论文阅读——GroupViT
GroupViT: Semantic Segmentation Emerges from Text Supervision
一、思想
把Transformer层分为多个组阶段grouping stages,每个stage通过自注意力机制学习一组tokens,然后使用学习到的组tokens通过分组模块Grouping Block融合相似的图片tokens。通过这种组级联,可以把图片中小分割块组成大块。
二、模型
图片分成不重叠的N个块,每个块经过线性映射变成 image token,除了 image tokens ,每个grouping stage同时concat一组可学习的group tokens,image token和group tokens都输入Transformer层。
Grouping Block的作用是把小块组合成大块,每个阶段都有该模块。
不是把所有的image token前向传播到所有Transformer层。
每个阶段经过GroupingBlock后得到的tokens数量越来越少,因为分割的区域越来越大,分割的数量越来越少。最后一层后,所有分割tokens经过Transformer层,输出平均池化,得到图片表示z。
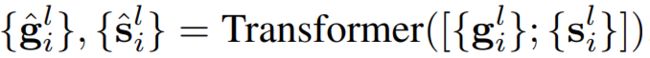
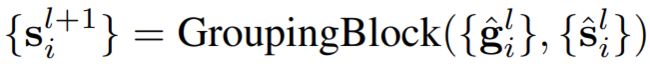
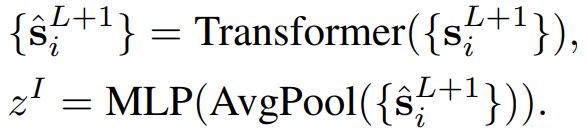
然后用了一个hard assignment技巧,使得可微分,将每个分割token分配给一个组。然后同一组的所有token融合得到一个新的分割token:
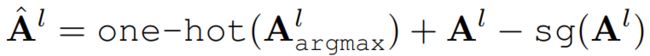
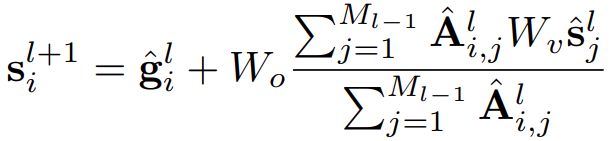
双编码器结构,GroupViT是图片编码器,Transformer是文本编码器,最终GroupViT输出的图片向量是所有输出的分割token的平均向量。
三、损失函数
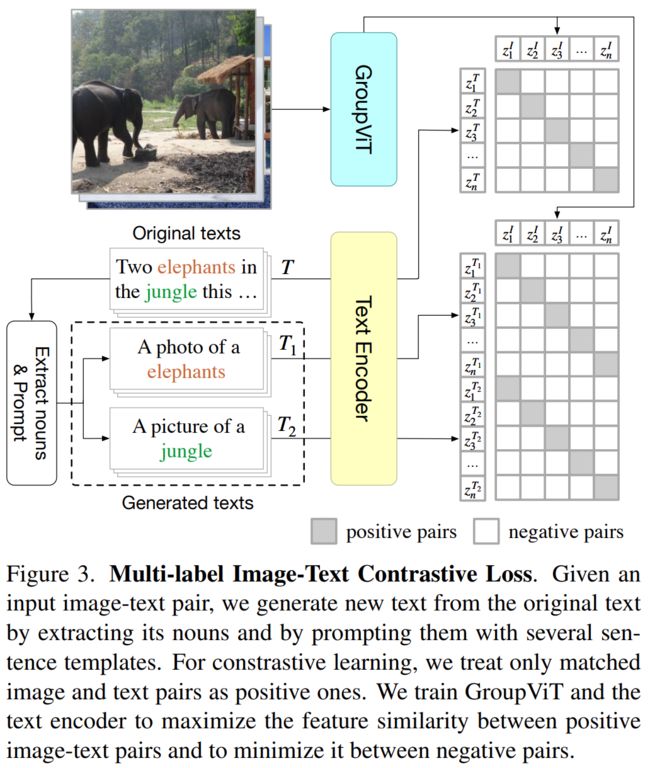
Image-Text Contrastive Loss:

Multi-Label Image-Text Contrastive Loss:
从GT文本中随机选出K个名词,然后用模版填充:“A photo of a {noun}”.
原始的文本图片对: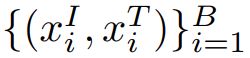
the new sets of image-“prompted text” pairs:
![]()

Zero-Shot Transfer to Semantic Segmentation
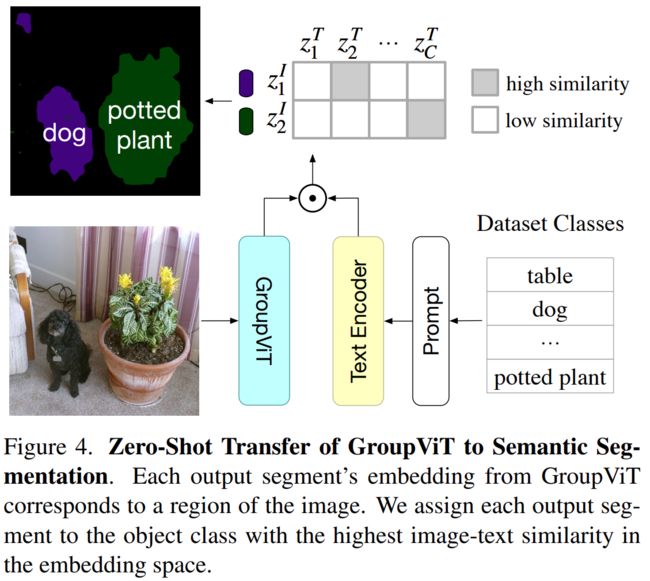
四、实验
部分细节:
ViT-S+12 Transformer layers+hidden dimension of 384
input images of size 224 × 224+patch size of 16 × 16
experiment with 1-stage and 2-stage architectures for GroupViT:
1-stage:
64 group tokens and insert the grouping block after the sixth Transformer layer;Before the grouping block, we project the 64 group tokens into 8 tokens using an MLP-Mixer layer [76] and output 8 segment tokens.
2-stage:
there are 64 and 8 group tokens in the first and second grouping stages, respectively. We insert grouping blocks after the sixth and ninth Transformer layers. We use a 2-layer MLP to project the visual and text embedding vectors into the same latent space.
Our batch size is 4096 with a learning rate initialized to 0.0016 and decayed via the cosine schedule. We use the Adam optimizer with a weight decay of 0.05. We train GroupVIT for 30 epochs with the 5 initial epochs containing linear warm-up. For the multi-label contrastive loss, we set K = 3.
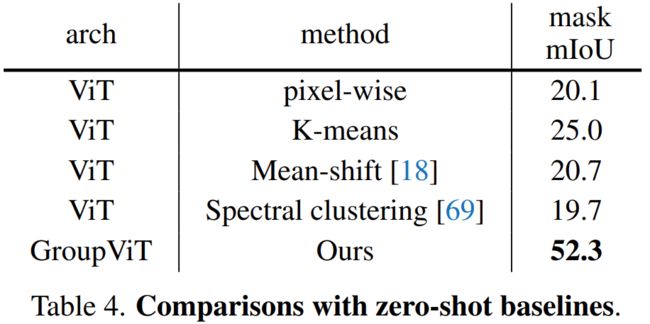
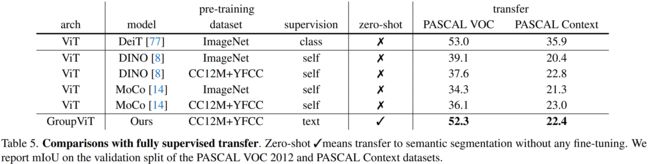
结果: