docker-compose 升级;yaml文件编写;gpu使用
1、docker-compose 升级(现在已经2.*版本,升级使支持gpu)
参考:https://blog.csdn.net/weixin_51311218/article/details/131376823
https://github.com/docker/compose/issues/8142
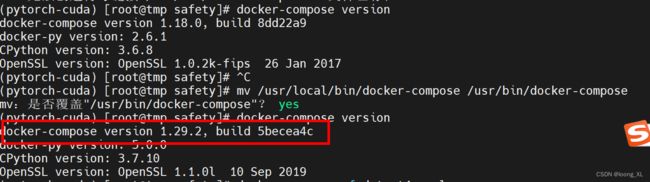
1)下载:原来1.18;升级到1.29.2版本
添加链接描述

2)下载后文件后更名为docker-compose;然后放到/usr/bin/文件下覆盖,有的是会放到/usr/local/bin/,本机是放在/usr/bin/下
3)然后sudo chmod +x /usr/bin/docker-compose,然后查看 docker-compose version
2、yaml文件编写(字典转yaml)
安装:pip install pyyaml
字典:
data = {
"version": "3.8",
"services": {
"my_gpu_service": {
"image": "cv-worker:v1",
"command": "/bin/bash -c 'yolo task=detect mode=train model=/data/yolov8m.pt data=/data/data2.yaml epochs=20 device=1 > /data/yolo1.log 2>&1'",
"volumes": [
"/mnt/data/loong/detection/safety/:/data",
],
"working_dir": "/data",
"shm_size": "15g",
"ports": [
"6006:6006",
],
}
}
}
字典转yaml:
import yaml
# 保存YAML文件
with open("detect1.yaml", "w") as f:
yaml.dump(data, f, default_flow_style=False, sort_keys=False)
3、gpu使用
参考:https://docs.docker.com/compose/gpu-support/
注意:yaml内部gpu对应方式
这里注意:yaml里gpu索引不一样,device_ids: [‘1’,‘3’,‘2’]是外部服务器gpu的索引号,yaml内部gpu索引号是按device_ids列表的索引:及内部0 device_ids第一个实际外部的1,内部1 device_ids第一个实际外部的3,内部2 device_ids第一个实际外部的2;所以下列device=0,1 对应的是device_ids的索引即外部1,3号gpu
外部gpu索引查询,pytorch与nvidia-smi索引不一样
pytorch查询gpu索引情况:
import torch
num_gpus = torch.cuda.device_count()
for i in range(num_gpus):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")

yaml代码例子
##运行
docker-compose -f aa.yaml up
aa.yaml
version: '3.8'
services:
my_gpu_service:
image: cv-worker:v1
command: /bin/bash -c 'yolo task=classify mode=train model=/data/yolov8n-cls.pt data=/work/cifar10_copy1
epochs=2 device=0,1 > /data/yolo1.log 2>&1'
volumes:
- //mnt/data/loong/classify/:/data
- /mnt/data/yolo/datasets/:/work
working_dir: /data
shm_size: 15g
ports:
- 6006:6006
# - 9000:9000
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['1','2','3']
capabilities: [gpu]