模式串匹配和字符串哈希
目录
一、字符串暴力匹配
二、字符串哈希解决匹配问题
不使用哈希的递归版本
使用哈希的版本
不太懂哈希表的可以看我上一篇文章。
哈希表及其基础(java详解)-CSDN博客
一、字符串暴力匹配
public class SubstringMatch {
//构造函数设置成私有的,不会被创建对象
private SubstringMatch(){}
//暴力匹配 源字符串s和目标字符串t
//在s中寻找t,返回匹配到的第一个索引i,没找到就返回-1
public static int bruteforce(String s, String t) {
if (s.length() < t.length()) {
return -1;
}
//s[i, i + t.length - 1] == t ?
for (int i = 0; i + t.length() - 1 < s.length(); i++) {
int j = 0;
for (; j < t.length(); j++) {
if (s.charAt(i + j) != t.charAt(j))
break;
if (j == t.length() - 1) return i; // 修改这里
}
}
return -1;
}
public static void main(String[]args){
String s1 = "hello, yujing.";
String t1 = "yujing";
System.out.println(SubstringMatch.bruteforce(s1, t1));
}
}
二、字符串哈希解决匹配问题
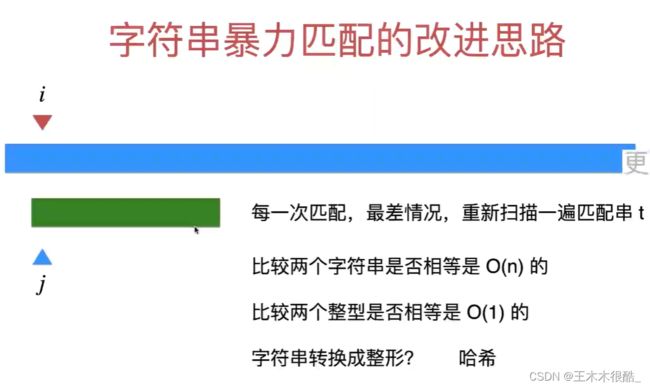

扔掉匹配问题不看,看字符串转哈希思想的一个应用。
1147. 段式回文 - 力扣(LeetCode)
你会得到一个字符串
text。你应该把它分成k个子字符串(subtext1, subtext2,…, subtextk),要求满足:
subtexti是 非空 字符串- 所有子字符串的连接等于
text( 即subtext1 + subtext2 + ... + subtextk == text)- 对于所有 i 的有效值( 即
1 <= i <= k) ,subtexti == subtextk - i + 1均成立返回
k可能最大值。
示例 1:
输入:text = "ghiabcdefhelloadamhelloabcdefghi" 输出:7 解释:我们可以把字符串拆分成 "(ghi)(abcdef)(hello)(adam)(hello)(abcdef)(ghi)"。示例 2:
输入:text = "merchant" 输出:1 解释:我们可以把字符串拆分成 "(merchant)"。示例 3:
输入:text = "antaprezatepzapreanta" 输出:11 解释:我们可以把字符串拆分成 "(a)(nt)(a)(pre)(za)(tep)(za)(pre)(a)(nt)(a)"。提示:
1 <= text.length <= 1000text仅由小写英文字符组成
根据题目,我们要尽可能多的把字符串划分成几段,第一段和最后一段字符串相等,第二段和倒数第二段字符串相等,如果分成奇数个那么最中间的一段不需要和任何段相等。
不使用哈希的递归版本
//不使用哈希的递归版本 O(N^2)
public class Solution {
public int longestDecomposition(String text){
return solve(text, 0, text.length() - 1);
}
//s[left, right]
//left从左往右走 right从右往左走
private int solve(String s, int left, int right){
if(left > right) return 0;
for(int i = left, j = right; i < j; i++, j--){
//s[left, i] == s[j, right]
if(equal(s, left, i, j, right))
return 2 + solve(s, i + 1, j - 1);
}
return 1;
}
//s[l1, r1] == s[l2, r2] ?
private boolean equal(String s, int l1, int r1, int l2, int r2){
for(int i = l1, j = l2; i <= r1 && j <= r2; i++, j++)
if(s.charAt(i) != s.charAt(j)) return false;
return true;
}
}
使用哈希的版本
基于哈希的思路代码整体框架和上一个不使用哈希的递归版本是一样的,区别在于给两个字符串判等的时候我们比较的是两个子串对应的哈希值,对于这两个哈希值我们不是每一次都计算一遍,不然整体还会是一个O(N^2)级别的算法。我们做的是要根据前一次计算的哈希值只通过一次计算来推导出当我们拿到新的左边的第i个字符和右边的第j个字符之后,这个新的哈希值是谁。即下图的方式。

//使用哈希 O(N)
public class Solution {
private long MOD = (long)(1e9 + 7);//即十亿零七
private long[] pow26;
public int longestDecomposition(String text){
//预处理操作,提前把26的各个次方数值存进去,用到哪个就直接提哪个
//pow26[i] = 26^i
//虽然这样做多用了空间,但在算法里时间比空间值钱,我们愿意用时间换空间
pow26 = new long[text.length()];
pow26[0] = 1;
for(int i = 1; i < text.length(); i++){
//求余是为了防止整型溢出
pow26[i] = pow26[i - 1] * 26 % MOD;
}
return solve(text, 0, text.length() - 1);
}
//s[left, right]
//left从左往右走 right从右往左走
private int solve(String s, int left, int right){
if(left > right) return 0;
long prehash = 0, posthash = 0;
for(int i = left, j = right; i < j; i++, j--){
//(s.charAt(i) - 'a')代表a对应0,b对应1,c对应2....
prehash = (prehash * 26 + (s.charAt(i) - 'a')) % MOD;
posthash = ((s.charAt(j) - 'a') * pow26[right - j] + posthash) % MOD;
//s[left, i] == s[j, right]
if(prehash == posthash && equal(s, left, i, j, right))
return 2 + solve(s, i + 1, j - 1);
}
return 1;
}
//s[l1, r1] == s[l2, r2] ?
private boolean equal(String s, int l1, int r1, int l2, int r2){
for(int i = l1, j = l2; i <= r1 && j <= r2; i++, j++)
if(s.charAt(i) != s.charAt(j)) return false;
return true;
}
}
在提交到leetcode后我们发现哈希的解法却比递归的慢,因为leetcode的测试样例的数据量不够大,反而显得哈希方法比较慢,如果数据量够大,哈希法的性能就能体现出来了。