Hadoop分布式配置小白篇(附加各阶段问题解决方式)
看的黑马的课,记录一下配置步骤
目录
1.VMware安装:
方法1:
方法2:
2.创建虚拟机
1.ISO镜像文件获取(CentOS):
2.创建(简略步骤)
3.克隆虚拟机(克隆伪分布式需要的三个节点)
创建node1
修改物理配置
网络配置
3.关闭防火墙、SELinux(三台机器都要执行)
4.主机名、ip修改,ssh免密登录
1.修改主机名
2.修改ip
ping 检查!
3.ssh免密
4.创建hadoop用户
5.jdk、hadoop环境部署
1.jdk环境配置
2.Hadoop环境配置
1.上传、解压到/export/server,配置软链接
2.配置4份文件
3.设置环境变量
4.给hadoop授权
5.启动集群、查看WEB UI
5.出现的问题
1.finalshell连接不上
2.finalshell连接很卡
方法1
方法2
1.VMware安装:
方法1:
按照微信公众号软件管家配置,里面有详细步骤且无试用期(推荐)
方法2:
官网:Windows 虚拟机 | Workstation Pro | VMware | CN
记得选择合适的安装路径即可
2.创建虚拟机
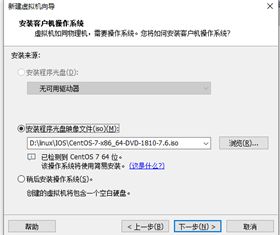
1.ISO镜像文件获取(CentOS):
链接:https://pan.baidu.com/s/1mykapkmv7fW3OdWJpNRODw?pwd=1234
提取码:1234
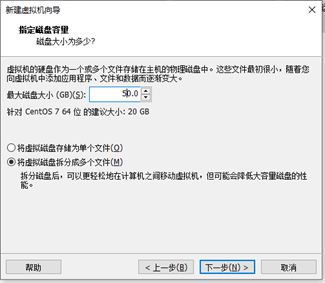
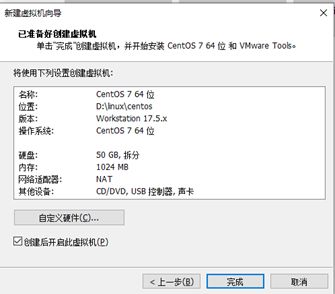
2.创建(简略步骤)

选择镜像存放地址

3.克隆虚拟机(克隆伪分布式需要的三个节点)
创建node1
右击上文创建的虚拟机,进行克隆
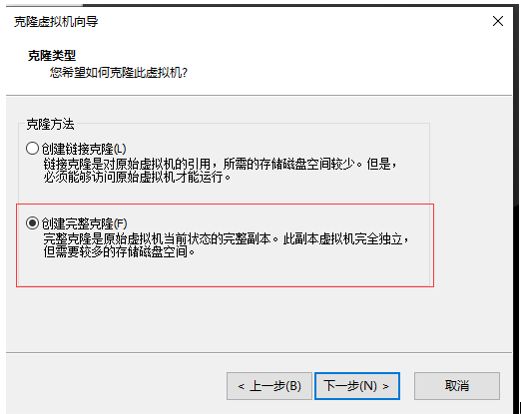

同理创建node2、node3(改名字、选择创建自己的路径)
修改物理配置
按下图进行配置、node1有主节点、从节点、主节点辅助、所以需要的配置更高
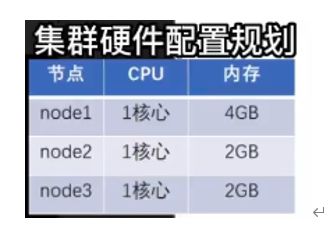
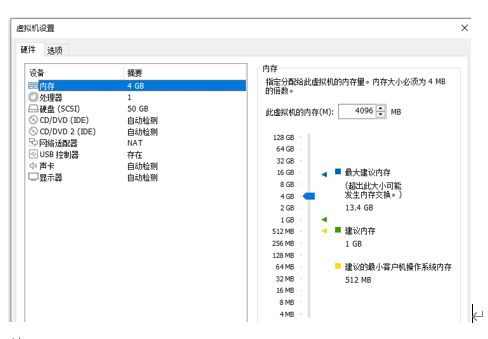
同理对node2、node3进行配置(2G)
网络配置
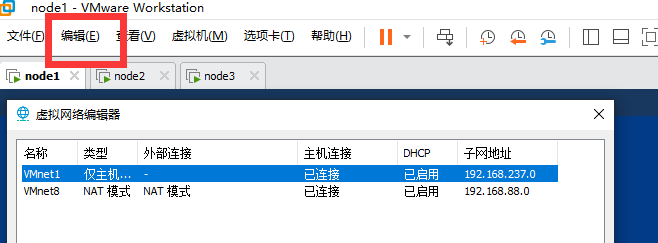
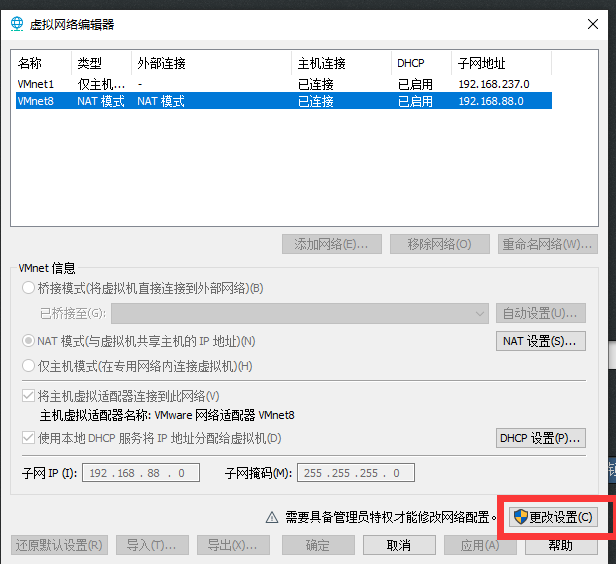

点击NAT设置

进入windows该页面
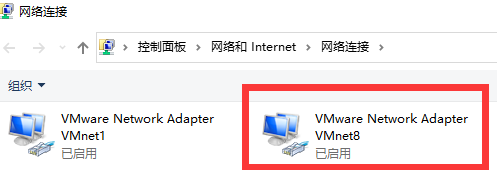
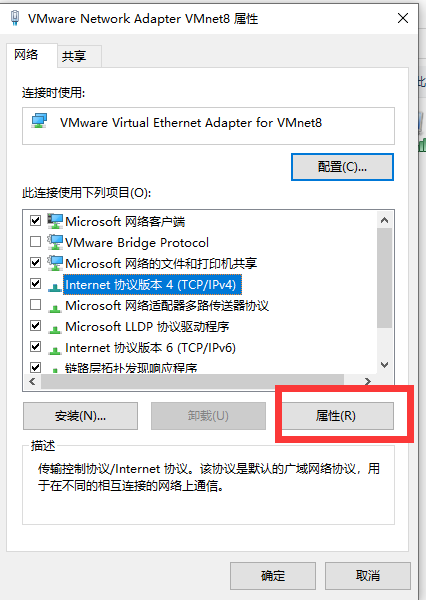

打开三台虚拟机、点击否
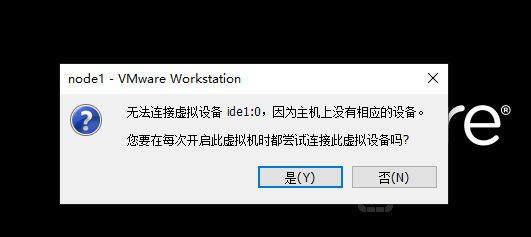
3.关闭防火墙、SELinux(三台机器都要执行)
关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
关闭SELinux:
vim /etc/sysconfig/selinux
将#SELINUX=enforcing改为
SELINUX=disabled
重启虚拟机即可
4.主机名、ip修改,ssh免密登录
1.修改主机名
#node1进行以下操作
su
hostnamectl set-hostname node1
#node2进行以下操作
su
hostnamectl set-hostname node2
#node3进行以下操作
su
hostnamectl set-hostname node3
2.修改ip
#对三个节点都进行以下操作
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR="192.168.88.201" #node2为202,node3为203
GATEWAY="192.168.88.2"
NETMASK="255.255.255.8"
DNS1="192.168.88.2"
#重启网卡
service network restart
Vim /etc/hosts
#在最后添加
192.168.88.201 node1
192.168.88.202 node2
192.168.88.203 node3
ping 检查!
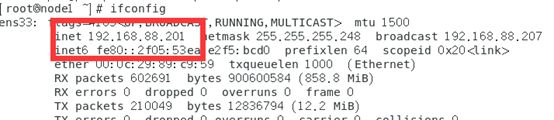
对网络进行,在node1中输入
ifconfig
看是否正确
在windows中看是否能ping通

在windows中输入
ipconfig

在linux中看是否能ping通

3.ssh免密
后续在多个服务器之间传文件更加方便
三个节点均进行以下操作:
#切换到root用户
su
ssh-keygen -t rsa -b 4096(一路回车)
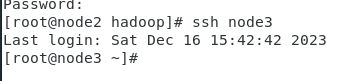
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
vi ~/.ssh/known_hosts 可以看到

实现免密登录
4.创建hadoop用户
当前用户root,拥有root权限,后面进行操作时不安全

每个节点执行:
useradd hadoop
passwd hadoop
su hadoop
ssh-keygen -t rsa -b 4096(一路回车)
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
5.jdk、hadoop环境部署
因为Hadoop是基于Java开发的,所以在安装Hadoop之前要先安装Java
1.jdk环境配置
#三台机器创建文件夹
mkdir -p /export/server
使用Finalshell或者Xshell将jdk传到三个主机的/export/server下
对三个主机进行以下操作
#转到root用户下
su
cd /export/server
#解压
tar -zxvf jdk-8u351-linux-x64.tar.gz
#创建软连接(名字太长不好操作、相当于创建一个他的快捷方式)
ln -s /export/server/jdk1.8.0_351 /export/server/jdk
#编辑/etc/profile文件
vim /etc/profile
#加入
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
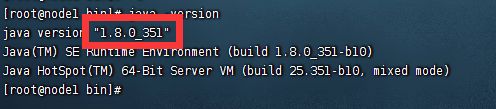
#查看java版本
java -version
改版本为系统自带的,删除系统自带的java程序
rm -f /usr/bin/java

软链接自己安装的java程序
ln -s /export/server/jdk/bin/java /usr/bin/java
java -version
2.Hadoop环境配置

在node1节点下以root权限进行操作
1.上传、解压到/export/server,配置软链接
上传到/export/server
#解压
tar -zxvf hadoop-3.3.0.tar.gz
#创建软连接(名字太长不好操作、相当于创建一个他的快捷方式)
ln -s /export/server/hadoop-3.3.0 /export/server/hadoop
2.配置4份文件

cd /export/server/hadoop//etc/hadoop
修改workers文件
vim workers
# 删除localhost,填入如下内容
node1
node2
node3修改hadoop-env.sh文件
vim hadoop-env.sh
# 添加内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
修改core-site.xml文件
vim core-site.xml
# 在最后添加内容
fs.defaultFS
hdfs://node1:8020
io.file.buffer.size
131072
修改hdfs-site.xml文件
vim hdfs-site.xml
# 在最后添加内容
dfs.datanode.data.dir.perm
700
dfs.namenode.name.dir
/data/nn
dfs.namenode.hosts
node1,node2,node3
dfs.blocksize
268435456
dfs.namenode.handler.count
100
dfs.datanode.data.dir
/data/dn
注意(node1及作为主节点NameNode又作为从节点DataNode,node2、node3为从节点):
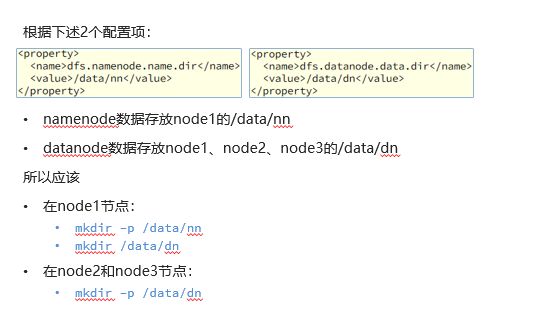
3.分发到node2、 node3,并设置环境变量
此时node1节点中的Hadoop中的文件配置好了,如果同样的对node2、node3进行同样的操作过于麻烦,可以直接将node1中配置好的文件分发到node2、node3中
cd /export/server
scp -r hadoop-3.3.0 node2:`pwd`/
scp -r hadoop-3.3.0 node3:`pwd`/
# 在node2下建立软连接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
# 在node2下建立软连接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop设置环境变量
对三个节点分别进行以下操作
# 在/etc/profile文件底部追加如下内容
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
#查看hadoop版本
hadoop version4.给hadoop授权
当前文件夹所有权为root、使用时hadoop用户无法进行操作

# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export

5.启动集群、查看WEB UI
# 以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
# 一键启动hdfs集群
start-dfs.sh
在浏览器输入:http://node1:9870
5.出现的问题
1.finalshell连接不上
检查步骤4中的ping检查!部分
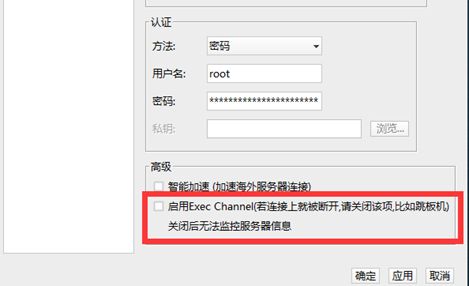
2.finalshell连接很卡
方法1
linux中输入
systemctl restart systemd-logind
方法2
ssh连接时