BERT学习笔记
BERT全称为Bidirectional Encoder Representations from Transformers,是Google在2018年提出的一种新的语言表示方法。它结合了Transformer网络结构和大规模无标注数据,实现了语言的深度双向表示学习。BERT让 Transformer 在 NLP 上有了更广泛的应用,特别是在语言理解方面有了很大提高,标志着NLP进入了新时代。
目录
0 ELMO
1 总体概述
2 模型基本原理
2.1 网络结构
2.2 训练目标:
3 Masking Input
4 Next Sentence Prediction
5 应用场景
5.1 case1 Sentiment analysis(情感分析)
5.2 case2 POS tagging(词性标注)
5.3 case3 Natural Language Inferencee (NLI 自然语言推理)
5.4 case4 Extraction-based Question Answering (QA)
6 总结:
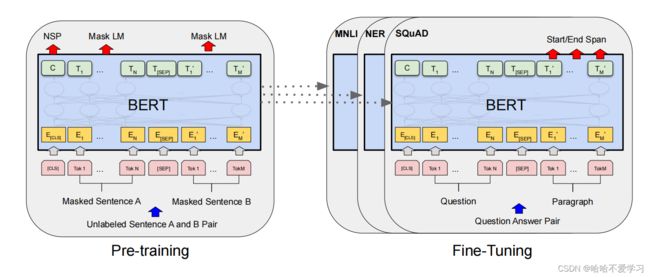
6.1 预训练
6.1 Fine-tuning
7 参考:
0 ELMO
词嵌入的局限性:机械地确定一个词有几个词义是困难的,不可能涵盖所有的意思
学习bert模型时,不可避免的会对与ELMO进行对比,下面对ELMO进行一个简单的介绍:
ELMo是一种用于语言理解的深度上下文语言模型,由Peters等人在2018年提出。ELMo利用双向语言模型学习上下文相关的词语表示,这些表示可以应用于nlp的各种下游任务中,并取得很好的效果。
ELMo的主要思想是:使用一个预训练的LSTM来学习语言模型,所学出的语言模型包含了丰富的语言上下文信息。然后利用这个语言模型的中间层输出作为输入文本的人特征表示,并直接用于各种NLP下游任务。具体来说,ELMo由以下几个步骤组成:
- 使用大规模语料训练语言模型(双向LSTM),得到前向和后向的语言模型。
- 对于输入文本,利用上一步学到的前向和后向语言模型进行前向和后向推理,得到每个token的上下文表示。
- 将上一步得到的前向和后向的上下文表示拼接,作为输入文本的语义表示,用于NLP下游任务。
- 下游任务直接使用步骤3产生的文本语义表示,无需对ELMo进行fine-tuning。
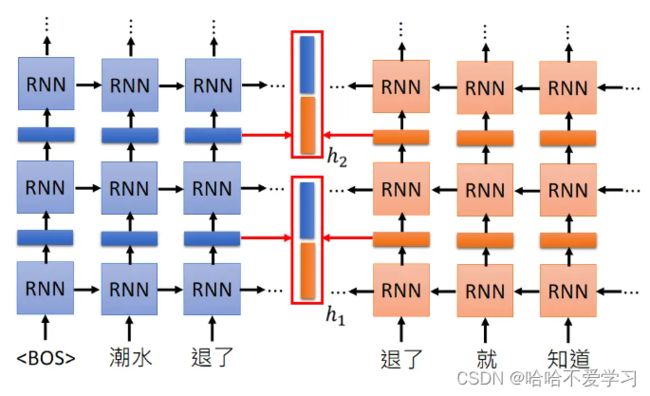
该RNN结构输入后一个词来输出前一个词,然后将上面的RNN结构输出的embedding与这个RNN结构的embedding拼接到一起,就获得了同时考虑上下文的词的embedding,过程也是可以“deep”的,如上图的网络结构,每一个隐藏层都会输出一个词的embedding,对于每一个embedding是全部都会被使用的
1 总体概述
BERT代表了近年来NLP最重要的进展之一,它提出了以下关键思想:
- 使用Transformer结构,基于注意力机制捕获远距离依赖和句法关系,更易建模。这是一个并行化结构,计算效率高
- 采用Mask语言模型和Next句子预测两种无监督的训练目标,利用双向上下文学习语义信息,得到强语义表征的BERT编码。
- 在大规模语料上pretrain BERT,然后对下游任务进行简单的fine-tuning,快速得到高性能的NLP系统。这种预训练再fine-tuning的方式大大减轻了实际应用的难度。
- 无需任何监督学习,使用通用的预训练和下游特定任务的微调,BERT在各种任务上均达到了当时SOTA的效果,如GLUE基准和SQuAD数据。这证明了其泛化能力和有效性,BERT带来的提升使NLP有了质的飞跃。

2 模型基本原理
2.1 网络结构
BERT采用Transformer结构,基于自注意力机制建模语言。Transformer结构包含Encoder和Decoder,BERT只使用Encoder。Encoder由多层自注意力和前馈神经网络组成。这种结构更易于并行化,可以更好捕获远距离依赖和句法结构。
2.2 训练目标:
BERT使用两个无监督的训练目标:
(1) Masked Language Model:将输入句子中的某些token随机替换为[MASK],然后基于上下文预测这些被替换的token。学习局部语义和上下文依赖关系。这有助于BERT理解每个词的表达
(2) Next Sentence Prediction:给定一对句子A和B,判断B是否是A的下一句。这可以学习句子之间的关系,捕获上下文信息,有助于BERT在文档层面上理解语言。
两个任务分别从局部和全局两个角度推动BERT学习语言表达。它们共同作用于BERT,使其对语言有较为全面和深入的理解。
3 Masking Input
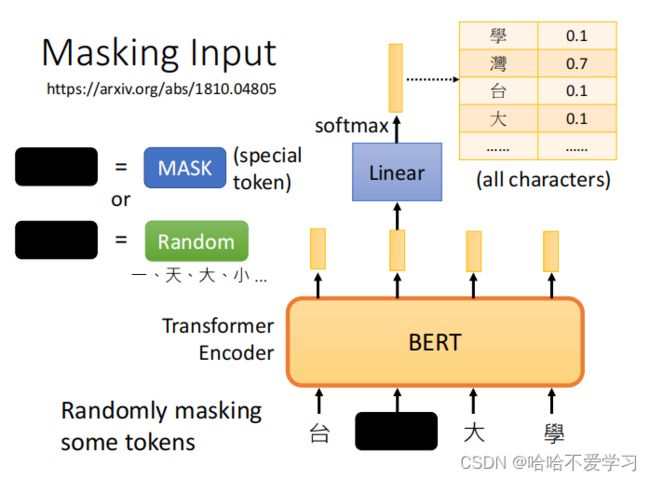
为了训练深度双向表示,我们只需随机屏蔽一定比例的输入token,然后基于句子的上下文预测这些被遮蔽的词。这可以让BERT学习上下文中的语义信息,从而学习语言表达的能力。这个过程称为:“masked LM” (MLM)
在BERT的Masked LM任务中,遮蔽词的比例与策略如下:
- 1遮蔽词的比例为15%。即在每个输入句子中,随机遮蔽15%的词。
- 除了遮蔽的15%词外,其他词不进行处理。
- 对不同词性的词采取不同的遮蔽策略:
- (1) 对80%的词采用随机遮蔽。这80%的词主要是普通词与实体。
- (2) 对10%的词采用确定性遮蔽。这10%的词主要是高频词,遮蔽它们可以缓解数据稀疏问题。
- (3) 对10%的词采用不遮蔽。主要是低频词,如果遮蔽它们模型的预测会很难,相当于增加了模型难度。
- (4) [CLS]、[SEP]等特殊词不遮蔽。
上述图片就是遮住“台湾大学”中的湾字,经过BERT模型,输出它的embedding vector,经过linear 和softmax生成各个可能字的概率。

T5采取多种随机遮蔽方式(遮掩、删除关键字、重新排列、逆转、同义词替换),遮蔽位置标注为
4 Next Sentence Prediction
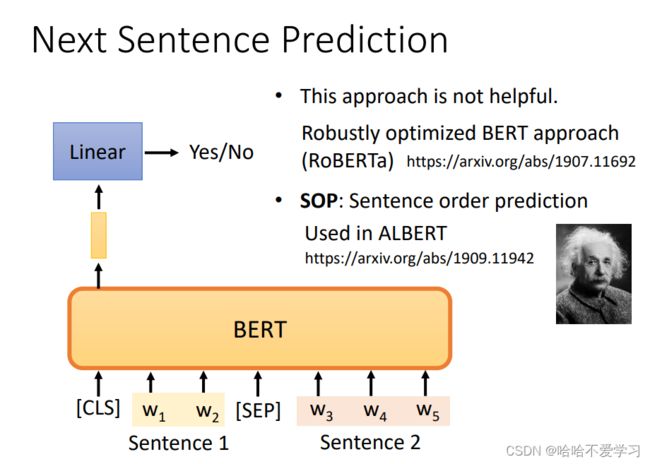
Next Sentence Prediction(下文预测)是BERT中的另一个无监督训练目标。它的主要思想是:给定一对句子A和B,判断B是否是A的下一句。这可以让BERT学习句子之间的关系和上下文语义信息,从而学习语言表达的能力。具体来说,Next Sentence Prediction任务包含以下几个步骤:
- 构建输入数据:[CLS] + A + [SEP] + B + [SEP]。A和B可以是真实的下一句,也可以不是。
- 将输入数据输入BERT模型。BERT产生每个词的预测,以及整个句子的预测。
- 整个句子的预测会判断B是否是A的下一句。预测为True或者False。
- 计算整个句子预测的二分类交叉熵loss,作为模型的训练loss。
- BERT根据此loss进行反向传播与参数更新。
RoBERTa:判断两个句子是不是拼接的,比较容易,用的少
ALBERT:判断两个句子的前后关系,用的比较多
5 应用场景
5.1 case1 Sentiment analysis(情感分析)

输入一个句子,进行情感分析。比如给一个句子判断是正面还是负面。
可以将句子输入到BERT,第一个token设置为[CLS]表示句子的分类,将这个toke对应输出的embedding输入到一个线性分类器中进行分类。线性分类器要从头开始训练,BERT的参数只需要微调即可。
5.2 case2 POS tagging(词性标注)
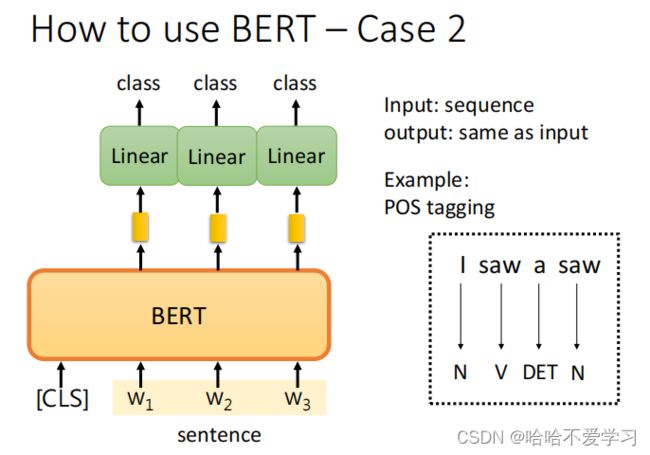
输入一个句子,输出每个单词的词性。
- 在BERT的输入序列中,每个子词embedding之后添加其真实的词性标注。
- Embedding和词性标注之间使用特殊分隔符[SEP]连接。将连接后的输入序列输入到BERT模型中。BERT会对每个子词产生一个词性预测。
- 计算每个子词的词性预测与真实词性标注之间的交叉熵损失。这个loss用来更新BERT的网络参数。
- 根据损失进行反向传播并更新BERT模型的参数。
- 在测试集上评估BERT的词性标注性能,比如准确率、召回率等评价指标。
5.3 case3 Natural Language Inferencee (NLI 自然语言推理)
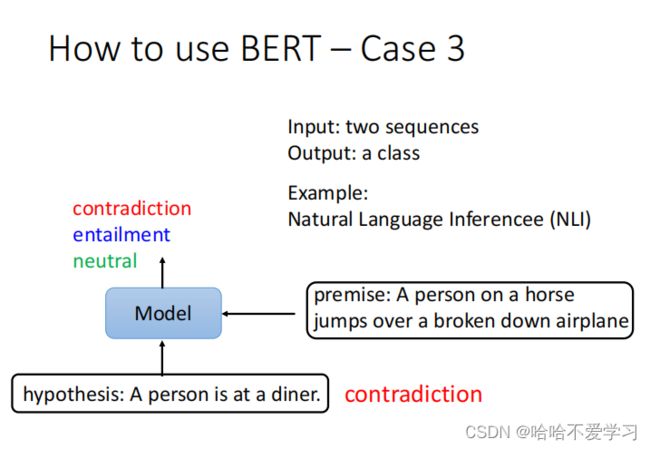
输入两个句子,输出一个类别判断两个句子的关系(矛盾?蕴涵?中性?)
- 前提:骑在马上的人,跳过一架坏掉的飞机
- 假设:一个人在吃晚餐
- 输出:矛盾
BERT可以用于自然语言推理(Natural Language Inference, NLI)任务。主要的方法步骤如下:
- 收集NLI数据集,如SNLI和MNLI数据集。这些数据集包含句对及其推理关系(蕴含、矛盾、中性)。
- 将前提句P和假设句H连续输入到BERT模型中,用[SEP]分隔。
- BERT会对输入的句对产生一个推理关系的预测。
- 将BERT的推理关系预测与句对的真实关系进行比较,计算二分类或三分类的交叉熵损失。
- 根据损失进行反向传播并更新BERT模型的参数。
- 在验证集和测试集上评估BERT的NLI性能,主要采用准确率作为评价指标。

5.4 case4 Extraction-based Question Answering (QA)

输入一段文字和一个问题,输出这个问题在原文的答案
具体做法是:
- 1) 对输入文段和问题进行编码,获取对应的序列表示。使用CLS token表示文段。
- 2) 对CLS token表示使用两个全连接层得到s和e向量。(s和e向量的维度由BERT模型的隐层大小决定。对于BERT-Base为768)
- s向量对应答案开始位置预测。
- e向量对应答案结束位置预测。
- 3) 对s和e向量使用softmax得到开始位置和结束位置的概率分布预测。
- 从s的概率分布中选取概率最高位置作为开始位置预测。
- 从e的概率分布中选取概率最高位置作为结束位置预测。
- 4) 输出开始位置和结束位置的预测。
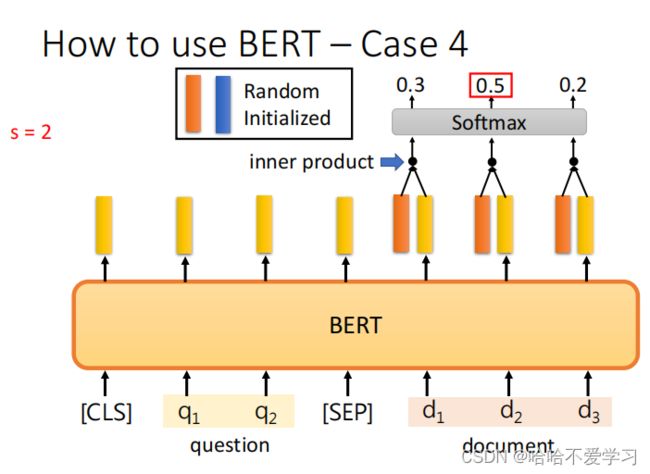
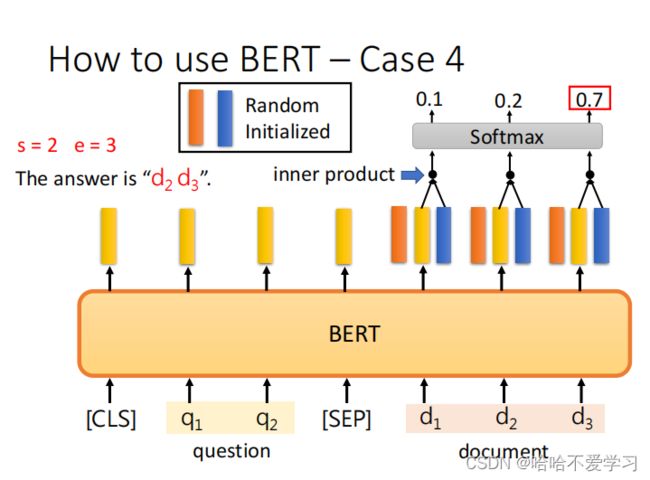
BERT可以用于问答(Question Answering, QA)任务。主要的方法步骤如下:
- 收集QA数据集,如SQuAD,其中包含文段、问题和答案位置。
- 将文段和问题连续输入BERT,用[SEP]分隔。
- BERT对输入的文段和问题产生答案开始位置和结束位置的预测。
- 计算BERT的预测与真实答案位置的损失,如交叉熵损失或其他距离损失。
- 根据损失更新BERT的模型参数。
- 在验证集和测试集上评估BERT的QA性能。
6 总结:
BERT通过Masked Language Model和Next Sentence Prediction两种任务进行预训练,然后通过简单的Fine-tuning应用到下游任务中,因此它主要有下面两个阶段:
- 1) 预训练阶段:通过大规模无标注数据和MLM与NSP任务学习语言表达。
- 2) 微调阶段:通过下游任务的数据集和相关损失微调BERT的参数,完成对新任务的适应。
6.1 预训练
BERT是通过Masked LM和Next Sentence Prediction两个无监督任务进行预训练的。其预训练流程如下:
- 收集大规模无标注语料进行预训练,例如Wikipedia和Book Corpus等。
- 从语料中采样输入序列,采样长度在512个token以内。如果一个序列超过512个token,则按512个token分片,每个分片作为一个实例。
- 对输入序列进行Mask操作,随机遮蔽15%的token。遮蔽策略按80%随机遮蔽,10%高频词遮蔽,10%低频词不遮蔽。
- 构建预训练实例。对输入序列采用两种方法构建实例:(1)MASKED LM实例:[CLS]+输入序列+[SEP]+[Mask1] [Mask2]...。需要预测Mask位置的词。(2)NEXT SENTENCE实例:[CLS]+句子A+[SEP]+句子B+[SEP]。需要判断B是否为A的下一句。
- 将构建好的预训练实例输入BERT模型。
- 对MASKED LM实例,计算Mask位置预测的损失,作为模型的训练loss。对NEXT SENTENCE实例,计算二分类交叉熵损失,作为模型的训练loss。
- 根据损失进行反向传播与参数更新。
- 重复步骤2-7,持续预训练BERT模型。
- 在大规模语料上预训练BERT后,得到通用的语言表达能力。然后在下游任务上进行简单的Fine-tuning,快速得到高性能的NLP系统。
6.1 Fine-tuning
主要步骤如下:
- 收集下游任务的数据集,如SQuAD用于问答和GLUE数据集用于推理。
- 将数据集的输入文本序列输入BERT,并添加任务相关的输出层及损失函数。
- 根据任务输出层和损失函数的结果,通过反向传播更新BERT模型的参数。这时只更新BERT输出层后的参数,其余参数保持预训练的参数值。
- 在验证集上评估模型性能,并根据性能选择最终模型。
- 在测试集上报告最终模型的性能,如准确率和F1 score等指标。
7 参考:
ELMO,BERT,GPT|深度学习(李宏毅)(十) - 简书 (jianshu.com)
2021 - 自监督式学习 (二) – BERT简介_哔哩哔哩_bilibili