vite原理
一、依赖预构建
1、为什么需要依赖预构建
CommonJS和UMD兼容性
在开发阶段中,vite的开发服务器将所有的代码视为原生ES模块。因此,vite必须先将作为CommonJS或者UMD发布的依赖项转换为ESM。
这是vite的一个特色,也是为什么会相对于webpack比较快的原因,我们从原理上来看一下为什么需要转为ESM。
webpack是为了兼容性的考虑,支持多种模块化,当我们使用webpack启动项目的时候,webpack会根据我们配置文件(webpack.config.js)中的入口文件(entry),分析出项目所有的依赖关系,然后打包成一个文件(bundle.js),然后再启动开发服务器。

这样带来的问题就是,项目越大,需要打包的东西就越多,启动的时间越长。
目前绝大多数现代浏览器都已经支持ES module了,浏览器遇到在遇到内部的import引用的时候,会自动发起http请求,去加载对应的模块,vite也是借助了浏览器的这个特性,只接受ESM规范,在代码中不可以使用CommonJS,那么这个时候就不需要再去遍历依赖文件夹了,直接启动开发服务器,然后在浏览器请求依赖的时候,请求到哪个依赖,再根据需要对模块进行实时编译。这种动态编译的方式在项目越大的时候优点越明显。

依赖预构建仅仅适用于开发模式,并使用esbuild将依赖项转换为ES模块。在生产构建中,将使用@rollup/plugin-commonjs。
性能
vite将很多内部模块的ESM依赖关系转换为单个模块,以提高后续页面加载性能。
一些包将它们的 ES 模块构建作为许多单独的文件相互导入。例如,lodash-es 有超过 600 个内置模块!当我们执行import { debounce } from ‘lodash-es’ 时,浏览器同时发出 600 多个 HTTP 请求!尽管服务器在处理这些请求时没有问题,但大量的请求会在浏览器端造成网络拥塞,导致页面的加载速度相当慢。


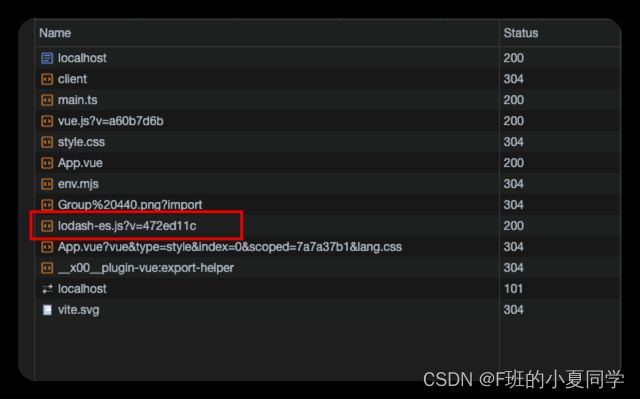
2、依赖预构建流程
缓存判断
默认的vite预构建产物缓存目录是node_modules/.vite/deps,在缓存目录中找到_metadata.json并进行解析读取,将_metadata.json文件中解析出的hash值与vite根据项目中包含的锁文件以及相关配置项信息进行hash得到的值进行比较。如果相同,则说明上次预构建产物结果无需进行变更,跳过预构建流程。如果不相同,则表示关联的依赖信息有更新或已过期,需要进行依赖预构建。
怎么去计算hash值呢?
根据几个源来决定是否需要重新运行预构建步骤:
- package.json 中的 dependencies 列表
- 包管理器的 lockfile,例如 package-lock.json, yarn.lock,或者 pnpm-lock.yaml
- 可能在 vite.config.js 相关字段中配置过的
只有在上述其中一项发生更改时,才需要重新运行预构建。
如果出于某些原因,你想要强制 Vite 重新构建依赖,你可以用 --force 命令行选项启动开发服务器,或者手动删除 node_modules/.vite 目录。

依赖扫描
如果没有找到符合的预构建产物缓存,vite将为预构建行为进行源码扫描,从代码中找到需要预构建的依赖,最终返回一个类似于下面这样的deps对象:
{
'vue': '/path/to/your/project/node_modules/vue/dist/vue.runtime.esm-bundler.js',
'element-plus': '/path/to/your/project/node_modules/element-plus/es/index.mjs',
'vue-router': '/path/to/your/project/node_modules/vue-router/dist/vue-router.esm-bundler.js'
}
具体实现就是,调用esbuild的build api,以index.html作为查找入口,将所有的来自node_modules以及在配置文件的optimizeDeps.include选项中指定的模块找出来。但是熟悉esbuild的同学都知道,esbuild默认支持的入口文件类型有js、ts、jsx、css、json、base64、dataurl、binary、file,并不包含html。vite是如何将index.html作为入口文件的呢?原因是vite自己实现了一个esbuild插件esbuildScanPlugin,来处理.vue和.html这种类型的文件。具体做法就是读取html的内容,然后将里面的script提取到一个esm格式的js模块。
问题又来了:在扫描的过程中,所有遇到的import 都会被预构建吗?
并不是的,预构建只会处理裸依赖,什么是裸依赖呢?
// 以名称导入即为裸依赖
import xxx from 'vue'
// 以路径导入则不是裸依赖
import xxx from "./a.ts"
Vite也是这样判断的。为什么要处理裸依赖呢?一方面是因为在浏览器环境下,是不支持这种裸模块引用的。另一方面,如果不进行构建,浏览器面对成千上万的子模块组成的依赖,依靠原生esm的加载机制,每个依赖的import都将产生一次http请求,所以,需要对裸模块引入进行打包,并处理成浏览器支持的路径导入方式。
依赖打包
到上一步,已经得到了需要预构建的依赖列表,把他们交给esbuild打包就行了。
二、静态资源处理和css模块化的处理
我们回忆一下,在webpack中,是如何去处理文件的,是通过loader,通过各种loader去读取各种文件,比如css-loader、style-loader处理css文件,因为webpack遵循的是CommonJS规范,并且只能识别js文件,所以就需要各种loader来做代码的转换,loader的本质就是一个函数,最后返回的也是一段可执行的javascript代码。但是vite呢?

我们发现在head标签里新建了一个style标签,我们的样式被写进了标签里面,vite对css的处理就是通过创建一个新的style标签,在页面引入样式文件来处理的。需要注意的是:vite会把css文件转化为js脚本文件,设置Content-Type:“text/javascript”来告知浏览器应该以javascript的方式来解析css脚本。这样做的好处有三点:
- 用于热更新
- 用于css模块化
- 去除了第三方工具对css的处理,提高了编译性能
css模块化 - 为什么会出现css模块化?
根本原因是为了解决协同开发,类名,id等冲突引起样式覆盖的问题。 - 如何解决?
让每一个css文件文件为单独的一个模块,具有单独模块的作用域,这样能够保证我使用的类名的唯一性。
比如:我们创建两个模块化的css:a.module.css、b.module.css
// a.module.css
.wrapper {
font-size: 20px;
color: blue
}
// b.module.css
.wrapper {
font-size: 100px;
color: red
}
//main.js
import AModuleCss from './a.module.css'
import BModuleCss from './b.module.css'
const ele1 = document.createElement('div');
ele1.className = AModuleCss.wrapper;
ele1.innerHTML = 'aaaaaa';
document.body.append(ele1)
const ele2 = document.createElement('div');
ele2.className = BModuleCss.wrapper;
ele2.innerHTML = 'bbbbb';
document.body.append(ele2)

我们发现,同样的类名,却只对自己作用域下的元素生效,并且,样式会被处理成key:value的形式,以类名作为键名,处理后的类名作为键值。
真实的类名会被替代为处理后的类名。

原理:
1、对css文件取名为xxx.module.css (module是一种约定,表示需要开启css模块化)
2、vite会将我们所有的类名进行一定规则的替换,(将footer替换为_footer_i22st_1)
3、同时创建一个映射对象{footer:“_footer_i22st_1”}
4、将替换过后的内容塞进style标签里然后放入到head标签中
5、将xxx.module.css内容进行全部抹除,替换成js脚本
6、将创建的映射对象在脚本中进行默认导出
静态资源处理
在vue中,静态资源分为两种:
1.存放在public中的静态资源,这部分资源会被完全的复制,不会经过构建工具处理,可以通过根绝对路径来引用他们,(即使没有被用到,也不会被tree shaking掉,会直接被完全复制)
2.存放在assets目录下,属于代码的一部分,只支持相对路径,会被构建工具打包,并且和样式会被压缩打到一起,可以避免额外的网络请求。
官方文档中有这样一句话:
public 中的资源不应该被 JavaScript 文件引用。
我们试着同时引入public、assets文件下的图片,看一下会有什么样的不同:

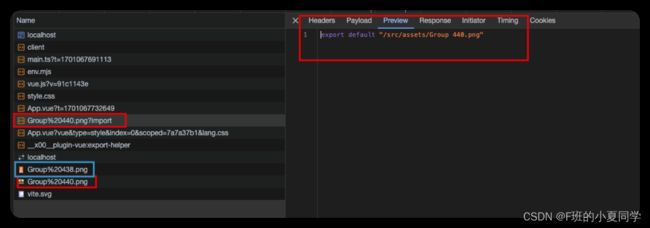
我们可以看到以import方式引入的图片,都会被处理成xxx?import请求,返回解析后的代码,得到的是一个可访问的url,但是public里的文件是不需要的,可以直接拿到图片。
那么假如我们在javascript文件中以import的方式去请求public中的静态资源,像这样

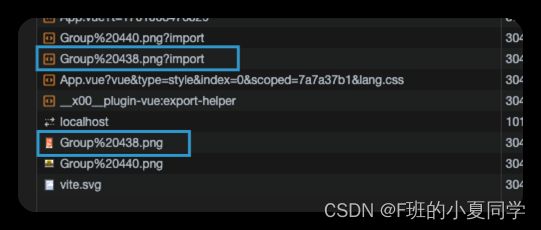
我们看到原本直接可以访问到的public静态资源也被处理了一次,那么这一次就有些多余了。所以不建议在javascript文件中引入public资源。
那么是如何实现的这样的差别化请求呢?
当请求资源的时候,首先会判断是否是import的资源:
export function servePublicMiddleware(){
return viteServePublicMiddleware(req,res,next){
const url = req.url;
//如果是import的资源会继续后续中间件transform的处理
if(isImportRequest(req.url)){
return next();
}
//public静态文件会直接返回
serve(req,res,next);
}
}
是import的资源,会继续importAnalysis插件中定义的transform方法。
importAnalysis:是vite内置的一个非常重要的插件,它的作用:
1、解析请求文件中的导入,是否存在,并且将相对路径重写为绝对路径 2、如果导入的模块需要更新,会在导入URL上挂一个参数,从未强制浏览器更新
3、对于引入 CommonJS 转成 ESM 的模块,会注入一段代码,以支持获取模块内容 4、更新 Module
Graph,以及收集请求文件接收的热更新模块 5、如果代码中环境变量import.meta.env,注入import.meta.env定义
async transform(source, importer, ssr) {
// 用?import标识非 js/css 的 import 依赖
url = markExplicitImport(url)
}
//判断是否是js请求或者css请求
function isEcplicitImportRequired(){
return !isJSRequest(cleanUrl(url)) && !isCSSRequest(url)
}
function markExplicitImport(url){
if(isEcplicitImportRequired(url)){
//如果不是就加上query=import
return injectQuery(url,'import');
}
}
我们通过ESM的方式导入静态资源,但是vite对他们的处理方式并不同,
比如:

打印出来的结果是样的:

css、js文件被直接输出内部定义的内容,json被转为了对象形式,而url和mp4被输出他们文件的url地址。
当然,有一些场景需要的时候,我们可以通过一些手段来改变他们的输出方式,
- ?url:声明将资源作为路径引入
- ?raw:声明将资源作为源文件引入
svg会和普通图片一样被作为一个路径引入,但是这个时候svg是没有办法改变颜色的,这个时候可以借助?raw将它作为源文件引入,我们就可以改变他的颜色了。
他的实现原理其实和刚刚的public和asstes的实现原理类似,也是通过query(?raw|url)来区别不同类型的静态资源,进行特殊的transform处理。
除了上面我们提到的一些资源格式,vite也对下面很多格式提供了内置的支持: - 媒体类文件,包括mp4、webm、ogg、mp3、wav、flac和aac。
- 字体类文件。包括woff、woff2、eot、ttf 和 otf。
- 文本类。包括webmanifest、pdf和txt。
但是假如你的项目中还需要其他格式的资源,可以通过assets Include配置让vite支持加载:
// vite.config.ts
{
assetsInclude: ['.gltf']
}
三、vite的热更新
在介绍热更新之前,我们先来思考一下,从修改代码到界面更新,这个过程发生了什么?
1、修改代码
2、重新编译(怎么编译?)
3、告诉前端要更新啦(怎么告诉?)
4、前端执行热更新代码进行热更新(怎么更新?)
实际上也就是这几个步骤:

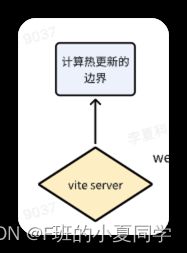
Vite server:指vite在开发时启动的server
什么是热更新边界?
比如说两个文件,a.ts被import进b.vue
(vue文件自带了热更新逻辑,但是ts文件是没有热更新逻辑的)
那么当a.ts改变的时候,怎么样进行热更新呢?b.vue作为最近的可接受热更新的模块,就被称为热更新边界。
沿着依赖树,往上找到最近的一个可以热更新的模块,即热更新边界,对其进行热更新即可。

websocket是什么时候创建的呢?
Vite server 会在index.html中注入@vite/client的脚本,当访问到index.html的时候,就会拉取这个脚本。

在client.ts里面会创建websocket

并且添加message监听事件:

handleMessage主要负责根据不同的类型执行不同的操作,在热更新里会触发handleMessage里的update操作,告诉client需要更新的模块。
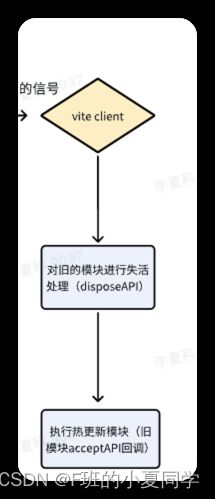
当client拿到需要更新的模块的时候,会进行老代码的退出和新代码的更新,这里涉及到了hot.dispose和hot.accept两个API。
accept用于传入一个回调函数,来定义该模块修改之后,需要怎么去热更新。
if (import.meta.hot) {
// 调用的时候,调用的是老的模块的 accept 回调
import.meta.hot.accept((mod) => {
// 老的模块的 accept 回调拿到的是新的模块
mod.render();
});
}
dispose 类似 hot,只是 dispose 定义的是老模块如何退出,而 hot 定义的是新模块如何更新。
在vite中,热更新是开箱即用的,vite 的 vite-plugin 插件,在编译模块时加入了 vue 热更新的代码。
vite 本身只提供热更新 API,不提供具体的热更新逻辑,具体的热更新行为,由 vue、react 这些框架提供。
四、为什么ESbuilld打包构建比较快?为什么没有应用到生产环境?

语言优势
大多数前端打包工具是基于javascript实现的,而Esbuild选择使用Go语言编写。
在CPU密集的场景下,Go更加具有性能优势。
因为javascript本质上是一门解释型的语言,每次执行的时候都会先将源码翻译成机器码,一边调度执行;而Go是一种编译型语言,在编译阶段就已经将源码转移成机器码,启动的时候只需要直接执行这些机器码即可。也就意味着,Go语言编写的程序比js少了一个动态解释的过程。
多线程优势
Go天生具有多线程运行能力,而javascript本质上是一门单线程语言,直到引入WebWoker才可能在浏览器/node中实现多线程。
Rollup/Webpack并没有使用WebWoker提供的多线程能力,而ESbuild的实现尽可能的使用各个CPU核,特别是打包过程的解析/代码生成阶段已经实现完全并行的处理。
并且Go语言多个线程之间还能共享相同的内存空间,而javascript的每个线程都有自己的内存堆,这意味着Go中多个处理单元,例如解释资源A的线程,可以直接读取资源B线程的运行结果,而js中相同的操作需要调用通讯接口woker.postMessage在线程间复制数据。

节制
ESbuild仅仅提供了构建一个现代Web应用所需的最小功能的集合
- 支持 js、ts、jsx、css、json、文本、图片等资源
- 增量更新
- Sourcemap
- 开发服务器支持
- 代码压缩
- Code split
- Tree shaking
- 插件支持
并且有很多功能官网明确声明没有计划实现支持。
定制
在之前的打包工具中,我们使用了很多第三方插件来解决各种工程需求,比如: - 使用babel实现ES版本转译
- 使用ESlint实现代码检查
- 使用TSC实现ts代码转译
- 使用less/stylus/sass等css预处理工具
我们已经完全习惯了这种方式,但是esBuild使用了另一种做法,直接完全重写整套编译流程所用的所有的工具,也就是说需要重写js/ts/jsx/json等资源文件的加载/解析/链接/代码生成逻辑。
开发成本很高,但是他可以以性能为最高级定制编译的各个阶段,比如说: - 重写ts转译工具,完全抛弃ts类型检查,只做代码转换
- 大多数打包工具把词法分析、语法分析、符号声明等步骤拆解为多个高内聚低耦合的单元,可读性和可维护性比较高,但是esbuild坚持性能第一,将多个处理算法混合在一起降低编译过程数据流转所带来的性能损耗。
结构一致性
我们提到esbuilld选择重写js/ts/jsx/css等语言在内的转译工具,所以他比较能保持编译步骤之间的结构一致性,比如在Webpack中使用babel-loader处理javascript代码的时候,可能需要经过多次数据转换: - Webpack读入源码,此时是字符串形式
- Babel解析源码,转换为AST形式
- Babel将源码AST转换为低版本的AST,Babel将低版本AST generator为低版本源码,字符串形式
- Webpack解析低版本源码
- Webpack将多个模块打包为最终产物
源码需要经历string=>AST=>AST=>string=>AST=>string,在字符串与AST之间反复横跳。
而Esbuild重写大多数转译工具之后,能够在过个编译阶段共用相似的AST,尽可能减少字符串到AST的结构转换,提升内存使用效率。
五、vite的插件机制
从上面可以知道,虽然esbuild快的惊人,但是因为一些重要功能的缺失–特别是代码分割和 CSS
处理方面,并不适合作为生产环境的打包工具。vite在生产环境用了rollup,vite需要保证,同一套配置,在开发环境和生产环境下的表现是一致的。想要达到这个效果,vite只能在开发环境模拟RollUp的行为,然后在生产环境打包的时候,将这部分替换成Rollup打包。

生产环境:vite直接调用了Rollup进行打包
开发环境:vite模拟了Rollup的插件机制,通过PluginContainer插件容器对象调度执行各个插件。
实现思想
实现Rollup的插件行为,实际上是实现相同的插件钩子行为。
插件钩子是在构建不同阶段调用的函数。钩子可以影响构建的行为、提供有关构建的信息或在构建完成后修改构建。
钩子行为,主要包括以下内容:
- 实现Rollup插件的调度
- 提供Rollup钩子的Context上下文对象
- 对钩子的返回值进行相应处理
- 实现钩子的类型
什么是钩子的调度?
按照一定的规则,在构建对应的阶段,执行对应的钩子。
举个栗子:当 Rollup 开始运行时,会先调用 options 钩子,然后是 buildStart
什么是钩子的 Context 上下文对象?
在 Rollup 的钩子函数中,可以调用 this.xxx 来使用一些 Rollup 提供的实用工具函数,而这个 this 就是钩子的 Context 上下文对象。Vite 需要在运行时,实现一套相同的 Context 上下文对象,才能保证插件能够正确地执行 Context 上下文对象的属性/方法。
什么是对钩子的返回值做相应的处理?
部分钩子的返回值,是会影响到Rollup的行为。
例如:
export default function myExample () {
return {
name: 'my-example',
options(options) {
// 修改 options
return options
}
};
}
options钩子的返回值,会覆盖Rollup当前的运行配置,从而影响到Rollup的行为。
Vite 同样需要实现这个行为 —— 根据返回值做相应的处理。每个钩子的返回值(如果有),对应的处理是不同的,都需要实现。
什么是钩子类型?
- async:钩子函数可以是 async 异步的,返回 Promise
- first:如果多个插件都实现了这个钩子,那么这些钩子会依次运行,直到一个钩子返回的不是 null 或 undefined的值为止。
- sequential:如果有几个插件实现了这个钩子,串行执行这些钩子
- parallel:如果多个插件都实现了这个钩子,并行执行这些钩子
Vite 同样需要实现这些钩子类型。
六、vite和webpack的对比
Webpack
优点
- 首屏加载:由于dev启动过程中已经完成整个打包操作,直接将构建好的首屏内容发送给浏览器,不存在性能问题。
- 懒加载:也是由于进行了打包操作,所有的依赖在dev构建过程中都得以处理,懒加载也不存在问题。
缺点 - 本地启动时间长:由于本地开发环境,webpack也会先进行打包,然后在启动服务运行项目,所以如果项目庞大就会出现启动慢的情况。
- 热更新慢
Vite
优点 - 启动快:借助了浏览器对 ESM 规范的支持,Vite 无需进行 bundle 操作,源文件之间的依赖关系通过浏览器对 ESM 规范的支持来解析,所以在启动过程中,只需要进行一些初始化的操作,其余全部交由浏览器处理,所以项目启动非常之快;
- 热更新快:
本地开发环境,在监听到文件变化以后,直接通过 ws 连接,通知浏览器去重新加载变化的文件;
编辑一个文件时,Vite 只需要精确地使已编辑的模块与其最近的 HMR 边界之间的链失活(大多数时候只是模块本身),使得无论应用大小如何,HMR 始终能保持快速更新;
源码缓存:Vite 同时利用 HTTP 头来加速整个页面的重新加载(再次让浏览器为我们做更多事情):源码模块的请求会根据 304 Not Modified 进行协商缓存,
依赖模块缓存:解析后的依赖请求则会通过 Cache-Control: max-age=31536000,immutable 进行强缓存,因此一旦被缓存它们将不需要再次请求。
缺点 - 首屏加载慢
- 没有对文件进行 bundle 操作,会导致大量的 http 请求
- dev 服务运行期间会对源文件做转换操作,需要时间
- 尽管预构建很快,但是也会阻塞首屏的加载
- Vite 需要把 webpack dev 启动完成的工作,移接到了 dev 响应浏览器的过程中,时间加长
- 但是由于缓存的存在,当第一次加载完成之后,再次 reload 的时候性能会有所提升
- 懒加载慢
和首屏加载一样,动态加载的文件需要对源文件进行转换操作还可能会有大量的 http 请求,懒加载的性能同样会受到影响。