Java导入导出word文档中的表格
使用poi导出列表数据到word文档中的表格中,表格支持自定义单元格合并,并可选择导出的列。
导入带表格的word文档,支持合并单元格的表格内容读取。

maven依赖
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poiartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxmlartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-scratchpadartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>fr.opensagres.xdocreportgroupId>
<artifactId>xdocreportartifactId>
<version>1.0.6version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>poi-ooxml-schemasartifactId>
<version>4.1.2version>
dependency>
<dependency>
<groupId>org.apache.poigroupId>
<artifactId>ooxml-schemasartifactId>
<version>1.3version>
dependency>
<dependency>
<groupId>com.deepoovegroupId>
<artifactId>poi-tlartifactId>
<version>1.10.0version>
dependency>
使用word模板文件
创建word模板文件时注意使用office word创建模板文件
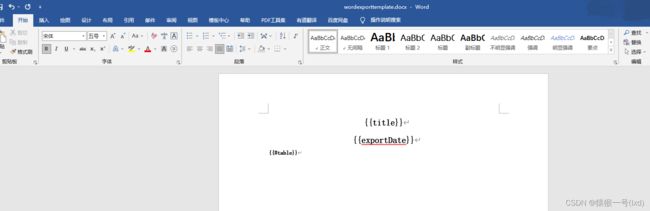
将模板文件放到resource下

获取resource文件夹下文件位置
/**
* 功能描述:
* 获取resource目录下的文件位置
* @Date: 2023-02-03 09:36:35
* @Param templateFileName:
* @return: java.lang.String
* @since: 1.0.0
*/
public String getTemplateAbsolutePath(String templateFileName) throws Exception {
//注意getResource("")里面是空字符串
String path = this.getClass().getClassLoader().getResource(templateFileName).getPath();
System.out.println(path);
//如果路径中带有中文会被URLEncoder,因此这里需要解码
String filePath = URLDecoder.decode(path, "UTF-8");
System.out.println(filePath);
return filePath;
}
导出方法
自定义导出注解
定义注解后可根据中文注释自动给对应字段赋值
import java.lang.annotation.Documented;
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
import static java.lang.annotation.ElementType.FIELD;
import static java.lang.annotation.RetentionPolicy.RUNTIME;
/**
* 实体model属性字段的位置顺序 ,从0开始
*/
@Documented
@Retention(RUNTIME)
@Target(FIELD)
public @interface BeanFieldIndex {
// 在表格中的列数
int index();
// 列名
String title();
}
导出的列表对象
import lombok.Data;
/**
* 功能描述:
*
* @Author: liuxd
* @description: 专家
* @Date: 2023/2/2
*/
@Data
public class ExpertVo {
/**
* 序号
*/
@BeanFieldIndex(index = 0,title = "序号")
private Long id;
/**
* 姓名
*/
@BeanFieldIndex(index = 1,title = "姓名")
private String name;
/**
* 性别
*/
@BeanFieldIndex(index = 2,title = "性别")
private String sex;
/**
* 年龄
*/
@BeanFieldIndex(index = 3,title = "年龄")
private Integer age;
/**
* 科室
*/
@BeanFieldIndex(index = 4,title = "科室")
private String dept;
/**
* 所属部队
*/
@BeanFieldIndex(index = 5,title = "所属部队")
private String unit;
/**
* 地址
*/
@BeanFieldIndex(index = 6,title = "地址")
private String address;
import com.deepoove.poi.data.TableRenderData;
import lombok.Data;
@Data
public class TableData {
/**
* 标题
*/
private String title;
/**
* 表格
*/
private TableRenderData table;
private String[][] tableList;
/**
* 导出日期
*/
private String exportDate;
}
/**
* 功能描述:
* 导出word,带表格
* @Date: 2023-02-02 11:56:49
* @Param tableData:
* @Param list: 要导出的数据
* @Param properties: 要导出的列
* @Param clazz: 导出的对象
* @Param fileName: 导出的文件名
* @Param title: 标题栏内容
* @Param sheetName: 导出的sheet名
* @Param rule: 合并的单元格的规则
* @Param headers: 表头
* @Param response:
* @return: void
* @since: 1.0.0
*/
public static void exportWord(List<?> list, String[] properties, String fileName, String title, String
sheetName, MergeCellRule rule, String templateFile, HttpServletResponse response) throws Exception {
TableData tableData = new TableData();
tableData.setTitle(title);
Object obj = list.get(0);
Class<?> clazz = obj.getClass();
Field[] fields = clazz.getDeclaredFields();
// 表格标题栏
String[] titleRow = new String[properties.length];
// 标题栏的属性值 确保导出的顺序
String[] titlePropertiesRow = new String[properties.length];
List<BeanVo> beanVos = new ArrayList<>();
for (int i = 0; i < properties.length; i++) {
String property = properties[i];
for (Field field : fields) {
// 找到当前匹配的字段
if (field.getName().equals(property)) {
BeanFieldIndex radiusIndex = field.getAnnotation(BeanFieldIndex.class);
if (radiusIndex != null) {
int index = radiusIndex.index();
String value = radiusIndex.title();
BeanVo beanVo = new BeanVo(index, value, property);
beanVos.add(beanVo);
}
break;
}
}
}
// 根据order排序
beanVos = beanVos.stream().sorted(Comparator.comparing(BeanVo::getOrder)).collect(Collectors.toList());
for (int i = 0; i < properties.length; i++) {
titleRow[i] = beanVos.get(i).getTitle();
titlePropertiesRow[i] = beanVos.get(i).getProperty();
}
RowRenderData row10 = Rows.of("序号", "基本信息", "", "", "基本信息1", "", "").center().create();
RowRenderData row0 = Rows.of(titleRow).center().create();
// 表格数据 加上1行表头
RowRenderData[] rowRenderData = new RowRenderData[list.size() + 2];
rowRenderData[0] = row10;
rowRenderData[1] = row0;
// 单元格合并规则
// MergeCellRule rule = mergeCell();
// 表格内容赋值
String[][] strings = new String[list.size()][properties.length];
for (int i = 0; i < list.size(); i++) {
Object o = list.get(i);
strings[i] = new String[titlePropertiesRow.length];
// 获取需要导出的字段值
for (int j = 0; j < titlePropertiesRow.length; j++) {
// 拼接该字段对应的get方法的方法名
String getMethodName = "get" + titlePropertiesRow[j].substring(0, 1).toUpperCase() + titlePropertiesRow[j].substring(1);
Method getMethod = clazz.getMethod(getMethodName, new Class[]{});
try {
// 利用Java反射机制调用get方法获取字段对应的值
Object target = getMethod.invoke(o, new Object[]{});
strings[i][j] = String.valueOf(target);
} catch (IllegalAccessException | InvocationTargetException | IllegalArgumentException e) {
System.out.println(e);
}
}
rowRenderData[i + 2] = Rows.of(strings[i]).center().create();
}
tableData.setTableList(strings);
TableRenderData table = Tables.of(rowRenderData).mergeRule(rule).create();
// 数据封装
tableData.setTable(table);
// 传入模板模板地址+信息数据
XWPFTemplate template = XWPFTemplate.compile(templateFile).render(tableData);
// 指定下载的文件名--设置响应头
response.setHeader("Content-Disposition", "attachment;filename=" + URLEncoder.encode(fileName, "UTF-8"));
response.setContentType("application/vnd.ms-word;charset=UTF-8");
response.setHeader("Pragma", "no-cache");
response.setHeader("Cache-Control", "no-cache");
response.setDateHeader("Expires", 0);
OutputStream out = response.getOutputStream();
BufferedOutputStream bos = new BufferedOutputStream(out);
try {
template.write(out);
} catch (IOException e) {
e.printStackTrace();
} finally {
bos.flush();
out.flush();
bos.close();
out.close();
template.close();
}
}
单元格合并规则
/***
* 功能描述:
* 导出word中的表格时合并相应单元格
* 要根据具体的需求去根据不同字段 分组 来确定单元格合并的行数与列数
* @Date: 2023-02-02 18:11:11
* @Param
* @return: com.deepoove.poi.data.MergeCellRule
* @since: 1.0.0
*/
public static MergeCellRule mergeCell() {
// 合并后单元格
/*MergeCellRule rule = MergeCellRule.builder().map(MergeCellRule.Grid.of(0, 0), MergeCellRule.Grid.of(1, 0)).
// 从第几行第几列合并到第几行第几列
map(MergeCellRule.Grid.of(0, 1), MergeCellRule.Grid.of(0, 3)).
map(MergeCellRule.Grid.of(0, 4), MergeCellRule.Grid.of(0, 6)).
// map(MergeCellRule.Grid.of(0, 4), MergeCellRule.Grid.of(1, 4)).
// map(MergeCellRule.Grid.of(rowRenderData.length - 1, 0), MergeCellRule.Grid.of(rowRenderData.length - 1, 3)).
build();*/
MergeCellRule.MergeCellRuleBuilder rule = MergeCellRule.builder();
rule.map(MergeCellRule.Grid.of(0, 1), MergeCellRule.Grid.of(0, 3));
rule.map(MergeCellRule.Grid.of(0, 4), MergeCellRule.Grid.of(0, 6));
return rule.build();
}
测试
/***
* 功能描述:
* 根据用户ID更新ws推送的参数
* @Date: 2022-12-01 09:21:25
* @return: void
* @since: 1.0.0
*/
@RequestMapping("/download")
public void download(HttpServletResponse response){
try {
List<ExpertVo> expertVoList = new ArrayList<>();
expertVoList.add(new ExpertVo(Long.valueOf("1"),"张三1","男",28,"","职务1","地址1"));
expertVoList.add(new ExpertVo(Long.valueOf("2"),"张三2","男",28,"","职务1","地址1"));
expertVoList.add(new ExpertVo(Long.valueOf("3"),"张三3","男",28,"","职务1","地址1"));
expertVoList.add(new ExpertVo(Long.valueOf("4"),"张三4","男",28,"","职务1","地址1"));
expertVoList.add(new ExpertVo(Long.valueOf("5"),"张三5","男",28,"","职务1","地址1"));
expertVoList.add(new ExpertVo(Long.valueOf("6"),"张三6","男",28,"","职务1","地址1"));
expertVoList.add(new ExpertVo(Long.valueOf("7"),"张三7","男",28,"","职务1","地址1"));
expertVoList.add(new ExpertVo(Long.valueOf("8"),"张三8","男",28,"","职务1","地址1"));
String templateFile = getTemplateAbsolutePath("wordtemplate/wordexporttemplate.docx");
// new String[]{"id","name","sex","dept","unit","address","age"} 为需要导出的列
WordExcelUtil.exportWord(expertVoList,new String[]{"id","name","sex","dept","unit","address","age"},"专家信息导出.docx","专家信息",null,WordExcelUtil.mergeCell(),templateFile,response);
} catch (IOException e) {
e.printStackTrace();
} catch (EncodeException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
导入方法
导入带合并单元格的思路为 当前单元格无值,就向上找,直到找到有值的单元格,将该单元格的值赋给当前单元格
.doc与.docx导入的方法不同
/**
* 功能描述:
* 导入带表格的word文档
* @Date: 2023-02-03 16:55:56
* @Param file:
* @Param firstRow: 从第几行开始读(具体数据行的上一行)
* @Param clazz: 表格对象的实体类
* @Param: LinkedHashMap map Word中除excel表格外的其他段落的内容 传参new 一个Map
* @return: java.util.List
* @since: 1.0.0
*/
public static <T> List<T> importWord(MultipartFile file, int firstRow, Class clazz, LinkedHashMap<String, Object> map,String fileName) throws Exception {
if(fileName.endsWith(".doc")){
return doDoc(file,firstRow,clazz,map);
}else if(fileName.endsWith(".docx")){
return doDocx(file,firstRow,clazz,map);
}else{
return null;
}
}
doc导入
/***
* 功能描述:
* 读取doc文档中表格数据示例 这里是03版 doc格式表格的读取方法
* @Author: LXD
* @Date: 2023-02-03 16:57:19
* @Param file:
* @Param firstRow: 从第几行开始读(具体数据行的上一行)
* @Param clazz: 表格对象的实体类
* @Param: LinkedHashMap map Word中除excel表格外的其他段落的内容 传参new 一个Map
* @return: java.util.List
* @since: 1.0.0
*/
public static <T> List<T> doDoc(MultipartFile file, int firstRow, Class clazz, LinkedHashMap<String, Object> map) throws Exception {
//用于存放预览信息
List<String> stringList = new ArrayList<String>();
List<T> list = new ArrayList<T>();
try {
//获取文件流
InputStream is = file.getInputStream();
//获取文件对象
HWPFDocument doc = new HWPFDocument(is);
//获取文件内容对象
Range r = doc.getRange();
//获取文件中所有的表格
TableIterator it = new TableIterator(r);
for (int i = 0; i < r.numParagraphs(); i++) {
//获取当前段落
Paragraph p = r.getParagraph(i);
//判断当前段落是否为表格
if (p.isInTable()) {
int rowNum = 0 + firstRow==1? 0 : firstRow-1;
// 先读取表头信息
List<String> firstRowStrings = new ArrayList<>();
while (it.hasNext()) {
Table tb = (Table) it.next();
// 循环所有行
while(rowNum<firstRow) {
//第一行
TableRow firstTr = tb.getRow(firstRow-1);
//迭代文档中的表格
for (int x = 0; x < firstTr.numCells(); x++) {
//取得单元格
TableCell td = firstTr.getCell(x);
//取得单元格的内容
Paragraph para = td.getParagraph(0);
String text = para.text();
if (StringUtils.isEmpty(text) || "\u0007".equals(text)) {
text = tb.getRow(0).getCell(x).getParagraph(0).text();
}
if(StringUtils.isNotBlank(text)){
// 去除不可见字符
text = text.replaceAll("\u0007","");
}
firstRowStrings.add(text);
}
rowNum++;
}
while(rowNum>=firstRow){
//迭代行,默认从firstRow开始 // 跳过表头信息行
for (int j = firstRow; j < tb.numRows(); j++) {
List<String> rowStrings = new ArrayList<>();
//当前行
TableRow tr = tb.getRow(j);
//用于存放一行数据,不需要可以不用
String rowText = "";
T t = (T) clazz.newInstance();
//迭代列,默认从0开始
for (int x = 0; x < tr.numCells(); x++) {
//取得单元格
TableCell td = tr.getCell(x);
//取得单元格的内容
Paragraph para = td.getParagraph(0);
String text = para.text();
int times = 1;
while (StringUtils.isEmpty(text) || "\u0007".equals(text)){
TableRow preTr = tb.getRow(j-times);
TableCell preCell = preTr.getCell(x);
//取得单元格的内容
text = preCell.getParagraph(0).text();
times = times + 1;
}
if(StringUtils.isNotBlank(text)){
// 去除不可见字符
text = text.replaceAll("\u0007","");
}
//自己用“ ”区分两列数据,根据自己需求 可以省略
if (StringUtils.isEmpty(rowText)) {
rowText = text;
rowStrings.add(text);
} else {
rowText = rowText + " " + text;
rowStrings.add(text);
}
}
stringList.add(rowText);
BeanRefUtils.setProperty(t, rowStrings,firstRowStrings);
list.add(t);
}
break;
}
}
}else{
System.out.println(p.text());
if(StringUtils.isNotBlank(p.text())){
map.put(String.valueOf(i+1),p.text());
}
}
}
return list;
} catch (IOException e) {
log.error("[文件操作 - 读取03版doc文件] - 文件读取失败,文件名称:{}", file.getOriginalFilename());
throw new Exception("文件读取失败", e);
}
}
docx导入
/***
* 功能描述:
* 读取doc文档中表格数据示例 这里是07版 docx格式表格的读取方法
* @Date: 2023-02-02 19:11:23
* @Param file:
* @Param firstRow: 从第几行开始读(具体数据行的上一行)
* @Param: LinkedHashMap map Word中除excel表格外的其他段落的内容 传参new 一个Map
* @since: 1.0.0
*/
public static <T> List<T> doDocx (MultipartFile file,int firstRow,Class clazz,LinkedHashMap<String, Object> map) throws Exception {
//用于存放预览信息
List<String> stringList = new ArrayList<String>();
List<T> list = new ArrayList<T>();
try {
//获取文件流
InputStream is = file.getInputStream();
//获取文件对象
XWPFDocument doc = new XWPFDocument(is);
//获取文件内容对象
XWPFParagraph[] paras = doc.getParagraphs().toArray(new XWPFParagraph[0]);
// 获取所有段落内容
Iterator<XWPFParagraph> itPara = doc.getParagraphsIterator();//获取word段落
// 段落序号
int paragraphNum = 1;
while (itPara.hasNext()) {
XWPFParagraph paragraph = itPara.next();//获取段落
// 非表格
if(!paragraph.getPartType().equals(BodyType.TABLECELL)){
System.out.println(paragraph.getText());
if(StringUtils.isNotBlank(paragraph.getText())){
map.put(String.valueOf(paragraphNum),paragraph.getText());
}
paragraphNum++;
//获取所有的表格对象
List tables = doc.getTables();
//因我文档中只有一个所以这里没有去遍历,直接获取指定表格对象
XWPFTable table = (XWPFTable) tables.get(0);
// 获取表头信息
List<String> firstRowStrings = new ArrayList<>();
//表头行信息
XWPFTableRow firstTr = table.getRow(1);
for (int x = 0; x < firstTr.getTableCells().size(); x++) {
//取得单元格
XWPFTableCell cell = firstTr.getCell(x);
//取得单元格的内容
String text = cell.getText();
// 如果表头该列为空,则读取该列上一行的数据
if(StringUtils.isEmpty(text)){
text = table.getRow(0).getCell(x).getText();
}
firstRowStrings.add(text);
}
//迭代行,默认从0开始 (第一行若为表头,则可以跳过)
for (int j = firstRow; j < table.getRows().size(); j++) {
List<String> rowStrings = new ArrayList<>();
//当前行
XWPFTableRow tr = table.getRow(j);
//用于存放一行数据,不需要可以不用
String rowText = "";
T t = (T) clazz.newInstance();
//迭代列,默认从0开始
for (int x = 0; x < tr.getTableCells().size(); x++) {
//取得单元格
XWPFTableCell cell = tr.getCell(x);
//取得单元格的内容
String text = cell.getText();
//自己用“ ”区分两列数据,根据自己需求 可以省略
int times = 1;
while (StringUtils.isEmpty(text)){
XWPFTableRow preTr = table.getRow(j-times);
XWPFTableCell preCell = preTr.getCell(x);
//取得单元格的内容
text = preCell.getText();
times = times + 1;
}
if (StringUtils.isEmpty(rowText)) {
rowText = text;
rowStrings.add(text);
} else {
rowStrings.add(text);
rowText = rowText + " ;" + text;
}
}
stringList.add(rowText);
BeanRefUtils.setProperty(t, rowStrings,firstRowStrings);
list.add(t);
}
return list;
} catch (IOException e) {
log.warn("[文件操作 - 读取07版docx文件] - 文件读取失败,文件名称:{}", file.getOriginalFilename());
throw new Exception("文件读取失败", e);
}
}
测试导入
public static void main(String[] args) throws Exception {
System.err.println("开始读取");
String filePath = "C:\\Users\\XXX\\Desktop\\2023专家信息.doc";
File file = new File(filePath);
try {
MultipartFile cMultiFile = new MockMultipartFile("file", file.getName(), null, new FileInputStream(file));
// 除表格外的段落内容
LinkedHashMap<String, Object> map = new LinkedHashMap<>();
importWord(cMultiFile,2,ExpertVo.class,map,file.getName()).stream().forEach(System.out::println);
System.out.println(map.toString());
System.err.println("结束读取");
} catch (IOException e) {
e.printStackTrace();
}
}