【C语言(九)】
深入理解指针(四)
一、回调函数
回调函数就是⼀个通过函数指针调⽤的函数。
如果你把函数的指针(地址)作为参数传递给另⼀个函数,当这个指针被用来调用其所指向的函数
时,被调用的函数就是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的⼀方调用的,用于对该事件或条件进行响应。
上一讲中我们写的计算机的实现的代码中,switch-case中的代码是重复出现的,其中虽然执行计算的逻辑是区别的,但是输⼊输出操作是冗余的,有没有办法,简化⼀些呢?
因为switch-case中的代码,只有调用函数的逻辑是有差异的,我们可以把调用的函数的地址以参数的形式传递过去,使用函数指针接收,函数指针指向什么函数就调用什么函数,这里其实使用的就是回调函数的功能。 

二、qsort使用举例
2.1、使用qsort函数排序整型数据
void gsort(
void* base,//base 指向了要排序的数组的第一个元素size_t num,//base指向的数组中的元素个数 (待排序的数组的元素的个数)
size_t size,//base指向的数组中元素的大小 (单位是字节)
int (*compar)const vod*p1,const void*p2)//函数指针 - 指针指向的函数是用来比较数组中的2个元素的);
#include
//cmp_int 这个函数是用来比较p1和p2指向的元素的大小
int cmp_int(const void* p1, const void* p2)
{
return *(int*)p1 - *(int*)p2;
}
void print_arr(int arr[],int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void test1()//测试qsort函数排序整型数据
{
int arr[10] = { 3,1,5,2,4,6,8,7,0,9 };
int sz = sizeof(arr) / sizeof(arr[0]);
print_arr(arr, sz);
qsort(arr, sz, sizeof(arr[0]), cmp_int);
print_arr(arr, sz);
}
int main()
{
//将一组整数排序为升序
test1();
return 0;
} 2.2、使用qsort排序结构体数据
#include
struct Stu
{
char name[20];
int age;
};
//按照年龄比较
int cmp_stu_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p1)->age - ((struct Stu*)p2)->age;
}
void test2()//测试qsort函数排序结构体数据
{
struct Stu arr[] = { {"zhangsan" , 20} , {"lisi" , 38} , {"wangwu" , 18} };
//比较两个结构体数据,不能直接使用 > < == 比较
//1.可以按照名字比较
//2.可以按照年龄比较
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_age);
}
//按照名字比较
int cmp_stu_by_name(const void* p1, const void* p2)
{
//两个字符串不能使用 > < == 比较
//而是使用库函数strcmp - string compare -> 其实是按照对应位置上字符的ASCII码值的大小比较的
return strcmp(((struct Stu*)p1)->name , ((struct Stu*)p2)->name);
}
void test3()
{
struct Stu arr[] = { {"zhangsan" , 20} , {"lisi" , 38} , {"wangwu" , 18} };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_stu_by_name);
}
int main()
{
test3();
return 0;
} 

三、qsort函数的模拟实现
使用回调函数,模拟实现qsort(采用冒泡的方式)。
int cmp_int(const void* p1, const void* p2)
{
return *((int*)p1) - *((int*)p2);
}
void Swap(char* buf1 , char* buf2 , size_t width)
{
int i = 0;
for (i = 0; i < width; i++)
{
char tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
buf1++;
buf2++;
}
}
void bubble_sort(void* base, size_t sz , size_t width , int (*cmp)(const void* p1 , const void* p2))
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
//if (arr[j] > arr[j + 1])
if(cmp((char*) base + j*width , (char*)base + (j + 1) * width) > 0)
{
/*int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;*/
//交换
Swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void test_arr()
{
//想排序一组数据 - 升序
int arr[] = { 3,1,5,7,9,2,4,0,8,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
print_arr(arr, sz);
bubble_sort(arr, sz, sizeof(arr[0]), cmp_int);
print_arr(arr, sz);
}
struct Stu
{
char name[20];
int age;
};
int cmp_stu_by_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
}
int cmp_stu_by_age(const void* p1, const void* p2)
{
return ((struct Stu*)p1)->age - ((struct Stu*)p2)->age;
}
void test_struct()
{
struct Stu arr[] = { {"zhangsan" , 18} , {"lisi" , 38} , {"wangwu" , 15} };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz, sizeof(arr[0]), cmp_stu_by_name);
//bubble_sort(arr, sz, sizeof(arr[0]), cmp_stu_by_age);
//打印arr数组的内容
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);
}
}
int main()
{
//test_arr();
test_struct();
return 0;
}四、sizeof和strlen的对比
4.1、sizeof
在学习操作符的时候,我们学习了 sizeof , sizeof 计算变量所占内存内存空间大小的,单位是
字节,如果操作数是类型的话,计算的是使用类型创建的变量所占内存空间的大小。
sizeof 只关注占用内存空间的大小,不在乎内存中存放什么数据。
sizeof(表达式)中的表达式也是不执行的:在编译时sizeof就已经确定了自己要计算的表达式结果所占的内存空间的大小,并不影响运行时 - 在编译时表达式已经计算完成了,将所要计算的值传递给sizeof(),运行时sizeof()直接计算,但是表达式并不运行。
#inculde
int main()
{
int a = 10;
printf("%d\n", sizeof(a));
printf("%d\n", sizeof a);
printf("%d\n", sizeof(int));
return 0;
} 4.2、strlen
strlen 是C语言库函数,功能是求字符串长度。函数原型如下:
size_t strlen ( const char * str );
统计的是从 strlen 函数的参数 str 中这个地址开始向后, \0 之前字符串中字符的个数。
strlen 函数会⼀直向后找 \0 字符,直到找到为止,所以可能存在越界查找。
#include
int main()
{
char arr1[3] = {'a', 'b', 'c'};
char arr2[] = "abc";
printf("%d\n", strlen(arr1));
printf("%d\n", strlen(arr2));
printf("%d\n", sizeof(arr1));
printf("%d\n", sizeof(arr1));
return 0;
} 4.3、sizeof和strlen对比
sizeof1. sizeof是操作符2. sizeof计算操作数所占内存的大小,单位是字节3. 不关注内存中存放什么数据strlen1. strlen是库函数,使⽤需要包含头文件 string.h2. srtlen是求字符串长度的,统计的是 \0 之前字符的间隔个数3. 关注内存中是否有 \0 ,如果没有 \0 ,就会持续往后找,可能会越界
五、数组和指针笔试题解析
5.1、一维数组
int main()
{
int a[] = {1,2,3,4};//a数组有4个元素,每个元素是int类型的数据
printf("%zd\n",sizeof(a));//16 - sizeof(数组名)的情况,计算的是整个数组的大小,单位是字节 - 16
printf("%zd\n",sizeof(a+0));//a表示的就是数组首元素的地址,a+0还是首元素的地址 - 4/8
//int*
printf("%zd\n",sizeof(*a));//a表示的就是数组首元素的地址,*a 就是首元素,大小就是4个字节
printf("%zd\n",sizeof(a+1));//a表示的就是数组首元素的地址,a+1就是第二个元素的地址,这里计算的是第二个元素的地址的大小 - 4/8
printf("%zd\n",sizeof(a[1]));//a[1]是数组的第二个元素,大小是4个字节
printf("%zd\n",sizeof(&a));//&a - 取出的是数组的地址,但是数组的地址也是地址,是地址,大小就是4/8个字节
//int (*pa)[4] = &a;
//int (*)[4]
printf("%zd\n",sizeof(*&a));//sizeof(a) -16
//1.&和*抵消
//2.&a 的类型是数组指针,int(*)[4],*&a就是对数组指针解引用访问一个数组的大小,是16个字节
printf("%zd\n",sizeof(&a+1));//&a+1是跳过整个数组后的一个地址,是地址,大小就是4/8个字节
printf("%zd\n",sizeof(&a[0]));//&a[0]是数组第一个元素的地址,大小就是4/8个字节
printf("%zd\n",sizeof(&a[0]+1));//&a[0] + 1 是第二个元素的地址,大小就是4/8个字节
//int *
return 0;
}5.2、字符数组
5.2.1、代码1:
int main()
{
char arr[] = {'a','b','c','d','e','f'};//arr数组中有6个元素
printf("%d\n", sizeof(arr));//计算的是整个数组的大小,6个字节
printf("%d\n", sizeof(arr+0));//arr+0 是数组第一个元素的地址 - 4/8
printf("%d\n", sizeof(*arr));//*arr是首元素,计算的是首元素的大小,就是1个字节
printf("%d\n", sizeof(arr[1]));//arr[1] - 1
printf("%d\n", sizeof(&arr));//4/8
printf("%d\n", sizeof(&arr+1));//4/8
printf("%d\n", sizeof(&arr[0]+1));//4/8
return 0;
}5.2.2、代码2:
int main()
{
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", strlen(arr));//随机值
printf("%d\n", strlen(arr+0));//随机值
printf("%d\n", strlen(*arr));//err
//'a'-97
printf("%d\n", strlen(arr[1]));//err
//'b' -98
printf("%d\n", strlen(&arr));//随机值
printf("%d\n", strlen(&arr+1));//随机值
printf("%d\n", strlen(&arr[0]+1));//随机值
return 0;
}5.2.3、代码3:
int main()
{
char arr[] = "abcdef";
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr+0));//arr+0是数组首元素的地址,地址的大小是4/8个字节
printf("%zd\n", sizeof(*arr));//*arr是数组的首元素,这里计算的是首元素的大小 - 1
printf("%zd\n", sizeof(arr[1]));//1
printf("%zd\n", sizeof(&arr));//&arr - 是数组的地址,数组的地址也是地址,是地址就是4/8个字节
printf("%zd\n", sizeof(&arr+1));//&arr+1,跳过整个数组,指向了数组的后边,4/8
printf("%zd\n", sizeof(&arr[0]+1));//&arr[0] + 1是第二个元素的地址 - 4/8
return 0;
}5.2.4、代码4:
int main()
{
char arr[] = "abcdef";
printf("%zd\n", strlen(arr));//arr也是数组首元素的地址 - 6
printf("%zd\n", strlen(arr+0));//arr + 0是数组首元素的地址,6
//printf("%zd\n", strlen(*arr));//传递是'a'-97 - err
//printf("%zd\n", strlen(arr[1]));//'b'-98 - err
printf("%zd\n", strlen(&arr));//6,&arr虽然是数组的地址,但是也是指向数组的起始位置
printf("%zd\n", strlen(&arr+1));//随机值
printf("%zd\n", strlen(&arr[0]+1));//&arr[0] + 1是第二个元素的地址 - 5
return 0;
}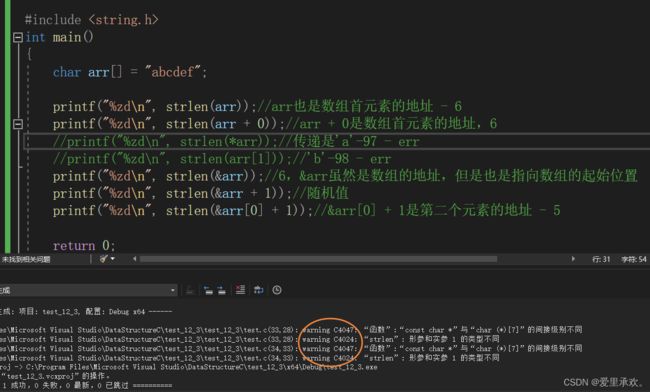 waining的原因:
waining的原因: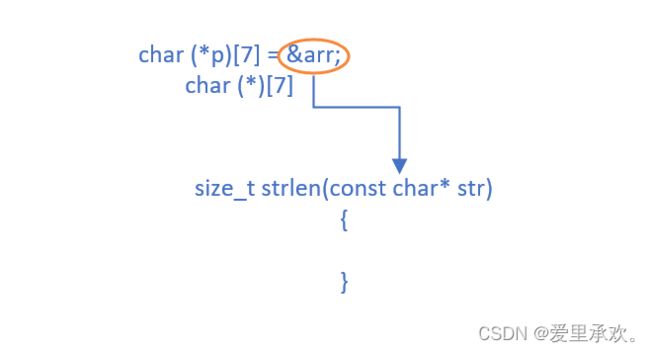
5.2.5、代码5:
int main()
{
char *p = "abcdef";
printf("%zd\n", sizeof(p));//4/8 - 计算的指针变量的大小
printf("%zd\n", sizeof(p+1));//p + 1是'b'的地址,是地址大小就是4/8个字节
printf("%zd\n", sizeof(*p));//*p就是'a',大小是1个字节
printf("%zd\n", sizeof(p[0]));//p[0]--> *(p+0) - *p -> 1字节
printf("%zd\n", sizeof(&p));//&p也是地址,是指针变量p的地址,大小也是4/8个字节
printf("%zd\n", sizeof(&p+1));//&p + 1是指向p指针变量后面的空间,也是地址,是4/8个字节
printf("%zd\n", sizeof(&p[0]+1));//&p[0]+1是'b'的地址,是地址就是4/8个字节
return 0;
}
5.2.6、代码6:
int main()
{
char *p = "abcdef";
printf("%zd\n", strlen(p));//6
printf("%zd\n", strlen(p+1));//5
//printf("%zd\n", strlen(*p));//err
//printf("%zd\n", strlen(p[0]));//p[0] -- *(p+0) --> *p -> err
printf("%zd\n", strlen(&p));//随机值
printf("%zd\n", strlen(&p+1));//随机值
printf("%zd\n", strlen(&p[0]+1));//5
return 0;
}5.3、二维数组

int main()
{
//二维数组也是数组,之前对数组名理解也是适合
int a[3][4] = {0};
printf("%zd\n",sizeof(a));;//12*4 = 48个字节,数组名单独放在sizeof内部
printf("%zd\n",sizeof(a[0][0]));//4
printf("%zd\n",sizeof(a[0]));//a[0]是第一行这个一维数组的数组名,数组名单独放在sizeof内部
//计算的是第一行的大小,单位是字节,16个字节
printf("%zd\n",sizeof(a[0]+1));//a[0]第一行这个一维数组的数组名,这里表示数组首元素
//也就是a[0][0]的地址,a[0] + 1是a[0][1]的地址
printf("%zd\n",sizeof(*(a[0]+1)));//a[0][1] - 4个字节
printf("%zd\n",sizeof(a+1));;//a是二维数组的数组名,但是没有&,也没有单独放在sizeof内部
//所以这里的a是数组首元素的地址,应该是第一行的地址,a+1是第二行的地址
//大小也是4/8 个字节
printf("%zd\n",sizeof(*(a+1)));//*(a + 1) ==> a[1] - 第二行的数组名,单独放在szeof内部,计算的是第二行的大小 - 16个字节
printf("%zd\n",sizeof(&a[0]+1));//&a[0]是第一行的地址,&a[0]+1就是第二行的地址,4/8
printf("%zd\n",sizeof(*(&a[0]+1)));//访问的是第二行,计算的是第二行的大小,16个字节
//int(*p)[4] = &a[0] + 1;
printf("%zd\n",sizeof(*a));//这里的a是第一行的地址,*a就是第一行,sizeof(*a)计算的是第一行的大小 - 16
//*a --> *(a+0) --> a[0]
printf("%zd\n",sizeof(a[3]));//这里不存在越界
//因为sizeof内部的表达式不会真实计算的
//计算的是第四行的大小 - 16
return 0;
}数组名的意义:
1. sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。2. &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。3. 除此之外所有的数组名都表示首元素的地址。
六、指针运算笔试题解析
6.1、题目1:
#include
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
} 
6.2、题目2:
//在X86环境下
//假设结构体的⼤⼩是20个字节
//程序输出的结构是啥?
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
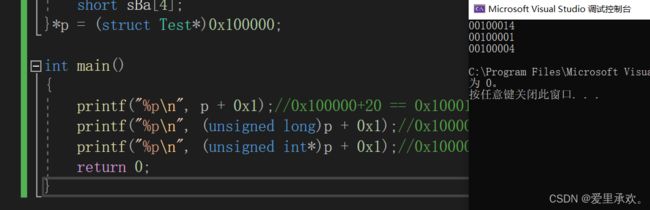
int main()
{
printf("%p\n", p + 0x1);//0x100000+20 == 0x100014
printf("%p\n", (unsigned long)p + 0x1);//0x100000+1 == 0x100001
printf("%p\n", (unsigned int*)p + 0x1);//0x100000+1 == Ox100004
return 0;
}
如果我们想输出以0x开头的数字呢?
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
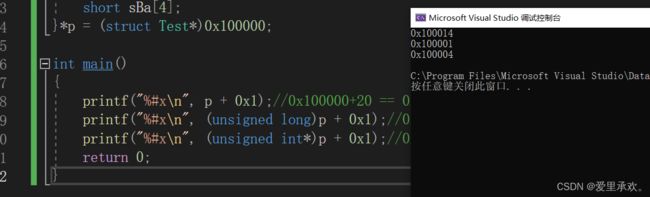
int main()
{
printf("%#x\n", p + 0x1);//0x100000+20 == 0x100014
printf("%#x\n", (unsigned long)p + 0x1);//0x100000+1 == 0x100001
printf("%#x\n", (unsigned int*)p + 0x1);//0x100000+1 == Ox100004
return 0;
}
6.3、题目3:
#include
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
} 大家可以试着想想这个数组里面的元素是如何初始化分配的?
下面我们先给出一个错误答案:
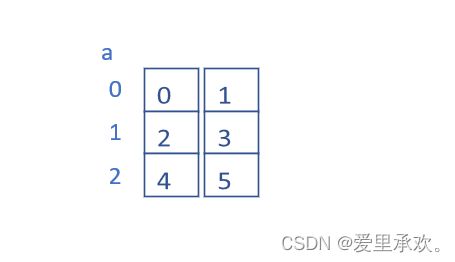 大家猜"对"了么?
大家猜"对"了么?
接下来是正确答案:
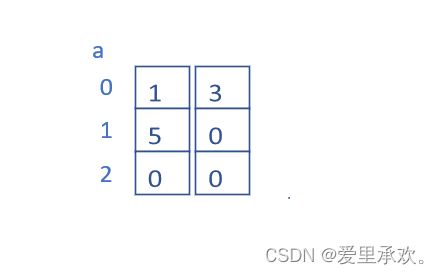 不要忽视数组初始化里面并不是大括号而是小括号,(x ,y)这代表了什么呢?没错,就是逗号表达式,表达式的值是最后一个数字的值。
不要忽视数组初始化里面并不是大括号而是小括号,(x ,y)这代表了什么呢?没错,就是逗号表达式,表达式的值是最后一个数字的值。
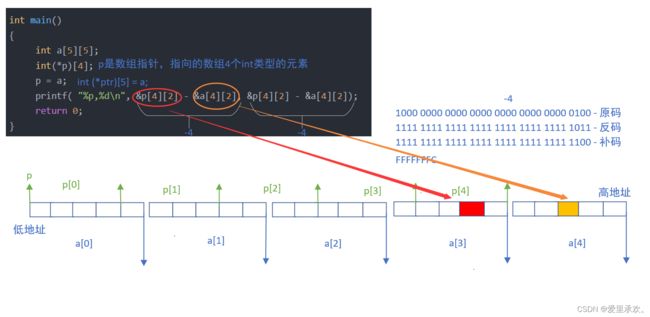
6.4、题目4:
//假设环境是x86环境,程序输出的结果是啥?
#include
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
} 
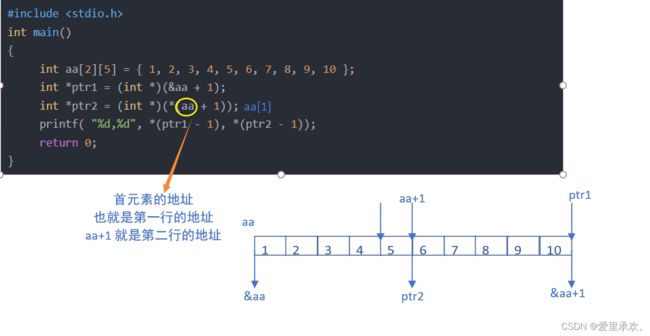
6.5、题目5:
#include
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
} 
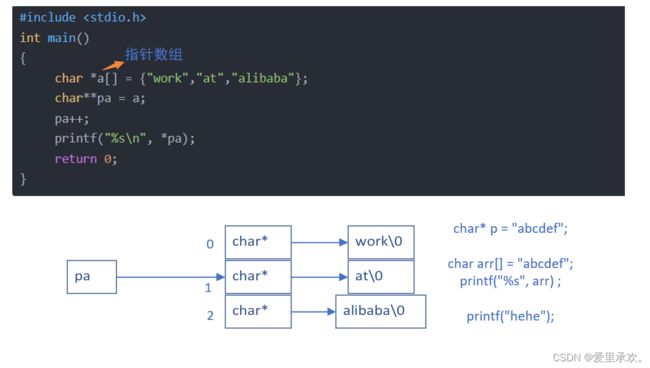
6.6、题目6:
#include
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);
return 0;
} 
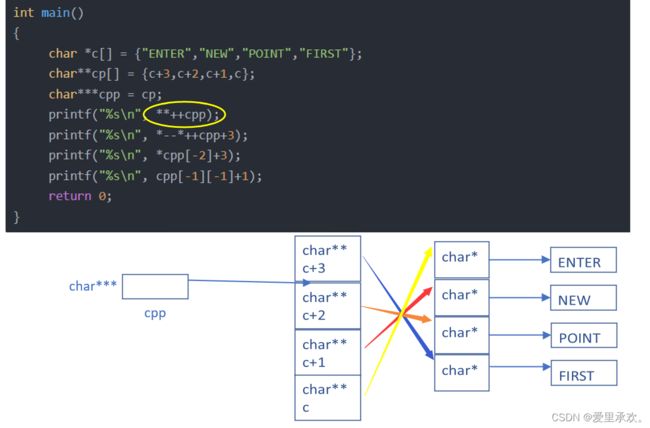
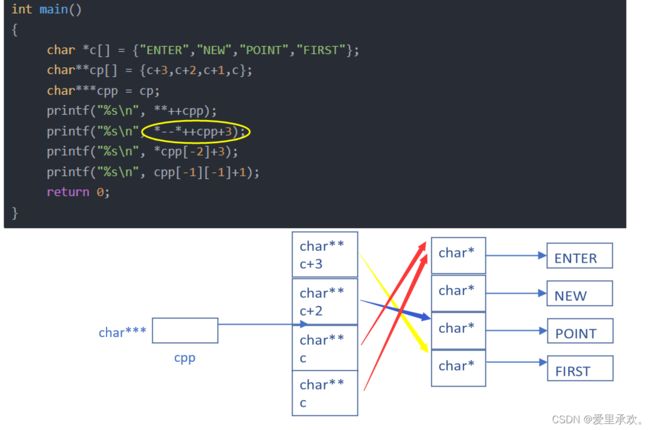
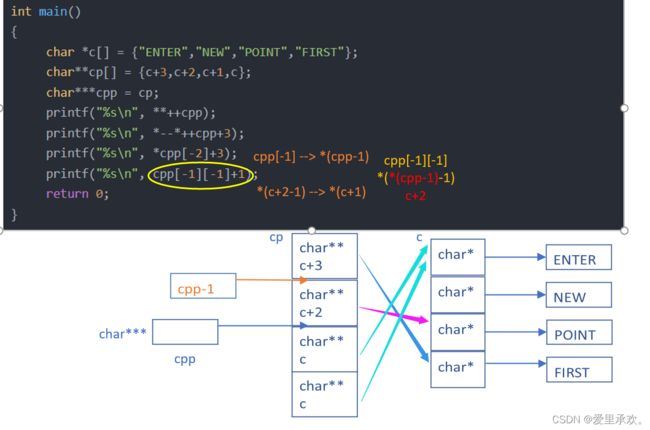
6.7、题目7:
#include
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp+3);
printf("%s\n", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}