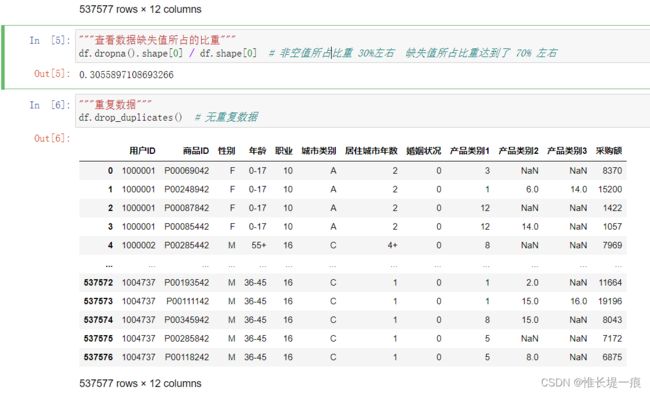
"""查看数据缺失值所占的比重"""
df.dropna().shape[0] / df.shape[0] # 非空值所占比重 30%左右 缺失值所占比重达到了 70% 左右
"""重复数据"""
df.drop_duplicates() # 无重复数据
3.数据分析
3.1销售情况
"""销售总额"""
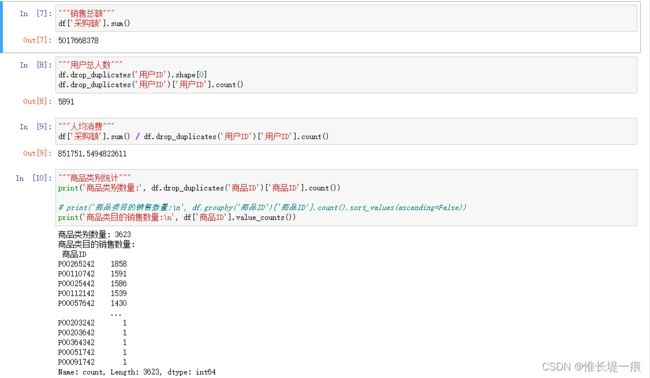
df['采购额'].sum()
"""用户总人数"""
df.drop_duplicates('用户ID').shape[0]
df.drop_duplicates('用户ID')['用户ID'].count()
"""人均消费"""
df['采购额'].sum() / df.drop_duplicates('用户ID')['用户ID'].count()
"""商品类别统计"""
print('商品类别数量:', df.drop_duplicates('商品ID')['商品ID'].count())
# print('商品类目的销售数量:\n', df.groupby('商品ID')['商品ID'].count().sort_values(ascending=False))
print('商品类目的销售数量:\n', df['商品ID'].value_counts())
4.用户画像分析
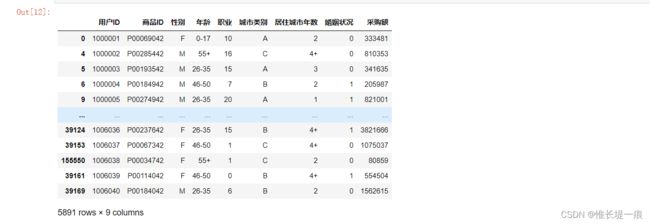
# 根据"用户ID"去重, 取出来想要的列, 然后用"用户ID"做排序
df_dd = df.drop_duplicates('用户ID')[
['用户ID', '商品ID', '性别', '年龄', '职业', '城市类别', '居住城市年数', '婚姻状况']
].sort_values('用户ID')
df

# 先根据"用户ID"做分组, 计算每个用户的采购总额, 新增一列采购额的数据
df_dd['采购额'] = df.groupby(by='用户ID')['采购额'].sum().sort_index().values
df_dd
df.groupby(by='用户ID').get_group(1000002)['采购额'].sum()

4.1性别对消费能力的影响
df_dd['性别'].value_counts()
x_data = ['男性', '女性']
sex_data = df_dd['性别'].value_counts().tolist()
data = list(zip(x_data, sex_data))
data

from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie()
.add("", data)
.set_global_opts(title_opts=opts.TitleOpts(title="男女性别所占比例"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}--{d}%"))
)
c.render_notebook()

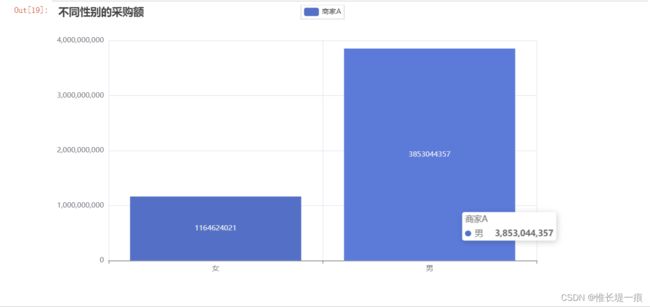
"""不同性别的采购额"""
s_gender = df_dd.groupby('性别')['采购额'].sum()
s_gender

from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c = (
Bar()
.add_xaxis(['女', '男'])
.add_yaxis("商家A", s_gender.values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="不同性别的采购额"))
)
c.render_notebook()
## 婚姻状况对消费能力的影响
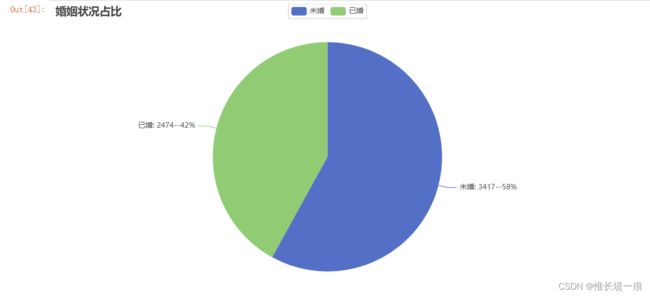
df_cc = df_dd['婚姻状况'].value_counts()
df_cc
"""婚姻状况所占比重"""
from pyecharts import options as opts
from pyecharts.charts import Pie
x = ['未婚', '已婚']
y = df_cc.values.tolist()
data = list(zip(x, y))
c = (
Pie()
.add("", data)
.set_global_opts(title_opts=opts.TitleOpts(title="婚姻状况占比"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}--{d}%"))
)
c.render_notebook()
"""不同婚姻状况的采购额"""
# 女性情况
nv_dd = df_dd[df_dd['性别'] == 'F']
nv_result = nv_dd.groupby('婚姻状况')['采购额'].sum()
nv_result
# 男性情况
nan_dd = df_dd[df_dd['性别'] == 'M']
nan_dd_result = nan_dd.groupby('婚姻状况')['采购额'].sum()
nan_dd_result
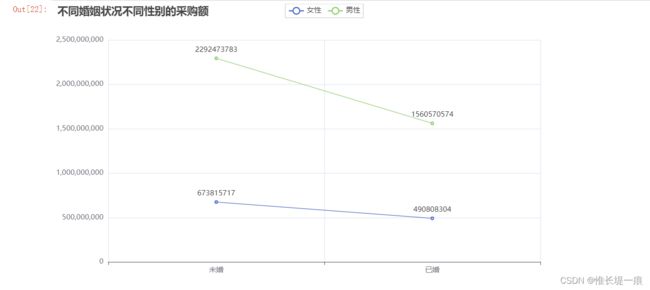
"""婚姻状况对采购的影响"""
from pyecharts import options as opts
from pyecharts.charts import Line
c = (
Line()
.add_xaxis(['未婚', '已婚'])
.add_yaxis("女性", nv_result.values.tolist())
.add_yaxis("男性", nan_dd_result.values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="不同婚姻状况不同性别的采购额"))
)
c.render_notebook()
4.2年龄对消费的影响
"""统计每个年龄阶段的人数"""
# 性别女数据, 分年龄段的数据
nv_dd = df_dd[df_dd['性别'] == 'F']
nv_result = nv_dd.groupby('年龄')['用户ID'].count()
nv_result
# 性别男数据, 分年龄段的数据
nan_dd = df_dd[df_dd['性别'] == 'M']
nan_dd_result = nan_dd.groupby('年龄')['用户ID'].count()
nan_dd_result

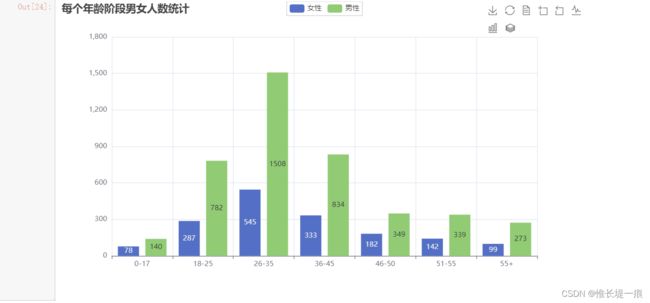
"""每个年龄阶段男女人数统计"""
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c = (
Bar()
.add_xaxis(nan_dd_result.index.tolist())
.add_yaxis("女性", nv_result.values.tolist())
.add_yaxis("男性", nan_dd_result.values.tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="每个年龄阶段男女人数统计"),
toolbox_opts= opts.ToolboxOpts()
)
)
c.render_notebook()
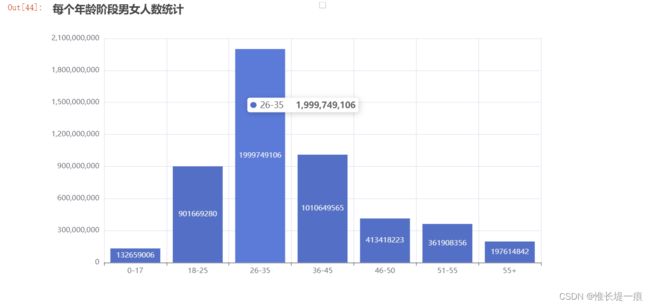
"""每个年龄阶段的消费能力"""
xiaofei = df_dd.groupby('年龄')['采购额'].sum()
xiaofei

"""每个年龄阶段男女人数统计"""
from pyecharts import options as opts
from pyecharts.charts import Bar
c = (
Bar()
.add_xaxis(xiaofei.index.tolist())
.add_yaxis("", xiaofei.values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="每个年龄阶段男女人数统计"))
)
c.render_notebook()
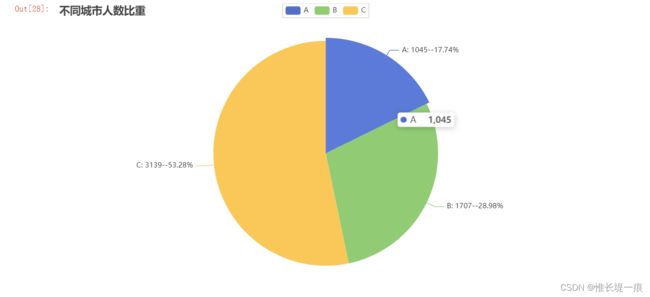
4.3城市字段分析
df_city = df_dd['城市类别'].value_counts()
df_city = df_city.sort_index()
df_city

"""城市所占比重"""
from pyecharts import options as opts
from pyecharts.charts import Pie
x = df_city.index.tolist()
y = df_city.values.tolist()
data = list(zip(x, y))
c = (
Pie()
.add("", data)
.set_global_opts(title_opts=opts.TitleOpts(title="不同城市人数比重"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}--{d}%"))
)
c.render_notebook()
"""城市消费采购额统计"""
city_sum = df_dd.groupby('城市类别')['采购额'].sum()
city_sum

"""城市消费采购额柱状图"""
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.faker import Faker
c = (
Bar()
.add_xaxis(city_sum.index.tolist())
.add_yaxis("消费水平", city_sum.values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="城市消费采购额柱状图"))
)
c.render_notebook()
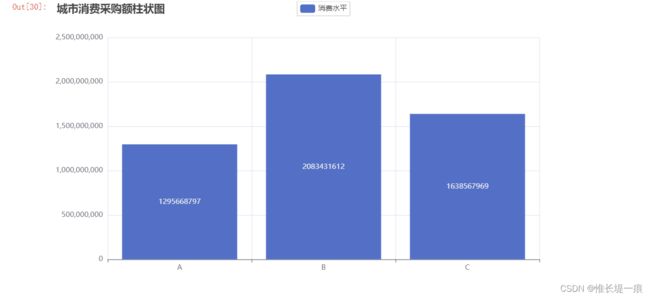
"""每个城市平均消费能力"""
city_sum / df_city
# 人数来说: C城市
# 消费总额: B城市
# 人均消费: A城市
city_live = df_dd.groupby('居住城市年数')['用户ID'].count()
city_live

"""不同居住年限人数饼图"""
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
x = ['游客', '1年', '2年', '3年', '4年以上']
y = city_live.values.tolist()
data = list(zip(x, y))
c = (
Pie()
.add("", data)
.set_global_opts(title_opts=opts.TitleOpts(title="不同居住年限人数饼图"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}--{d}%"))
)
c.render_notebook()

"""不同居住年份的采购额"""
city_xiaofei = df_dd.groupby('居住城市年数')['采购额'].sum()
city_xiaofei

"""不同居住年限采购额饼图"""
from pyecharts import options as opts
from pyecharts.charts import Pie
x = ['游客', '1年', '2年', '3年', '4年以上']
y = city_xiaofei.values.tolist()
data = list(zip(x, y))
c = (
Pie()
.add("", data)
.set_global_opts(title_opts=opts.TitleOpts(title="不同居住年限采购额饼图"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}--{d}%"))
)
c.render_notebook()

4.4职业分析
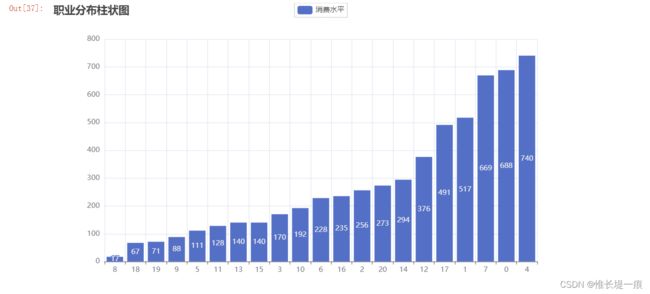
work = df_dd['职业'].value_counts().sort_values()
work
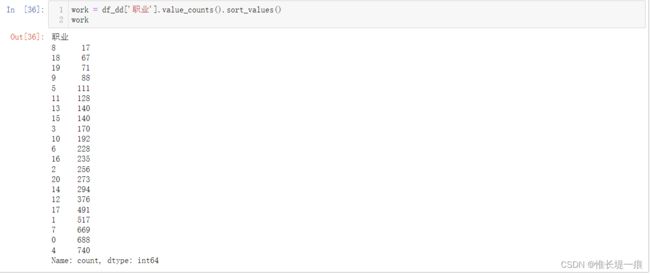
"""职业分布柱状图"""
from pyecharts import options as opts
from pyecharts.charts import Bar
c = (
Bar()
.add_xaxis(work.index.tolist())
.add_yaxis("消费水平", work.values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="职业分布柱状图"))
)
c.render_notebook()
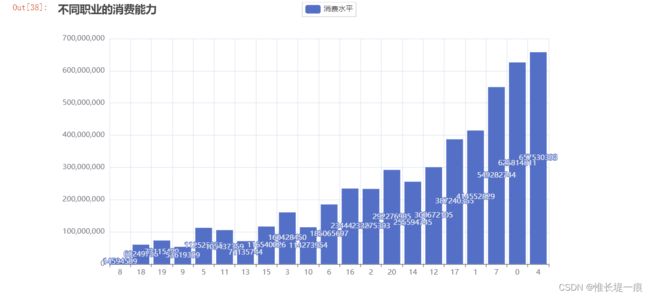
"""不同职业的消费能力"""
ocp_data = df_dd.groupby('职业')['采购额'].sum()
ocp_data
ocp_data_list = []
for i in work.index:
# print(ocp_data[i])
ocp_data_list.append(ocp_data[i])
data_ser = pd.Series(index=work.index.tolist(), data=ocp_data_list)
from pyecharts import options as opts
from pyecharts.charts import Bar
x = work.index.tolist()
c = (
Bar()
.add_xaxis(data_ser.index.tolist())
.add_yaxis("消费水平", data_ser.values.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="不同职业的消费能力"))
)
c.render_notebook()
work.index.tolist()
data_ser
5.总结
- 性别方面: 男性的消费能力比女性要高
- 婚否: 购买商品的人, 未婚的比已婚的购买人数多, 未婚的比已婚的采购额要高, 男性的婚姻状况对男性的采购额影响较大
- 年龄: 18 - 45 年龄范围的人, 消费能力要强
- 城市: B城市猜测是中大型城市, 消费能力要高于其他城市
- 居住年限: 居住一年左右的人群消费能力要高, 后续随着居住年限的增加, 消费能力会降低
- 职业: 不同职业消费能力差异大, 营销策划重点可以放在 [ 14 20 12 17 1 7 0 4 ]