基于spark的音乐数据分析系统的设计与实现
收藏关注不迷路
文章目录
- 前言
- 一、项目介绍
- 二、开发环境
- 三、功能介绍
- 四、核心代码
- 五、效果图
- 六、文章目录
前言
本文主要对音乐数据,进行分析,系统技术主要使用,1.对原始数据集进行预处理;3.使用python语言编写Spark程序对HDFS中的数据进行处理分析,并把分析结果写入到MySQL数据库;4.利用Spark MLlib进行数据和关系预测;5.利用IntelliJ IDEA搭建动态Web应用;6.利用plotly进行前端可视化分析。
关键词:音乐数据分析;可视化分析;python语言
一、项目介绍
本文对网易云音乐平台的数据进行分析,分析年度音乐专辑销量TOP10 ;年度月排行榜榜首播放量;最受欢迎的音乐类型;音乐评论数TOP榜;用户性别比例。使用Hadoop提供HDFS的分布式存储[10],利用Spark对HDFS中的数据进行处理,并对结果进行可视化分析。
音乐数据分析系统的设计开发工作:
- 网易云音乐数据爬虫。在本课题中,需要爬取的数据主要包括音乐数据、用户数据、评论数据等等,每一种类型的数据对应一个爬取接口。使用Python进行数据清洗。这三种类型的数据分别应用于不同的功能中。
- 将前面爬取到的数据作为数据源,上传到HDFS文件系统上。
- 使用Scala语言编写Spark程序对数据进行分析处理。可以从多个角度对网易云音乐的现有数据进行有效的信息挖掘,并加以分析。
- 恰当的数据可视化展示。当分析出数据结论之后,采用合适的方式去展示最终的结果数据。比如可以使用柱状图、折线图、词云图、饼状图等阐释数据的特点。
二、开发环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
————————————————
三、功能介绍
整个音乐流量可视化系统,主要包含前台和后台,前台是可视化数据,呈现大屏幕效果,主要包含了音乐数据的分析,以及音乐播放量分析,音乐专辑分析,用户登录信息,后台包含登录注册功能,以及个人中心修改资料,音乐数据添加,对用户的删除和查看,音乐数据的预测分析,以及系统权限的设置,具体如下图所示。
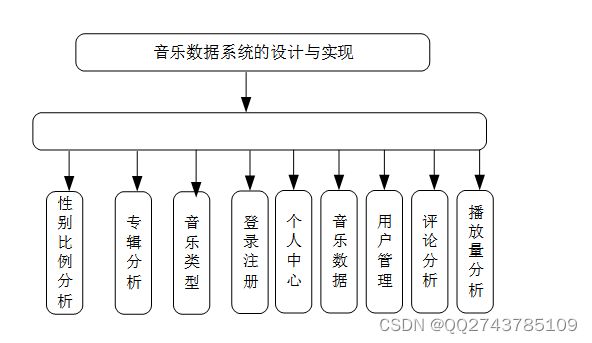
图4-1音乐数据分析系统的分析
四、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
五、效果图
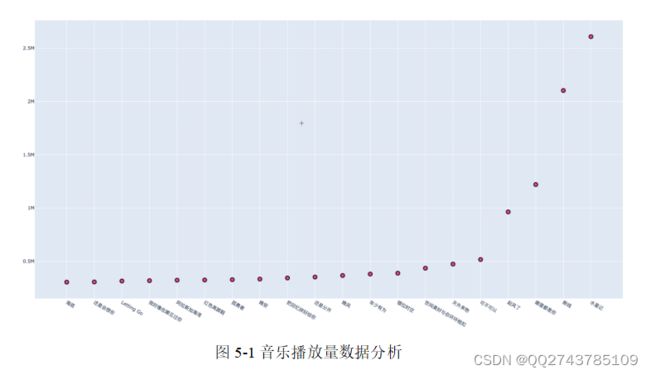

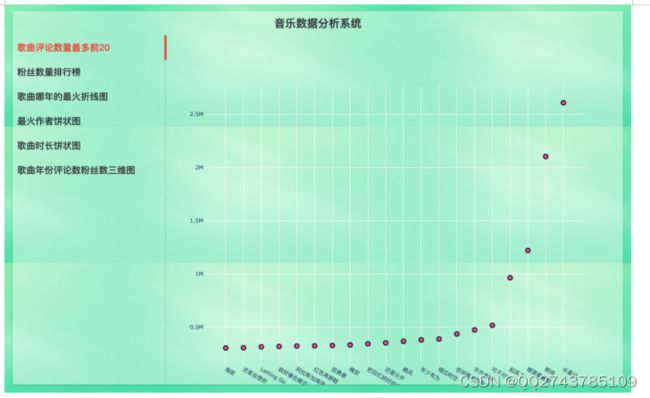
歌曲评论数最多前20

粉丝数量排行榜
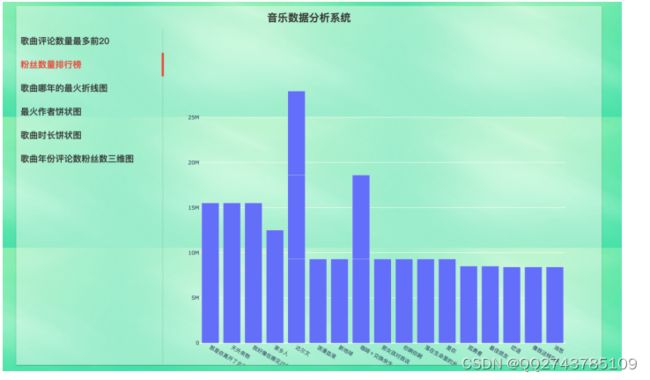
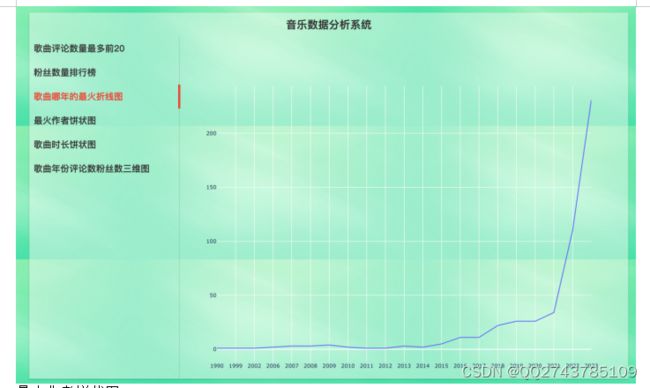
哪年歌曲最火折线图
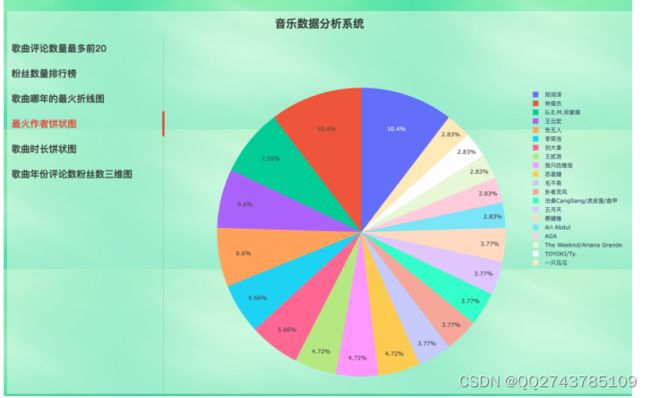
最火作者饼状图
歌曲时长饼状图
六、文章目录
目录
1绪论 1
1.1研究背景 1
1.2研究意义 2
1.3研究现状 3
1.3.1国内外研究现状分析 3
1.3.2国外研究现状 3
2.1HDFS集群 5
2.2python 5
2.3spark 5
2.4hadpoop 6
2.5Eharts 6
3需求分析 7
3.1 可行性分析 7
3.1.1 技术可行性 7
3.1.2 操作可行性 7
3.1.3 经济可行性 7
3.2 系统需求分析 7
3.3用例分析 8
4系统数据库 10
4.1数据库表单 10
4.2系统E-R图 13
4系统详细设计 15
4.1系统架构 15
4.2爬虫分析 15
4.3数据可视化 16
4.4系统登录流程 17
4.5预测分析流程 18
5.系统实现 19
5.1实时动态分析效果 19
5.2后台登录 19
5.3后台首页 20
5.4预测分析 21
5.5音乐数据分析 21
6 系统测试 23
6.1 测试目的 23
6.2 测试方法 23
6.3 登录测试 23
6.4 集成测试 24
总结 25
参考文献 26
致 谢 28