No.8爬虫学习——xpath基础知识
xpath解析:是最常用且最便捷高效的一种解析方式,通用性
1、xpath解析原理
(1)实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中
(2)通过调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
2、环境的安装:
pip install lxml
3、如何实例化一个etree对象:from lxml import etree
(1)将本地的html文档中的源码数据加载到etree对象中:
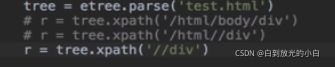
etree.parse(filePath)
(2)可以将从互联网上获取的源码数据加载到该对象中
etree.HTML('path_text')
xpath('xpath表达式')
(3)xpath表达式
/表示的是从根节点开始定位。表示的是一个层级
//表示的是多个层级。可以表示从任意位置开始定位
属性定位://div[@class="song"] tag[@attrName="attrValue"]
索引定位://div[@class="song"]/p[3] 索引是从1开始的
取文本:
(1)/text() 获取的是标签中直系的文本内容
(2)//text() 标签中非直系的文本内容(所有的文本内容)
取属性:/@attrName ==>img/src