MySQL事务与MVCC详解
前置概念之事务
在开始MVCC的讨论之前,我们必须了解一些关于事务的概念。
什么是事务
现在我们开发的一个功能需要进行操作多张表,假如我们遇到以下几种情况:
- 某个逻辑报错
- 数据库连接中断
- 某台服务器突然宕机
- …
这时候我们数据库执行的操作可能才到一半,所以为了避免这种一半一半的情况,我们就需要事务来保证数据一致性。
所以事务就是当作一个原子的逻辑组操作,要么全都成功执行,要么全部都失败。事务有分分布式事务和数据库事务,如果没有特指,我们平时所说的事务都是数据库事务,也就是本文探讨的话题。
事务的四大特性
原子性(Atomicity):一组操作要构成一个原子,原子可以看作事务的最小单位,不可在进行分割了,要么都执行,要么都不执行。一致性(Consistency):经过一个事务的操作后,前后要保持数据一致性,例如我们要用数据库记录一次转账操作,那么两个数据经过转账逻辑之后总额还是保持不变。隔离性(Isolation):在并发场景下,每个事务之间的操作互不干扰。持久性(Durability):存储到数据库中的数据永不丢失,及时数据库发生故障,当然机器被破坏了那就另说了。
并发事务会带来那些问题
这里笔者先说一个概念,具体会在后文示例中详尽介绍
脏读
我们举个例子,我们开启一个事务A,准备读取user表的数据,结果事务B将事务A要读取的数据修改了,但事务还没提交,A却能看到这个未提交的结果(而且这个结果后续还不一定提交)。
这种其他事务还没提交的结果能被另一个事务看到的情况就属于脏读。
幻读
我们再举个例子,事务A查询user表,此时表中有10条数据。再次期间,事务B插入5条数据。事务A在查发现有15条事务。这就是幻读。
不可重复读
仍然举一个例子,事务A读取id为1的数据,name为xiaoming。事务B在此期间更新id为1的数据并提交这个事务,结果事务A再次读取时发现name变了,这就是不可重复读。
你可能会问了,这和幻读听起来是一个概念啊,他俩有什么区别?
幻读说白了就是针对插入或者删除操作后导致数据前后不一致的情况,而不可重复读是针对两次相同查询操作出现数据不一致。
数据丢失
这个就很好理解了,高并发场景下,事务A修改id为1的money+100,事务B修改id为1的money+200,他们统一时间读取,先后写入,这就导致如果事务A后写入,那么money最后只加了100,如果事务B后写入,那么money就少了100。
事务的隔离级别
读未提交(READ UNCOMMITTED)
在这个级别下,任何事务的修改操作即使没有提交,其他事务也能看到,造成脏读。
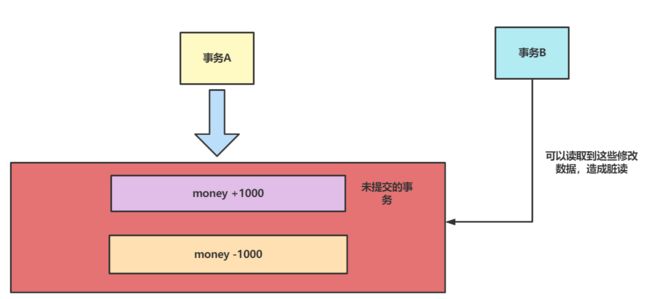
对此我们不妨用下面这段SQL来验证一下:
首先我们先建个测试表
create table test2 (id int,name varchar(10),money int);
insert into test2 values(1,'xiaoming',100);
insert into test2 values(2,'xiaowang',100);
事务A开启事务,进行更新操作,不提交
start transaction;
update test2 set money = money +100 where name ='xiaoming';
update test2 set money =money -100 where name ='xiaowang';
事务B设置为读未提交的隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ committed;
select * from test2 t ;
查询结果是事务B看到了事务A的更新操作,造成脏读。同理这个隔离级别也会造成幻读(同一个事务同一次查询记录数不一样)、以及不可重复读(同一个事务下查询记录的值不一样)。
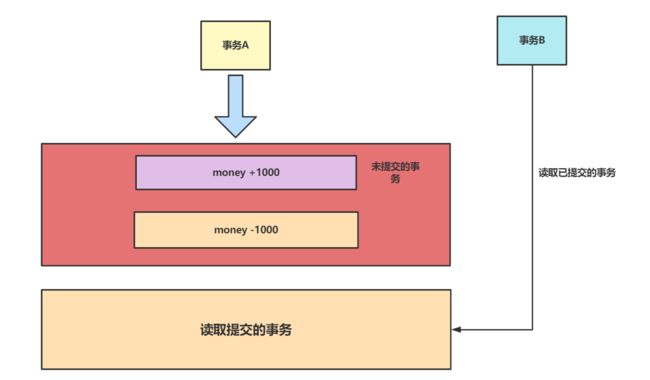
读已提交(READ COMMITTED)
这个概念也很好理解,每个事务只能看到其他事务提交后的数据。避免了脏读:
但是无法避免幻读和不可重复度,我们就以幻读为例,如下图,事务B首先查询到数据表中没有id为1的用户,在这个查询结束后,事务A进行一次插入操作但是事务还未提交。
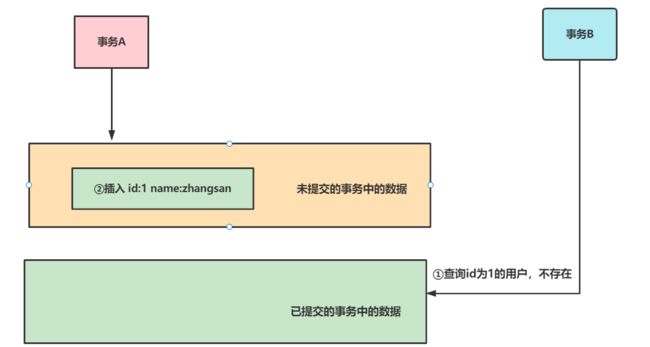
此时,在事务A执行插入但还未提交事务前,事务B进行插入操作。结果插入失败了,事务B就感觉出现幻觉一样,明明没查到数据,咋还告诉我违反唯一约束了呢?

了解流程之后,我们拿SQL印证一下,首先创建数据表
drop table if exists account1;
CREATE TABLE `account1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`balance` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `account1_un` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=UTF8MB4;
事务B查询,没数据
SET SESSION TRANSACTION ISOLATION LEVEL READ committed;
START TRANSACTION;
SELECT * from account1;
事务A在此期间插入,事务不提交
SET SESSION TRANSACTION ISOLATION LEVEL READ committed;
START TRANSACTION;
insert into account1(name,balance) values('zhangsan',1000);
事务B插入失败,造成幻读。
insert into account1(name,balance) values('zhangsan',1000);
可重复读(REPEATABLE READ)
这个隔离级别,也很好理解,同一个事务内,多次查询的数据都是一样的。我们不妨基于上面的例子实验一下
首先事务B查询
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION;
select * from account1 a where id=3;
事务A执行更新并提交
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
START TRANSACTION;
update account1 set balance=0 where id=3;
commit;
事务B再查数据还是不变,总的来说可重复读避免了脏读和不可重复读,但是幻读还是无法避免。
串行化(SERIALIZABLE)
事务隔离最高级别,解决上方一切问题。
MVCC
了解当前读和快照读
快照读,即读取数据是从快照中获取的,事务在进行事务读取时不上锁,这就是mysql并发读写性能高的原因之一。而当前读反之,读取数据时会上锁,这也就意味着即使你的隔离级别是可重复读,你用当前读也能读取到其他事务的最新结果,造成不可重复读。
如下所示:
首先事务A读取数据,假设数据值是100
begin;
select * from account1 a ;
事务B更新事务并提交
update account1 set name='xiaozhang1' where id=1;
事务A使用快照读,数据还是1000
select * from account1 a ; --快照读 旧数据
一旦使用当前读,就是其他事务提交的新数据了
--两个都是当前读,得到最新结果
select * from account1 a for update;
select * from account1 a lock in share mode;4
核心概念之undo log
首先说说undo log,在innoDB的聚簇索引中,每一条记录除了我们表中的数据以外,还会额外记录名为事务id(transaction id)的隐藏列。每当用户对当前数据进行修改操作后,新值的数据的事务id就会递增。同时每行数据还有一个回滚指针(roll_pointer),如下图所示,每当用户对索引进行更新之后,旧的数据就会被存放到undo log中,新的数据的回滚指针指向这条最新的旧数据(就是刚刚存到undo log中的数据,通俗的说是最新的垃圾)。用于后续可能需要的回滚操作。

核心概念之readView
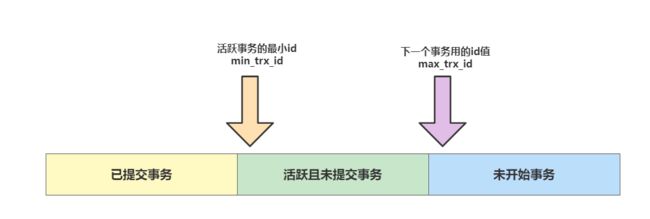
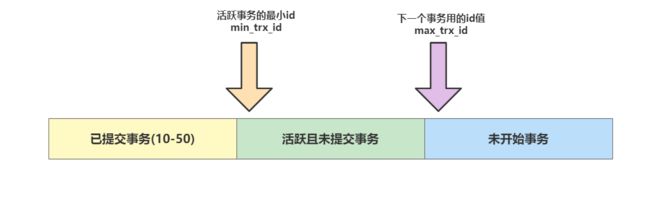
说完了undo log,接下来就说说readView,readView就是真正用到undo log的东西,readView如下图所示,可以看到它由三个部分组成,分别是:
已提交事务:已提交事务中记录的则是已经被提交的事务id集合。活跃事务:这个则记录那些还能活动且还没被提交的事务,其中min_trx_id指向活跃事务的最小值。未开始事务:这里面则是存放待使用的事务id值,其中max_trx_id就是记录这一块的最小值。
用几个事务间的SQL的MVCC工作机制
了解了undo log和readView,我们就可以了解mvcc的工作机制了。就以可重复读为例,我们来了解一下这两个东西如何实现可重复读。
首先事务A进行查询,查询语句为:
select * from account1 a where id=1;
然后事务启动创建readView,如下图所示,可以看到从数据表中知道id为1当前名字为xiaoming。

翻译成readView如下图所示,注意当前事务是读操作,所以事务id为0,从下图可以看出已提交事务中的最大值为50,所以就取50,所以name为xiaoming。

这时候,事务B启动,对id为1的数据进行更新,SQL如下所示,事务提交。
update account1 set name='aa' where id=1;
完成后,undo log图如下所示

回到事务A,由于可重复这个隔离级别只有在启动时创建readView,所以在此查询id为1的值,所以readView还是和第一次查询一样,取值还是取已提交事务最大值,所以name还是xiaoming。
了解了可重复读的过程吗,我们再来说说读已提交这个隔离级别下的工作过程,老规矩事务A进行查询,得到name为xiaoming。
undo log如下图所示
生成的readView如下所示,所以事务id取50,name为xiaoming。
此时事务B进行更新操作,并将事务提交,最终undo log如下
回到事务A,由于当前隔离级别是读已提交,所以每次查询都会生成最新的readView,由于事务B提交了最新结果,所以取最新已提交事务id 60,得到name为aa的数据。

更进一步的理解
MySQL 的隔离级别是基于锁实现的吗
答: 是基于锁和mvcc共同实现的,SERIALIZABLE 这个隔离级别就是基于锁实现的,其他隔离级别都是基于mvcc,需要补充的是REPEATABLE-READ 如果使用当前读也是基于锁实现。
MySQL 的默认隔离级别是什么?
以笔者使用的MySQL8来说使用如下命令可以看到默认级别为可重复读。
select @@transaction_isolation;
参考文献
看完这篇还不懂MySQL的MVCC机制算我输
MVCC 水略深,但是弄懂了真的好爽!
MySQL常见面试题总结