VGG(pytorch)
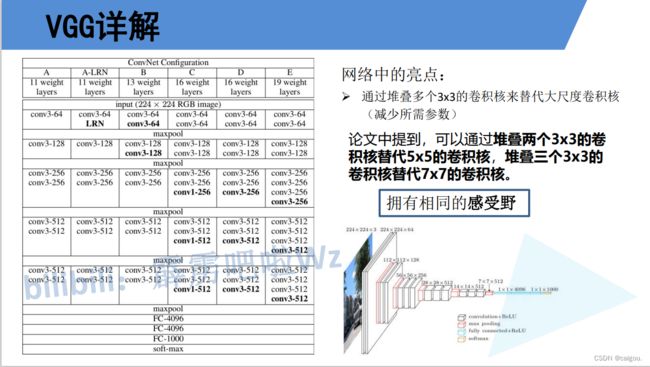
VGG:达到了传统串型结构深度的极限
学习VGG原理要了解CNN感受野的基础知识


model.py
import torch.nn as nn
import torch
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
#features参数是特征层模型,传入这个参数直接使用构造的特征层模型
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list):
layers = []
in_channels = 3
#传入参数cfg是一个列表,遍历参数列表构造VGG特征层
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
#特征层函数返回一个nn.Sequential(*layers),
#这段代码中的 return nn.Sequential(*layers) 使用了 nn.Sequential 类来创建一个神经网络模型。
# 在这里,layers 是一个可迭代对象,包含了神经网络模型的各个层或模块。
#这段代码的作用是封装一个神经网络模型,该模型按照 layers 中层或模块的顺序连接起来,并作为 nn.Sequential 对象返回。
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
#在函数定义中的 **kwargs 是一个特殊的参数形式,它允许函数接受任意数量的关键字参数(keyword arguments)。
# 这个参数形式使用了双星号 ** 来表示。
#在上述代码中,**kwargs 的作用是允许函数 vgg() 接受额外的关键字参数,并将这些参数收集到 kwargs 字典中
#如vgg(model_name="vgg16", num_classes=10, pretrained=True) pretrained就是一个**kwargs参数
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
train.py
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import vgg
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
#定义一个数据加载器用于迭代提取数据
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 30
best_acc = 0.0
save_path = './{}Net.pth'.format(model_name)
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
这里由于训练时间太长,运行了19个epoch中断。结果如下
using cuda:0 device.
Using 8 dataloader workers every process
using 3306 images for training, 364 images for validation.
train epoch[1/30] loss:1.542: 100%|██████████| 104/104 [08:39<00:00, 4.99s/it]
100%|██████████| 12/12 [01:13<00:00, 6.15s/it]
[epoch 1] train_loss: 1.605 val_accuracy: 0.245
train epoch[2/30] loss:1.399: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.12s/it]
[epoch 2] train_loss: 1.476 val_accuracy: 0.401
train epoch[3/30] loss:1.310: 100%|██████████| 104/104 [08:34<00:00, 4.94s/it]
100%|██████████| 12/12 [01:18<00:00, 6.53s/it]
[epoch 3] train_loss: 1.293 val_accuracy: 0.456
train epoch[4/30] loss:0.958: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.11s/it]
[epoch 4] train_loss: 1.185 val_accuracy: 0.519
train epoch[5/30] loss:1.327: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.11s/it]
[epoch 5] train_loss: 1.135 val_accuracy: 0.527
train epoch[6/30] loss:1.209: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.12s/it]
[epoch 6] train_loss: 1.077 val_accuracy: 0.571
train epoch[7/30] loss:0.725: 100%|██████████| 104/104 [1:25:27<00:00, 49.30s/it]
100%|██████████| 12/12 [01:21<00:00, 6.82s/it]
[epoch 7] train_loss: 1.051 val_accuracy: 0.596
train epoch[8/30] loss:1.146: 100%|██████████| 104/104 [08:50<00:00, 5.10s/it]
100%|██████████| 12/12 [01:27<00:00, 7.31s/it]
[epoch 8] train_loss: 1.008 val_accuracy: 0.615
train epoch[9/30] loss:1.381: 100%|██████████| 104/104 [08:48<00:00, 5.08s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 9] train_loss: 0.995 val_accuracy: 0.640
train epoch[10/30] loss:0.466: 100%|██████████| 104/104 [08:34<00:00, 4.95s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 10] train_loss: 0.966 val_accuracy: 0.673
train epoch[11/30] loss:0.867: 100%|██████████| 104/104 [08:33<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.13s/it]
[epoch 11] train_loss: 0.926 val_accuracy: 0.659
train epoch[12/30] loss:0.804: 100%|██████████| 104/104 [08:34<00:00, 4.94s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 12] train_loss: 0.916 val_accuracy: 0.665
train epoch[13/30] loss:0.377: 100%|██████████| 104/104 [08:35<00:00, 4.96s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 13] train_loss: 0.879 val_accuracy: 0.648
train epoch[14/30] loss:0.588: 100%|██████████| 104/104 [08:35<00:00, 4.95s/it]
100%|██████████| 12/12 [01:13<00:00, 6.16s/it]
[epoch 14] train_loss: 0.841 val_accuracy: 0.676
train epoch[15/30] loss:0.725: 100%|██████████| 104/104 [08:35<00:00, 4.96s/it]
100%|██████████| 12/12 [01:13<00:00, 6.13s/it]
[epoch 15] train_loss: 0.830 val_accuracy: 0.687
train epoch[16/30] loss:0.977: 100%|██████████| 104/104 [08:35<00:00, 4.96s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 16] train_loss: 0.811 val_accuracy: 0.720
train epoch[17/30] loss:0.923: 100%|██████████| 104/104 [08:34<00:00, 4.95s/it]
100%|██████████| 12/12 [01:13<00:00, 6.14s/it]
[epoch 17] train_loss: 0.796 val_accuracy: 0.703
train epoch[18/30] loss:1.150: 100%|██████████| 104/104 [08:34<00:00, 4.95s/it]
100%|██████████| 12/12 [01:13<00:00, 6.15s/it]
[epoch 18] train_loss: 0.794 val_accuracy: 0.720
train epoch[19/30] loss:0.866: 19%|█▉ | 20/104 [01:54<07:59, 5.71s/it]predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import GoogLeNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "../tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = GoogLeNet(num_classes=5, aux_logits=False).to(device)
# load model weights
weights_path = "./googleNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path, map_location=device),
strict=False)
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()
预测结果
class: daisy prob: 0.00207
class: dandelion prob: 0.00144
class: roses prob: 0.101
class: sunflowers prob: 0.00535
class: tulips prob: 0.89