Spark+Kafka构建实时分析Dashboard案例
目录
一、环境准备
Ubuntu安装
Hadoop安装
Spark安装
Kafka安装
Python安装
Python依赖库安装
vscode安装
Python工程目录结构
二、数据处理和Python操作Kafka
数据集
数据预处理
运行
三、 Structured Streaming实时处理数据
建立pyspark项目
运行
四、结果展示
环境准备
app.py文件源码
index.html文件源码
效果展示
五、补充说明
案例来自林子雨老师的团队案例网站
一、环境准备
Ubuntu: 22.10
Hadoop: 3.1.3
Spark: 3.3.1Scala: 2.12.15
Kafka: 3.4.0
Python: 3.10.7
Flask: 2.3.2
Flask-SocketIO: 5.3.4
Kafka-python: 2.0.2pyspark:3.4.0
-
Ubuntu安装
VMware官方下载地址 Ubuntu安装教程
-
Hadoop安装
apache软件下载地址 Hadoop安装教程
PS:在Apache软件下载地址里选择文件夹 hadoop -> common -> 所需版本 -> 选择后缀仅有.tar.gz的文件
-
Spark安装
Spark官方下载地址 Spark安装教程
PS:在Spark官方下载地址选择所需版本后在Choose a package type选择栏里选择Pre-built with user-provided Apache Hadoop之后再点击下方链接下载即可
-
Kafka安装
Kafka官方下载地址 Kafka安装教程
PS:在Kafka官方下载地址里选择对应Scala版本
在教程里的代码可能会出现报错的情况
cd /usr/local/kafka bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblab若下载的Kafka版本为2.2+,需要使用下列代码
cd /usr/local/kafka bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic dblab若后面依照教程仍出错可以考虑将 --zookeeper localhost:2181 改为 --bootstrap-server localhost:9092
-
Python安装
Python下载地址
PS:在安装Ubuntu时系统会自带Python,但考虑到可能出现Spark和自带的Python版本不兼容导致一些内容无法使用(如RDD编程),下面提供一种方法(强烈建议在执行下方操作时克隆虚拟机或快照!):
在Python下载地址里选择所需的Python版本(Stable Releases列表里的)版本选择Gzipped source tarball
#更新apt sudo apt update #下载和安装python 3的依赖包 sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev libsqlite3-dev wget libbz2-dev cd /home/hadoop/下载 #假设安装包位于/home/hadoop/下载,如果是其它路径,则更改此命令的目录 sudo tar -xvf Python-3.8.16.tgz -C /usr/local #解压缩到 /usr/local cd /usr/local/Python-3.8.16 #以下3个步骤依次执行 sudo ./configure --enable-optimizations --prefix=/usr/local/Python-3.8.16 sudo make -j 2 sudo make altinstall #建立软链接,将系统python3的命令链接到我们自己安装的python3.8版本 sudo rm -r /usr/bin/python3 sudo ln -s /usr/local/Python-3.8.16/bin/python3.8 /usr/bin/python3 sudo ln -s /usr/local/Python-3.8.16/bin/python3.8 /usr/bin/pip3
-
Python依赖库安装
PS:如果无法使用pip install但确有安装Python,可以尝试到Python解释器所在的文件夹运行或者使用sudo apt-get install python3-pip。
pip install pyspark pip install flask pip install flask-socketio pip install kafka-python
-
vscode安装
在Ubuntu系统自带的Ubuntu Software里搜索下载即可
PS:使用相对路径找不到文件,解决:设置Python插件 搜索execute in file dir 打勾

-
Python工程目录结构

- data目录存放的是用户日志数据;
- scripts目录存放的是Kafka生产者和消费者;
- static/js目录存放的是前端所需要的js框架;
- templates目录存放的是html页面;
- app.py为web服务器,接收Structed Streaming处理后的结果,并推送实时数据给浏览器;
二、数据处理和Python操作Kafka
-
数据集
数据集下载
-
数据预处理
文件目录:./scripts/producer.py
# coding: utf-8
import csv
import time
from kafka import KafkaProducer
# 实例化一个KafkaProducer示例,用于向Kafka投递消息
producer = KafkaProducer(bootstrap_servers='localhost:9092')
# 打开数据文件
csvfile = open("../data/user_log.csv","r")
# 生成一个可用于读取csv文件的reader
reader = csv.reader(csvfile)
for line in reader:
gender = line[9] # 性别在每行日志代码的第9个元素
if gender == 'gender':
continue # 去除第一行表头
time.sleep(0.1) # 每隔0.1秒发送一行数据
# 发送数据,topic为'sex'
producer.send('sex',line[9].encode('utf8'))文件目录:./scripts/consumer.py
from kafka import KafkaConsumer
consumer = KafkaConsumer('sex')
for msg in consumer:
print((msg.value).decode('utf8'))-
运行
开启Kafka:
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.propertiescd /usr/local/kafka
bin/kafka-server-start.sh config/server.properties使用vscode启动生产者和消费者:
PS:由于vscode运行文件时通常只会在一个终端上运行,这无法满足同时运行生产者和消费者的需求,所以需要在vscode里使用两个终端来运行。
运行结果:
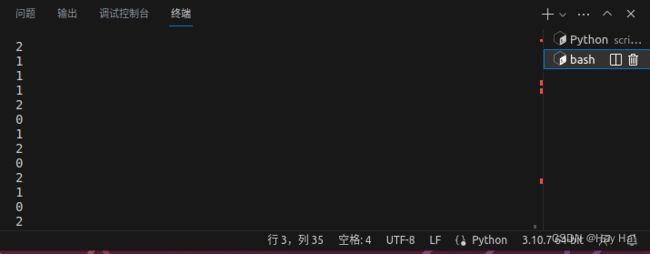
三、 Structured Streaming实时处理数据
-
建立pyspark项目
cd /usr/local/spark/mycode
mkdir kafka修改Spark配置文件
cd /usr/local/spark/conf
sudo vim spark-env.sh配置Spark开发Kafka环境 下载
把下载的代码库放到目录/usr/local/spark/jars目录下
sudo mv ~/下载/spark-streaming_2.12-3.2.0.jar /usr/local/spark/jars
sudo mv ~/下载/spark-streaming-kafka-0-10_2.12-3.2.0.jar /usr/local/spark/jars把 Kafka 相关 jar 包的路径信息增加到 spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoopclasspath):/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*在当前目录创建kafka_test.py文件
from kafka import KafkaProducer
from pyspark.streaming import StreamingContext
#from pyspark.streaming.kafka import KafkaUtils
from pyspark import SparkConf, SparkContext
import json
import sys
from pyspark.sql import DataFrame
from pyspark.sql import SparkSession
from pyspark.sql.functions import window
from pyspark.sql.types import StructType, StructField
from pyspark.sql.types import TimestampType, StringType
from pyspark.sql.functions import col, column, expr
def KafkaWordCount(zkQuorum, group, topics, numThreads):
spark = SparkSession \
.builder \
.appName("KafkaWordCount") \
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
topicAry = topics.split(",")
# 将topic转换为hashmap形式,而python中字典就是一种hashmap
topicMap = {}
for topic in topicAry:
topicMap[topic] = numThreads
#lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(lambda x : x[1])
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "sex") \
.load()
df.selectExpr( "CAST(timestamp AS timestamp)","CAST(value AS STRING)")
#lines = df.selectExpr("CAST(value AS STRING)")
windowedCounts = df \
.withWatermark("timestamp", "1 seconds") \
.groupBy(
window(col("timestamp"), "1 seconds" ,"1 seconds"),
col("value")) \
.count()
wind = windowedCounts.selectExpr( "CAST(value AS STRING)","CAST(count AS STRING)")
query = wind.writeStream.option("checkpointLocation", "/check").outputMode("append").foreach(sendmsg).start()
query.awaitTermination()
query.stop()
# 格式转化,将格式变为[{1: 3}]
def Get_dic(row):
res = []
#for elm in row:
tmp = {row[0]: row[1]}
res.append(tmp)
print(res)
return json.dumps(res)
def sendmsg(row):
print(row)
if row.count != 0:
msg = Get_dic(row)
# 实例化一个KafkaProducer示例,用于向Kafka投递消息
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send("result", msg.encode('utf8'))
# 很重要,不然不会更新
producer.flush()
if __name__ == '__main__':
# 输入的四个参数分别代表着
# 1.zkQuorum为zookeeper地址
# 2.group为消费者所在的组
# 3.topics该消费者所消费的topics
# 4.numThreads开启消费topic线程的个数
if (len(sys.argv) < 5):
print("Usage: KafkaWordCount ")
exit(1)
zkQuorum = sys.argv[1]
group = sys.argv[2]
topics = sys.argv[3]
numThreads = int(sys.argv[4])
print(group, topics)
KafkaWordCount(zkQuorum, group, topics, numThreads)
在当前目录创建脚本文件startup.sh
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.0 /usr/local/spark/mycode/kafka/kafka_test.py 127.0.0.1:2181 1 sex 1-
运行
启动HDFS
cd /usr/local/hadoop #这是hadoop的安装目录
./sbin/start-dfs.sh启动Kafka
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.propertiescd /usr/local/kafka
bin/kafka-server-start.sh config/server.properties运行脚本
sh startup.sh更改consumer.py文件
from kafka import KafkaConsumer
consumer = KafkaConsumer('result')
for msg in consumer:
print((msg.value).decode('utf8'))运行生产者消费者程序
vscode运行生产者和消费者文件
运行结果
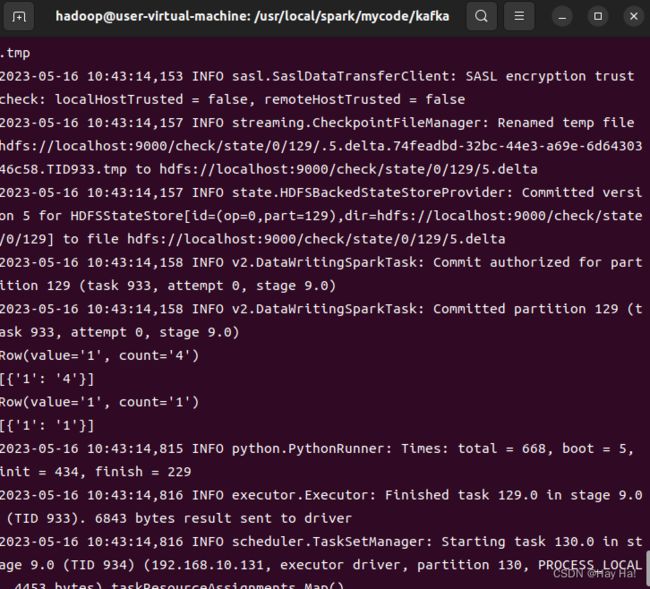 脚本运行效果图
脚本运行效果图
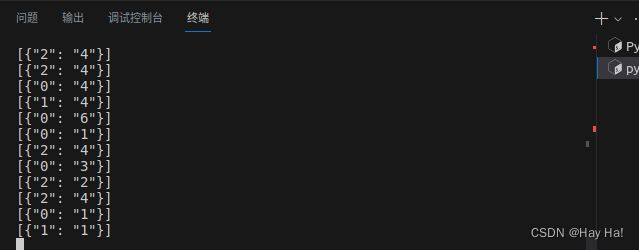 消费者终端运行效果图
消费者终端运行效果图
四、结果展示
-
环境准备
源码下载
PS:解压下载文件,将里面有关js库的文件导入到项目中
-
app.py文件源码
import json
from flask import Flask, render_template
from flask_socketio import SocketIO
from kafka import KafkaConsumer
# 因为第一步骤安装好了flask,所以这里可以引用
app = Flask(__name__)
app.config['SECRET_KEY'] = 'secret!'
socketio = SocketIO(app)
thread = None
# 实例化一个consumer,接收topic为result的消息
consumer = KafkaConsumer('result')
# 一个后台线程,持续接收Kafka消息,并发送给客户端浏览器
def background_thread():
girl = 0
boy = 0
for msg in consumer:
data_json = msg.value.decode('utf8')
data_list = json.loads(data_json)
for data in data_list:
if '0' in data.keys():
girl = data['0']
elif '1' in data.keys():
boy = data['1']
else:
continue
result = str(girl) + ',' + str(boy)
print(result)
socketio.emit('test_message', {'data': result})
# 客户端发送connect事件时的处理函数
@socketio.on('test_connect')
def connect(message):
print(message)
global thread
if thread is None:
# 单独开启一个线程给客户端发送数据
thread = socketio.start_background_task(target=background_thread)
socketio.emit('connected', {'data': 'Connected'})
# 通过访问http://127.0.0.1:5000/访问index.html
@app.route("/")
def handle_mes():
return render_template("index.html")
# main函数
if __name__ == '__main__':
socketio.run(app, debug=True)-
index.html文件源码
DashBoard
Girl:
Boy:
-
效果展示
启动Kafka
cd /usr/local/kafka
bin/zookeeper-server-start.sh config/zookeeper.propertiescd /usr/local/kafka
bin/kafka-server-start.sh config/server.properties启动HDFS
cd /usr/local/hadoop #这是hadoop的安装目录
./sbin/start-dfs.sh启动脚本
sh startup.sh运行生产者和消费者程序
vscode运行生产者和消费者文件
运行app.py程序

最终效果展示
网页端效果图
 在HDFS的WEB页面可以看到check的文件
在HDFS的WEB页面可以看到check的文件
五、补充说明
如果想多次运行这个程序,但出现运行脚本时报错可以考虑以下几个方面
- 出现如下图所示错误:即Name node is in safe mode.
HDFS处于安全模式时无法对文件进行修改,可以等待一段时间再运行脚本(上图并非本人提供)
- 若无上述的错误,但运行仍然失败
考虑将kafka_test.py的下图代码里的"/check"更改为其他名称,例如:"/check1",这可能是因为HDFS里文件重复导致的问题。
query = wind.writeStream.option("checkpointLocation", "/check").outputMode("append").foreach(sendmsg).start()