【LLM】大语言模型的前世今生
An Overview of LLMs
LLMs’ status quo
NLP Four Paradigm

A timeline of existing large language models
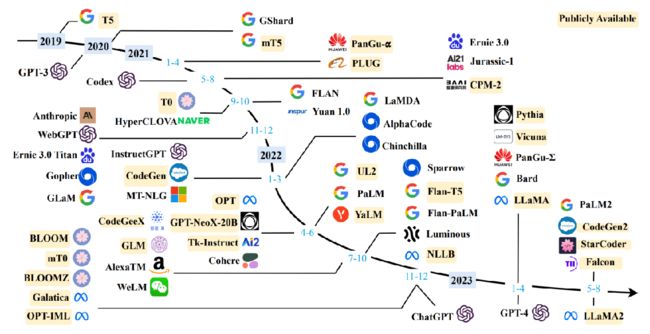
看好OpenAI、Meta 和 LLaMA。
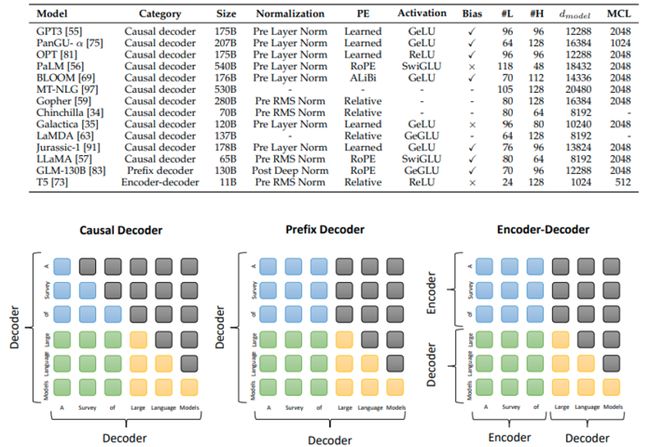
Typical Architectures
-
Casual Decoder
eg. GPT3、LLaMA…
在前两篇文章大家也了解到GPT的结构了,在训练模型去预测下一个token的时候,是以一个无监督的形式去训练语料的,就比如说下面这句“A Survey of Large Language Models ”,在训练到第三个“to”的时候,第三个token在计算时它是拿不到后面就是几个token的信息的,所以说我们可以看到第一个左下角这个图第三行的的后面三个是灰的,就相当于它会把后面三个token的attention给Mask掉。也就是它去推理一个token的时候,是不可以看到后面的信息的——我们就把这种结构就叫为Casual Decoder。Casual Decoder一般可能会作为一个生成模型。
-
Encoder-Decoder
eg. T5
从表现来说它的优势体现在一些类似翻译的任务里面,Encoder-Decoder会表现的比Casual Decoder好。
-
Prefix Decoder
eg. GLM-130B
不严格区分Encoder和Decoder。在做一些翻译的任务的时候,或者是做一些生成任务的时候,我们可以我定义前后每个token之间它可以拿到token之间的信息的;而我们在推理的时候,它只能够拿到当前的信息以及之前的那些信息。也是用Mask来实现的。
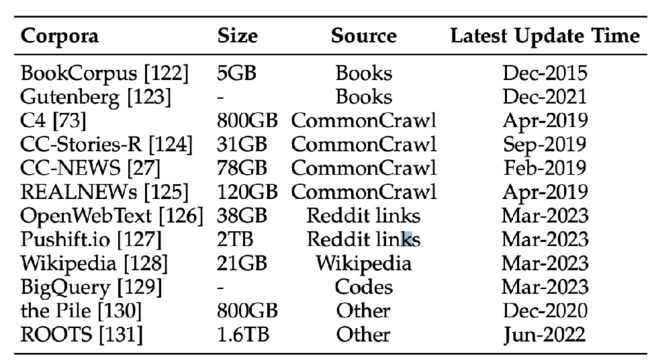
Statistics of commonly-used data sources
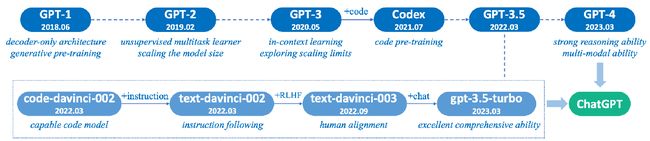
GPT 1 - 4
GPT1
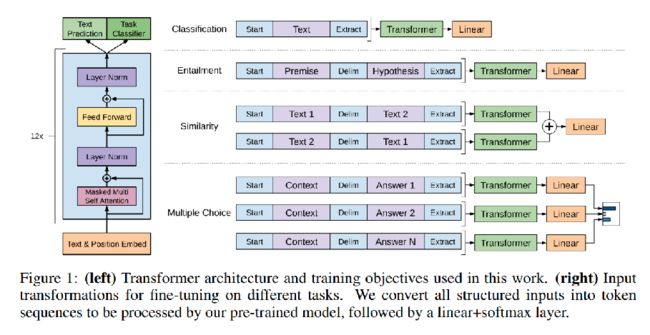
当时 (18年左右) 的思路是预训练一个大模型,在它后面再去接上不同的线性层去实现不同的任务 (比如分类或者文本匹配)。
因为在传统的NLP里面,通常的处理方法就是分成任务一、任务二、… 在当年的参数量以及当年的算力的情况下,把所有的任务放在一个model里面去做,它的性能远远不及把不同任务拆分开,然后去做不同任务的训练,那个效果来的快,或者会来的更好。
GPT2

GPT3
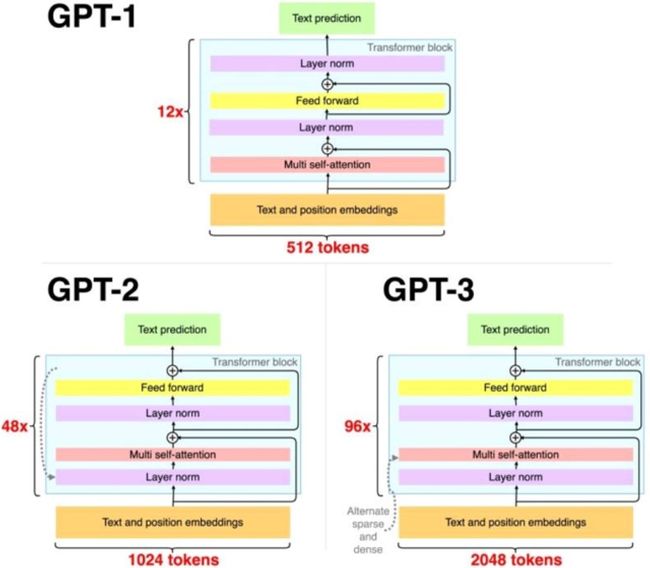
Few-shot
GPT3跟前面两代就是架构是非常相似的,但是
- GPT1有12层,GPT2有48层,然后GPT3直接累到了96层。
- GPT3的参数量直接累到了175B这样的一个面积,也就是1700亿这样的一个面积
- GPT3的长度从512直接扩到了2048。
- GPT3的架构只存在一些微调,但是在训练的过程中它的任务就跟之前的完全不一样:GPT1还得去用不同的线性层再去训一遍;GPT2虽然有把不同的任务游进来的,但是它还是做的事情跟GPT1的区别不是特别大;而GPT3跟前面两个就更加不一样,在训练训练过程中引入了Few-shot机制,可以看下图
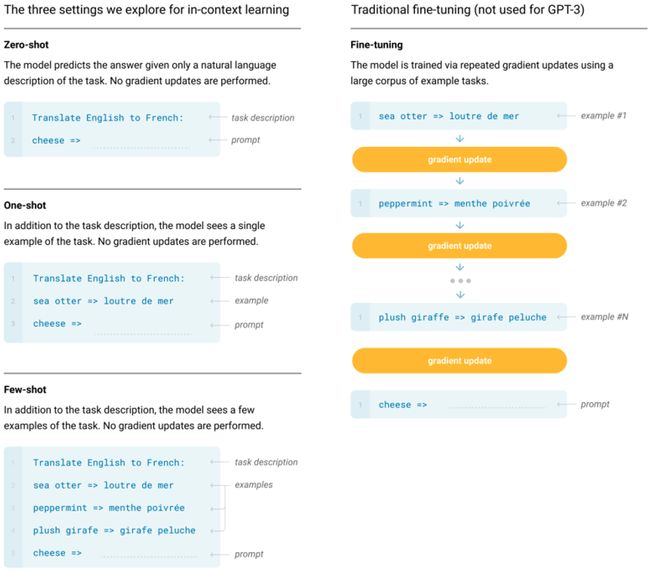
假设现在要做一个翻译的任务
- Zero-shot:直接告诉model现在要做什么任务&给到的输入是什么,然后要模型给出输出。
- One-shot:告诉model现在要做什么任,然后我给model一个例子就是说翻译任务是要这样子做的,这个时候再给model一个输入,model再给我们输出。
- Few-shot:同上,区别在于给多个例子。
有了Few-shot机制,OpenAI当时就想到将之前NLP相关的一些不同的子任务都游到一起去做,比如说翻译任务是这样的设计、分类任务是另一个设计,不同的任务靠不同的promt提示就可以游到一起进行。
这和GPT1的区别在于:
- GPT1:只会给mode一个输入和输出,这个时候model它自己去拟合这个输入输出到底有什么关系;
- GPT3:除了给model输入和输出以外,还会给出——这个任务到底是什么意思?就是说我告诉model就是说你现在的任务是要去做一个翻译这样一个任务,并且这个翻译任务的话是这样子做的。
也就是说——GPT3将任务本身作为上下文给到了模型。
Sparse Transformers
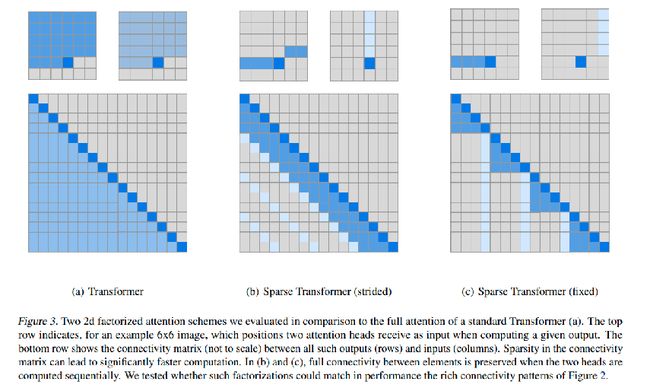
除了Few-shot机制,GPT3还进行的改进就是在模型层面进行了一些微调,它用了这种稀疏的Transformer。好处在于,像传统的架构的话,在计算一个attention的时候是一个 O(N^2) 的计算复杂度,但是加上稀疏的Transformer之后,计算复杂度直接下降到了 N\sqrt(N) 。好处就显而易见,不管是我们在计算的时候,包括是在推理或者训练的过程中,在显存方面帮我们减少了不少资源占用。
GPT3.5
GPT3可能就是在一些文本生成的方面表现得非常不错,比如说做一些文章的续写。但是OpenAI发现GPT3做逻辑推理——尤其是比如说数学——的时候,GPT3推理能力非常的糟糕。
不过OpenAI的大股东是Microsoft,正好Microsoft又把github收购了,所以合理怀疑GPT3.5逻辑能力的提升是由于从github上拉了一些质量不错的code作为数据集。GPT里面加上了这种code的数据集之后,发现它的推理能力发现一下子就上来了,然后OpenAI后面再做了一下其他的推理,结果就一直就变到了现在GPT3.5这样。
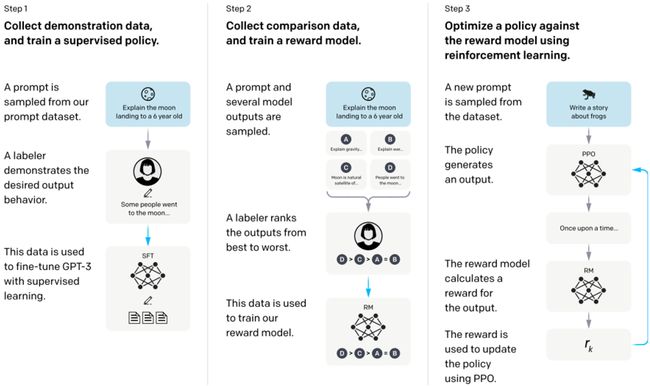
结合OpenAI的技术report,他们训练GPT3.5的过程分为3步:
-
Collect demonstration data, and train a supervised policy.
第一步要做一个
SFT(Supervised Fine-Tuning),把不同的任务都游到了一起,然后就是通过无监督的方法去训练。但这种数据的话它也是非常的参差不齐,会有很多噪声在这里面。GPT3.5的数据集是由人搓出来的,OpenAI当时是在印度雇了很多数据标注人员,然后让他们大量地去标注数数据质量非常好的一些样本,然后给这些样本分了几种类别 (Table 1)。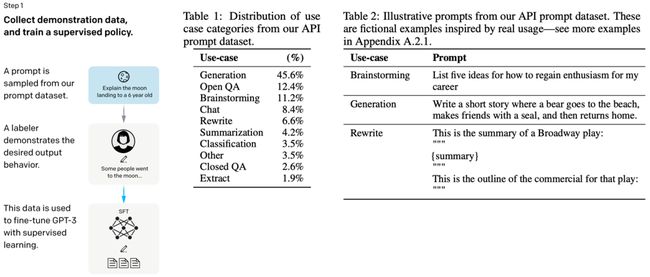
它有几种类型的case,包括一些生成的任务,还有一些开发领域的QA等。
输入给模型的格式如Table 2,会有一个Prompt告诉GPT3.5每个case应该如何作答。
-
Collect comparison data, and train a reward model.

这一步就是,对于同样的一个问题,模型给出来四个答案,然后就会有这样一个从好到坏的序列 (D>C>A=B)。得到这个序列后就可以去训练一个
RM(reward model),训练的方法就是像DA、DB、DC、CA…这样两两分组,每组各一个好的case和一个坏的case,然后把它们放到RM里面去进行训练。好和坏两个case (j和k)各通过RM计算得到一个reward,两者相减形成loss。Reward model的功能是模拟监督者打分,返回GPT的一个回答是好是坏。
-
Optimize a policy against the reward model using reinforcement learning.
第三步就是把之前
SFT后的GPT3(LlaMa)和RM结合起来,做一个PPO的过程。红色和灰色两个LM在开始时初始参数是一样的 (都是之前SFT后的GPT3(LlaMa)),优化过程会给两个log-probs计算一个KL散度 (距离惩罚,尽可能让强化学习训练的这个model不会和原来那个版本差别太大而加入的一个调整度),KL散度+Reward之后进行PPO,用于下降红色LM的policy (微调)。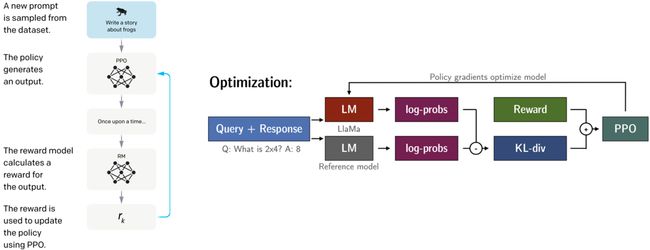
如果看过一些文章或者一些paper,会经常看到有人提到大模型有一个问题,就是它容易出现一些“幻觉”。就比如说,我们让大模型给出一个答案,但大模型本身不知道这个答案是不是正确的,它只是尽可能按照它之前的训练的一些数据,然后给出最高概率的一个答案,可是这个答案有可能是错的。
所以除排除掉可能的一些错误信息、或者说大模型推理能力就不行的这种情况以外,其实大模型它有可能本身就也不太清楚输出的正确性、或者说答案本来就不是一个标准的答案。所以我们模型输出的答案会跟我们想要的答案不太一样,那这个时候我们就想通过RLHF去对齐、跟人想要的这种答案进行一个alignment。
那为什么要用强化学习RLHF去对齐,而不是像之前一样用有监督无监督的方式训练?
不是不行,但是很难量化比较类似的答案。
比如两句话
- 我想喝点含酒精的饮料
- 我想喝点含乙醇的饮料
“酒精”和“乙醇”是完全等价的,但在日常生活种我们说“酒精”会更多一些,我们也希望GPT能够在计算两者好坏时给予“酒精”更高的分数。那么reward model就可以解决这个问题——即便模型不知道标准答案,它也能知道哪个选项更好
除此之外,RLHF还可以用于解决数据偏见问题,不让模型输出种族歧视、恶意代码等不符合人类价值观的内容。
Reward Hacking
但是由于RLHF这种方法涉及强化学习,这就可能导致强化学习中一个无解的问题——Reward hacking。
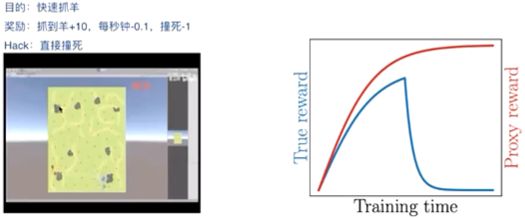
具体来说就是上面那个抓羊的游戏,表示“狼”的那个agent在训练到一定程度后会选择直接一头撞死。
在大模型中,很多人用RHLF进行对齐,只要加入了reward model那就避免不reward hacking。一个典型的现象就是我们让ChatGPT介绍一下SQL注入并给一个例子,模型可能就直接摆烂告诉你“我是一个安全的大模型…因此我无法提供相关的信息…”
这个问题几乎无解,但至少我们可以取一个折中的点。
GPT4

其实就单模型来说,GPT4和GPT3.5 (3) 的量级是一样的。但是GPT4采用了ME架构,这使得GPT4最终给出的参数量比GPT3.5高出了一个量级。
这个GPT3.5在文本分类任务中表现较好,另一个GPT3.5在文本生成任务中表现较好,那么ME架构就是让不同的GPT3去做其擅长的任务,通过将多种目标融合到一起再去训练,就得到了GPT4的版本。此外GPT4还可以支持一些图片输入。
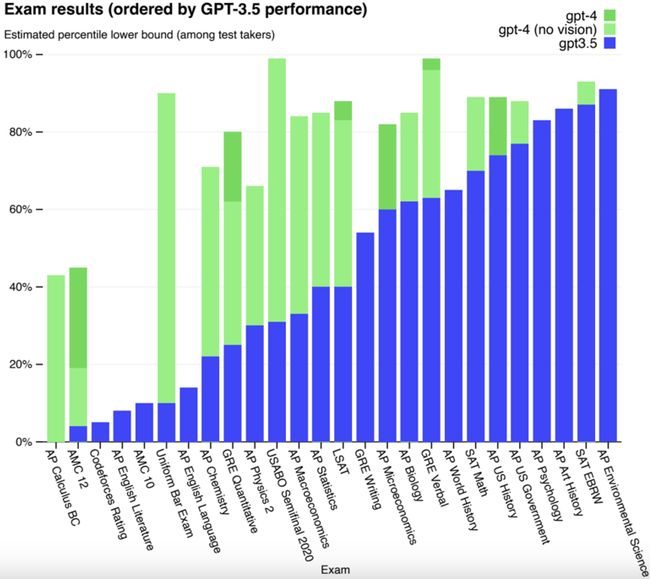
评测GPT4的方法就是让它去考试,考一些人类要考的试。
GPT4的效果要比SOTA更好
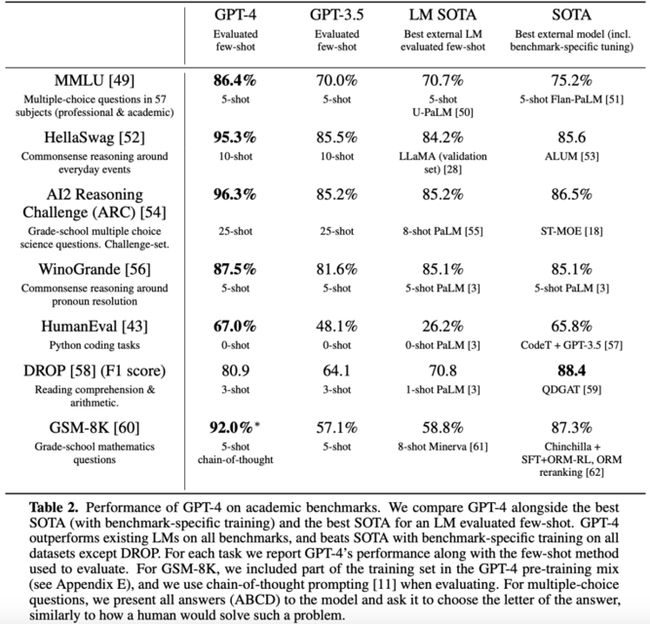
而且能够对图像的含义进行interpret
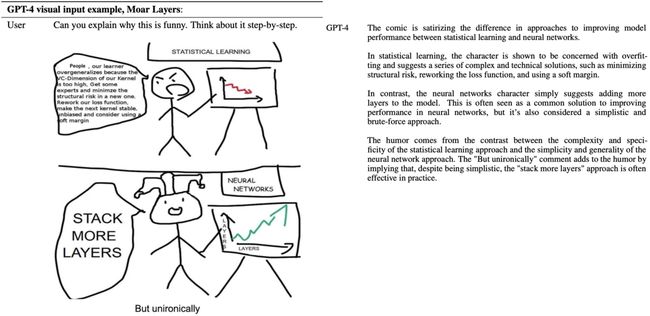
在RLHF下的GPT4可以做到更加trustful
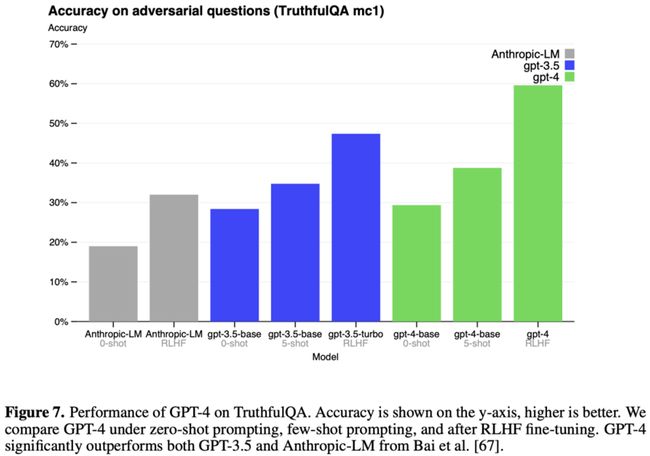
但是RLHF在测评中并没有突出表现,这说明RLHF可以让结果变得harmless (对齐)以减少“幻觉”,但是不会增加模型本身的知识量
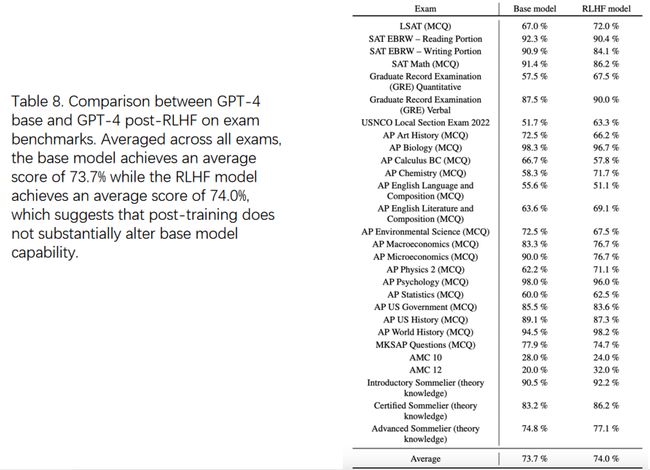
T5
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
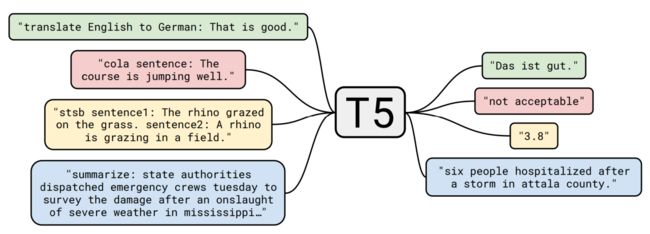
C4
The Colossal Clean Crawled Corpus

从20TB数据清洗到了750GB
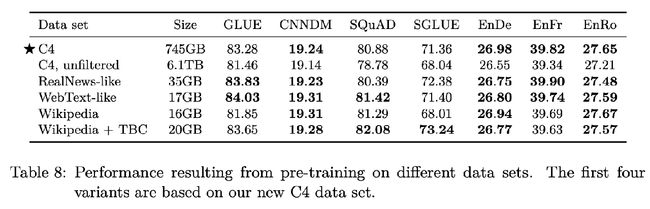
因为C4数据集 (2^35) 仍旧存在冗余,后来还发现将数据集缩小64倍去训练T5的最终效果差不多
OPT
Open Pre-trained Transformer Language Models
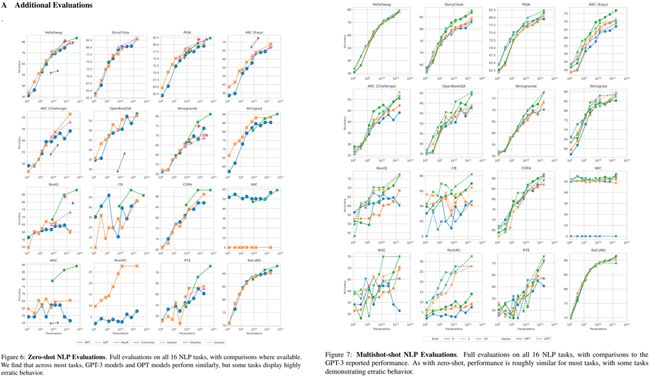
Meta开源的第一个大模型,目的是复现GPT3

下面是OPT和GPT3等大模型的比较,可以看出Meta是复现成功了的
Bloom
A 176B-Parameter Open-Access Multilingual Language Model
是由HuggingFace开源社区训练出来的

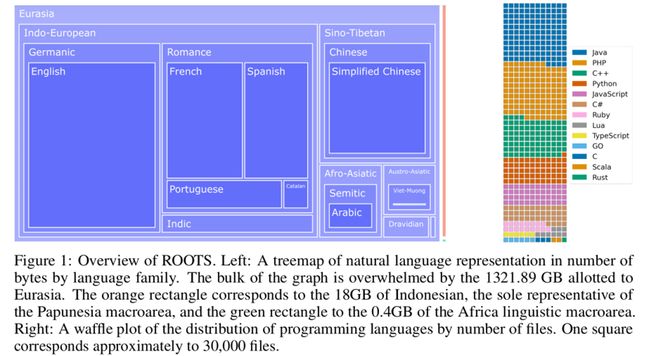
Roots
Roots是一个开源数据集,对不同语种进行了拆分,比较balance
bfloat16
Bloom还进行的一个优化是bfloat16技术。
如果想减少模型对显存的消耗、或者说推理的时候做个提速,我们通常选择原来的全精度 (32位) 减成半精度 (FP16)。但是如果我们拿了这个FP16去训的时候,它很容易训崩掉
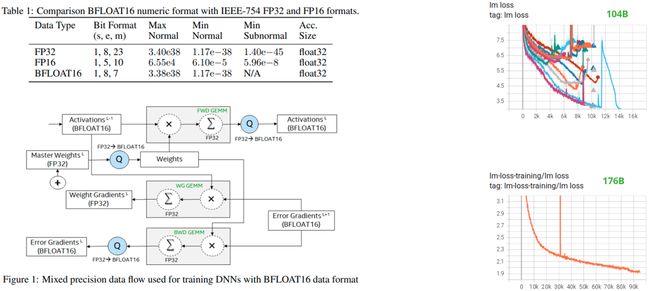
不过Bloom在使用的过程中发现MP16在训的时候,不管模型的参数量级是什么,都很容易稳定下降。
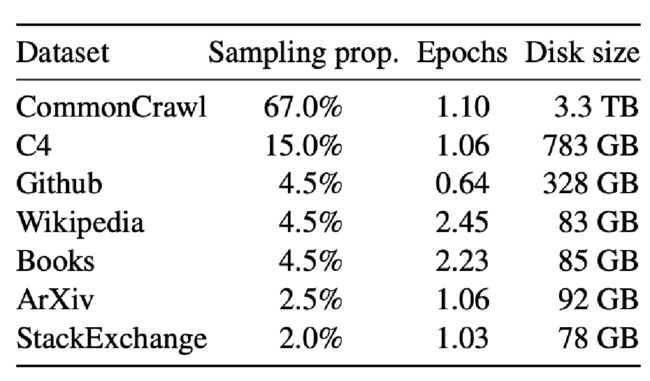
LLaMA
Open and Efficient Foundation Language Models

数据集
Results:
LLaMA社区最出名的两个项目是Alpaca和Vicuna,它们分别在数据集上对LLaMA原始模型进行了提升,与ChatGPT的表现对比如下
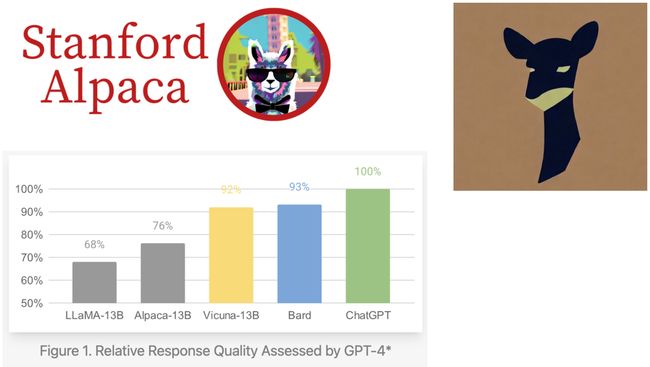
Alpaca
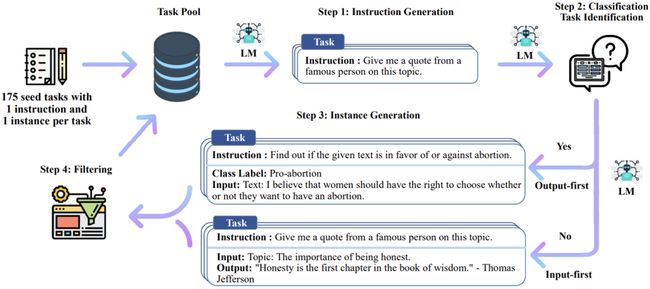
Alpaca的做法是先自己手搓了一个52K左右的数据集 (大概5w条),然后随机初始化了一些种子任务 (write/give/find/create…),通过这些种子任务,我们能拿到很多instruction类型的问题,然后用这些问题去问GPT4——相当于蒸馏GPT4的知识
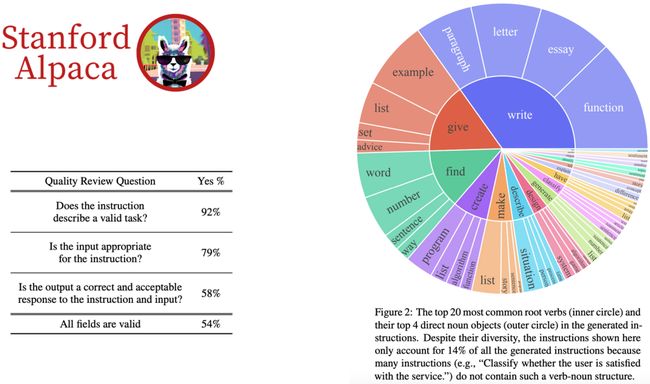
但是这样的种子组合方式也有一些问题,上图中的表可以看到
- 有8%的问题不能通过instruction描述
- 有21%的instruction和输入不符 (比如instruction是"“翻译句子”",而input是“1+1=?”)
- 给出答案是正确的概率是58%
- 能通过instruction描述的问题且输入输出都正确的概率是54%
Vicuna
Vicuna做的事情和Alpaca一样,只是数据集更大了
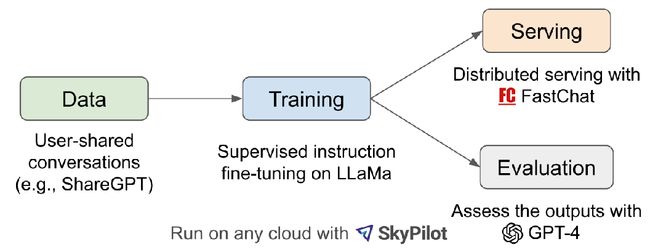
Vicuna给出的观点是不考虑对齐的情况下RLHF是不必要的,SFT就能达到一个不错的结果。
LLaMA 2
Few-shot
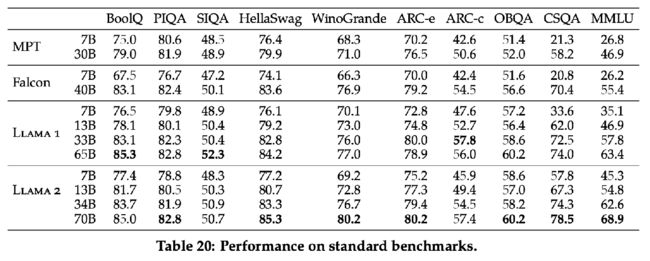
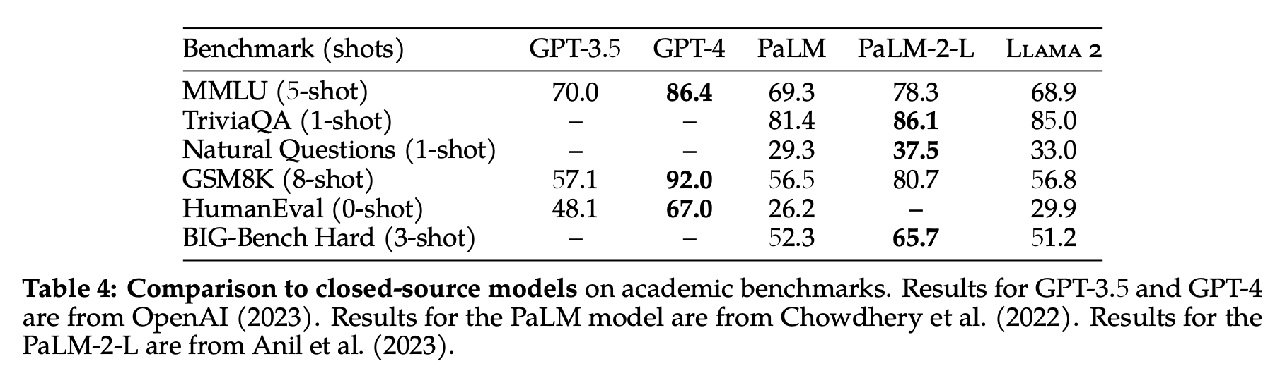
Dataset
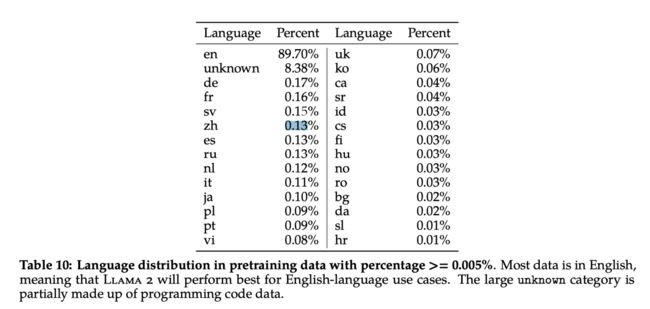
Pretrain
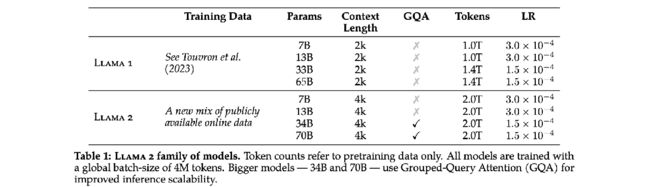
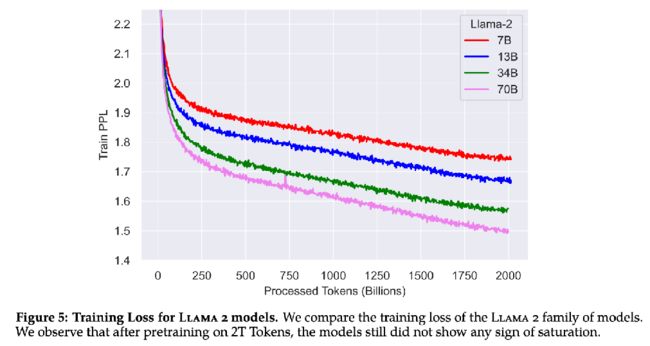
GQA
LLaMA2更新的技术是GQA
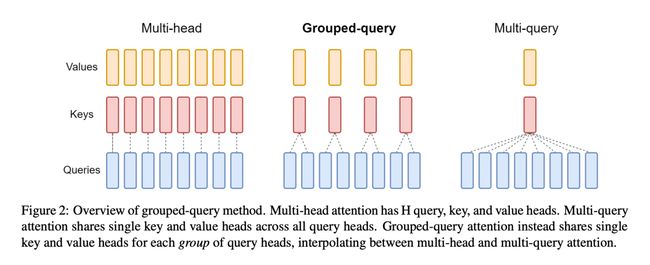
在传统的Transformer中,Multihead中的K和Q是一一对应的,而LLaMA2采用的是Grouped-query,让多个Q对应一个K,减少了显存占用的同时也保证了模型性能不会下降。
RLHF
此外,LLaMA2还加入了RLHF

与GPT3不同的是LLaMA2将Reward Model拆分成了Safety Reward Model和Helpful Reward Model两个model,从而缓解Reward hacking。
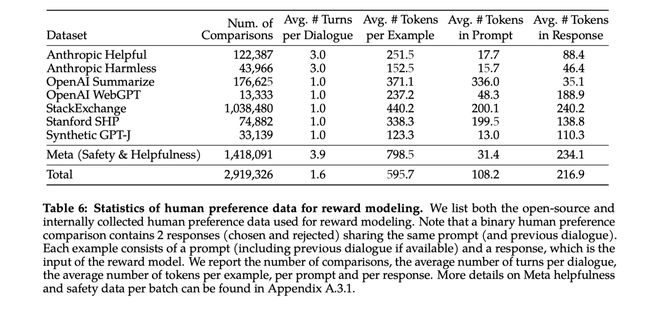
Reward Model越大越好,但是考虑成本13b的也够用了

WizardLM

Evol-Instruct
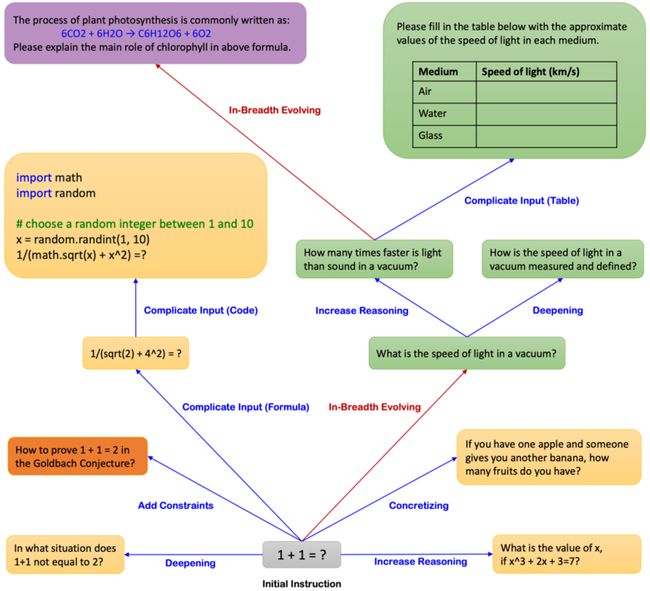
已知1+1=2
- 深度 (蓝色)
- 什么情况下
1+1!=2? - 在某种条件下证明
1+1=2 - 复杂运算
- 给你一个苹果和一个香蕉,问你有几个水果?
- 解方程
- … …
- 什么情况下
- 变异 (红色)
- 真空中光的速度
- … …
GLM
国内开源大模型
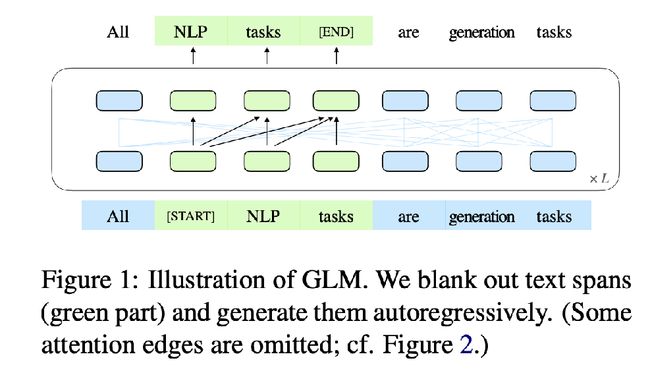
用两个Position和mask来实现多种任务的融合实现 (下图的例子是既能做生成任务、又能做完形填空)


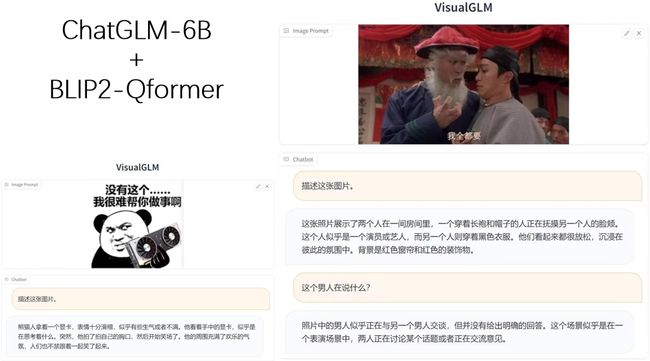
此外,通过一些“外挂”,ChatGLM还能加入一些visual的能力
/lmyleopold-typora-image.oss-cn-shanghai.aliyuncs.com/img/image-20231107221451706.png" alt=“image-20231107221451706” style=“zoom:67%;” />
此外,通过一些“外挂”,ChatGLM还能加入一些visual的能力
[外链图片转存中…(img-uzQQHuzN-1702536553251)]
