ChatGPT在指尖跳舞: open-interpreter实现本地数据采集、处理一条龙
原文:ChatGPT在指尖跳舞: open-interpreter实现本地数据采集、处理一条龙 - 知乎
目录
收起
Part1 前言
Part2 Open - Interpreter 简介
Part3 安装与运行
Part4 工作场景
1获取网页内容
2 pdf 文件批量转换
3 excel 文件合并
Part5总结
参考资料
往期推荐
更多详情请点击查看原文ChatGPT在指尖跳舞: open-interpreter实现本地数据采集、处理一条龙
Python教学专栏,旨在为初学者提供系统、全面的Python编程学习体验。通过逐步讲解Python基础语言和编程逻辑,结合实操案例,让小白也能轻松搞懂Python!
>>>点击此处查看往期Python教学内容
本文目录
一、前言
二、Open - Interpreter 简介
三、安装与运行
四、工作场景
(一)获取网页内容
(二)pdf文件批量转换
(三)excel文件合并
五、总结
本文共4192个字,阅读大约需要11分钟,欢迎指正!
Part1 前言
本期介绍由 KillianLucas 发布在 Github 上的一个开源项目 open-interpreter,该项目允许 AI 大语言模型(LLMs)在本地电脑运行代码(Python、Javascript、Shell 等),和之前文章中通过调用 ChatGPT 运行代码的方法有着异曲同工之妙。(传送门:Python 实战 | ChatGPT + Python 实现全自动数据处理/可视化)
当然,与之相比,open-interpreter 更加强大和完善,能够更灵活地处理多种任务,目前已经登上了 Github 热榜并获得了 17k+ 的星标。本篇文章将介绍 open-interpreter 的用法,并给出一些应用示例。
Part2 Open - Interpreter 简介
一言蔽之,Open - Interpreter 就是一个部署在本地电脑上的,能够帮你完成本地电脑操作,调用本地的网络、编程环境帮你采集和操作、处理本地数据的 AI 工具。
实际上,OpenAI 也发布过一款代码解释器,该解释器使用 GPT-4 模型,在沙盒、防火墙执行环境中工作。OpenAI 发布的代码解释器支持上传和下载文件,但有 100M 的文件大小限制。此外,出于安全考虑,OpenAI 为这个解释器设置了严格的限制,使它不能访问网络,且只能使用有限的三方库[1]。
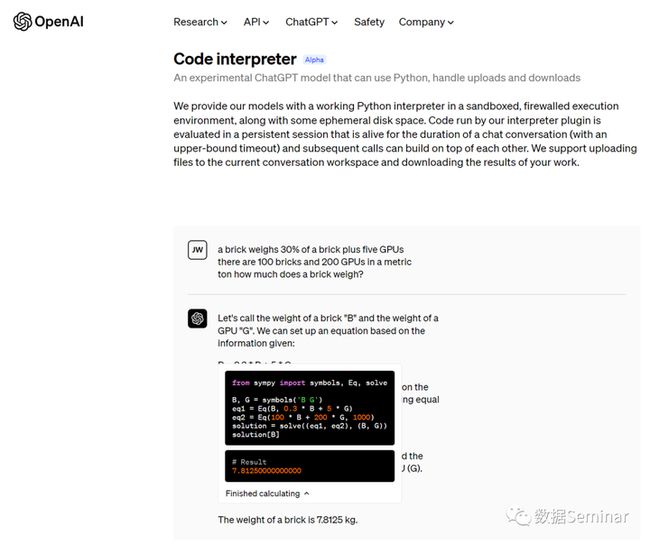
OpenAI 发布的代码解释器
与 OpenAI 发布的解释器相比,open-interpreter 解释器具有以下的优势:
- 支持联网,可以通过 Python 三方库访问网络
- 本地访问,文件大小和操作时间没有限制
- 可以使用所有库,GPT 在给出的代码中会包含安装库的代码
- 支持GPT-4和ChatGPT-3.5-Turbo,甚至如果没有API,还可以把模型换成开源的Code LLaMa
Part3 安装与运行
open-interpreter 既支持在 Python 开发环境中运行,也支持在本地终端运行(需要确保本地编程语言已部署),但发布者 KillianLucas 更倾向于使用终端运行,在本文结果的测试中,笔者也确实发现用终端运行更加方便。无论使用哪种运行方式,安装方法都是一样的:
1 pip install open-interpreter
安装完成后,如果要在终端运行,有三种开启方式:
- 默认开启——使用 GPT-4 模型:
interpreter - 快速开启——使用 GPT-3.5-Turbo 模型:
interpreter --fast - 本地开启——使用本地模型(免费):
interpreter --local
在终端输入开启命令并回车后会提示指定 OpenAI API Key,输入 Key 并回车后即可运行 open-interpreter:
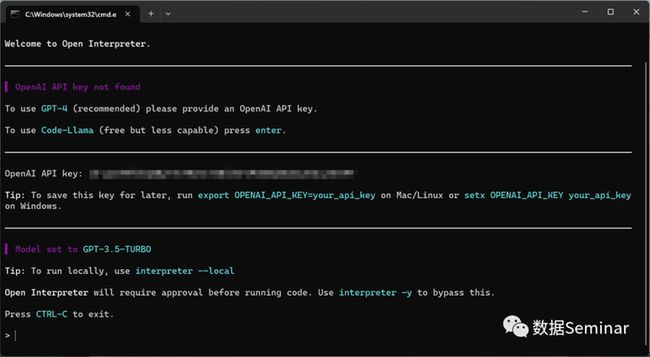
open-interpreter 终端运行界面(使用 GPT-3.5-Turbo 模型)
这里顺便提一下,如果不想在每次使用时重复输入 OpenAi API Key,那么可以将 Key 储存在环境变量中,这样每次运行的时候将从环境变量中自动导入。只需要在计算机设置中搜索环境变量,然后新建一个名为“OPENAI_API_KEY”的环境变量即可:
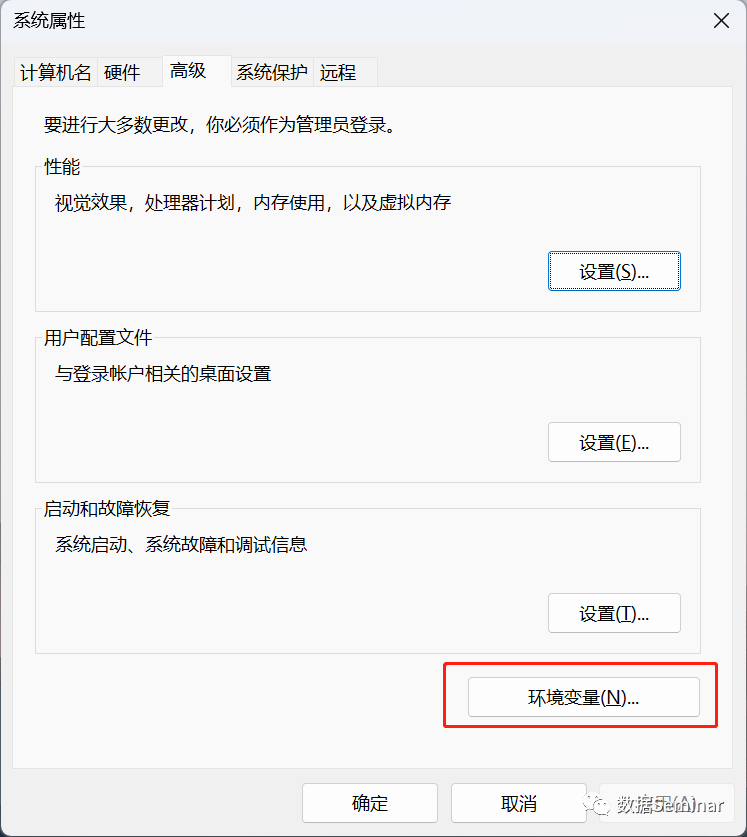
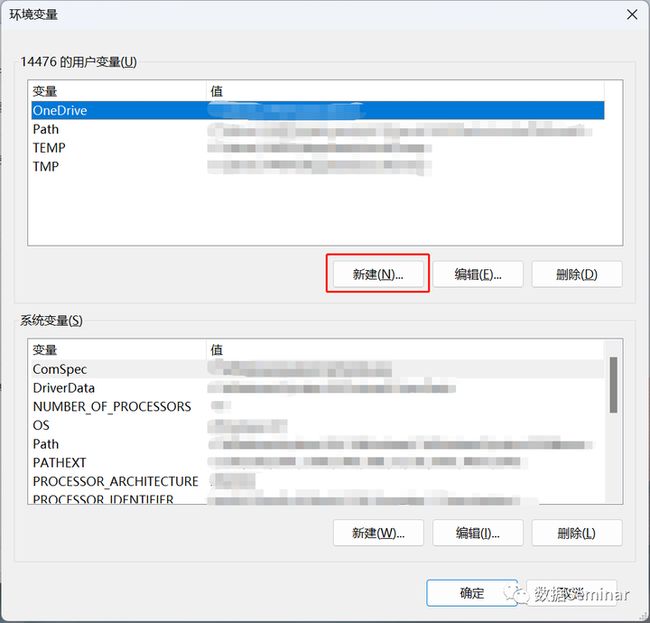
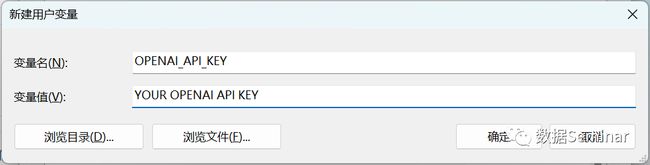
也可以在终端中输入setx OPANAI_API_KEY YOUROPANAIAPIKEY来将 Key 存入环境变量。在 Python 开发环境中要通过导入库的方式运行 open-interpreter:
1 import interpreter
如果要使用其他模型,需要用以下代码指定,否则会默认使用 GPT-4 模型:
1 interpreter.model = "gpt-3.5-turbo"
在开发环境中调用 open-interpreter 需要使用函数interpreter.chat()。如果不指定内容,将和终端运行一样启动交互式聊天,如果要更精确的控制,也可以在函数中指定具体的提问内容:
1 # 交互式聊天
2 interpreter.chat()
3
4 # 精确控制
5 interpreter.chat("你的提问内容")
当 open-interpreter 给出任务的实行计划和代码时,需要输入y来确认接受给出的计划或者代码,如果对给出的答案不满意,可以输入n,并重新给出要求让 AI 完善答案,直到满意为止。接下来将用几个工作场景中的应用来展示 open-interpreter 的强大功能。
Part4 工作场景
1获取网页内容
open-interpreter 最引人注目的特点是支持联网,我们首先让它尝试读取和理解网页的内容。我们索性让它读取 open-interpreter 项目所在的 Github 网址,来一个简单的“自我介绍”。
首先,我们使用开启命令运行 open-interpreter(这里使用的是 GPT-4 模型),然后向它提问“这个Github项目的主要内容是什么?https://github.com/KillianLucas/open-interpreter”,之后 AI 给出了相应的解决步骤以及 Python 代码:
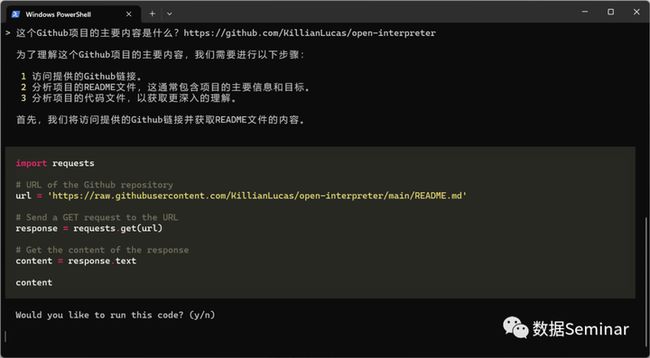
访问网页解决方案
我们键入y选择接受这个解决思路,open-interpreter 会运行代码并给出结果:
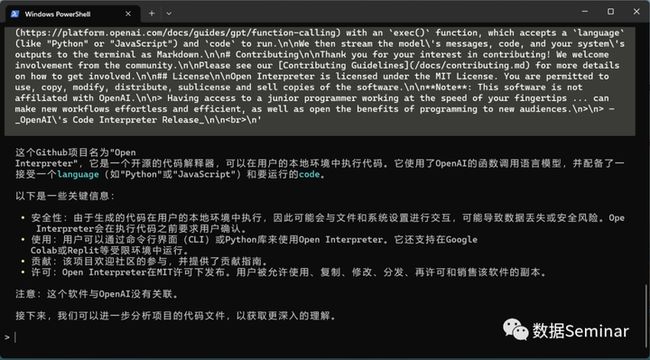
访问网页结果
open-interpreter 成功读取了该网页的内容,并给出了信息摘要。
接下来,我们尝试让 open-interpreter 完成一个简单的爬虫任务。我们想要从浙江省科学技术厅发布的通知中获取“2022年度浙江省科技领军企业认定名单”和“2022年度浙江省科技小巨人企业认定名单”,发布通知的网页地址为“https://kjt.zj.gov.cn/art/2023/1/13/art_1229225203_5055092.html”,原始网页内容如下:

原始网页信息
我们向 open-interpreter 发出指令让其获取这些内容,AI 给出的解决方案为:
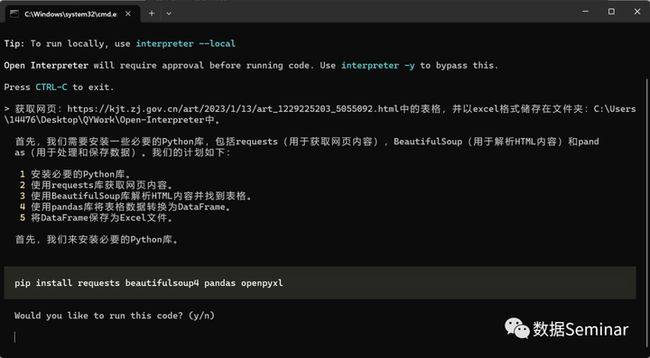
从网页获取表格方案
可以看到,AI 首先给出代码安装request、beautifulsoup4、pandas和openpyxl四个库,由于在此之前这四个库已经安装过了,因此键入n并让其修改方案,AI 的修改结果如图:
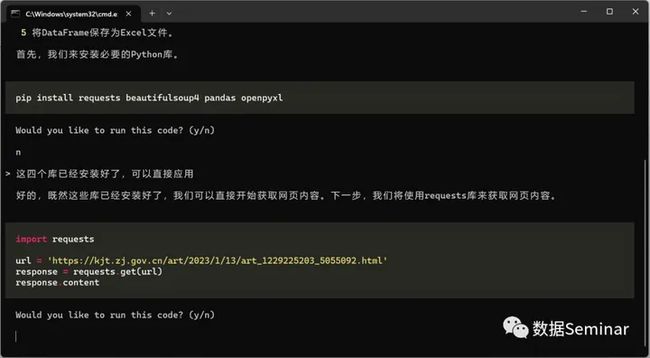
按要求修正 AI 给出的方案
之后重复上述操作,根据自己的需求选择是否接受 AI 的代码,并让其一直完善直到满意即可。最终,open-interpreter 完成了任务,将表格储存在了要求的目录下:
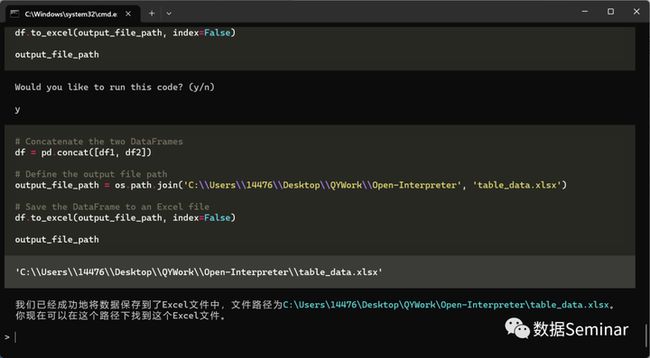
网页表格获取结果的储存
最终 AI 储存的 excel 内容如下图所示。可以看到操作过程中 AI 正确获取了我们需要的信息,且没有包含无关信息,任务完成的非常成功:
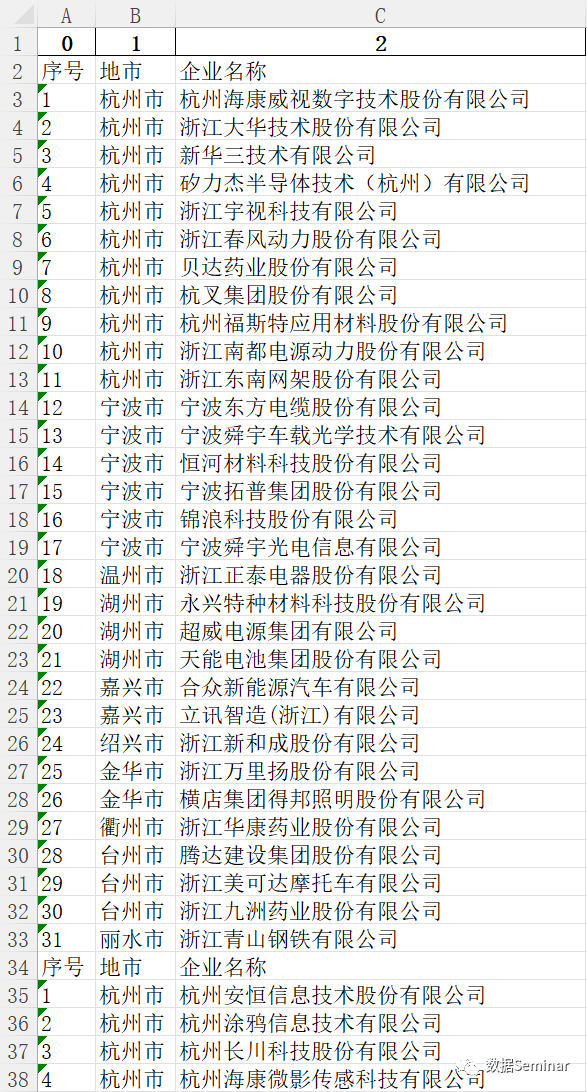
open-interpreter 获取的 excel 表格内容
2 pdf 文件批量转换
数据处理过程中经常会遇到一些以 pdf 格式存储的表格,使用 Python 可以将这些表格储存为 excel 格式。现在文件夹中有四个 pdf 文件,我们向 open-interpreter 发出指令让它把其中的表格提取出来,并以 excel 格式储存。
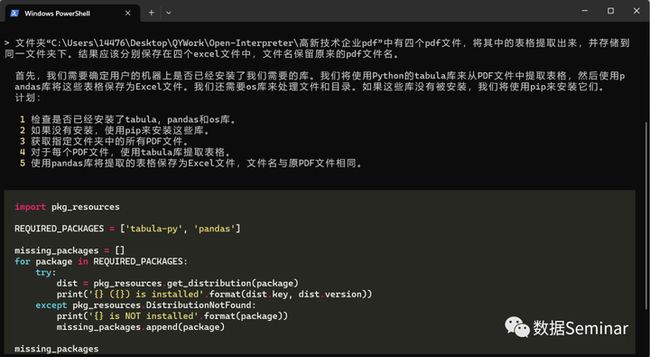
pdf 批量转换方案
同样地,AI 将给出解决的步骤,我们按照自己的需求不断调整,最终 AI 将完成 pdf 的批量转换,并将转换得到的 excel 文件保存在同一文件夹下:
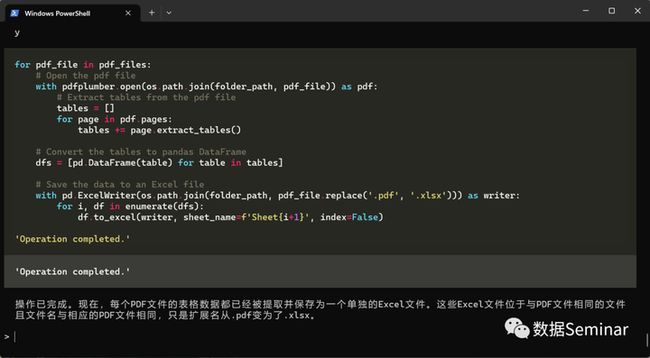
pdf 转换完成
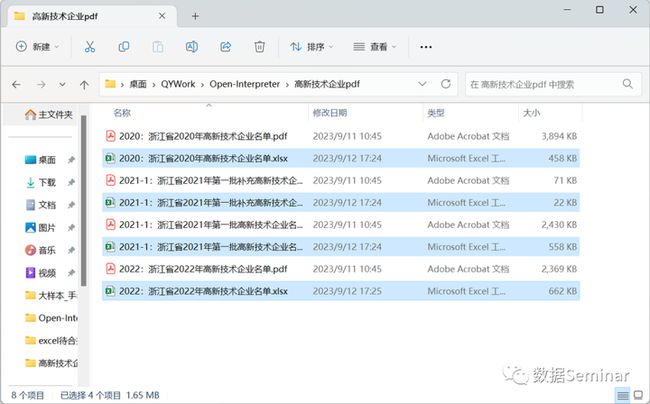
转换得到的 excel 表格
3 excel 文件合并
处理数据时我们经常会遇到这样的情况:由于数据库导出限制或者其他原因,一个完整的数据集被拆分为多个小的数据集分开存储,而数据分析时我们需要将小的数据集合并。这类任务使用 open-interpreter 也可以轻松完成。
本节示例数据我们使用了企研·社科大数据平台“中国公共政策与绿色发展数据库”中的“21家主要银行绿色信贷情况统计表”(网址:https://r.qiyandata.com/)。文件夹中共有五个 excel 表,其字段全部相同,现在我们向 open-interpreter 发出指令让它把五个表合并成一个大的 excel 表:
“21家主要银行绿色信贷情况统计表”位于CPPGD下的“绿色金融”-“绿色信贷”模块。
中国公共政策与绿色发展数据库(简称 "CPPGD")是由企研数据携手浙江大学中国农村发展研究院和浙江工商大学经济学院联合发起,为助力国家围绕"碳达峰、碳中和"双碳目标做出的一系列重大战略部署,服务中国绿色发展及相关领域学术与政策研究而倾力打造的专题数据库。
更多数据相关资讯请查看原文!
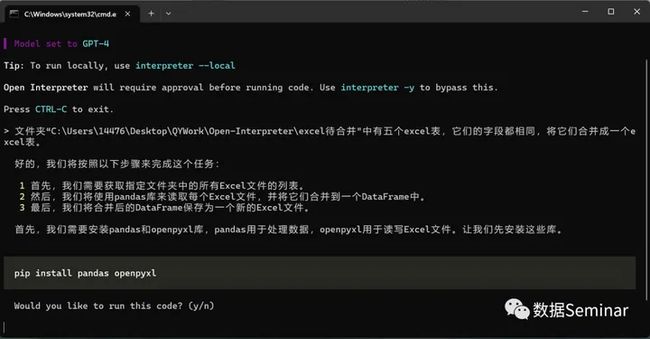
excel 合并方案
最后,open-interpreter 成功的将五个 excel 表合并成了一个名为“merged.xlsx”的总表:
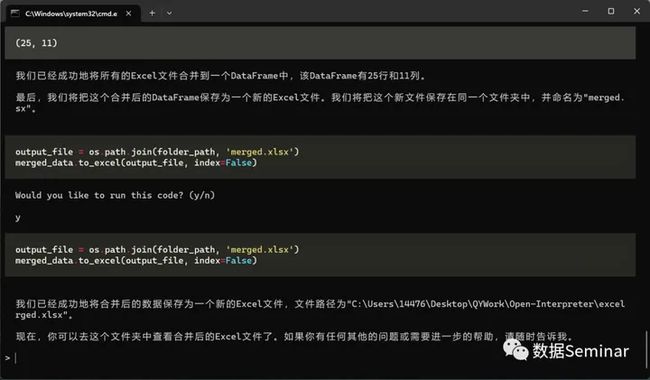
excel 合并结果
最终合并的表格共有 25 行,包含 11 个字段:
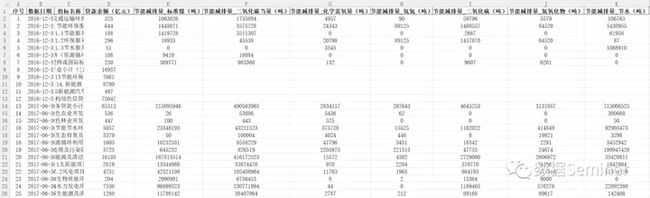
合并后的 excel 数据
Part5总结
随着 LLM 大模型的发展,AI 可以使用的范围越发广泛,各种 AI 工具层出不穷。本文介绍的 open-interpreter 在一定程度上解决了 GPT 模型不能联网的问题,本地运行的特点让它可以操作本地文件,代码确认功能则保证了安全性问题,是一个很好的 LLM 拓展应用。当然,介于篇幅问题,本文没有面面俱到地展示 open-interpreter 的所有功能,有兴趣的读者可以参考作者 KillianLucas 贴在 Github 项目页中的 Colab 笔记[2],或者自行安装探索。
参考资料
[1]有限的三方库: https://wfhbrian.com/mastering-chatgpts-code-interpreter-list-of-python-packages/
[2]Colab 笔记: https://qiyandata.feishu.cn/wik