python结合Selenium
网站学习连接:操控元素的基本方法 | 白月黑羽
安装Selenium
cmd窗口,cd命令进入pip安装路径“D:\python\Scripts”后,输入“pip install -U selenium”,安装最新版本的selenium,如图:
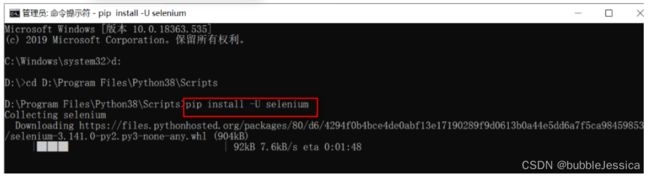
安装等待中,当出现“Successfully installed selenium...”表示Selenium已经安装成功。selenium-xx表示版本号。如图: 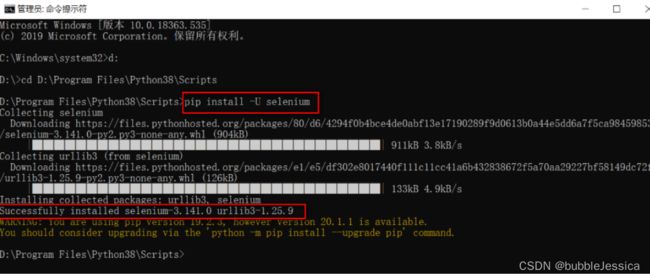
114版本
驱动下载在这个链接

120以后版本
驱动在这个链接,其中http状态码是200的才可以下载,驱动大版本一致就可以使用,不需一模一样

把驱动器chromedriver.exe存放到d:\tools目录下并设置环境变量
案例
from selenium import webdriver
from selenium.webdriver.chrome.webdriver import Service
# 创建 WebDriver 对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome(service=Service(r'd:\tools\chromedriver.exe'))
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.baidu.com')
# 程序运行完会自动关闭浏览器,就是很多人说的闪退
# 这里加入等待用户输入,防止闪退
input()
定位操作元素(根据ID)
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象
wd = webdriver.Chrome()
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.byhy.net/_files/stock1.html')
# 根据id选择元素,返回的就是该元素对应的WebElement对象
element = wd.find_element(By.ID, 'kw')
# 通过该 WebElement对象,就可以对页面元素进行操作了
# 比如输入字符串到 这个 输入框里
element.send_keys('通讯')
element = wd.find_element(By.ID, 'go')
element.click()
wd.quit()
根据 class属性、tag名 选择元素
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建 WebDriver 实例对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome()
# WebDriver 实例对象的get方法 可以让浏览器打开指定网址
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
# 根据 class name 选择元素,返回的是 一个列表
# 里面 都是class 属性值为 animal的元素对应的 WebElement对象
elements = wd.find_elements(By.CLASS_NAME, 'animal')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)
使用
find_elements选择的是符合条件的所有元素, 如果没有符合条件的元素,返回空列表使用
find_element选择的是符合条件的第一个元素, 如果没有符合条件的元素,抛出 NoSuchElementException 异常
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建 WebDriver 实例对象,指明使用chrome浏览器驱动
wd = webdriver.Chrome()
# WebDriver 实例对象的get方法 可以让浏览器打开指定网址
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
# 根据 tag name 选择元素,返回的是 一个列表
# 里面 都是 tag 名为 div 的元素对应的 WebElement对
elements = wd.find_elements(By.TAG_NAME, 'div')
# 取出列表中的每个 WebElement对象,打印出其text属性的值
# text属性就是该 WebElement对象对应的元素在网页中的文本内容
for element in elements:
print(element.text)
pass通过WebElement对象选择元素
WebDriver 对象 选择元素的范围是 整个 web页面, 而
WebElement 对象 选择元素的范围是 该元素的内部。
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
element = wd.find_element(By.ID,'container')
# 限制 选择元素的范围是 id 为 container 元素的内部。
spans = element.find_elements(By.TAG_NAME, 'span')
for span in spans:
print(span.text)
pass等待元素出现
因为我们的代码执行的速度比 网站响应的速度 快。
网站还没有来得及 返回搜索结果,我们就执行了如下代码
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象
wd = webdriver.Chrome()
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.byhy.net/_files/stock1.html')
# 根据id选择元素,返回的就是该元素对应的WebElement对象
element = wd.find_element(By.ID, 'kw')
# 通过该 WebElement对象,就可以对页面元素进行操作了
# 比如输入字符串到 这个 输入框里
element.send_keys('通讯')
element = wd.find_element(By.ID, 'go')
element.click()
# 等待 1 秒
from time import sleep
sleep(1)
element = wd.find_element(By.ID,'1')
print(element.text)
wd.quit()
Selenium提供了一个更合理的解决方案,是这样的:
当发现元素没有找到的时候, 并不立即返回 找不到元素的错误。
而是周期性(每隔半秒钟)重新寻找该元素,直到该元素找到,
或者超出指定最大等待时长,这时才 抛出异常(如果是
find_elements之类的方法, 则是返回空列表)。Selenium 的 Webdriver 对象 有个方法叫
implicitly_wait,可以称之为隐式等待,或者全局等待。该方法接受一个参数, 用来指定 最大等待时长。
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象
wd = webdriver.Chrome()
wd.implicitly_wait(10)
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.byhy.net/_files/stock1.html')
# 根据id选择元素,返回的就是该元素对应的WebElement对象
element = wd.find_element(By.ID, 'kw')
# 通过该 WebElement对象,就可以对页面元素进行操作了
# 比如输入字符串到 这个 输入框里
element.send_keys('通讯')
element = wd.find_element(By.ID, 'go')
element.click()
element = wd.find_element(By.ID,'1')
print(element.text)
wd.quit()
获取元素属性
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象
wd = webdriver.Chrome()
wd.implicitly_wait(10)
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.byhy.net/_files/stock1.html')
element = wd.find_element(By.ID,'1')
print(element.text)
print(element.get_attribute('class'))
wd.quit()
要获取整个元素对应的HTML文本内容,可以使用
element.get_attribute('outerHTML')如果,只是想获取某个元素
内部的HTML文本内容,可以使用element.get_attribute('innerHTML')
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建 WebDriver 对象
wd = webdriver.Chrome()
wd.implicitly_wait(10)
# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('https://www.byhy.net/_files/stock1.html')
element = wd.find_element(By.ID,'1')
print(element.get_attribute('outerHTML'))
print(element.get_attribute('innerHTML'))
wd.quit()
CSS选择器
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
element = wd.find_element(By.CSS_SELECTOR, '.plant')
print(element.get_attribute('outerHTML'))
pass
子代使用> 后代使用空格 兄弟相邻使用+ 所有兄弟使用~ 共用使用逗号隔开
根据属性获取元素
css 选择器支持通过任何属性来选择元素,语法是用一个方括号
[]。比如要选择上面的a元素,就可以使用
[href="http://www.miitbeian.gov.cn"]。这个表达式的意思是,选择 属性href值为
http://www.miitbeian.gov.cn的元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample1.html')
# 根据属性选择元素
element = wd.find_element(By.CSS_SELECTOR, '[href="http://www.miitbeian.gov.cn"]')
# 打印出元素对应的html
print(element.get_attribute('outerHTML'))验证选择器可以在谷歌浏览器右击检查选择element,然后Ctrl+F查找选择器是否存在
frame切换
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.get('https://cdn2.byhy.net/files/selenium/sample2.html')
# 先根据name属性值 'innerFrame',切换到iframe中
wd.switch_to.frame('innerFrame')
# 根据 class name 选择元素,返回的是 一个列表
elements = wd.find_elements(By.CLASS_NAME, 'plant')
for element in elements:
print(element.text)
pass使用 WebDriver 对象的 switch_to 属性,像这样
wd.switch_to.frame(frame_reference)
其中, frame_reference 可以是 frame 元素的属性 name 或者 ID 。
比如这里,就可以填写 iframe元素的id ‘frame1’ 或者 name属性值 ‘innerFrame’。
怎么切换回原来的主html呢?很简单,写如下代码即可
wd.switch_to.default_content()
切换窗口
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.implicitly_wait(10)
wd.get('https://cdn2.byhy.net/files/selenium/sample3.html')
# 点击打开新窗口的链接
link = wd.find_element(By.TAG_NAME, "a")
link.click()
# mainWindow变量保存当前窗口的句柄
mainWindow = wd.current_window_handle
for handle in wd.window_handles:
# 先切换到该窗口
wd.switch_to.window(handle)
# 得到该窗口的标题栏字符串,判断是不是我们要操作的那个窗口
if '必应' in wd.title:
# 如果是,那么这时候WebDriver对象就是对应的该该窗口,正好,跳出循环,
break
# wd.title属性是当前窗口的标题栏 文本
print(wd.title)
wd.find_element(By.ID, 'sb_form_q').send_keys("白月黑羽")
# 通过前面保存的老窗口的句柄,自己切换到老窗口
wd.switch_to.window(mainWindow)
wd.find_element(By.ID, 'outerbutton').click()
input('')
radio单选框
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://cdn2.byhy.net/files/selenium/test2.html')
# 获取当前选中的元素
element = wd.find_element(By.CSS_SELECTOR,
'#s_radio input[name="teacher"]:checked')
print('当前选中的是: ' + element.get_attribute('value'))
# 点选 小雷老师
wd.find_element(By.CSS_SELECTOR,
'#s_radio input[value="小雷老师"]').click()
input('')
checkbox复选框
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://cdn2.byhy.net/files/selenium/test2.html')
# 先把 已经选中的选项全部点击一下
elements = wd.find_elements(By.CSS_SELECTOR,
'#s_checkbox input[name="teacher"]:checked')
for element in elements:
element.click()
# 再点击 小雷老师
wd.find_element(By.CSS_SELECTOR,
"#s_checkbox input[value='小雷老师']").click()
input('')
select下拉框
from selenium import webdriver
from selenium.webdriver.common.by import By
# 导入Select类
from selenium.webdriver.support.ui import Select
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://cdn2.byhy.net/files/selenium/test2.html')
# 创建Select对象
select = Select(wd.find_element(By.ID, "ss_single"))
# 通过 Select 对象选中小雷老师
select.select_by_visible_text("小雷老师")
input('')
multiple列表框
from selenium import webdriver
from selenium.webdriver.common.by import By
# 导入Select类
from selenium.webdriver.support.ui import Select
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://cdn2.byhy.net/files/selenium/test2.html')
# 创建Select对象
select = Select(wd.find_element(By.ID, "ss_multi"))
# 清除所有 已经选中 的选项
select.deselect_all()
# 选择小雷老师 和 小凯老师
select.select_by_visible_text("小雷老师")
select.select_by_visible_text("小凯老师")
input('')
鼠标移动
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://www.baidu.com/')
ac = ActionChains(driver)
# 鼠标移动到元素上
ac.move_to_element(
driver.find_element(By.CSS_SELECTOR, '[name="tj_briicon"]')
).perform()
pass
冻结界面
控制台输入:setTimeout(function(){debugger},5000)
弹出框处理
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://cdn2.byhy.net/files/selenium/test4.html')
# --- prompt ---
driver.find_element(By.ID, 'b3').click()
# 获取 alert 对象
alert = driver.switch_to.alert
# 打印 弹出框 提示信息
print(alert.text)
# 输入信息,并且点击 OK 按钮 提交
alert.send_keys('web自动化 - selenium')
alert.accept()
# 点击 Cancel 按钮 取消
driver.find_element(By.ID, 'b3').click()
alert = driver.switch_to.alert
alert.dismiss()Xpath
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://cdn2.byhy.net/files/selenium/test1.html')
elements = wd.find_elements(By.XPATH, '/html/body/div')
for element in elements:
print('--------')
print(element.get_attribute('outerHTML'))
‘//’ 符号也可以继续加在后面,比如,要选择 所有的 div 元素里面的 所有的 p 元素 ,不管div 在什么位置,也不管p元素在div下面的什么位置,则可以这样写
//div//p
elements = driver.find_elements(By.XPATH, "//div//p")如果使用CSS选择器,对应代码如下
elements = driver.find_elements(By.CSS_SELECTOR,"div p")如果,要选择 所有的 div 元素里面的 直接子节点 p , xpath,就应该这样写了
//div/p如果使用CSS选择器,则为
div > p
根据id属性选择
选择 id 为 west 的元素,可以这样
//*[@id='west']
如果是CSS的话,这样写:[id='west']选择所有p里面id为west的元素,可以这样 //p[@id='west']
根据class属性选择

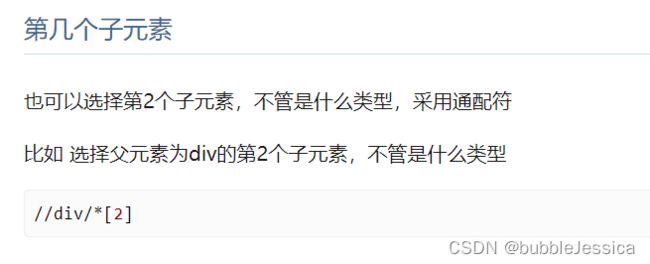
某类型第几个子元素
比如要选择 p类型第2个的子元素,就是://p[2]相当于CSS里面的p:nth-of-type(2)
注意:是p类型第2个子元素,而不是第2个子元素并且是p类型
input:nth-child(1)是input上面父节点div的第一个子节点
范围选择

选择父节点(/..)
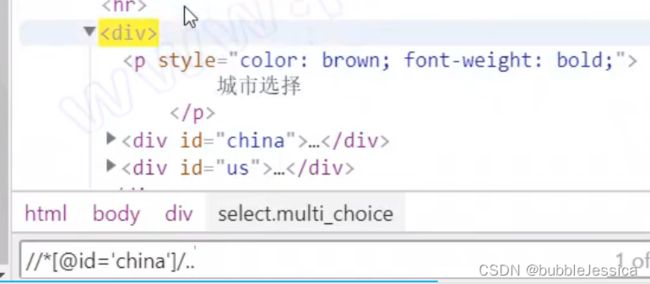
注意点
from selenium import webdriver
from selenium.webdriver.common.by import By
wd = webdriver.Chrome()
wd.implicitly_wait(5)
wd.get('https://cdn2.byhy.net/files/selenium/test1.html')
china = wd.find_element(By.ID, 'china')
elements = china.find_elements(By.XPATH, './/p')
for element in elements:
print(element.get_attribute('outerHTML'))
print('--------')
pass注意webElement使用XPATH,需要在前面加上.