Java I/O流详解
Java I/O流
1、Java I/O流概述
IO就是输入、输出。Java IO类库基于抽象基础类InputStream和OutputStream构建了一套I/O体系,主要解决从数据源读入数据和将数据写入到目的端的问题。我们可以将数据源和目的地理解为IO流的两端。
- 从一种数据源中通过InputStream流对象读入数据到程序内存中流程如图 1-1所示;
- 从程序内存中通过OutputStream流对象写入到目的地的流程图如图 1-2所示。

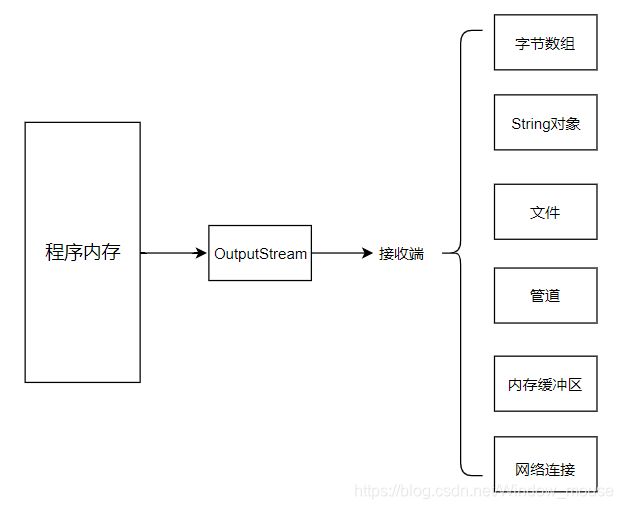
然后,除了面向字节流的InputStream/OutputStream体系之外,Java IO库还提供面向字符流的Reader/Writer体系。
Reader/Writer的继承结构主要是为了国际化,因为它能更好地处理16位的Unicode字符。
注:若无特殊说明,默认为JDK 1.8。
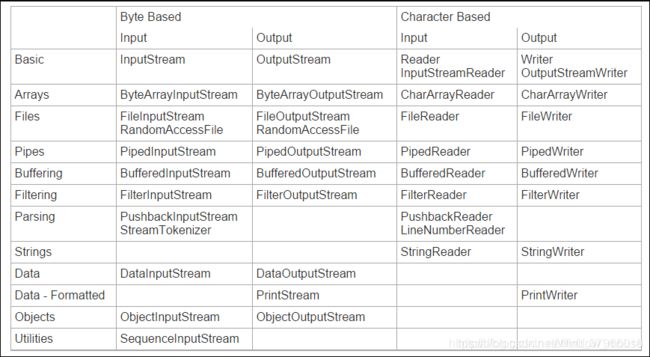
2、Java I/O流总体设计
理解了I/O类库的设计思路,理清其中的层次脉络之后。就能知道用哪些流对象可以组合成什么样的功能,例如:
-
从流的流向上可以分为:
- 输入流InputStream或Reader,任何从这两个流派生而来的类都有read()基本方法,读取单个字节或者字节数组;
- 输出流OutputStream或Writer,任何从这两个流派生而来的类都有write()基本方法,用于写单个字节或者字节数组。
-
从操纵字节或者操作字符的角度,可分为:
- 面向字节流的类,基本都以XxxStream结尾;
- 面向字符流的类,基本都以XxxReader或者XxxWriter结尾(一般而言)。
3、装饰器模式
我们一般在使用I/O流的时候都会见到类似下面的语句:
FileInputStream inputStream = new FileInputStream(new File("file.txt"));
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
这里其实是一种装饰器模式的使用,I/O体系中使用了装饰器模式包装了各种各样的功能类。
在Java I/O流中体系中,FilterInputStream/FilterOutputStream、FilterReader/FilterWriter就是装饰器模式的接口类,从该类向下包装了一些功能类。例如,DataInputStream、BufferedInputStream等。
整个I/O流的继承体系结构如下:
-
InputStream体系如图 3-1所示。

图 3-1 -
OutputStream体系如图 3-2所示。
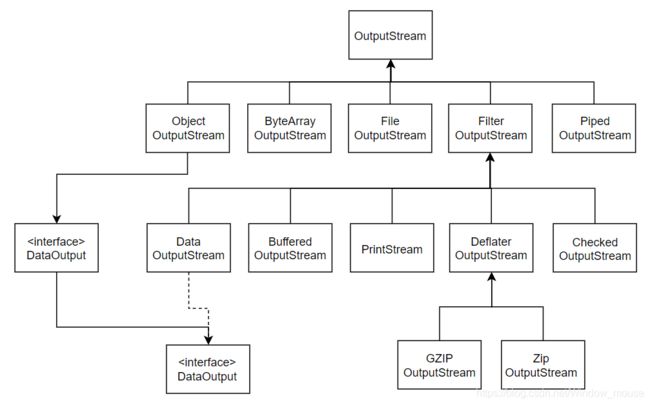
图 3-2 -
Reader体系如图 3-3所示。
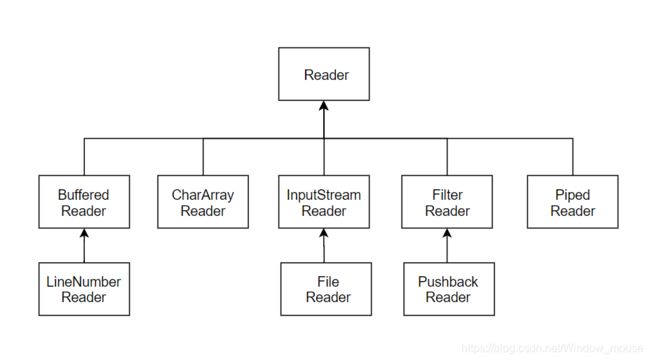
图 3-3 -
Writer体系如图 3-4所示。
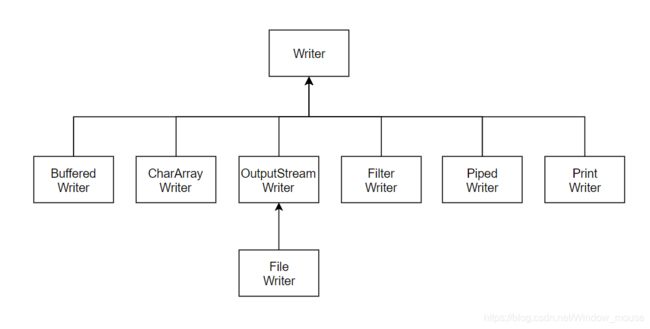
图 3-4
总结如下图 3-5所示。
4、File类
File类其实不止是代表一个文件,它也能代表一个目录下的一个组件(代表一个文件路径)。java.io.File类(File类)其实是一个与文件本身操作有关的类,此类可以实现文件创建、删除、重命名、获取文件大小、修改日期等常见的系统文件操作。
如果要使用File类则必须提供完整的文件操作路径,对于文件路径的设置可以通过File类的构造方法完成,当获取了正确的文件路径后就可以对文件进行操作,常用方法如下所示。
// 构造方法:
public File(String pathname) // 给定一个要操作文件的完整路径
public File(File parent, String child) // 给定要操作文件的父路径和子文件名称
// 成员方法:
boolean delete() // 删除文件或文件夹目录。
boolean createNewFile() // 创建一个新的空文件。
boolean mkdirs() // 创建一个新的空文件夹。
boolean canExecute() // 文件是否能执行
File list() // 获取指定目录下的文件和文件夹名称。
File listFiles() // 获取指定目录下的文件和文件夹对象。
boolean exists() // 文件或者文件夹是否存在
String getAbsolutePath() // 获取绝对路径
long getFreeSpace() // 返回分区中未分配的字节数。
String getName() // 返回文件或文件夹的名称。
String getParent() // 返回父目录的路径名字符串;如果没有指定父目录,则返回 null。
File getParentFile() // 返回父目录File对象
String getPath() // 返回路径名字符串。
long getTotalSpace() // 返回此文件分区大小。
long getUsableSpace() // 返回占用字节数。
int hashCode() // 文件哈希码。
long lastModified() // 返回文件最后一次被修改的时间。
long length() // 获取长度,字节数。
boolean canRead() // 判断是否可读
boolean canWrite() // 判断是否可写
boolean isHidden() // 判断是否隐藏
static File[] listRoots() // 列出可用的文件系统根。
boolean renameTo(File dest) // 重命名
boolean setExecutable(boolean executable) // 设置执行权限。
boolean setExecutable(boolean executable, boolean ownerOnly) // 设置其他所有用户的执行权限。
boolean setLastModified(long time) // 设置最后一次修改时间。
boolean setReadable(boolean readable) // 设置读权限。
boolean setReadable(boolean readable, boolean ownerOnly) // 设置其他所有用户的读权限。
boolean setWritable(boolean writable) // 设置写权限。
boolean setWritable(boolean writable, boolean ownerOnly) // 设置所有用户的写权限。
// 路径分隔符
static final String separator // 不同操作系统可以获取不同的分隔符
Tips:不同系统对文件路径的分割符表是不一样的,比如Windows中是“\”,Linux是“/”。而File类给我们提供了抽象的表示File.separator,屏蔽了系统层的差异。因此平时在代码中不要使用诸如“\”这种代表路径,可能造成Linux平台下代码执行错误。
范例1:创建带目录的文件
package edu.blog.test09;
import java.io.File;
import java.io.IOException;
public class FileTestDemo01 {
public static void main(String[] args) throws IOException {
File file = new File("d:" + File.separator + "hello" + File.separator +
"demo" + File.separator + "message" +
File.separator + "test.txt"); //操作文件路径
if (!file.getParentFile().exists()) { //父路径不存在
System.out.println(file.getParentFile().mkdirs()); //创建父路径
}
if (file.exists()) { //文件存在
System.out.println(file.delete()); //删除文件
} else { //文件不存咋
System.out.println(file.createNewFile()); //创建新的文件
}
}
}
/*
结果:
创建了D:\hello\demo\message\text.txt
*/
本程序创建了带目录的文件,所以在文件创建前首先要判断父目录是否存在,如果不存在则通过getParentFile()获取父路径的File类对象,并利用mkdirs()创建多级父目录。
范例2:获取文件的详细信息
获取路径“E:\QQMusic\musicDownload\song\17岁 - 刘德华.mp3”的文件信息。
package edu.blog.test09;
import java.io.File;
import java.io.IOException;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
public class FileTestDemo02 {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "QQMusic" +
File.separator + "musicDownload" + File.separator +
"song" + File.separator + "17岁 - 刘德华.mp3");
System.out.println("文件是否可读:" + file.canRead());
System.out.println("文件是否可写:" + file.canWrite());
System.out.println("文件大小:" + MathUtil.round(
file.length() * 1.0 / 1024 / 1024, 2) + "M");
System.out.println("最后修改时间:" + DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss").
format(LocalDateTime.ofInstant(Instant.ofEpochMilli(file.lastModified()),
ZoneId.of("Asia/Shanghai"))));
System.out.println("是否为目录:" + file.isDirectory());
System.out.println("是否为文件:" + file.isFile());
}
}
class MathUtil {
private MathUtil() {
}
public static double round(double num, int scale) {
return Math.round(Math.pow(10, scale) * num / Math.pow(10, scale));
}
}
/*
结果:
文件是否可读:true
文件是否可写:true
文件大小:4.0M
最后修改时间:2020-07-16 16:34:31
是否为目录:false
是否为文件:true
*/
本程序中利用File类中提供的方法获取了与文件有关的一些基础信息,在获取文件长度以及最后修改日期时返回的数据类型都是long,所以进行相应的转换后才可以方便阅读。日期处理类用的是LocalDateTime类,不清楚的可以看一下文章。
范例3:文件批量更名
项目开发过程中,经常会存在数据采集的问题,假设现在有一个需求,就是将某一个目录(假设为E:\test)中的所有以“.txt”为后缀的文件全部改为以“.java”的后缀。
此范例的执行流程如图 4-1、图 4-2所示。


package edu.blog.test10;
import java.io.File;
public class FileUtil {
public FileUtil() {
}
public static void getAllFileName(File file) {
if (file.isDirectory()) { // 当前路径为目录
File[] files = file.listFiles(); // 获得此路径所有的File实例对象
if (files != null) { // File实例不为null
for (File f : files) { // 拿到每一个File实例对象
if (f.isFile()) { // 如果是文件直接输出文件名
System.out.println(f.getName());
} else if (f.isDirectory()) { // 如果是目录则递归调用
getAllFileName(f);
}
}
}
} else if (file.isFile()) { // 当前路径为文件
System.out.println(file.getName()); // 直接输出文件名
}
}
public static void renameFile(File file, String fileNameSuffix, String newFileNameSuffix) {
if (file.isDirectory()) { // 当前路径为目录
File[] files = file.listFiles(); // 获得此路径所有的File实例对象
if (files != null) { // File实例不为null
for (File f : files) { // 拿到每一个File实例对象
renameFile(f,fileNameSuffix,newFileNameSuffix); // 递归调用
}
}
} else { // 当前路径为文件
if (file.isFile()) {
String fileName = null; // 文件名称
if (file.getName().endsWith(fileNameSuffix)) { // 是否以"fileNameSuffix"为后缀
fileName = file.getName().substring(0, file.getName().
lastIndexOf(".")) + newFileNameSuffix;
File newFile = new File(file.getParentFile(), fileName); // 新的文件名
file.renameTo(newFile); // 重命名
}
}
}
}
}
package edu.blog.test10;
import java.io.File;
public class FileTestDemo {
public static void main(String[] args) {
String filePathName = "e:" + File.separator + "test"; // 给定目录
String fileNameSuffix = ".java"; // 文件后缀
String newFileNameSuffix = ".txt"; // 文件新后缀
File file = new File(filePathName);
//先输出路径里面所有的文件名
FileUtil.getAllFileName(file);
System.out.println("=========================");
//改变文件的后缀
FileUtil.renameFile(file, fileNameSuffix, newFileNameSuffix);
//先输出路径里面所有的文件名
FileUtil.getAllFileName(file);
System.out.println("=========================");
}
}
/*
结果:
新建文本文档 - 副本 (2).java
新建文本文档 - 副本 (3).java
新建文本文档 - 副本 (4).java
新建文本文档 - 副本 (5).java
新建文本文档 - 副本 (6).java
新建文本文档 - 副本.java
新建文本文档.java
=========================
新建文本文档 - 副本 (2).txt
新建文本文档 - 副本 (3).txt
新建文本文档 - 副本 (4).txt
新建文本文档 - 副本 (5).txt
新建文本文档 - 副本 (6).txt
新建文本文档 - 副本.txt
新建文本文档.txt
=========================
*/
5、字节流
5.1、InputStream 字节输入流
InputStream是输入流,它是从数据源对象读入数据到程序内存,使用的流对象,其定义为:
public abstract class InputStream extends Object implements Closeable{}
很明显InputStream类它是一个抽象类,继承于Object类,实现了Closeable接口。
其中,Closeable接口从JDK 1.5后提供,其定义如下:
public interface Closeable extends AutoCloseable {
public void close() throws IOException;
}
注:《AutoCloseable接口》这篇文章简单介绍了AutoCloable接口。
此外InputStream类还提供了一些基础的输入流方法,如下所示。
//从数据中读入一个字节,并返回该字节,遇到流的结尾时返回-1
abstract int read();
//读入一个字节数组,并返回实际读入的字节数,最多读入b.length个字节,遇到流结尾时返回-1
int read(byte[] b);
// 读入一个字节数组,返回实际读入的字节数或者在碰到结尾时返回-1.
//b:代表数据读入的数组, off:代表第一个读入的字节应该被放置的位置在b中的偏移量,len:读入字节的最大数量
int read(byte[],int off,int len);
// 返回当前可以读入的字节数量,如果是从网络连接中读入,这个方法要慎用,
int available();
//在输入流中跳过n个字节,返回实际跳过的字节数
long skip(long n);
//标记输入流中当前的位置
void mark(int readlimit);
//判断流是否支持打标记,支持返回true
boolean markSupported();
// 返回最后一个标记,随后对read的调用将重新读入这些字节。
void reset();
//关闭输入流,这个很重要,流使用完一定要关闭
void close();
接下来列出一些继承于InputStream的流,其实就是对应了一些数据源类型,如下表 5-1所示。
| 类 | 功能 |
|---|---|
| ByteArrayInputStream | 将字节数组作为InputStream |
| StringBufferInputStream | 将String转成InputStream |
| FileInputStream | 从文件中读取内容 |
| PipedInputStream | 产生用于写入相关PipedOutputStream的数据。实现管道化 |
| SequenceInputStream | 将两个或多个InputStream对象转换成单一的InputStream |
| FilterInputStream | 抽象类,主要是作为“装饰器”的接口类,实现其他的功能流 |
5.2、OutputStream 字节输出流
OutputStream是输出流,它是将程序内存的数据写入到目的地(也就是接收数据的一端),其定义为:
public abstract class OutputStream implements Closeable, Flushable{}
很明显OutputStream类它也是一个抽象类,继承于Object类,实现了Closeable接口、Flushable接口。
其中,Closeable接口同上面一样,不再赘述。而Flushable接口也是从JDK 1.5后提供,其定义如下:
public interface Flushable{
public void flush() throws IOException;
}
此外OutputStream类也提供了一些基础的输出流方法,如下所示。
// 写出一个字节的数据
abstract void write(int n);
// 写出字节到数据b
void write(byte[] b);
// 写出字节到数组b,off:代表第一个写出字节在b中的偏移量,len:写出字节的最大数量
void write(byte[] b, int off, int len);
//冲刷输出流,也就是将所有缓冲的数据发送到目的地
void flush();
// 关闭输出流
void close();
同样地,OutputStream也提供了一些基础流的实现,这些实现也可以和特定的目的地(接收端)对应起来,比如输出到字节数组或者是输出到文件/管道等,如下表 5-2所示。
| 类 | 功能 |
|---|---|
| ByteArrayOutputStream | 在内存中创建一个缓冲区,所有送往“流”的数据都要放在此缓冲区 |
| FileOutputStream | 将数据写入文件 |
| PipedOutputStream | 和PipedInputStream配合使用。实现管道化 |
| FilterOutputStream | 抽象类,主要是作为“装饰器”的接口类,实现其他的功能流 |
6、使用装饰器包装流
6.1、装饰器包装流
Java IO 流体系使用了装饰器模式来给哪些基础的输入/输出流添加额外的功能。这些额外的功能可能是:可以将流缓冲起来以提高性能、或者使流能够读写基本数据类型等。
这些通过装饰器模式添加功能的流类型都是从InputStream和OutputStream抽象类扩展而来的。可以再返回文章最开始说到I/O流体系的层次时,那几种图加深下印象。
例如,我们来说一说FilterInputStream、FilterOutputStream,其定义为:
public class FilterInputStream extends InputStream {}
public class FilterOutputStream extends OutputStream {}
而继承了FilterInputStream类,在其基础上再增加了额外的功能,例如PushbackInputStream、BufferedInputStream等,其定义如下:
public class BufferedInputStream extends FilterInputStream {}
public class PushbackInputStream extends FilterInputStream {}
就不一一列举了,剩下的一些继承了FilterInputStream、FilterOutputStream的流,如下表 6-1、表 6-2所示。
-
FilterInputStream类型:
表 6-1 类 功能 DataInputStream 和DataOutputStream搭配使用,使得流可以读取int char long等基本数据类型 BufferedInputStream 使用缓冲区,主要是提高性能 LineNumberInputStream 跟踪输入流中的行号,可以使用getLineNumber、setLineNumber(int) PushbackInputStream 使得流能弹出“一个字节的缓冲区”,可以将读到的最后一个字符回退 -
FilterOutStream类型:
表 6-2 类 功能 DataOutputStream 和DataInputStream搭配使用,使得流可以写入int char long等基本数据类型 PrintStream 用于产生格式化的输出 BufferedOutputStream 使用缓冲区,可以调用flush()清空缓冲区
大多数情况下,其实我们在使用流的时候都是输入流和输出流搭配使用的。目的就是为了读出和写入数据,因此要理解流的使用就是搭配起来或者使用功能流组合起来去读出或者写入数据。
6.2、FileInputStream类和FileOutputStream类
讲完装饰器包装流,然后我们来说一说文件输入流FileInputStream和文件输出流FileOutputStream。
如果要通过程序向文件进行内容输出和写入,我们可以使用FileInputStream类以及FileOutputStream类。
-
FileOutputStream类
可以通过这个类向文件写入数据,其构造方法为:
// 采用覆盖的形式创建文件输出流 public FileOutputStream(File file) throws FileNotFoundException; public FileOutputStream(String name) throws FileNotFoundException; // 采用覆盖或者追加的形式创建文件输出流 public FileOutputStream(File file, boolean append) throws FileNotFoundException; public FileOutputStream(String name, boolean append) throws FileNotFoundException; -
FileInputStream类
可以通过这个类读取文件中的内容,其构造方法为:
// 通过打开一个到实际文件的连接来创建一个FileInputStream对象,该文件通过文件系统中的File对象file指定 public FileInputStream(File file) throws FileNotFoundException; // 通过打开一个到实际文件的连接来创建一个FileInputStream对象,该文件通过文件系统中的路径名name指定 public FileInputStream(String name) throws FileNotFoundException;
范例:使用FileOutputStream向文件中写入数据。
补充:数据如何实现换行
- Windows:\r\n
- Linux:\n
- Mac:\r
package edu.blog;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileOutputStreamTestDemo {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "test"
+ File.separator + "test.txt"); // 文件输出路径
if (!file.getParentFile().exists()) { // 父目录不存在
file.getParentFile().mkdirs(); // 创建目录
}
FileOutputStream fileOutputStream = new FileOutputStream(file); // 子类实例化输出流对象
String string = "Hello World!" + "\r\n" + "Java!!!"; // 数据内容
fileOutputStream.write(string.getBytes()); // 字符串转化为字节数组
fileOutputStream.close(); // 关闭资源
}
}
/*
text.txt文件内容:
Hello World!
Java!!!
*/
范例:使用FileInputStream类读取文件内容。
package edu.blog.test11;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class FileInputStreamTestDemo {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "test"
+ File.separator + "test.txt"); // 文件输出路径
if (file.exists()) { // 如果文件存在
FileInputStream inputStream = new FileInputStream(file); // 实例化文件输入流
byte[] data = new byte[1024]; // 定义字节数组
int len; // 读取数据,将数据读取到数组中,并返回读取的字节数
while ((len = inputStream.read(data)) != -1) { // 文件为空
System.out.println(new String(data, 0, len)); // 字节转换为字符串
}
inputStream.close(); // 关闭输入流
}
}
}
/*
结果:
Hello World!
Java!!!
*/
7、字符流
使用InputStream和OutputStream进行字节数据读出和写入,这类数据适合于网络传输以及底层数据交换,但是在操作使需要进行字节数组的转换。而在程序中为了方便文字的处理,往往都会采用字符数据类型,所以在JDK 1.1开始就提供了字符流,Writer和Reader。
7.1、Reader 字符输入流
Reader是实现字符输入流的操作类,可以实现char数据类型的读取,其定义为:
public abstract class Reader implements Readable, Closeable {}
Reader类为抽象类,继承了Object类,实现了Readable接口与Closeable接口。
其中,Readable接口从JDK 1.5后提供,可以实现缓冲区的数据读取,其定义如下:
public interface Readable{
public int read(java.nio.CharBuffer cb) throws IOException;
}
Reader类提供了一些常用方法,如下所示。
//读取单个字符,无数据读取时返回-1
int read();
//读取多个字符,并返回读取个数
int read(char[] cbuf);
//跳过指定的字符个数后读取
long skip(long n);
//是否可以开始读取数据
boolean ready();
//关闭输入流
abstract void close();
7.2、Writer 字符输出流
Writer是实现字符输出流的操作类,其定义为:
public abstract class Writer implements Appendable, Closeable, Flushable {
同样,Writer类为抽象类,继承了Object类,实现了Readable接口、Closeable接口、Appendable接口。
其中,Appendable接口从JDK 1.5后提供,其定义如下:
public interface Appendable{
public Appendable append(CharSequence csq) throws IOException;
public Appendable append(CharSequence csq, int start, int end) throws IOException;
public Appendable append(char c) throws IOException;
}
注:《CharSequence接口》这篇文章也简单介绍了CharSequence接口。
Writer类提供了一些常用方法,如下所示。
//追加写入内容
Writer append(CharSequence csq);
//写入字符数组
void write(char[] cbuf);
//写入单个字符
void write(int c);
//写入字符串
void write(String str);
//刷新缓冲区
abstract void flush();
//关闭输出流
abstract void close();
注:字符流当然也有类似于字节流的装饰器实现方式。
使用装饰器包装流,给字符流添加额外的功能或者说行为,这些功能字符流类主要有:
- BufferedReader
- BufferedWriter
- PrintWriter
- LineNumberReader
- PushbackReader
同字节流类似,此处便不拓展了。
7.3、FileReader类和FileWriter类
同InputStream、OutputStream类一样,Reader、Writer都是抽象类,只能通过其子类进行实例化。当想通过Writer类和Reader类进行文件操作时,可以通过其子类FileReader、FileWriter进行实例化对象。
-
FileWriter类
构造方法:
// 根据给定的 File 对象构造一个 FileWriter 对象 public FileWriter(File file); // 根据给定的 File 对象构造一个 FileWriter 对象 public FileWriter(File file, boolean append); // 根据给定的文件名构造一个 FileWriter 对象 FileWriter(String fileName); // 根据给定的文件名以及指示是否附加写入数据的 boolean 值来构造 FileWriter 对象 FileWriter(String fileName, boolean append); -
FileReader类
构造方法:
// 在给定从中读取数据的 File 的情况下创建一个新 FileReader 对象 public FileReader(File file); // 在给定从中读取数据的文件名的情况下创建一个新 FileReader 对象 public FileReader(String fileName);
范例:使用FileWriter实现写入数据
package edu.blog.test11;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
public class FileWriterTestDemo {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "test"
+ File.separator + "file.txt"); // 文件输出路径
if (!file.getParentFile().exists()) { // 父路径不存在
file.getParentFile().mkdirs(); // 创建父路径
}
Writer fileWriter = new FileWriter(file); //实例化Writer实例化对象
fileWriter.write("Hello World!!!"); // 写入字符串
fileWriter.append("Java Java Java"); // 追加写入内容
fileWriter.close(); // 关闭输出流
}
}
范例:使用FileReader实现读取数据
package edu.blog.test11;
import java.io.*;
public class FileReaderTestDemo {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "test"
+ File.separator + "file.txt"); // 文件输出路径
if (file.exists()) { // 如果文件存在
Reader fileReader = new FileReader(file); // 实例化Reader对象
char[] data = new char[1024]; // 定义字符数组
int len; // 读取数据,将数据读取到数组中,并返回读取的字符数
while ((len = fileReader.read(data)) != -1) { // 文件为空
System.out.println(new String(data, 0, len)); // 字符转换成String输出
//System.out.println(data); // 字符可以直接输出
}
fileReader.close(); // 关闭输入流
}
}
}
/*
结果:
Hello World!!!Java Java Java
*/
由上面的程序便可发现字符流的特点之一就是可以直接进行字符数据的输出。
8、字节流和字符流
Java提供的两种流随JDK版本不断升级完善。虽然java.io包中提供字节流和字符流两类处理支持类,但是在数据传输(或者将数据保存在磁盘)时所操作的数据依然是字节数据,而字符数据都是通过缓冲区进行处理后得到的内容,如图 8-1所示。
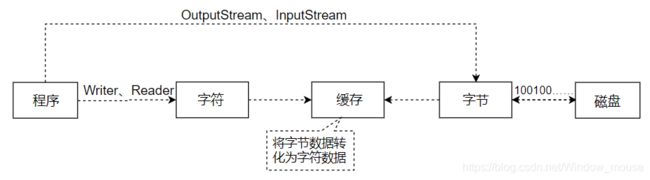
两类操作流最大的区别就在于字符流使用到了缓冲区(这样子更适合进行中文数据的操作),而字节流是直接进行数据处理操作。所以当使用字符流进行输出时就必须使用Flushable接口中提供的flush()方法强制性刷新缓冲区的内容,否则数据将不会输出。
范例:字符流输出并强制刷新缓冲区
package edu.blog.test11;
import java.io.*;
public class FileWriterTestDemo {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "test"
+ File.separator + "flushTest.txt"); // 文件输出路径
if (!file.getParentFile().exists()) { // 父路径不存在
file.getParentFile().mkdirs(); // 创建父路径
}
Writer fileWriter = new FileWriter(file); //实例化Writer对象
fileWriter.write("Hello World!!!"); // 写入字符串
fileWriter.append("flush flush flush"); // 追加写入内容
fileWriter.flush(); // 刷新缓冲区
Reader fileReader = new FileReader(file); // 实例化Reader对象
char[] data = new char[1024];
int len = 0;
while ((len = fileReader.read(data)) != -1) {
System.out.println(data);
}
fileWriter.close();
fileReader.close();
}
}
/*
结果:
Hello World!!!flush flush flush
*/
本程序在使用Writer类写入数据时使用了flush()方法,如果不使用此方法,那么此时将不会有任何内容保存到文件中。
这里,可能有人会说,那上面7.3的例子你不也没有使用flush()方法也可以输出吗???
其实是因为,字符流关闭时会自动清空缓冲区。
上面7.3例子确实没有调用flush()方法,但是调用的是close()方法进行输出流关闭,在关闭的时候会自动进行缓冲区的强制刷新,所以程序额内容才可以正常地保存到文件中。
总的来说,Reader是Java IO中所有Reader的基类。Reader与InputStream类似,不同点在于,Reader基于字符而非基于字节。
Writer是Java IO中所有Writer的基类。与Reader和InputStream的关系类似,Writer基于字符而非基于字节,Writer用于写入字符,OutputStream用于写入字节。
所以关于字节流InputStream、OutputStream以及字符流Reader、Writer可以对比着学习。
| 面向字节 | 面向字符 |
|---|---|
| InputStream | Reader |
| OutputStream | Writer |
| FileInputStream | FileReader |
| FileOutputStream | FileWriter |
| ByteArrayInputStream | CharArrayReader |
| ByteArrayOutputStream | CharArrayWriter |
| PipedInputStream | PipedReader |
| PipedOutputStream | PipedWriter |
| StringBufferInputStream(已弃用) | StringReader |
| 无对应类 | StringWriter |
9、转换流
字节流与字符流各有特点,Java不仅提供了两种流,还提供了两个“适配器” 流类型,它们可以将字节流转化成字节流,称为转换流。
转换流的设计目的是解决字节流与字符流之间操作类型的转换,java.io包中提供有两个转换流:OutputStreamWriter、InputStreamReader,其类的定义如下:
//OutputStreamWriter
public class OutputStreamWriter extends Writer {}
//InputStreamReader
public class InputStreamReader extends Reader {}
构造方法如下:
//OutputStreamWriter
public OutputStreamWriter (OutputStream out);
//InputStreamReader
public InputStreamReader (InputStream in);
其转换的形式如图 9-1所示。

我们可以发现:
- OutputStream是Writer的子类,并且可以通过构造方法接收OutputStream的类实例;
- InputStream是Reader的子类,并且可以通过构造方法接收InputStream的类实例。
即只需传入相应的字节流实例就可以利用对象的向上转型将字节流转为字符流。
范例:实现字节流与字符流的转换
package edu.blog.test11;
import java.io.*;
public class ConvertStreamTestDemo {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "test"
+ File.separator + "convert.txt"); // 文件输出路径
if (!file.getParentFile().exists()) { // 父路径不存在
file.getParentFile().mkdirs(); // 创建父路径
}
OutputStream outputStream = new FileOutputStream(file); //字节流
Writer writer = new OutputStreamWriter(outputStream); //字节流转字符流
//Writer writer = new OutputStreamWriter(new FileOutputStream(file));
writer.write("Hello World!!!" + "\r\n"); // 字符流输出
writer.write("Hello World!!!" + "\r\n");
writer.write("Hello World!!!");
writer.flush();
Reader reader = new InputStreamReader(new FileInputStream(file)); // 字节流转字符流
char[] data = new char[1024];
while ((reader.read(data)) != -1) {
System.out.println(data); // 字符可以直接输出
}
}
}
/*
结果:
Hello World!!!
Hello World!!!
Hello World!!!
*/
本程序利用转化流将字节输出流转化为字符输出流,这样就可以调用Writer类的write()方法直接输出字符串内容,同样的,将字节流转化为字符流,也可以读出字符,直接输出。
11、压缩流
Java IO类库是支持读写压缩格式的数据流的。我们可以把一个亦或是一批文件压缩成一个zip文档。这些压缩相关的流类是按字节处理的。先来看设计压缩解压缩的相关流类,大致如下所示。
| 压缩类 | 功能 |
|---|---|
| CheckedInputStream | getCheckSum()可以为任何InputStream产生校验和(不仅是解压缩) |
| CheckedOutputStream | getCheckSum()可以为任何OutputStream产生校验和(不仅是压缩) |
| DeflaterOutputStream | 压缩类的基类 |
| ZipOutputStream | 继承自DeflaterOutputStream,将数据压缩成Zip文件格式 |
| GZIPOutputStream | 继承自DeflaterOutputStream,将数据压缩成GZIP文件格式 |
| InflaterInputStream | 解压缩类的基类 |
| ZipInputStream | 继承自InflaterInputStream,解压缩Zip文件格式的数据 |
| GZIPInputStream | 继承自InflaterInputStream,解压缩GZIP文件格式的数据 |
其中,CheckedInputStream和CheckedOutputStream,他们一般都会和Zip压缩解压缩过程配合使用,主要是为了保证我么压缩和解压缩过程数据包的正确性,得到的是中间没有被篡改过的数据。
以CheckedInputStream为例,其构造方法为:
public CheckedInputStream(InputStream in, Checksum cksum){
super(in);
this.cksum = cksum;
}
Checksum是一个接口。
范例:压缩E:\test目录下的“*.txt”文件
import java.io.*;
import java.util.zip.Adler32;
import java.util.zip.CheckedOutputStream;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
//在FileUtil添加一个compressFiles()方法
public class FileUtil {
public FileUtil() {
}
public static void compressFiles(File[] files, String zipPath) throws IOException {
// 定义文件输出流,表明是要压缩成zip文件的
FileOutputStream f = new FileOutputStream(zipPath);
// 给输出流增加校验功能
CheckedOutputStream checkedOs = new CheckedOutputStream(f, new Adler32());
// 定义zip格式的输出流,这里要明白一直在使用装饰器模式在给流添加功能
// ZipOutputStream 也是从FilterOutputStream 继承下来的
ZipOutputStream zipOut = new ZipOutputStream(checkedOs);
// 增加缓冲功能,提高性能
BufferedOutputStream buffOut = new BufferedOutputStream(zipOut);
//对于压缩输出流我们可以设置个注释
zipOut.setComment("zip test");
// 下面就是从Files[] 数组中读入一批文件,然后写入zip包的过程
for (File file : files) {
// 建立读取文件的缓冲流,同样是装饰器模式使用BufferedReader
// 包装了FileReader
BufferedReader bfReadr = new BufferedReader(new FileReader(file));
// 一个文件对象在zip流中用一个ZipEntry表示,使用putNextEntry添加到zip流中
zipOut.putNextEntry(new ZipEntry(file.getName()));
int c;
while ((c = bfReadr.read()) != -1) {
buffOut.write(c);
}
// 注意这里要关闭
bfReadr.close();
buffOut.flush();
}
buffOut.close();
}
}
package edu.blog.test11;
import java.io.File;
import java.io.IOException;
public class ZipStreamTestDemo {
public static void main(String[] args) throws IOException {
String dir = "e:" + File.separator + "test";
String zipPath = dir + File.separator + "test.zip";
File file = new File(dir);
System.out.println(dir + "的所有文件:");
FileUtil.getAllFileName(file);
System.out.println("===================");
File[] files = file.listFiles();
if (files != null) {
FileUtil.compressFiles(files, zipPath);
}
System.out.println(dir + "的所有文件:");
FileUtil.getAllFileName(file);
}
}
/*
结果:
e:\test的所有文件:
convert.txt
file.txt
flushTest.txt
test.txt
===================
e:\test的所有文件:
convert.txt
file.txt
flushTest.txt
test.txt
test.zip
*/
由上程序执行结果发现,多了一个test.zip文件。
范例:解压test.zip到
//在FileUtil中添加unConpressZip()方法
public class FileUtil {
public static void unConpressZip(String zipPath, String destPath) throws IOException {
if (!destPath.endsWith(File.separator)) {
destPath = destPath + File.separator;
File file = new File(destPath);
if (!file.exists()) {
file.mkdirs();
}
}
// 新建文件输入流类,
FileInputStream fis = new FileInputStream(zipPath);
// 给输入流增加检验功能
CheckedInputStream checkedIns = new CheckedInputStream(fis, new Adler32());
// 新建zip输出流,因为读取的zip格式的文件嘛
ZipInputStream zipIn = new ZipInputStream(checkedIns);
// 增加缓冲流功能,提高性能
BufferedInputStream buffIn = new BufferedInputStream(zipIn);
// 从zip输入流中读入每个ZipEntry对象
ZipEntry zipEntry;
while ((zipEntry = zipIn.getNextEntry()) != null) {
System.out.println("解压中" + zipEntry);
// 将解压的文件写入到目标文件夹下
int size;
byte[] buffer = new byte[1024];
FileOutputStream fos = new FileOutputStream(destPath + zipEntry.getName());
BufferedOutputStream bos = new BufferedOutputStream(fos, buffer.length);
while ((size = buffIn.read(buffer, 0, buffer.length)) != -1) {
bos.write(buffer, 0, size);
}
bos.flush();
bos.close();
}
buffIn.close();
// 输出校验和
System.out.println("校验和:" + checkedIns.getChecksum().getValue());
}
}
package edu.blog.test11;
import java.io.File;
import java.io.IOException;
public class ZipStreamTestDemo02 {
public static void main(String[] args) throws IOException {
//将test.zip解压到这里
String file = "e:" + File.separator + "test" + File.separator + "here";
//test.zip所在的目录路径
String zipPath = "e:" + File.separator + "test" + File.separator + "test.zip";
FileUtil.unConpressZip(zipPath, file);
System.out.println("==========================");
File f = new File(file);
System.out.println(file + "的全部文件:");
FileUtil.getAllFileName(f);
}
}
/*
结果:
解压中convert.txt
解压中file.txt
解压中flushTest.txt
解压中test.txt
校验和:2047244883
==========================
e:\test\here的全部文件:
convert.txt
file.txt
flushTest.txt
test.txt
*/
12、字符编码
在计算机世界中,所有的显示文字都是按照其指定的数字编码进行保存的。在以后进行程序的开发过程中,会经常见到一些常见的编码。
- ISO8859-1:是一种国际通用单字节编码,最多只能表示0~255的字符范围,主要在英文传输中使用;
- GBK/GB2312:中文的国际编码,专门用来表示汉字,是双字节编码。GBK可以表示简体中文和繁体中文,而GB2312只能表示简体中文,GBK兼容GB2312;
- UNICODE:十六进制编码,可以准确地表示出任何语言文字,此编码不兼容ISO8859-1编码;
- UTF-8编码:由于UNICODE不支持ISO8859-1编码,而且占据空间多,英文字母也需要使用两个字节编码,使用UNICODE不便于传输和存储,因此产生了UTF编码。UTF编码兼容ISO8859-1编码,同时也可以用来表示所有的语言字符,不过UTF编码是不定长编码,每一个字符的长度从1~6个字符不等,一般在中文网页中使用的此编码,因为可以节省空间。
从JDK 1.9开始,Java中的默认编码为UTF-8。
13、内存操作类
内存操作流是以内存作为操作终端实现的I/O数据处理,与文件操作不同的地方在于,内部操作流不会进行磁盘数据操作。
Java中提供以下两类内存操作流:
- 字节内存操作流:ByteArrayOutputStream、ByteArrayInputStream;
- 字符内存操作流:CharArrayWriter、CharArrayReader。
ByteArrayInputStream、CharArrayReader:将内容写入到内存中,
ByteArrayOutputStream、CharArrayWriter:将内存中数据输出。
操作的流程图如 图13-1所示。

-
ByteArrayInputStream:是InputStream子类
public class ByteArrayInputStream extends InputStream;构造方法:
//创建一个 ByteArrayInputStream,使用 buf 作为其缓冲区数组。 public ByteArrayInputStream(byte[] buf); public ByteArrayInputStream(byte[] buf, int offset, int length);接收一个byte数组,实际上内存的输入就是在构造方法上将数据传递到内存之中。
-
ByteArrayOutputStream:是OutputStream子类
输出就是从内存中写出数据。
public class ByteArrayOutputStream extends OutputStream;构造方法:
//创建一个新的 byte 数组输出流 public ByteArrayOutputStream(); //创建一个新的 byte 数组输出流,它具有指定大小的缓冲区容量(以字节为单位) public ByteArrayOutputStream(int size);主要方法:
//将指定的字节写入此 byte 数组输出流 public void write(int b);
范例:利用内存流实现小写字母转大写字母的操作
注意:跟文件读取不一样,不要设置文件路径。
package edu.blog.test12;
import java.io.*;
public class MemoryStreamTestDemo {
public static void main(String[] args) throws IOException {
String str = "hello world"; // 小写字母
InputStream inputStream = new ByteArrayInputStream(str.getBytes()); // 数据保存在内存输入中
OutputStream outputStream = new ByteArrayOutputStream(); // 读取内存中的数据
int data = 0;
while ((data = inputStream.read()) != -1) { // 每次读取一个字节
outputStream.write(Character.toUpperCase(data)); // 处理并保存数据
}
System.out.println(outputStream); // 转换后内容
inputStream.close(); // 关闭流
outputStream.close();
}
}
/*
结果:
HELLO WORLD
*/
本程序利用程序作为操作终端,定义的字符串作为输入流的内容,并且提供循环获取每一个字节数据,利用Character类提供的toUpperCase()将小写字母转为大写字母后保存在了输出流中。
实际上以上操作很好体现了对象的多态。通过实例化其子类不同,完成的功能也不同,也就相当于输出的位置不同,如果是输出文件,则使用FileXxxx类。如果是内存,则使用ByteArrayXxx。
Tips:ByteArrayOutputStream类的一个重要方法。
ByteArrayOutputStream是内存的字节输出流操作类,所有的内容都会暂时保存此类对象中,在此类中提供有一个获取保存全部数据的方法:public byte[] toByteArray(),可以将全部的数据转为字节取出。
14、管道流
Java是一门多线程编程语言,可以通过多个线程提高程序的执行性能,所以在进行I/O设计时也提供了不同线程间的管理通信流(管道流)。管道流的作用是可以进行两个线程间的通信,可以分为字节流管道流和字符管道流。
- 字节管道流:PipedOutputStream 和 PipedInputStream;
- 字符管道流:PipedWriter 和 PipedReader。
也可按输入和输出分为:管道输出流和管道输入流。
- 管道输出流:PipedOutputStream、PipedWriter 是写入者/生产者/发送者;
- 管道输入流:PipedInputStream、PipedReader 是读取者/消费者/接收者。
//PipedOutputStream管道连接
public void connect(PipedInputStream snk) throws IOException;
//PipedWriter管道连接
public void connect(PipedReader snk) throws IOException;
注:字符管道流原理跟字节管道流一样,只不过底层一个是 byte 数组存储 一个是 char 数组存储的。
所以我们来分析一下字节管道流,Java的管道输入与输出实际上使用的是一个循环缓冲数来实现的。输入流PipedInputStream从这个循环缓冲数组中读数据,输出流PipedOutputStream往这个循环缓冲数组中写入数据。当这个缓冲数组已满的时候,输出流PipedOutputStream所在的线程将阻塞;当这个缓冲数组为空的时候,输入流PipedInputStream所在的线程将阻塞。
范例:使用字节管道流实现线程通信
package edu.blog.test13;
import java.io.IOException;
import java.io.PipedOutputStream;
// 数据发送线程
public class SendThread implements Runnable{
private PipedOutputStream pipedOutputStream; // 管道输出流
// 构造器
public SendThread(PipedOutputStream pipedOutputStream) {
this.pipedOutputStream = pipedOutputStream;
}
public SendThread() {
}
// get、set方法
public PipedOutputStream getPipedOutputStream() {
return pipedOutputStream;
}
public void setPipedOutputStream(PipedOutputStream pipedOutputStream) {
this.pipedOutputStream = pipedOutputStream;
}
@Override
public void run() {
try {
// 数据发送
this.pipedOutputStream.write("I am SendThread-run\r\n".getBytes());
// 关闭输出流
this.pipedOutputStream.close();
} catch (IOException e){
e.printStackTrace();
}
}
}
package edu.blog.test13;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.PipedInputStream;
// 数据接收线程
public class ReceiveThread implements Runnable {
private PipedInputStream pipedInputStream; // 管道输入流
// 构造器
public ReceiveThread() {
}
public ReceiveThread(PipedInputStream pipedInputStream) {
this.pipedInputStream = pipedInputStream;
}
// get、set方法
public PipedInputStream getPipedInputStream() {
return pipedInputStream;
}
public void setPipedInputStream(PipedInputStream pipedInputStream) {
this.pipedInputStream = pipedInputStream;
}
@Override
public void run() {
// 开启读取缓冲区
byte[] data = new byte[1024];
// 读取长度
int len = 0;
// 通过内存流保存内容
ByteArrayOutputStream baos = new ByteArrayOutputStream();
try {
// 部分数据读取
while ((len = this.pipedInputStream.read(data)) != -1) {
// 数据保存到内存流
baos.write(data, 0, len);
}
// 输出数据
System.out.println(new String(baos.toByteArray()));
// 关闭内存流
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
// 关闭输入流
this.pipedInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
package edu.blog.test13;
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
public class PipedStreamTestDemo {
public static void main(String[] args) throws IOException {
// 发送线程
SendThread sendThread = new SendThread(new PipedOutputStream());
// 接收线程
ReceiveThread receiveThread = new ReceiveThread(new PipedInputStream());
// 管道连接
sendThread.getPipedOutputStream().connect(receiveThread.getPipedInputStream());
// 启动线程
new Thread(sendThread, "消息发送线程").start();
new Thread(receiveThread, "消息接收线程").start();
}
}
/*
结果:
I am SendThread-run
*/
本程序定了两个线程类对象,发送线程通过PipedOutputStream类中的connect()方法与接收线程的PipedInputStream类进行连接,当发送线程通过管道输出流发送数据时,接收线程就可以通过线程输入流接受内容。
注:在使用管道流之前,需要注意以下要点:
- 管道流仅用于多个线程之间传递信息,若用在同一个线程中可能会造成死锁;
- 管道流的输入输出是成对的,一个输出流只能对应一个输入流,使用构造函数或者connect函数进行连接;
- 一对管道流包含一个缓冲区,其默认值为1024个字节,若要改变缓冲区大小,可以使用带有参数的构造函数;
- 管道的读写操作是互相阻塞的,当缓冲区为空时,读操作阻塞;当缓冲区满时,写操作阻塞;
- 管道依附于线程,因此若线程结束,则虽然管道流对象还在,仍然会报错“read dead end”;
- 管道流的读取方法与普通流不同,只有输出流正确close时,输出流才能读到-1值。
15、打印流
在java.io包中对于数据的疏忽操作可以通过OutputStream类或者Writer类完成,但是这两个输出类本身都存在一定的局限性。例如,OutputStream只允许输出字节数据,Writer只允许输出字符数据和字符串数据。而在现实开发过程中,会有多种数据类型的数据需要输出(如,整型、浮点型、字符型、引用类型),因而为了简化输出的操作提供了两个打印操作类:字节打印流(PrintStream)、字符打印流(PrintWriter)。
打印流是输出信息最方便的类,注意包含字节打印流PrintStream和字符打印流:PrintWriter。打印流提供了非常方便的打印功能,
可以打印任何类型的数据信息,例如:小数,整数,字符串。
PrintStream类与PrintWriter类中定义的方法形式非常相似,接下来就来说说PrintStream类,其常用方法如下:
//构造,通过一个File对象实例化PrintStream类
public PrintStream(File file) throws FileNotFoundException;
//构造,接收OutputStream对象,实例化PrintStream类
public PrintStream(OutputStream out);
//根据指定的Locale进行格式输出
public PrintStream printf(Locale l, String format, Object... args);
//根据本地环境格式化输出
public PrintStream printf(String format, Object... args);
//此方法被重载很多次,输出任意数据
public void print(数据类型 变量);
//此方法被重载很多次,输出任意格式后换行
public void println(数据类型 变量);
//注:数据类型可以为:boolean、char、char[]、double、float、int等
**打印流好处:**通过定义的构造方法可以发现,有一个构造方法可以直接接收OutputStream类的实例,与OutputStream相比起来,PrintStream可以更方便的输出数据,即相当于把OutputStream类重新包装了一下,使之输出更方便。
范例:使用printStream输出信息。
package edu.blog.test14;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
public class PrintStreamTestDemo01 {
public static void main(String[] args) throws FileNotFoundException {
PrintStream ps = null; // 声明打印流对象
// 如果现在是使用FileOuputStream实例化,意味着所有的输出是向文件之中
ps = new PrintStream(new FileOutputStream(new File("e:" + File.separator + "test.txt")));
ps.print("hello ");
ps.println("world!!!");
ps.print("1 + 1 = " + 2);
ps.close();
}
}
打开文件管理器就会发现多了一个test.txt文件,且文件内容就为:
hello world!!!
1 + 1 = 2
从JDK 1.5开始,打印流支持了格式化输出的操作,可以利用printf()方法设置数据的占位符:
- 字符串:%s
- 整型:%d
- 浮点数:%f
- 字符:%c
范例:格式化输出
package edu.blog.test14;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
public class PrintStreamTestDemo02 {
public static void main(String[] args) throws FileNotFoundException {
PrintStream ps = null; // 声明打印流对象
// 如果现在是使用FileOuputStream实例化,意味着所有的输出是向文件之中
ps = new PrintStream(new FileOutputStream(new File("e:" + File.separator + "test.txt")));
String name = "李华"; // 定义字符串
int age = 30; // 定义整数
float score = 990.356f; // 定义小数
char sex = 'M'; // 定义字符
ps.printf("姓名:%s;年龄:%d;成绩:%f;性别:%c", name, age, score, sex);
ps.close();
}
}
再次打开test.txt文件,文件的内容变为:
姓名:李华;年龄:30;成绩:990.356018;性别:M
16、RandomAccessFile
InputStream和Reader可以实现文件的批量的读取,但是对于较大文件时的处理逻辑就会非常复杂。RandomAccessFile类可以实现文件数据的随机读取,即通过对文件内部读取位置的自由定义,以实现部分数据的读取操作,所以在使用此类操作时必须保证写入数据时数据格式与长度统一。
RandomAccessFile类的常用方法如下所示。
//构造,接收File类的对象,指定操作路径,但是在设置时需要设置模式,r:只读;w:只写;rw:读/写
public RandomAccessFile(File file, String mode) throws FileNotFoundException;
//构造,不再使用File类对象表示文件,而是直接输入一个固定的文件路径
public RandomAccessFile(String name, String mode) throws FileNotFoundException;
//关闭操作
public void close();
//将内容读取到一个byte数组中
public int read();
//读取一个字节
public final byte readByte();
//从文件中读取整性数据
public final byte readInt();
//设置读指针的位置
public void seek(long pos);
//将一个字符串写入到文件中,按字节的方法处理
public final void writeBytes(String s);
//将一个int型数据写入文件
public final void writeInt();
//指针跳过了多少个字节
public int skipBytes(int n);
范例:使用RandomAccessFile写入数据
package edu.blog.test15;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomAccseeFileTestDemo01 {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "test.txt");
RandomAccessFile raf = new RandomAccessFile(file, "rw"); // 读写模式
//要保存的姓名数据,为了保证长度一致,使用空格填充
String[] names = new String[]{
"zhangsan",
"lisi ",
"wangwu "
};
int[] ages = new int[]{30, 20, 16};
int len = names.length;
for (int i = 0; i < len; i++) {
raf.write(names[i].getBytes()); // 写入字符串
raf.writeInt(ages[i]); // 写入整型
}
raf.close();
}
}
RandomAccessFile类具备数据的写入和读取能力,本程序为了方便地操做使用了rw读/写模式,随后利用循环将内容写入文件中。
范例:使用RandomAccessFile读取数据
package edu.blog.test15;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomAccseeFileTestDemo02 {
public static void main(String[] args) throws IOException {
File file = new File("e:" + File.separator + "test.txt");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
//读取 王五
raf.skipBytes(24);
byte[] data = new byte[8];
int len = raf.read(data);
System.out.println("姓名:" + new String(data, 0, len).trim() +
"、年龄:" + raf.readInt());
raf.close();
}
}
/*
结果:
姓名:wangwu、年龄:16
*/
不程序使用了RandomAccessFile依据保存的字节长度实现了所需要的数据读取操作,此类读取的机制由于不会讲所有的数据全部读取出来,所以非常适合于读取数据量较大的文件内容。
17、System类中I/O流
相信每一个初学编程的人,应该都是打印出“Hello World”啊哈哈哈,现在再回头看一看那个语句:
System.out.println("Hello World");
那么我们就来说一说标准的输出流/输出流。
在标准的IO模型中,Java定义了3个与I/O操作有关的常量,如下:
//常量;描述:错误输出
public static final PrintStream err;
//常量;描述:系统输出
public static final PrintStream out;
//常量;描述:系统输入
public static final InputStream in;
从上可以发现,System类的2个变量都是PrintStream类的实例。
范例:实现信息输出
package edu.blog.test16;
public class SystemIOTestDemo01 {
public static void main(String[] args) {
try {
//非数字组成转化会出现异常
Integer.parseInt("Java");
} catch (NumberFormatException e) {
System.out.println(e); //信息输出
System.err.println(e); //错误输出
}
}
}
/*
结果:
java.lang.NumberFormatException: For input string: "Java"
java.lang.NumberFormatException: For input string: "Java"
*/
本程序由于将字符串"Java"强制转为了int型数据,所以发生了异常,而此时异常处理中分别使用了System.out和System.err输出了异常类对象,但是输出的结果相同,所以这两种并没有上面区别。但是Java本身的规则是这样子解释的:System.err输出的是不希望用户看见的错误;而System.out输出的是希望用户看见的错误。
Tips:IDE中System.err和Syetem.out的区别
如果只是通过命令行的方式来执行,两者输出的内容是完全相同的。但是如果在开发工具上执行,两者的输出会使用不同颜色表示。
范例:使用System.in实现键盘数据输入
package edu.blog.test16;
import java.io.IOException;
import java.io.InputStream;
public class SystemIOTestDemo02 {
public static void main(String[] args) throws IOException {
InputStream inputStream = System.in;
System.out.print("请输入信息:");
byte[] data = new byte[1024];
int len = inputStream.read(data);
System.out.println("输入的内容为:" + new String(data, 0, len));
}
}
/*
结果:
请输入信息:Hello World
输入的内容为:Hello World
*/
本程序通过System.in实现键盘输入数据的处理,同时将输入的数据内容进行回显,不过此方法实现的键盘输入操作存在以下缺陷
- 数据的接收需要通过一个字节数组完成,如果输入的数据超过了数组的长度,则有可能会出现数据丢失问题;
- System.in为输入字节流,所以对中文的处理支持不够友好。
18、Scanner输入流
在JDK 1.5后提供了专门的输入数据类,此类不仅可以完成之前的输入数据操作,也可以方便地对输入数据进行验证。此类存放在java.util包中,常用方法如下:
//构造,从文件中接受内容
public Scanner(File source) throws FileNotFoundException;
//构造,从指定的字节输入流中接受内容
public Scanner(InputStream source);
//判断输入的数据是否符合指定的正则标准
public boolean hasNext(Pattern pattern);
//判断数据内容是否为指定类型,如hasNextInt()
public boolean hasNextXxx();
//接收内容
public String next();
//接收内容,进行正则验证
public String next(Pattern pattern);
//接收指定类型的数据,如nextInt()
public 数据类型 nextXxx();
//接收小数
public float nextFloat();
//设置读取的分隔符
public Scanner useDelimiter(String pattern);
然后我们再来看看Scanner类的定义结构:
public final class Scanner implements Iterator<String>, Closeable {}
范例:使用Scanner实现键盘数据输入
package edu.blog.test17;
import java.util.Scanner;
public class ScannerTestDemo01 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in); // 创建输入流对象
System.out.print("请输入年龄:"); // 提示信息
if (scanner.hasNextInt()) { // 满足格式可以输入
int age = scanner.nextInt(); // 直接获取数字
System.out.println("年龄:" + age); // 数据回显
} else {
System.out.println("输入的内容不是数字"); // 错误信息提示
}
scanner.close(); // 关闭输入流
}
}
/*
结果:
请输入年龄:13
年龄:13
*/
范例:读取文件内容
package edu.blog.test17;
import java.io.File;
import java.io.IOException;
import java.util.Scanner;
public class ScannerTestDemo02 {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(new File("e:"
+ File.separator + "test.txt")); // 文件路径
scanner.useDelimiter("\n"); // 设置读取分隔符
while (scanner.hasNext()) { // 是否有数据
System.out.println(scanner.next()); // 获取数据
}
scanner.close(); // 关闭输入流
}
}
/*
结果:
Java
Hello World
30
24
*/
Scanner默认将空字符作为分隔符,在本程序中所读取的test.txt文件中的内容都是以换行作为分隔符的,所以为了进行正常的数据读取,就必须利用useDelimiter()方法指定数据读取的分隔符。
19、对象序列化
序列化就是将对象转成字节序列的过程,反序列化就是将字节序列重组成对象的过程。
为什么要有对象序列化机制呢?
程序中的对象,其实是存在有内存中,当我们JVM关闭时,无论如何它都不会继续存在了。那有没有一种机制能让对象具有“持久性”呢?序列化机制提供了一种方法,你可以将对象序列化的字节流输入到文件保存在磁盘上。
序列化机制的另外一种意义便是我们可以通过网络传输对象了,Java中的远程方法调用(RMI),底层就需要序列化机制的保证。
在Java中怎么实现序列化和反序列化
首先要序列化的对象必须实现一个Serializable接口(这是一个标识接口,不包括任何方法),其次需要是用两个对象流类:ObjectInputStream和ObjectOutputStream。主要使用ObjectInputStream对象的readObject方法读入对象、ObjectOutputStream的writeObject方法写入对象到流中。
我们在前面的文章序列化&反序列化已经比较详细地讲述了序列化和反序列化,这里就不再重复讲了。
20、参考资料
参考的资料有:
- JDK 1.8 - API中文帮助文档
- 《Java编程实现》
- 《Java从入门到项目实践》
- 大佬的博客(太多了,实在是没记住)
关于Java I/O流体系的知识我自己感觉大概就是这么多,这其实也是我的个人笔记,为了加深自己对I/O流的理解。
这篇文章大概有1.2w个字,足足写了一个星期,但是其实更多的是一些例子,并没有深入讲源码(主要是我能力也没达到那个地步哈哈哈)。
注:此文章为个人学习笔记,如有错误,敬请指正。
另外,转载请注明出处,谢谢。