Spring Boot学习:ShardingSphere-JDBC数据分片配置
目录
-
- 前言
- 背景
-
- 垂直分片
- 水平分片
- Spring Boot集成sharding-jdbc
- sharding-jdbc配置
- 配置解析
- table-strategy分片策略
-
- 1、standard
- 2、none
- 3、inline
- 4、complex
前言
ShardingSphere学习专栏: 传送门
背景
传统的将数据集中存储至单一数据节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足互联网的海量数据场景。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
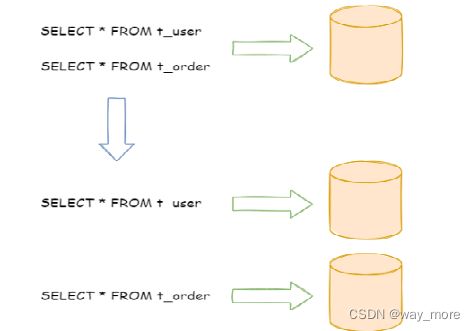
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表),如下图所示。

水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案。
Spring Boot集成sharding-jdbc
ShardingSphere-JDBC 提供了官方的 Spring Boot Starter,使开发者可以非常便捷的整合 ShardingSphere-JDBC 和 Spring Boot
引入 如下Maven 依赖即可
<!-- for spring boot -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
sharding-jdbc配置
下面是Spring Boot项目下的ShardingSphere-JDBC数据分片配置
#数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.names=ds0,ds1
#数据源相关连接信息
spring.shardingsphere.datasource.ds0.type=org.apache.commons.dbcp.BasicDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=
spring.shardingsphere.datasource.ds1.type=org.apache.commons.dbcp.BasicDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
#默认分片策略,当表没有设置单独的分片规则时,就会使用默认的分片策略。
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
配置解析
下面我们就来分析下上面的配置
1、数据源配置: 首先需要配置数据源,指定数据库连接信息,spring.shardingsphere.datasource就是数据源的相关配置,首先在names指定数据源名称,然后再配置相应数据源的连接配置,格式如下
spring.shardingsphere.datasource.-source-name>.type= #数据库连接池类名称
spring.shardingsphere.datasource.-source-name>.driver-class-name= #数据库驱动类名
spring.shardingsphere.datasource.-source-name>.url= #数据库url连接
spring.shardingsphere.datasource.-source-name>.username= #数据库用户名
spring.shardingsphere.datasource.-source-name>.password= #数据库密码
spring.shardingsphere.datasource.-source-name>.xxx= #数据库连接池的其它属性
注:每个data-source-name都需要配置
2、分片规则配置: 针对每个需要进行分片的表,需要配置相应的分片规则。这一部分是在spring.shardingsphere.sharding.tables进行配置,下面我就上述例子进行解析
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
这个配置是 Sharding-JDBC 中指定实际数据节点的配置,用于表示分片规则中具体的数据节点。它定义了表名为 t_order 的分片规则中的实际数据节点。在该属性值中,使用了占位符和表达式来表示不同的数据节点。
1、t_order表示哪个表需要分片,多个表需要相应进行配置,actual-data-nodes表示配置数据节点,固定值
2、ds$->{0…1} 表示数据源的名称,其中 $->{0…1} 表示占位符,可以被替换为 0 或 1,这里表示有两个数据源,分别为 ds0 和 ds1。
3、t_order$->{0…1} 表示表名的后缀,其中 $->{0…1} 同样表示占位符,可以被替换为 0 或 1,这里表示有两个表名后缀,分别为 t_order0 和 t_order1。
在上述配置中,有两个数据源 ds0 和 ds1,并且有两个表名后缀 t_order0 和 t_order1,那么实际的数据节点将包括 ds0.t_order0、ds0.t_order1、ds1.t_order0、ds1.t_order1 四个。
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
table-strategy:指定表的分片策略,table-strategy有以下几种策略
-
none表示不分片,所有数据都存储在同一个表中。 -
standard表示使用标准分片策略,根据分片键的值进行范围匹配,将数据路由到对应的分片表中。 -
inline表示使用行表达式分片策略,根据分片键的值通过表达式计算得到分片结果,将数据路由到对应的分片表中。 -
complex表示使用复合分片策略,可以同时使用多个分片键对数据进行分片计算,将数据路由到对应的分片表中。
具体的table-strategy使用,我会在下面详细解释
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
用于指定生成主键的列名,在上述配置中,t_order 表的主键生成列配置为 order_id。这意味着在向 t_order 表插入数据时,ShardingSphere 会自动生成主键,并将生成的主键值赋给 order_id 列
shardingSphere 提供了多种主键生成策略(如雪花算法、UUID 等),可以根据业务需求选择合适的主键生成器。通过配置spring.shardingsphere.sharding.tables.t_order.key-generator.type可以指定生成策略。
spring.shardingsphere.sharding.default-database-strategy
spring.shardingsphere.sharding.default-database-strategy为默认分片策略,当表没有设置单独的分片规则时,就会使用默认的分片策略
我们还可以使用spring.shardingsphere.sharding.default-data-source-name指定默认数据源名称。当未明确指定数据源名称时,ShardingSphere 将使用该属性配置的数据源作为默认数据源。
spring.shardingsphere.sharding.default-data-source-name=ds-0
table-strategy分片策略
table-strategy:指定表的分片策略,下面详细介绍下table-strategy的几种策略
1、standard
对应StandardShardingStrategy,标准分片策略,根据分片键的值进行范围匹配,将数据路由到对应的分片表中,提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
配置standard策略,我们需要实现PreciseShardingAlgorithm和RangeShardingAlgorithm接口来自定义自己的分片算法,如下所示
PreciseShardingAlgorithm实现类
@Component
public class MyTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Integer> {
/**
* @param tableNames 对应分片库中所有分片表的集合
* @param shardingValue 为分片属性,logicTableName 为逻辑表,columnName 分片键,value 为从 SQL 中解析出来的分片键的值
* @return
*/
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<Integer> shardingValue) {
for (String tableName : tableNames) {
// 取模算法,分片键 % 表数量
String value = String.valueOf(shardingValue.getValue() % tableNames.size() );
if (tableName.endsWith(value)) {
return tableName;
}
}
throw new IllegalArgumentException("分片失败,tableNames:" + tableNames);
}
}
配置文件进行进行配置
#配置分片键
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
#分片键策略
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=com.example.demo.shardingsphere.MyTablePreciseShardingAlgorithm
2、none
对应NoneShardingStragey,不分片策略,SQL会被发给所有节点去执行
3、inline
对应InlineShardingStrategy,使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用
如我们例子的配置
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order$->{order_id % 2}
shardingColumn:指定用于分片计算的列名,这里使用 order_id 字段。
algorithmExpression:指定分片算法表达式,这里使用了内联表达式 t_order$->{order_id % 2}。该表达式表示根据 order_id 的值进行取模运算,结果为0时路由到 t_order0 表,结果为1时路由到 t_order1 表。
4、complex
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持,ComplexShardingStrategy支持多分片键,如果表是多分片键的,那么需要使用该策略
使用complex 策略,需要我们自定义一个ComplexShardingAlgorithm实现类,在该实现类定义相关分片算法,如下所示
@Slf4j
public class MyComplexShardingAlgorithm implements ComplexKeysShardingAlgorithm {
/**
*
* @param availableTargetNames 进行分片的表
* @param shardingValue
* @return
*/
@Override
public Collection<String> doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
List<String> result = new ArrayList<>();
// 获取分片键列和对应的分片键值
Map<String, Collection<Long>> columnNameAndShardingValuesMap = shardingValue.getColumnNameAndShardingValuesMap();
// 遍历分片键列和分片键值
for (Map.Entry<String, Collection<Long>> entry : columnNameAndShardingValuesMap.entrySet()) {
String columnName = entry.getKey();
Collection<Long> shardingValues = entry.getValue();
log.info("分片键:"+columnName);
// 根据分片键列和分片键值进行分片逻辑的实现
for (Long shardingVal : shardingValues) {
for (Object availableTargetName : availableTargetNames) {
String tableName = availableTargetName.toString();
String value = String.valueOf(shardingVal % availableTargetNames.size() );
if (tableName.endsWith(value)) {
result.add(tableName) ;
}
}
}
}
return result;
}
}
注:ComplexKeysShardingValue 的 getColumnNameAndShardingValuesMap() 方法返回一个 Map
这个方法的作用是获取所有的分片键列及其对应的分片键值,其中键是分片键列的名称,值是对应的分片键值的集合。通过遍历这个 Map,你可以获得每个分片键列的分片键值集合,并根据自己的业务逻辑进行相应的分片操作。
ComplexKeysShardingValue 的getColumnNameAndRangeValuesMap() 方法返回一个 Map
这个方法的作用是获取所有的分片键列及其对应的范围值,其中键是分片键列的名称,值是对应的范围值。通过遍历这个 Map,你可以获得每个分片键列的范围值,并根据自己的业务逻辑进行相应的分片操作。
进行配置
#配置分片键
spring.shardingsphere.sharding.tables.t_order.table-strategy.complex.sharding-columns=order_id,user_id
#分片键策略
spring.shardingsphere.sharding.tables.t_order.table-strategy.complex.algorithm-class-name=com.example.demo.shardingsphere.MyComplexShardingAlgorithm