AWS DynamoDB基本原理和操作
文章目录
- DynamoDB介绍
-
- 主键
- 二级索引
- DynamoDB Streams
- DynamoDB API
-
- PartiQL - 一种与 SQL 兼容的查询语言
- 经典 API
-
- 创建数据
- 读取数据
- 更新数据
- 删除数据
- DynamoDB Streams
- 事务
-
- PartiQL - 一种与 SQL 兼容的查询语言
- 经典 API
- Amazon DynamoDB 中支持的数据类型和命名规则
-
- 数据类型
- 标量类型
- 数字
- 字符串
- Binary
- 布尔值
- Null
- 文档类型
- 列表
- 映射
- 集
- 读取一致性
-
- 最终一致性读取
- 强一致性读取
- 分区和数据分配
-
- 数据分配:分区键
- 数据分配:分区键和排序键
- DynamoDB数据库的特点
- DynamoDB操作
-
- SQL
- DynamoDB
- 获取有关表的信息
-
- SQL
- DynamoDB
- 将数据写入表
-
- SQL
- DynamoDB
- 从表中读取数据时的主要区别
- 使用项目的主键读取项目
- 查询表
-
- DynamoDB API
- PartiQL for DynamoDB
- 扫描表(慎用)
- 修改表中的数据
- 从表中删除数据
- 删除表(慎用)
DynamoDB介绍
DynamoDB 允许您自动从表中删除过期项目,请参阅 使用 DynamoDB 生存时间 (TTL) 让项目过期。
DynamoDB 自动将表的数据和流量分布到足够数量的服务器上,所有数据项目均存储在固态硬盘 (SSD) 中,并自动复制到某个 AWS 区域的多个可用区,以便提供数据自身的高可用性和数据持久性。
在 DynamoDB 中,表、项目和属性是您使用的核心组件。表是项目的集合,而每个项目是属性的集合。
主键
DynamoDB 支持两种不同类型的主键:
分区键 – 由一个称为分区键的属性构成的简单主键。
分区键和排序键 – 称为复合主键,此类型的键由两个属性组成。第一个属性是分区键,第二个属性是排序键。
项目的分区键也称为其哈希属性。哈希属性一词源自 DynamoDB
中使用的内部哈希函数,以基于数据项目的分区键值实现跨多个分区的数据项目平均分布。项目的排序键也称为其范围属性。范围属性一词源自 DynamoDB
存储项目的方式,它按照排序键值有序地将具有相同分区键的项目存储在互相紧邻的物理位置。
二级索引
DynamoDB 支持两种索引:
全局二级索引 – 分区键和排序键可与基表中的这些键不同的索引。
本地二级索引 – 分区键与基表相同但排序键不同的索引。
DynamoDB 中的每个表具有 20 个全局二级索引(默认配额)和 5 个本地二级索引的配额。
DynamoDB Streams
DynamoDB Streams 是一项可选功能,用于捕获 DynamoDB 表中的数据修改事件。有关这些事件的数据将以事件发生的顺序近乎实时地出现在流中。
每个事件由一条流记录 表示。如果您对表启用流,则每当以下事件之一发生时,DynamoDB Streams 都会写入一条流记录:
-
向表中添加了新项目:流将捕获整个项目的映像,包括其所有属性。
-
更新了项目:流将捕获项目中已修改的任何属性的“之前”和“之后”映像。
-
从表中删除了项目:流将在整个项目被删除前捕获其映像。
每条流记录还包含表的名称、事件时间戳和其他元数据。流记录具有 24 个小时的生命周期;在此时间过后,它们将从流中自动删除。
测试TTL方式,是否可以捕捉数据变化。待验证!
您可以将 DynamoDB Streams 与 AWS Lambda 结合使用以创建触发器—在流中有您感兴趣的事件出现时自动执行的代码。
例如,假设有一个包含某公司客户信息的 Customers 表。假设您希望向每位新客户发送一封“欢迎”电子邮件。您可对该表启用一个流,然后将该流与 Lambda 函数关联。Lambda 函数将在新的流记录出现时执行,但只会处理添加到 Customers 表的新项目。对于具有 EmailAddress 属性的任何项目,Lambda 函数将调用 Amazon Simple Email Service (Amazon SES) 以向该地址发送电子邮件。
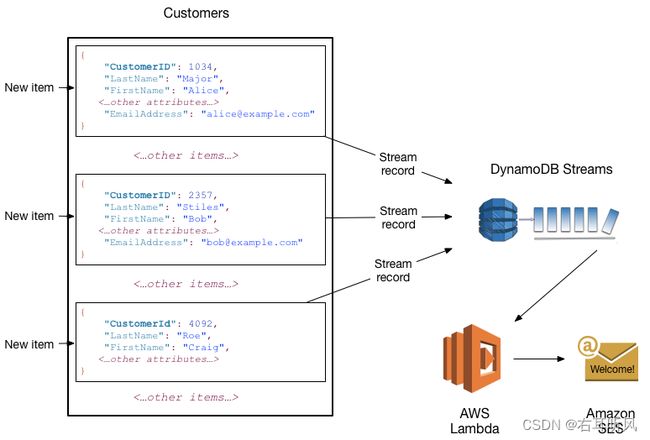
注意 在此示例中,最后一位客户 Craig Roe 将不会收到电子邮件,因为他没有 EmailAddress。
除了触发器之外,DynamoDB Streams 还提供了强大的解决方案,例如,AWS 区域内和区域之间的数据复制、DynamoDB 表中的数据具体化视图、使用 Kinesis 具体化视图的数据分析等。
DynamoDB API
控制层面操作可让您可以创建和管理 DynamoDB 表。还可以支持您使用依赖于表的索引、流和其他对象。
-
CreateTable – 创建新表。或者,您也可以创建一个或多个二级索引并为表启用 DynamoDB Streams。
-
DescribeTable– 返回有关表的信息,例如,表的主键架构、吞吐量设置和索引信息。
-
ListTables – 返回列表中您的所有表的名称。
-
UpdateTable – 修改表或其索引的设置、创建或删除表上的新索引或修改表的 DynamoDB Streams 设置。
-
DeleteTable – 从 DynamoDB 中删除表及其所有依赖对象。
数据层面 操作可让您对表中的数据执行创建、读取、更新和删除(也称为 CRUD)操作。某些数据层面操作还可从二级索引读取数据。
您可以使用 PartiQL - 用于 Amazon DynamoDB 的 SQL 兼容语言 来执行这些 CRUD 操作,也可以使用 DynamoDB 的经典 CRUD API,将每个操作分离为不同的 API 调用。
PartiQL - 一种与 SQL 兼容的查询语言
-
ExecuteStatement— 从表中读取多个项目。您还可以写入或更新表的单个项目。当写入或更新单个项目时,您必须指定主键属性。
-
BatchExecuteStatement— 写入、更新或读取表中的多个项目。这比 ExecuteStatement
更有效,因为您的应用程序只需一个网络往返行程即可写入或读取项目。
经典 API
创建数据
-
PutItem - 将单个项目写入表中。您必须指定主键属性,但不必指定其他属性。
-
BatchWriteItem – 将最多 25 个项目写入到表。这比多次调用 PutItem
更有效,因为您的应用程序只需一个网络往返行程即可写入项目。您还可以使用 BatchWriteItem 来从一个或多个表中删除多个项目。
读取数据
-
GetItem - 从表中检索单个项目。您必须为所需的项目指定主键。您可以检索整个项目,也可以仅检索其属性的子集。
-
BatchGetItem – 从一个或多个表中检索最多 100 个项目。这比多次调用 GetItem
更有效,因为您的应用程序只需一个网络往返行程即可读取项目 -
Query -
检索具有特定分区键的所有项目。您必须指定分区键值。您可以检索整个项目,也可以仅检索其属性的子集。或者,您也可以对排序键值应用条件,以便只检索具有相同分区键的数据子集。您可以对表使用此操作,前提是该表同时具有分区键和排序键。您还可以对索引使用此操作,前提是该索引同时具有分区键和排序键。 -
Scan -
检索指定表或索引中的所有项目。您可以检索整个项目,也可以仅检索其属性的子集。或者,您也可以应用筛选条件以仅返回您感兴趣的值并放弃剩余的值。
更新数据
- UpdateItem -
修改项目中的一个或多个属性。您必须为要修改的项目指定主键。您可以添加新属性并修改或删除现有属性。您还可以执行有条件更新,以便更新仅在满足用户定义的条件时成功。或者,您也可以实施一个原子计数器,该计数器可在不干预其他写入请求的情况下递增或递减数字属性。
删除数据
-
DeleteItem - 从表中删除单个项目。您必须为要删除的项目指定主键。
-
BatchWriteItem – 从一个或多个表中删除最多 25 个项目。这比多次调用 DeleteItem
更有效,因为您的应用程序只需一个网络往返行程即可删除项目。您也可以使用 BatchWriteItem 来向一个或多个表添加多个项目。
注意
您可以使用 BatchWriteItem 创建数据和删除数据。
DynamoDB Streams
DynamoDB Streams 操作可让您对表启用或禁用流,并能允许对包含在流中的数据修改记录的访问。
- ListStreams - 返回您的所有流的列表,或仅返回特定表的流。
- DescribeStream - 返回有关流的信息,例如,流的 Amazon Resource Name (ARN)
和您的应用程序可开始读取前几条流记录的位置。 - GetShardIterator – 返回一个分片迭代器,这是您的应用程序用来从流中检索记录的数据结构。
- GetRecords - 使用给定分片迭代器检索一条或多条流记录。
事务
事务 提供原子性、一致性、隔离性和持久性 (ACID),使您能够更轻松地维护应用程序中的数据正确性。
您可以使用 PartiQL - 用于 Amazon DynamoDB 的 SQL 兼容语言 来执行事务操作,也可以使用 DynamoDB 的经典 CRUD API,将每个操作分离为不同的 API 调用。
PartiQL - 一种与 SQL 兼容的查询语言
ExecuteTransaction – 一种批处理操作,用于在表内和跨表对多个项目执行 CRUD 操作,并保证得到全有或全无结果。
经典 API
- TransactWriteItems – 一种批处理操作,用于在表内和跨表对多个项目执行 Put、Update 和 Delete
操作,并保证得到全有或全无结果。 - TransactGetItems – 一种批处理操作,用于执行 Get 操作以从一个或多个表检索多个项目。
Amazon DynamoDB 中支持的数据类型和命名规则
DynamoDB 的命名规则:
所有名称都必须使用 UTF-8 进行编码,并且区分大小写。
表名称和索引名称的长度必须介于 3 到 255 个字符之间,而且只能包含以下字符:
a-z
A-Z
0-9
_ (下划线)
- (短划线)
. (圆点)
数据类型
DynamoDB 对表中的属性支持很多不同的数据类型。可按以下方式为属性分类:
- 标量类型 - 标量类型可准确地表示一个值。标量类型包括数字、字符串、二进制、布尔值和 null。
- 文档类型 - 文档类型可表示具有嵌套属性的复杂结构,例如您将在 JSON 文档中找到的结构。文档类型包括列表和映射。
- 集类型 - 集类型可表示多个标量值。集类型包括字符串集、数字集和二进制集。
DynamoDB 是 NoSQL 数据库并且无架构。这意味着,与主键属性不同,您无需在创建表时定义任何属性或数据类型。与此相对,关系数据库要求您在创建表时定义每个列的名称和数据类型。
标量类型
标量类型包括数字、字符串、二进制、布尔值和 null。
数字
数字可为正数、负数或零。数字最多可精确到 38 位。超过此位数将导致异常。
正数范围:1E-130 到 9.9999999999999999999999999999999999999E+125
负数范围:-9.9999999999999999999999999999999999999E+125 到 -1E-130
在 DynamoDB 中,数字以可变长度形式表示。系统会删减开头和结尾的 0。
字符串
字符串是使用 UTF-8 二进制编码的 Unicode。如果属性未用作索引或表的键,并且受最大 DynamoDB 项目大小限制 400 KB 的约束,则字符串的最小长度可以为零。
以下附加约束将适用于定义为字符串类型的主键属性:
- 对于简单的主键,第一个属性值(分区键)的最大长度为 2048 字节。
- 对于复合主键,第二个属性值(排序键)的最大长度为 1024 字节。
Binary
二进制类型属性可以存储任意二进制数据,如压缩文本、加密数据或图像。DynamoDB 会在比较二进制值时将二进制数据的每个字节视为无符号。
如果二进制属性未用作索引或表的键,且受到最大 DynamoDB 项目大小限制 400 KB 的约束,则该属性的长度可以为零。
如果您将主键属性定义为二进制类型属性,以下附加限制将适用:
- 对于简单的主键,第一个属性值(分区键)的最大长度为 2048 字节。
- 对于复合主键,第二个属性值(排序键)的最大长度为 1024 字节。
在将二进制值发送到 DynamoDB 之前,您的应用程序必须采用 Base64 编码格式对其进行编码。收到这些值后,DynamoDB 会将数据解码为无符号字节数组,将其用作二进制属性的长度。
布尔值
布尔类型属性可以存储 true 或 false。
Null
空代表属性具有未知或未定义状态。
文档类型
文档类型包括列表和映射。这些数据类型可以互相嵌套,用来表示深度最多为 32 层的复杂数据结构。
只要包含值的项目大小在 DynamoDB 项目大小限制 (400 KB) 内,列表或映射中值的数量就没有限制。
如果属性未用于表或索引键,属性值可以是空字符串或空二进制值。属性值不能为空集(字符串集、数字集或二进制集),但允许使用空的列表和映射。列表和映射中允许使用空的字符串和二进制值。
列表
列表类型属性可存储值的有序集合。列表用方括号括起:[ … ]
列表类似于 JSON 数组。列表元素中可以存储的数据类型没有限制,列表元素中的元素也不一定为相同类型。
以下示例显示了包含两个字符串和一个数字的列表。
FavoriteThings: [“Cookies”, “Coffee”, 3.14159]
映射
映射类型属性可以存储名称/值对的无序集合。映射用大括号括起:{ … }
映射类似于 JSON 对象。映射元素中可以存储的数据类型没有限制,映射中的元素也不一定为相同类型。
映射非常适合用来将 JSON 文档存储在 DynamoDB 中。以下示例显示了一个映射,该映射包含一个字符串、一个数字和一个含有另一个映射的嵌套列表。
{
Day: "Monday",
UnreadEmails: 42,
ItemsOnMyDesk: [
"Coffee Cup",
"Telephone",
{
Pens: { Quantity : 3},
Pencils: { Quantity : 2},
Erasers: { Quantity : 1}
}
]
}
注意
DynamoDB 让您可以使用映射中的单个元素,即使这些元素深层嵌套也是如此
集
DynamoDB 支持表示数字、字符串或二进制值集的类型。集中的所有元素必须为相同类型。例如,数字集类型的属性只能包含数字,字符串集只能包含字符串,依此类推。
只要包含值的项目大小在 DynamoDB 项目大小限制 (400 KB) 内,集中的值的数量就没有限制。
集中的每个值必须是唯一的。集中的值的顺序不会保留。因此,您的应用程序不能依赖集中的元素的任何特定顺序。DynamoDB 不支持空集,但集合中允许使用空字符串和二进制值。
以下示例显示了一个字符串集、一个数字集和一个二进制集:
["Black", "Green", "Red"]
[42.2, -19, 7.5, 3.14]
["U3Vubnk=", "UmFpbnk=", "U25vd3k="]
读取一致性
Amazon DynamoDB 在全世界多个 AWS 区域可用。每个区域均与其他 AWS 区域独立和隔离。例如,如果一个 People 表在 us-east-2 区域,一个 People 表在 us-west-2 区域,则视为两个完全不同的表。
最终一致性读取
当您从 DynamoDB 表中读取数据时,响应反映的可能不是刚刚完成的写入操作的结果。响应可能包含某些陈旧数据。如果您在短时间后重复读取请求,响应将返回最新的数据。
强一致性读取
当您请求强一致性读取时,DynamoDB 会返回具有最新数据的响应,从而反映来自所有已成功的之前写入操作的更新。但是,这种一致性有一些缺点:
- 如果网络延迟或中断,可能会无法执行强一致性读取。在这种情况下,DynamoDB 可能会返回服务器错误 (HTTP 500)。
- 强一致性读取可能比最终一致性读取具有更高的延迟。
- 全局二级索引不支持强一致性读取。
- 强一致性读取可能比最终一致性读取使用更高的吞吐量。
注意
除非您指定其他读取方式,否则 DynamoDB 将使用最终一致性读取。读取操作 (例如 GetItem,Query 和 Scan)提供了一个 ConsistentRead 参数。如果您将此参数设置为 true,DynamoDB 将在操作过程中使用强一致性读取。
分区和数据分配
Amazon DynamoDB 将数据存储在分区。分区是为表格分配的存储,由固态硬盘 (SSD) 提供支持,并可在 AWS 区域内的多个可用区中自动进行复制。分区管理由 DynamoDB 全权负责,您从不需要亲自管理分区。
在您创建表时,表的初始状态为 CREATING。在此期间,DynamoDB 会向表分配足够的分区,以便满足预置吞吐量需求。表的状态变为 ACTIVE 后,您可开始读取和写入表数据。
数据分配:分区键
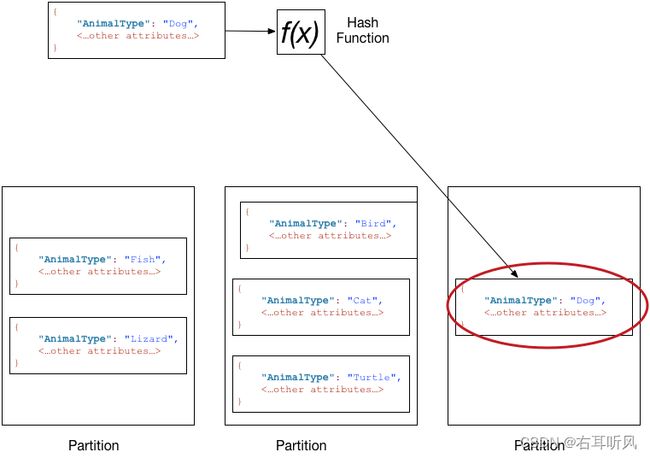
如果表具有简单主键(只有分区键),DynamoDB 将根据其分区键值存储和检索各个项目。
DynamoDB 使用分区键的值作为内部散列函数的输入值,从而将项目写入表中。散列函数的输出值决定了项目将要存储在哪个分区。
要从表读取项目,必须指定项目的分区键值。DynamoDB 使用此值作为其哈希函数的输入值,得到可从中找到该项目的分区。
下图显示了名为 Pets 的表,该表跨多个分区。表的主键是 AnimalType(仅显示此关键属性)。DynamoDB 使用其哈希函数决定新项目的存储位置,在这种情况下,会根据字符串 Dog 的哈希值。请注意,项目并非按排序顺序存储的。每个项目的位置由其分区键的哈希值决定。
数据分配:分区键和排序键
如果表具有复合主键(分区键和排序键),DynamoDB 将采用与 数据分配:分区键 中所述的方式相同的方式来计算分区键的哈希值。但是,它按排序键值有序地将具有相同分区键值的项目存储在互相紧邻的物理位置。
为将某个项目写入表中,DynamoDB 会计算分区键的散列值以确定该项目的存储分区。在该分区中,可能有几个具有相同分区键值的项目。因此,DynamoDB 会按排序键的升序将该项目存储在具有相同分区键的其他项目中。
要从表中读取项目,必须指定分区键值和排序键值。DynamoDB 计算分区键的哈希值,得出可从中找到该项目的分区。
如果您想要的项目具有相同的分区键值,则可以通过单一操作 (Query) 读取表中的多个项目。DynamoDB 返回具有该分区键值的所有项目。或者,您也可以对排序键应用某个条件,以便它仅返回特定值范围内的项目。
假设 Pets 表具有由 AnimalType(分区键)和 Name(排序键)构成的复合主键。下图显示了 DynamoDB 写入项目的过程,分区键值为 Dog、排序键值为 Fido。
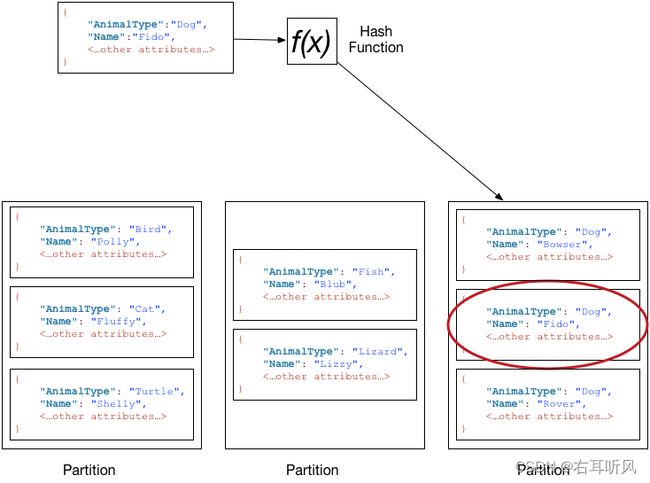
为读取 Pets 表中的同一项目,DynamoDB 会计算 Dog 的哈希值,从而生成这些项目的存储分区。然后,DynamoDB 扫描排序键属性值,直到找到 Fido。
要读取 AnimalType 为 Dog 的所有项目,您可以执行 Query 操作,无需指定排序键条件。默认情况下,这些项目会按存储顺序 (即按排序键的升序) 返回。或者,您也可以请求以降序返回。
若要仅查询某些 Dog 项目,您可以对排序键应用某个条件(例如,仅使用 Name 以 A 到 K 范围的字母开始的 Dog 项目。
DynamoDB数据库的特点
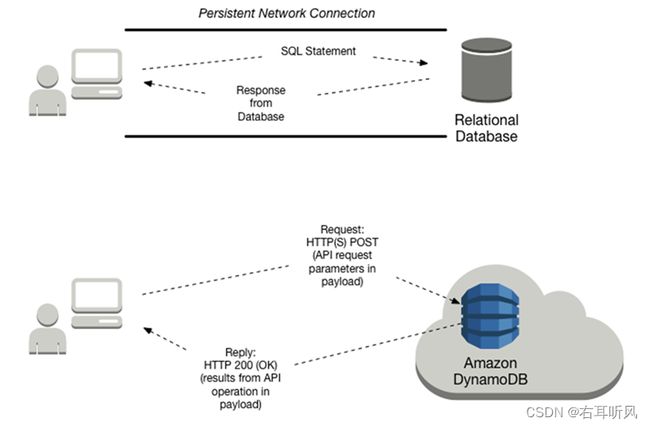
要让您的应用程序能够访问数据库,其必须经过身份验证,以确保该应用程序能够使用数据库。此外,您的应用程序还必须获得授权,以使该应用程序只能执行它有权执行的操作。
DynamoDB 是一项 Web 服务,与其进行的交互是无状态的。应用程序不需要维护持久性网络连接。相反,与 DynamoDB 的交互是通过 HTTP(S) 请求和响应进行的。
下图说明客户端与关系数据库和 Amazon DynamoDB 之间的交互。

DynamoDB操作
表是关系数据库和 Amazon DynamoDB 中的基本数据结构。关系数据库管理系统 (RDBMS) 要求您在创建表时定义表的架构。相比之下,DynamoDB 表没有架构—与主键不同,您在创建表时无需定义任何属性或数据类型。
SQL
使用 CREATE TABLE 语句创建表,如以下示例所示。
CREATE TABLE Music (
Artist VARCHAR(20) NOT NULL,
SongTitle VARCHAR(30) NOT NULL,
AlbumTitle VARCHAR(25),
Year INT,
Price FLOAT,
Genre VARCHAR(10),
Tags TEXT,
PRIMARY KEY(Artist, SongTitle)
);
此表的主键包含 Artist 和 SongTitle。
您必须定义表的所有列和数据类型以及表的主键。(如有必要,您稍后可以使用 ALTER TABLE 语句更改这些定义。)
许多 SQL 实现可让您将表的存储规范定义为 CREATE TABLE 语句的一部分。除非另外指明,否则使用默认存储设置创建表。在生产环境中,数据库管理员可以帮助确定最佳存储参数。
DynamoDB
使用 CreateTable 操作可创建预置模式表,并指定参数,如下所示:
{
TableName : "Music",
KeySchema: [
{
AttributeName: "Artist",
KeyType: "HASH", //Partition key
},
{
AttributeName: "SongTitle",
KeyType: "RANGE" //Sort key
}
],
AttributeDefinitions: [
{
AttributeName: "Artist",
AttributeType: "S"
},
{
AttributeName: "SongTitle",
AttributeType: "S"
}
],
ProvisionedThroughput: { // Only specified if using provisioned mode
ReadCapacityUnits: 1,
WriteCapacityUnits: 1
}
}
此表的主键包括 Artist(分区键)和 SongTitle(排序键)。
您必须向 CreateTable 提供以下参数:
- TableName – 表名称。
- KeySchema – 用于主键的属性。有关更多信息,请参阅表、项目和属性和主键。
- AttributeDefinitions – 键架构属性的数据类型。
- ProvisionedThroughput (for provisioned tables) –
每秒需对此表执行的读取和写入次数。DynamoDB 将保留足量的存储和系统资源,以便始终满足您的吞吐量需求。如有必要,您稍后可使用
UpdateTable 操作后更改这些设置。由于存储分配完全由 DynamoDB 管理,因此您无需指定表的存储要求。
获取有关表的信息
您可以根据您的规范验证是否已创建表。关系数据库中显示了所有表的架构。Amazon DynamoDB 表没有架构,因此仅显示主键属性。
SQL
大多数关系数据库管理系统 (RDBMS) 允许您描述表的结构—列、数据类型、主键定义等。在 SQL 中,没有执行此任务的标准方法。不过,许多数据库系统提供了 DESCRIBE 命令。以下是 MySQL 的一个示例。
DESCRIBE Music;
这将返回表的结构以及所有列名称、数据类型和大小。
+------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+-------+
| Artist | varchar(20) | NO | PRI | NULL | |
| SongTitle | varchar(30) | NO | PRI | NULL | |
| AlbumTitle | varchar(25) | YES | | NULL | |
| Year | int(11) | YES | | NULL | |
| Price | float | YES | | NULL | |
| Genre | varchar(10) | YES | | NULL | |
| Tags | text | YES | | NULL | |
+------------+-------------+------+-----+---------+-------+
此表的主键包含 Artist 和 SongTitle。
DynamoDB
DynamoDB 具有 DescribeTable 操作,与之类似。唯一的参数是表名称。
{
TableName : "Music"
}
来自 DescribeTable 的回复如下所示。
{
"Table": {
"AttributeDefinitions": [
{
"AttributeName": "Artist",
"AttributeType": "S"
},
{
"AttributeName": "SongTitle",
"AttributeType": "S"
}
],
"TableName": "Music",
"KeySchema": [
{
"AttributeName": "Artist",
"KeyType": "HASH" //Partition key
},
{
"AttributeName": "SongTitle",
"KeyType": "RANGE" //Sort key
}
],
...
DescribeTable 还返回有关表中的索引、预置的吞吐量设置、大约项目数和其他元数据的信息。
将数据写入表
关系数据库表包含数据行。行由列组成。Amazon DynamoDB 表包含项目。项目由属性 组成。
本节介绍如何将一行(或一个项目)写入表。
SQL
关系数据库中的表是一个由行和列组成的二维数据结构。一些数据库管理系统还支持半结构化数据(通常包括原生 JSON 或 XML 数据类型)。但实施详情因供应商而异。
在 SQL 中,可使用 INSERT 语句向表添加行。
INSERT INTO Music
(Artist, SongTitle, AlbumTitle,
Year, Price, Genre,
Tags)
VALUES(
'No One You Know', 'Call Me Today', 'Somewhat Famous',
2015, 2.14, 'Country',
'{"Composers": ["Smith", "Jones", "Davis"],"LengthInSeconds": 214}'
);
此表的主键包含 Artist 和 SongTitle。您必须为这些列指定值。
注意
该示例使用 Tags 列存储有关 Music 表中歌曲的半结构化数据。Tags 列定义为类型 TEXT,可在 MySQL 中存储最多 65535 个字符。
DynamoDB
在 Amazon DynamoDB 中,您可以使用 DynamoDB API 或 PartiQL(一种与 SQL 兼容的查询语言)将项目添加到表中。
使用 DynamoDB API,您可以使用 PutItem 操作向表添加项目。
{
TableName: "Music",
Item: {
"Artist":"No One You Know",
"SongTitle":"Call Me Today",
"AlbumTitle":"Somewhat Famous",
"Year": 2015,
"Price": 2.14,
"Genre": "Country",
"Tags": {
"Composers": [
"Smith",
"Jones",
"Davis"
],
"LengthInSeconds": 214
}
}
}
此表的主键包含 Artist 和 SongTitle。您必须为这些属性指定值。
以下是要了解的有关此 PutItem 示例的几个关键事项:
- DynamoDB 使用 JSON 提供对文档的原生支持。这使得 DynamoDB 非常适合存储半结构化数据,例如标记。您也可以从 JSON文档中检索和操作数据。
- 除了主键(Artist 和 SongTitle)外,Music 表没有任何预定义属性。
- 大多数 SQL 数据库是面向事务的。当您发出 INSERT 语句时,数据修改不是永久性的,直至您发出 COMMIT 语句。利用Amazon DynamoDB,当 DynamoDB 回复 HTTP 200 状态代码 (OK) 时,PutItem 操作的效果是永久性的。
使用 PartiQL,您可以通过使用 PartiQL Insert 语句来使用 ExecuteStatement 操作向表添加项目。
INSERT into Music value {
'Artist': 'No One You Know',
'SongTitle': 'Call Me Today',
'AlbumTitle': 'Somewhat Famous',
'Year' : '2015',
'Genre' : 'Acme'
}
此表的主键包含 Artist 和 SongTitle。您必须为这些属性指定值。
从表中读取数据时的主要区别
利用 SQL,您可使用 SELECT 语句从表中检索一个或多个行。可使用 WHERE 子句来确定返回给您的数据。
Amazon DynamoDB 提供以下操作来读取数据:
- ExecuteStatement 将会检索表中的单个或多个项目。BatchExecuteStatement
可以通过单个操作检索不同表中的多个项目。所有这些操作均使用 PartiQL,一种 SQL 兼容的查询语言。 - GetItem – 从表中检索单个项目。这是读取单个项目的最高效方式,因为它将提供对项目物理位置的直接访问。(DynamoDB 还提供
BatchGetItem 操作,允许在单个操作中执行最多 100 次 GetItem 调用。) - Query – 检索具有特定分区键的所有项目。在这些项目中,您可以将条件应用于排序键并仅检索一部分数据。Query
针对存储数据的分区提供快速、高效的访问。(有关更多信息,请参阅 分区和数据分配。) - Scan – 检索指定表中的所有项目。(不应对大型表使用此操作,因为这可能会占用大量系统资源。)
注意:(DynamoDB 不支持表关联连接)
利用关系数据库,您可以使用 SELECT语句联接多个表中的数据并返回结果。联接是关系模型的基础。要确保联接高效运行,应持续优化数据库及其应用程序的性能。
DynamoDB 是一个不支持表连接的非关系 NoSQL 数据库。相反,应用程序一次从一个表中读取数据。
使用项目的主键读取项目
在 Amazon DynamoDB 中,您可以使用 DynamoDB API 或 PartiQL(一种与 SQL 兼容的查询语言)读取表中的项目。
使用 PartiQL,您可以通过使用 PartiQL ExecuteStatement 语句来使用 Select 操作读取表中的项目。
SELECT AlbumTitle, Year, Price
FROM Music
WHERE Artist='No One You Know' AND SongTitle = 'Call Me Today'
请注意,此表的主键包含 Artist 和 SongTitle。
注意:
选择 PartiSQL 语句也可用于查询或扫描 DynamoDB 表
使用 DynamoDB API,您可以使用 PutItem 操作向表添加项目。
DynamoDB 提供 GetItem 操作来按项目的主键检索项目。GetItem 非常高效,因为它提供对项目物理位置的直接访问。(有关更多信息,请参阅 分区和数据分配。)
默认情况下,GetItem 将返回整个项目及其所有属性。
{
TableName: "Music",
Key: {
"Artist": "No One You Know",
"SongTitle": "Call Me Today"
}
}
您可以添加 ProjectionExpression 参数以仅返回一些属性。
{
TableName: "Music",
Key: {
"Artist": "No One You Know",
"SongTitle": "Call Me Today"
},
"ProjectionExpression": "AlbumTitle, Year, Price"
}
请注意,此表的主键包含 Artist 和 SongTitle。
DynamoDB GetItem 操作非常高效:此操作使用主键值确定相关项目的确切存储位置,并直接从此位置检索该项目。在按主键值检索项目时,SQL SELECT 语句同样高效。
mysq SQL SELECT 语句支持多种类型的查询和表扫描。DynamoDB 的 Query 和 Scan 操作功能类似,在 查询表 和 扫描表 中介绍。
mysql SQL SELECT 语句可执行表联接,这允许您同时从多个表中检索数据。在标准化数据库表的情况下,联接是最高效的,并且各个表之间的关系很明确。不过,如果您在一个 SELECT 语句中联接的表过多,则会影响应用程序性能。可使用数据库复制、具体化的视图或查询重写来解决此类问题。
DynamoDB 是一个非关系数据库且不支持表联接。如果您将现有应用程序从关系数据库迁移到 DynamoDB,则需要非规范化数据模型以消除联接需要。
查询表
常见访问模式是根据您的查询条件从表中读取多个项目
在 Amazon DynamoDB 中,您可以使用 DynamoDB API 或 PartiQL(一种与 SQL 兼容的查询语言)查询表中的项目。
DynamoDB API
使用 Amazon DynamoDB,Query 操作可让您以类似方式检索数据。Query 操作提供对存储数据的物理位置的快速高效访问。有关更多信息,请参阅 分区和数据分配。
可以将 Query 用于任何具有复合主键 (分区键和排序键) 的表。您必须指定分区键的相等条件,并且可以选择性为排序键提供另一个条件。
KeyConditionExpression 参数指定要查询的键值。可使用可选 FilterExpression 在结果中的某些项目返回给您之前删除这些项目。
在 DynamoDB 中,您必须使用 ExpressionAttributeValues 作为表达式参数(如 KeyConditionExpression 和 FilterExpression)中的占位符。这类似于在关系数据库中使用绑定变量,其中,您在运行时将实际值代入 SELECT 语句。
请注意,此表的主键包含 Artist 和 SongTitle。
以下是其他几个 DynamoDB Query 示例。
// Return a single song, by primary key
{
TableName: "Music",
KeyConditionExpression: "Artist = :a and SongTitle = :t",
ExpressionAttributeValues: {
":a": "No One You Know",
":t": "Call Me Today"
}
}
// Return all of the songs by an artist
{
TableName: "Music",
KeyConditionExpression: "Artist = :a",
ExpressionAttributeValues: {
":a": "No One You Know"
}
}
// Return all of the songs by an artist, matching first part of title
{
TableName: "Music",
KeyConditionExpression: "Artist = :a and begins_with(SongTitle, :t)",
ExpressionAttributeValues: {
":a": "No One You Know",
":t": "Call"
}
}
PartiQL for DynamoDB
使用 PartiQL,您可以使用 ExecuteStatement 操作和分区键上的 Select 语句执行查询。
SELECT AlbumTitle, Year, Price
FROM Music
WHERE Artist='No One You Know'
通过此方式使用 SELECT 语句将返回与此特定 Artist 关联的所有歌曲。
扫描表(慎用)
在 SQL 中,不带 SELECT 子句的 WHERE 语句将返回表中的每个行。在 Amazon DynamoDB 中,Scan 操作可执行相同的工作。在这两种情况下,您都可以检索所有项目或部分项目。
无论您使用的是 SQL 还是 NoSQL 数据库,都应谨慎使用扫描操作,因为它们会占用大量系统资源。有时,扫描是适合的 (例如,扫描小型表) 或不可避免的 (例如,执行数据的批量导出操作)。但通常来说,您应设计应用程序以避免执行扫描。
在 Amazon DynamoDB 中,您可以使用 DynamoDB API 或 PartiQL(一种与 SQL 兼容的查询语言)对表执行扫描。
使用 PartiQL,您可以通过 Select 语句来使用 ExecuteStatement 操作执行扫描,以返回表的所有内容。
SELECT AlbumTitle, Year, Price
FROM Music
请注意,此语句将返回 Music 表中的所有项目。
借助 DynamoDB API,您可以使用 Scan 操作来通过访问表或者二级索引中的每个项目来返回一个或多个项目和项目属性。
// Return all of the data in the table
{
TableName: "Music"
}
// Return all of the values for Artist and Title
{
TableName: "Music",
ProjectionExpression: "Artist, Title"
}
Scan 操作还提供一个 FilterExpression 参数,您可以使用它丢弃不希望在结果中出现的项目。在执行扫描后且结果返回给您之前,应用 FilterExpression。(不建议对大表使用。即使仅返回几个匹配项目,您仍需为整个 Scan 付费。)
修改表中的数据
SQL 语言提供 UPDATE 语句来修改数据。Amazon DynamoDB 使用 UpdateItem 操作来完成类似的任务。
在 SQL 中,可使用 UPDATE 语句修改一个或多个行。SET 子句为一个或多个列指定新值,WHERE 子句确定修改的行。以下是示例。
UPDATE Music
SET RecordLabel = 'Global Records'
WHERE Artist = 'No One You Know' AND SongTitle = 'Call Me Today';
如果任何行均不匹配 WHERE 子句,则 UPDATE 语句不起作用。
在 DynamoDB 中,您可以使用经典 API 或 PartiQL(一种与 SQL 兼容的查询语言)修改单个项目。(如果要修改多个项目,则必须使用多个 操作。)
借助 DynamoDB API,您可以使用 UpdateItem 操作修改单个项目。
{
TableName: "Music",
Key: {
"Artist":"No One You Know",
"SongTitle":"Call Me Today"
},
UpdateExpression: "SET RecordLabel = :label",
ExpressionAttributeValues: {
":label": "Global Records"
}
}
您必须指定要修改的项目的 Key 属性和一个用于指定属性值的 UpdateExpression。UpdateItem 的行为与“upsert”操作的行为类似:如果项目位于表中,则更新项目,否则添加(插入)新项目。
UpdateItem 支持条件写入,在此情况下,操作仅在特定 ConditionExpression 的计算结果为 true 时成功完成。例如,除非歌曲的价格大于或等于 2.00,否则以下 UpdateItem 操作不会执行更新。
{
TableName: "Music",
Key: {
"Artist":"No One You Know",
"SongTitle":"Call Me Today"
},
UpdateExpression: "SET RecordLabel = :label",
ConditionExpression: "Price >= :p",
ExpressionAttributeValues: {
":label": "Global Records",
":p": 2.00
}
}
从表中删除数据
在 SQL 中,DELETE 语句从表检索一个或多个行。Amazon DynamoDB 使用 DeleteItem 操作一次删除一个项目。
在 SQL 中,可使用 DELETE 语句删除一个或多个行。WHERE 子句确定要修改的行。以下是示例。
DELETE FROM Music
WHERE Artist = 'The Acme Band' AND SongTitle = 'Look Out, World';
您可以修改 WHERE 子句以删除多个行。例如,您可以删除某个特定艺术家的所有歌曲,如以下示例所示。
DELETE FROM Music WHERE Artist = 'The Acme Band'
在 DynamoDB 中,您可以使用经典 API 或 PartiQL(一种与 SQL 兼容的查询语言)删除单个项目。(如果要修改多个项目,则必须使用多个 操作。)
借助 DynamoDB API,您可以使用 DeleteItem 操作删除表中的数据(一次删除一个项目)。您必须指定项目的主键值。
{
TableName: "Music",
Key: {
Artist: "The Acme Band",
SongTitle: "Look Out, World"
}
}
注意
除了 DeleteItem 之外,Amazon DynamoDB 还支持同时删除多个项目的 BatchWriteItem 操作。
DeleteItem 支持条件写入,在此情况下,操作仅在特定 ConditionExpression 的计算结果为 true 时成功完成。例如,以下 DeleteItem 操作仅在项目具有 RecordLabel 属性时删除项目。
{
TableName: "Music",
Key: {
Artist: "The Acme Band",
SongTitle: "Look Out, World"
},
ConditionExpression: "attribute_exists(RecordLabel)"
}
使用 PartiQL,您可以使用 Delete 语句通过 ExecuteStatement 操作删除表中的数据 (一次删除一个项目)。您必须指定项目的主键值。
此表的主键包含 Artist 和 SongTitle。您必须为这些属性指定值。
DELETE FROM Music
WHERE Artist = 'Acme Band' AND SongTitle = 'PartiQL Rocks'
您还可以指定操作的其他选项。以下 DELETE 操作只有在项目超过 11 个奖项时才会删除该项目。
DELETE FROM Music
WHERE Artist = 'Acme Band' AND SongTitle = 'PartiQL Rocks' AND Awards > 11
删除表(慎用)
在 SQL 中,可使用 DROP TABLE 语句删除表。在 Amazon DynamoDB 中,使用 DeleteTable 操作。
当您不再需要一个表并希望将它永久性丢弃时,可使用 SQL 中的 DROP TABLE 语句。
DROP TABLE Music;
表一经删除便无法恢复。(一些关系数据库允许您撤消 DROP TABLE 操作,但这是一项供应商特定的功能,并未广泛实施。)
DynamoDB 具有类似操作:DeleteTable。在以下示例中,表将被永久删除。
{
TableName: "Music"
}