大数据分析与应用实验任务十二
大数据分析与应用实验任务十二
实验目的:
-
通过实验掌握spark机器学习库本地向量、本地矩阵的创建方法;
-
熟悉spark机器学习库特征提取、转换、选择方法;
实验任务:
一、逐行理解并参考编写运行教材8.3.1、8.3.3节各个例程代码,查看向量或本地矩阵结果请用.toArray()方法。
1、本地向量
首先安装numpy,否则会报错“ImportError: No module named ‘numpy’”
sudo pip3 install numpy
所有本地向量都以 pyspark.ml.linalg.Vectors 为基类,DenseVector 和 SparseVector 分别是它的两个继承类,故推荐使用 Vectors 工具类下定义的工厂方法来创建本地向量。如果要使用 pyspark.ml 包提供的向量类型,则需要显式地引入 pyspark.ml.linalg.Vectors 这个类。
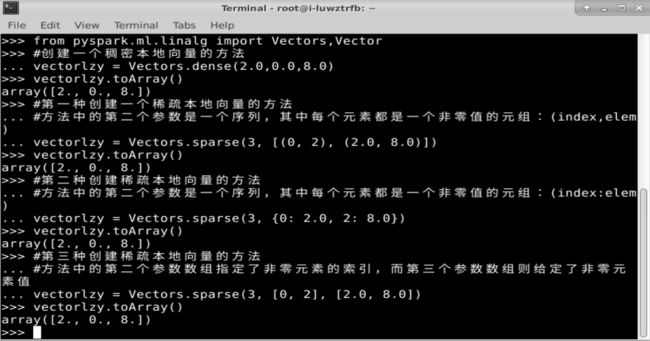
from pyspark.ml.linalg import Vectors,Vector
#创建一个稠密本地向量的方法
vector = Vectors.dense(2.0,0.0,8.0)
#第一种创建一个稀疏本地向量的方法
#方法中的第二个参数是一个序列,其中每个元素都是一个非零值的元组:(index,elem)
vector = Vectors.sparse(3, [(0, 2), (2.0, 8.0)])
#第二种创建稀疏本地向量的方法
#方法中的第二个参数是一个序列,其中每个元素都是一个非零值的元组:(index:elem)
vector = Vectors.sparse(3, {0: 2.0, 2: 8.0})
#第三种创建稀疏本地向量的方法
#方法中的第二个参数数组指定了非零元素的索引,而第三个参数数组则给定了非零元素值
vector = Vectors.sparse(3, [0, 2], [2.0, 8.0])
2、本地矩阵
本地矩阵的基类是 pyspark.ml.linalg.Matrix,DenseMatrix 和 SparseMatrix 均是它的继承类。与本地向量类似,spark.ml 包也为本地矩阵提供了相应的工具类 Matrices,调用工厂方法即可创建实例。
使用如下代码创建一个稠密矩阵:
from pyspark.ml.linalg import Matrix,Matrices #引入必要的包
#创建一个 3 行 2 列的稠密矩阵[ [1.0,2.0], [3.0,4.0], [5.0,6.0] ]
#注意,这里的数组参数是列优先的,即按照列的方式从数组中提取元素
Matrix_lzy = Matrices.dense(3, 2, [1.0, 3.0, 5.0, 2.0, 4.0, 6.0])
Matrix_lzy.toArray()

使用如下代码继续创建一个稀疏矩阵:
#创建一个 3 行 2 列的稀疏矩阵[ [9.0,0.0], [0.0,8.0], [0.0,6.0]]
#第一个数组参数表示列指针,即每一列元素的开始索引值
#第二个数组参数表示行索引,即对应的元素是属于哪一行
#第三个数组即是按列优先排列的所有非零元素,通过列指针和行索引即可判断每个元素所在的位置
Matrix_lzy = Matrices.sparse(3, 2, [0, 1, 3], [0, 2, 1], [9, 6, 8])
Matrix_lzy.toArray()

通过上述代码就创建了一个 3 行 2 列的稀疏矩阵[ [9.0,0.0], [0.0,8.0], [0.0,6.0]]。在Matrices.sparse 的参数中,3 表示行数,2 表示列数。第 1 个数组参数表示列指针,其长度=列数+1,表示每一列元素的开始索引值;第二个数组参数表示行索引,即对应的元素是属于哪一行,其长度193第 8 章 Spark MLlib =非零元素的个数;第三个数组即是按列优先排列的所有非零元素。在上面的例子中,(0,1,3)表示第 1 列有 1 个(=1-0)元素,第 2 列有 2 个(=3-1)元素;第二个数组(0, 2, 1)表示共有 3 个元素,分别在第 0、2、1 行。因此,可以推算出第 1 个元素位置在(0,0),值是 9.0。
二、逐行理解并参考编写运行教材8.5.1特征提取中的TF-IDF实例。
首先,对于一组句子,使用分解器 Tokenizer,把每个句子划分成由多个单词构成的“词袋”;然后,对每一个“词袋”,使用 HashingTF 将句子转换为特征向量;最后,使用 IDF 重新调整特征向量。这种转换通常可以提高使用文本特征的性能。具体步骤如下。
第一步:导入 TF-IDF 所需要的包。代码如下:
from pyspark.ml.feature import HashingTF,IDF,Tokenizer
第二步:创建一个集合,每一个句子代表一个文件。代码如下:
sentenceData = spark.createDataFrame([(0, "I heard about Spark and I love Spark"),(0, "I wish Java could use case classes"),(1, "Logistic regression models are neat")]).toDF("label", "sentence")
第三步:用 Tokenizer 把每个句子分解成单词。代码如下:
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
wordsData_lzy = tokenizer.transform(sentenceData)
wordsData_lzy.show()
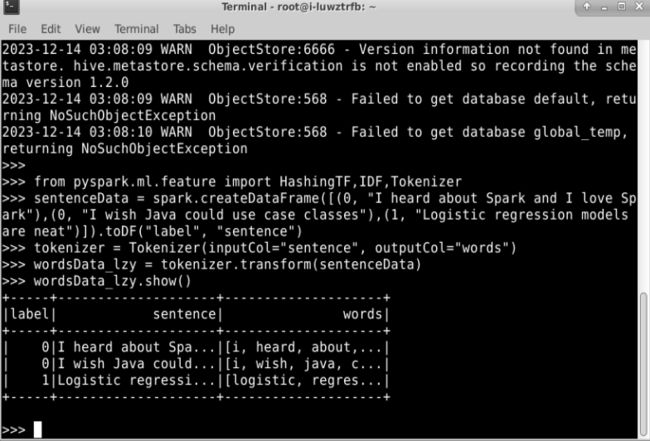
从打印结果可以看出,Tokenizer 的 transform()方法把每个句子拆分成了一个个单词,这些单词构成一个“词袋”(里面装了很多个单词)。
第四步:用 HashingTF 的 transform()方法把每个“词袋”哈希成特征向量,这里设置哈希表的桶数为 2000。代码如下:
hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures= 2000)
featurizedDatalzy = hashingTF.transform(wordsData_lzy)
featurizedDatalzy.select("words","rawFeatures").show(truncate=False)
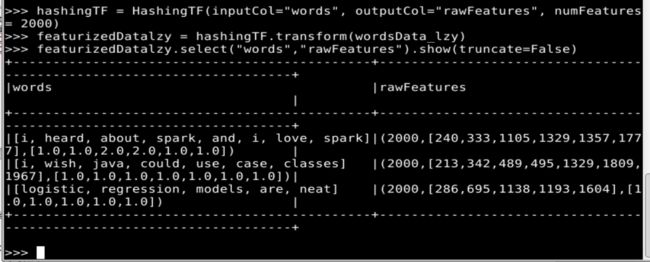
可以看出,“词袋”中的每一个单词被哈希成了一个不同的索引值。
第五步:调用 IDF 方法来重新构造特征向量的规模,生成的变量 idf 是一个评估器,在特征向量上应用它的 fit()方法,会产生一个 IDFModel(名称为 idfModel)。代码如下:
idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedDatalzy)
第六步:调用 IDFModel 的 transform()方法得到每一个单词对应的 TF-IDF 度量值。代码如下:
rescaledData = idfModel.transform(featurizedDatalzy)
rescaledData.select("features", "label").show(truncate=False)

三、逐行理解参考编写并运行教材8.5.2节中三种重要的特征转换方法,即StringIndexer、IndexToString以及VectorIndexer方法。
1、StringIndexer
首先,引入需要使用的类。代码如下:
from pyspark.ml.feature import StringIndexer
其次,构建一个 DataFrame,设置 StringIndexer 的输入列和输出列的名字。代码如下:
df_lzy = spark.createDataFrame([(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5,
"c")],["id", "category"])
indexer_lzy = StringIndexer(inputCol="category", outputCol="categoryIndex")
最后,通过 fit()方法进行模型训练,用训练出的模型对原数据集进行处理,并通过 indexed.show()进行展示。代码如下:
model = indexer_lzy.fit(df_lzy)
indexed_lzy = model.transform(df_lzy)
indexed_lzy.show()

2、IndexToString
与 StringIndexer 相反,IndexToString 用于将标签索引的一列重新映射回原有的字符型标签。IndexToString 一般与 StringIndexer 配合使用。先用 StringIndexer 将字符型标签转换成标签索引,进行模型训练,然后在预测标签的时候再把标签索引转换成原有的字符标签。当然,Spark 允许使用自己提供的标签。实例代码如下:
from pyspark.ml.feature import IndexToString, StringIndexer
toString = IndexToString(inputCol="categoryIndex", outputCol="originalCategory")
indexString = toString.transform(indexed_lzy)
indexString.select("id", "originalCategory").show()

3、VectorIndexer
首先,引入所需要的类,并构建数据集。代码如下:
from pyspark.ml.feature import VectorIndexer
from pyspark.ml.linalg import Vector, Vectors
df_lzy = spark.createDataFrame([(Vectors.dense(-1.0, 1.0, 1.0),), (Vectors.dense(-1.0, 3.0, 1.0),), (Vectors.dense(0.0, 5.0, 1.0), )], ["features"])
其次,构建 VectorIndexer 转换器,设置输入和输出列,并进行模型训练。代码如下:
indexer_lzy = VectorIndexer(inputCol="features", outputCol="indexed", maxCategories= 2)
indexerModel = indexer_lzy.fit(df_lzy)
此处设置 maxCategories 为 2,即只有种类小于 2 的特征才被视作类别型特征,否则被视作连续型特征。
再次,通过 VectorIndexerModel 的 categoryMaps 成员来获得被转换的特征及其映射,可以看到,共有两个特征被转换,分别是 0 号和 2 号。代码如下:
categoricalFeatures_lzy = indexerModel.categoryMaps.keys()
print ("Choose"+str(len(categoricalFeatures_lzy))+"categorical features:"+str(categoricalFeatures_lzy))

最后,将模型应用于原有的数据,并打印结果。代码及结果如下:
indexed = indexerModel.transform(df_lzy)
indexed.show()

四、逐行理解并参考编写运行教材8.5.3节中特征选择的卡方选择案例。
卡方选择是统计学上常用的一种有监督特征选择方法,它通过对特征和真实标签进行卡方检验,来判断该特征与真实标签的关联程度,进而确定是否对其进行选择。
与 spark.ml 包中的大多数学习方法一样,spark.ml 包中的卡方选择也是以“评估器+转换器”的形式出现的,主要由 ChiSqSelector 和 ChiSqSelectorModel 两个类来实现。
首先,进行环境的设置,引入卡方选择器所需要使用的类。代码如下:
from pyspark.ml.feature import ChiSqSelector, ChiSqSelectorModel
from pyspark.ml.linalg import Vectors
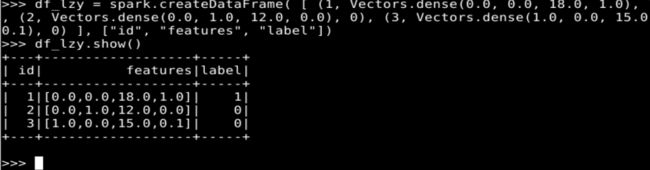
其次,创造实验数据,这是一个具有 3 个样本、4 个特征维度的数据集,标签有 1 和 0 两种,我们将在此数据集上进行卡方选择。代码如下:
df_lzy = spark.createDataFrame( [ \
... (1, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1), \
... (2, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0), \
... (3, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0) \
... ], ["id", "features", "label"])
df_lzy.show()
再次,用卡方选择进行特征选择器的训练,为了便于观察,我们设置只选择与标签关联性最强的一个特征(可以通过 setNumTopFeatures(…)方法进行设置)。代码如下:
selector = ChiSqSelector( \
... numTopFeatures = 1, \
... featuresCol = "features", \
... labelCol = "label", \
... outputCol = "selected-feature")
最后,用训练出的模型对原数据集进行处理,可以看到,第三列特征被选出作为最有用的特征列。代码如下:
selector_model = selector.fit(df_lzy)
result_lzy = selector_model.transform(df_lzy)
result_lzy.show()

实验心得
通过大数据分析与应用实验任务十二,我深入了解了Spark机器学习库在向量和矩阵创建、特征提取、转换和选择方面的应用。我学习了如何在pyspark编程环境中创建文件夹并保存代码,参考教材中的例子编写和运行了各个例程代码,熟悉了Spark机器学习库中的向量和矩阵操作。同时,我也参考教材的内容编写并运行了TF-IDF特征提取、StringIndexer、IndexToString和VectorIndexer特征转换以及卡方选择特征选择的案例。通过这次实验,我深入了解了Spark机器学习库的使用,并学会了如何创建本地向量和本地矩阵,进行特征提取、转换和选择。这些技能对于我的未来数据分析和机器学习工作非常有帮助。