【LLM】“幻觉”的缓解方法
Hallucination
What’s Hallucination 什么是幻觉
在大型语言模型(LLM)中生成与现实或已知事实不符的信息。

幻觉的类型
- 上下文冲突型(Context-Conflicting Hallucination)
- 事实冲突型(Fact-Conflicting Hallucination)
下面是一些不同类型的幻觉的例子

- 输入冲突型幻觉(Input-conflicting Hallucination)
- 用户描述:用户提到和朋友Hill一起打篮球的经历,包括在场上花费的时间以及对这个游戏的热爱如何把他们作为好朋友更紧密地联系在一起。
- 模型响应:模型错误地将“Hill”改为了“Lucas”,并声称这让他们成为了好朋友,这与用户输入的信息不符。
- 上下文冲突型幻觉(Context-conflicting Hallucination)
- 用户描述:用户请求关于NBA总裁的信息。
- 模型响应:模型提供了关于当前NBA总裁Adam Silver的信息,但在描述中错误地提到了前NBA总裁David Stern的观点,造成了上下文的冲突。
- 事实冲突型幻觉(Fact-conflicting Hallucination)
- 用户描述:用户询问葡萄牙第三任国王Afonso II的母亲是谁。
- 模型响应:模型错误地声称Afonso II的母亲是Queen Urraca of Castile,而事实上她并不是。
Mitigation of LLM Hallucination 缓解大型语言模型中的幻觉
预训练期间的缓解(Pre-training Mitigation)
在预训练阶段减少幻觉产生的策略——Data Cleansing。
监督微调期间的缓解(Mitigation during SFT)
下图中的左侧圆形区域代表LLMs(大型语言模型)的参数知识,而右侧圆形区域代表SFT(监督微调)数据。两个区域的重叠部分旁边有一句话:“Teach LLMs to hallucinate”,这暗示了SFT数据中的样本通常包含超出LLMs参数知识范围的信息,这可能会导致幻觉现象,也就是在生成输出时产生不准确或不相关的信息。

这说明SFT数据在训练LLMs时,可能会引导模型学习到错误的信息或教会模型“幻觉”,特别是当数据包含超出模型参数知识范围的样本时。简而言之,这张图通过视觉方式表达了在SFT过程中存在的一个潜在风险:在超出LLMs已有知识范围的数据中进行训练,可能会导致模型生成不准确的信息。
基于人类反馈的强化学习期间的缓解(Mitigation during RLHF)
表格列出了五种不同的情况,每种情况都对应一个奖励值,这是在强化学习(Reinforcement Learning, RL)中减轻大型语言模型(Large Language Models, LLMs)产生幻觉(hallucinations)的一种奖励设计示例。
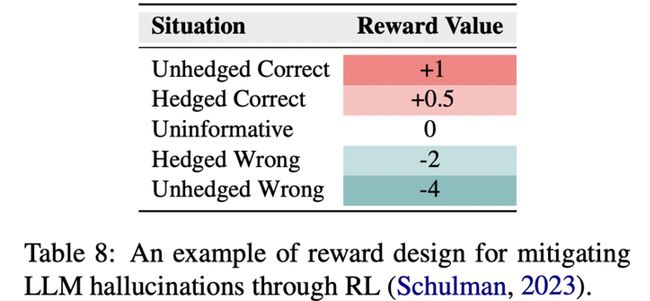
表中的每种情况如下:
- Unhedged Correct (未设防正确): 当LLM的回答是正确且没有保留的时,奖励值为+1。
- Hedged Correct (设防正确): 当LLM给出了一个正确但带有保留的回答时,奖励值为+0.5。
- Uninformative (无信息的): 当LLM的回答没有提供有用信息时,奖励值为0。
- Hedged Wrong (设防错误): 当LLM的回答是错误的但带有保留时,奖励值为-2。
- Unhedged Wrong (未设防错误): 当LLM的回答是错误的且没有保留时,奖励值为-4。
这个表格的目的是展示如何通过RL来调整LLMs的行为,鼓励它们给出正确的信息,并减少错误的信息。奖励值较高的情况会被模型视为更加理想的输出,因此模型在未来的行为中会更倾向于重复这些情况。相反,负的奖励值会使模型避免在未来的输出中重复相应的行为。这种方法旨在通过对正确和错误回答的不同“惩罚”和“奖励”,帮助模型学习如何减少幻觉现象。
推理阶段的缓解(Mitigation during Inference)
缓解策略
- 设计解码策略(Designing Decoding Strategies)
- 利用外部知识(Resorting to External Knowledge)
- 利用不确定性(Exploiting Uncertainty)
现在有两种使用外部知识减少LLMs在生成回应时的幻觉的方式,能够提高回答的准确性和可靠性

第一种方法是**“Generation-time Supplement” (生成时补充)*
- 用户提出查询(User Query)。
- 知识检索器(Knowledge Retriever)基于用户查询检索信息。
- 知识被传递给LLM。
- LLM结合检索的知识生成最终回应(Final Response)。
这个过程强调在生成回答之前先获取外部知识,确保LLM的回答基于最准确和最新的信息。
第二种方法是**“Post-hoc Correction” (事后修正)**:
- 用户提出查询。
- LLM直接生成中间回应(Intermediate Response)。
- 修正器(Fixer)使用外部知识源(如知识库、代码执行器和搜索引擎)对LLM的初步回答进行修正。
- 经过修正后得到最终回应。
这个过程强调在LLM生成回答之后再进行修正,利用外部知识源校正任何不准确或不相关的信息,减少幻觉现象。
LLMs处理复杂问题
下图展示了利用大型语言模型(LLMs)解决问题的四种不同方法
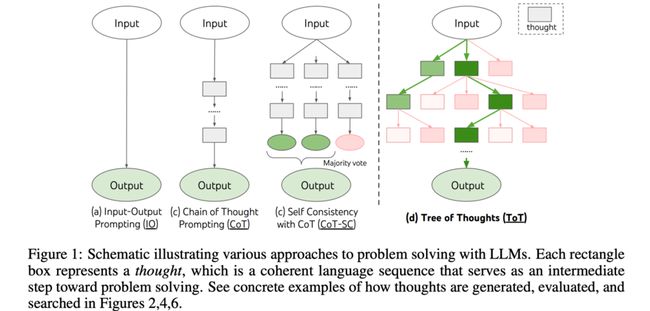
(a) Input-Output Prompting (IO): 这是最简单的方法,直接从输入到输出。
(b) Chain of Thought Prompting (CoT): 这种方法使用一系列中间步骤(或“思路”),这些步骤被串联起来导向最终的输出。
© Self Consistency with CoT (CoT-SC): 这种方法在CoT的基础上增加了自我一致性的检查,可能通过多次迭代和多数投票来确定最终的输出。
(d) Tree of Thoughts (ToT): 这个过程形成了一个思路的树,其中每个矩形代表一个“思路”,这是解决问题的一个中间步骤。在这个方法中,思路会被生成、评估,并搜索最佳路径以产生最终输出。图中的绿色和红色箭头代表了思路的评估过程,其中绿色代表正面评估,红色代表负面评估。
我们通过不同的策略引导LLMs以更加结构化和连贯的方式来解决复杂问题。这些方法有助于提高LLMs的输出质量,通过更详细的中间步骤来减少错误和提高逻辑连贯性。
RAG:检索增强生成(Retrieval Augmented Generation)
- RAG的概念:解释RAG的基本概念和功能。
- RAG的工作机制:介绍RAG如何结合检索步骤以获取正确的信息。
- 知识库的索引和使用:探讨如何利用知识库和嵌入(embeddings)来寻找最佳的知识片段。
下图是RAG的流程图,展示了使用预训练检索器和序列到序列模型(seq2seq model)的复合方法的原理:
-
Query Encoder:首先,用户的查询(比如一个问题或一个需验证的事实)通过一个查询编码器(Query Encoder)转换成一个查询向量(q(x))。这个查询编码器是预训练的。
-
Retriever:接着,使用最大内积搜索(Maximum Inner Product Search,MIPS)在一个非参数化的文档索引(Retriever p_n)中找到与查询向量相关度最高的文档(d(z))。这些文档包含了可能对回答查询有帮助的信息。
-
Generator:然后,选取的文档被送入一个参数化的生成器(Generator pθ),它是一个序列到序列模型。这个生成器利用查询向量和相关文档生成一个或多个可能的回答。
-
Marginlize:最后,模型将生成的回答进行边缘化(Marginlize),以得出最终预测(y)。这意味着,如果生成器产生了多个回答,模型会评估这些回答并选择最好的一个作为最终输出。

图中展示了RAG在不同任务上的应用,包括定义查询(Define “middle ear”),问题回答(Question Answering),事实验证(Fact Verification)和问题生成(Jeopardy Question Generation)。通过结合检索到的信息和生成器的预测能力,RAG旨在提高最终输出的质量和准确性。
- Define “middle ear”(定义“中耳”):
- 这是一个定义查询的例子。用户想要知道“中耳”是什么。在这个例子中,模型将利用检索器找到关于“中耳”的相关文档或信息,然后生成器基于这些信息生成定义。最终输出可能是“中耳包括鼓膜腔和三个听骨。”
- Barack Obama was born in Hawaii.(巴拉克·奥巴马出生在夏威夷。):
- 这是一个事实验证查询的例子。在这种情况下,用户提供了一个需要验证的陈述。RAG模型会检索相关文档来确认这个陈述是否正确。这个过程可能包括查找奥巴马的出生地信息,并最终生成一个支持该事实的标签,确认这个陈述是正确的。
- The Divine Comedy(《神曲》):
- 这是一个生成问题的例子,比如在智力竞赛节目“危险边缘”(Jeopardy)中使用的问题。在这个例子中,用户提供了一个答案(在这个节目中,参赛者是根据答案来提出问题的)。RAG模型将检索与“神曲”相关的信息,然后生成一个合适的问题。比如,生成器可能会生成这样一个问题:“这部14世纪的作品被分为三个部分:‘地狱’、‘炼狱’和‘天堂’”。
RAG的整个流程强调了端到端训练(End-to-End Training)的重要性,其中查询编码器和生成器都可以通过反向传播进行微调,以优化整个系统的性能。
下图详细说明了检索增强生成(Retrieval-Augmented Generation, RAG)的工作流程,包括三个主要阶段:索引(Indexing)、检索(Retrieval)和增强回答生成(Augmented Answer Generation)

-
索引(Indexing):
-
过程从
Loader开始,它负责从Knowledge Base加载文档。 -
接下来,
Splitter将加载的文档分割成更小的Document Snippets,以便更精确地检索信息。 -
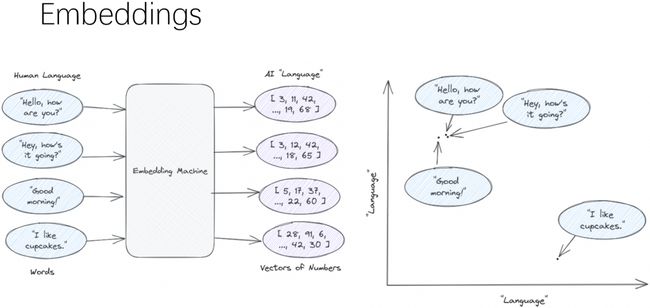
Embedding Machine对这些文档片段生成嵌入向量(Embeddings),这些嵌入向量是文档内容的数学表示。Embedding Machine会将单词或短语转换为代表其意义的高维空间中的点,意思相近的距离会更近
-
这些嵌入向量存储在
Vector Database中,方便后续检索。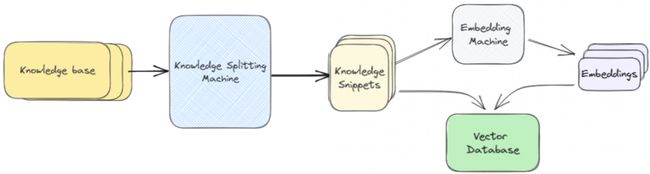
向量数据库(Vector Database): 存储嵌入向量的数据库,它允许快速的相似性查询。在RAG模型中,当用户提出查询时,模型会在这个数据库中查找与查询最相关的知识片段的向量表示
-
-
检索(Retrieval):
-
当用户提出一个问题时,该问题也通过
Embedding Machine转换成嵌入向量。
-
使用这个嵌入向量,在
Vector Database中执行“closeness”查询,以找到与用户问题内容最接近的Relevant Snippets。用户问题通过嵌入机器转换成向量,并且在
Vector Database中找到距离最近的知识片段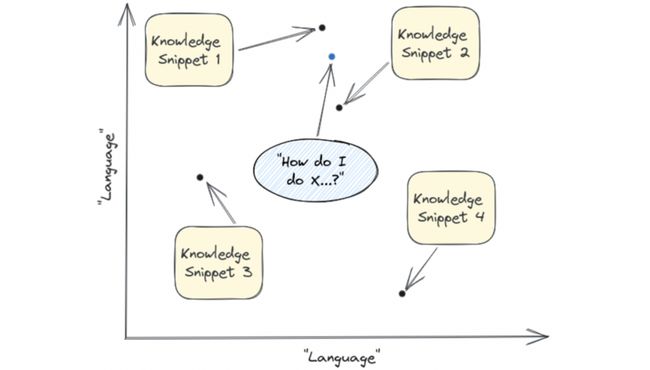
-
-
增强回答生成(Augmented Answer Generation):
- 检索到的相关片段被送入大型语言模型(LLM),LLM考虑这些相关片段生成对用户问题的回答。
- 通过这种方式,LLM能够利用额外的、特定于问题的信息来生成更准确、更相关的答案,而不仅仅是依赖它的预训练知识。
整个RAG的工作流程利用了两种类型的模型:一个是用于生成嵌入向量的Embedding Machine,另一个是用于生成答案的语言模型(LLM)。这种结合了检索和生成的方法使得模型在处理复杂查询时更加强大,尤其是在需要理解和引用外部信息源的情况下。
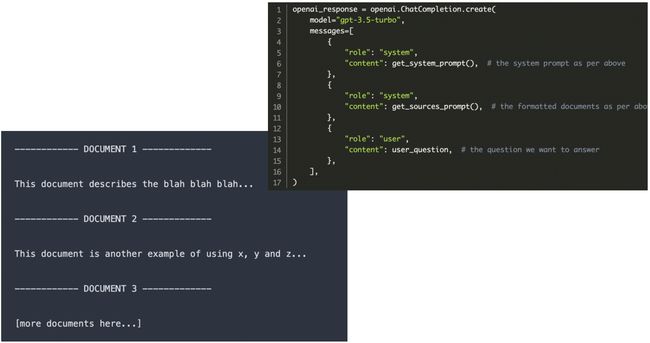
在实际的gpt-3.5-turbo的调用中,
messages数组包含了三个不同角色的信息:system、sources和user:
system角色提供了一个或多个提示(prompts),这可能包括了模型生成回答前需要的任何上下文或指示。sources角色包含了格式化的文档,这些文档可能是从知识库中检索到的,并被预处理为模型可以理解和使用的格式。user角色包含了实际的问题,这是想要得到答案的查询。
这个流程模拟了RAG模型的工作方式,其中语言模型不仅依赖内建的知识库,还结合了外部文档来生成回答。在实际应用中,系统可以使用这样的代码结构来执行RAG的检索步骤,将检索到的信息以及用户的问题输入到语言模型中,然后生成增强的回答。
RLHF:Reinforcement Learning from Human Feedback 基于人类反馈的强化学习
- InstructGPT的介绍:解释InstructGPT的概念和用途。
- 预训练语言模型(Pretraining Language Models):探讨在预训练阶段为RLHF做准备的步骤。
- 奖励模型训练(Reward Model Training):介绍如何训练奖励模型来映射输入文本到标量奖励。
- 使用奖励模型的RL微调(RL Fine-tuning with a Reward Model):详细说明如何利用奖励模型进行微调。
利用人类反馈进行强化学习(RLHF)优化一个语言模型输出的过程有如下三步:
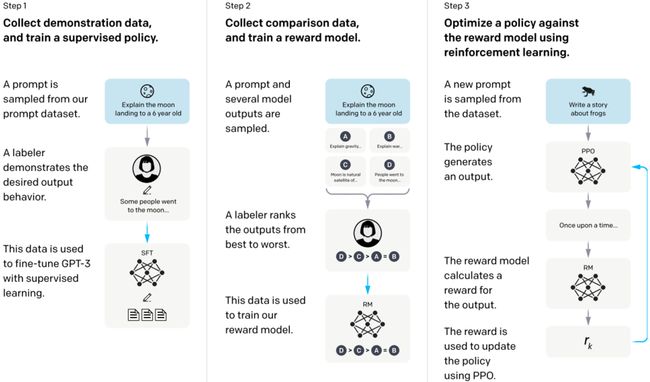
- 收集演示数据,并训练一个监督策略:
- 从数据集中抽取一个提示,例如“向六岁小孩解释月球登陆”。
- 标注者(labeler)提供了期望的输出行为,比如一个简单且易于理解的解释。
- 这些演示数据被用来通过监督学习微调GPT-3模型,让模型学会生成类似的回答。
- 收集比较数据,并训练一个奖励模型:
- 采样一个提示并生成多个模型输出,输出示例可能是关于月球登陆的不同解释。
- 标注者对这些输出按照质量从最好到最差进行排序。
- 这些排序数据用来训练奖励模型,奖励模型能够对输出的质量进行评分。
- 使用强化学习根据奖励模型优化策略:
- 从数据集中抽取一个新的提示,如“写一个关于青蛙的故事”。
- 策略生成输出,例如一个有关青蛙的故事。
- 奖励模型基于输出计算奖励值。
- 这个奖励被用来通过算法(例如PPO, Proximal Policy Optimization)更新策略,以改善模型未来的输出。
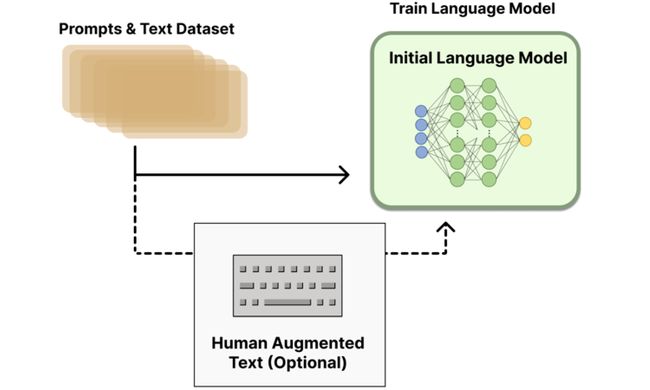
Pretraining language models
-
提示与文本数据集(Prompts & Text Dataset):这部分代表训练语言模型所需的数据,包括各种文本提示和相应的文本样本。
-
初始语言模型训练(Train Language Model):这显示了使用上述数据集对初始语言模型进行训练的过程。模型的训练旨在理解和生成自然语言。
-
人类增强文本(Human Augmented Text)(可选):这是一个可选步骤,表示除了已有的数据集之外,还可以加入由人类编写的高质量文本。这些文本可能用于提供更复杂或更多样化的示例,帮助模型学习更丰富的语言表达
Optional step:
- Pay humans to write responses to existing prompts($$$)
- Considered high quality initialization for RLHF
Supervised Fine Tuning (SFT):使用上述人类编写的响应对模型进行监督式微调。目的是根据人类编写的高质量响应来调整模型的预测,使其能够产生更准确、更符合用户期望的输出。
Reward model training
这张图描述了强化学习从人类反馈(RLHF)流程中的奖励模型训练部分。图中展示了从数据集采样、初始语言模型的使用,以及如何依靠人类评分来训练一个奖励模型。以下是详细步骤:
-
提示数据集(Prompts Dataset): 包含用于训练的不同文本提示。这些提示是奖励模型训练的起点,通常特定于模型将要执行的任务。
-
初始语言模型(Initial Language Model): 这表示一个已经预训练的语言模型,它可以生成基于提示的文本输出。
-
生成文本(Generated text): 根据提示数据集,初始语言模型会生成多个文本输出。
-
人类评分(Human Scoring): 接下来,人类评价者会对这些文本输出进行评分,根据质量对它们进行排序,如使用ELO评分系统等。
-
奖励(偏好)模型(Reward (Preference) Model): 评分数据用于训练一个奖励模型,这个模型的目标是能够将输入文本映射到一个标量奖励值。这意味着奖励模型可以根据输入的文本评估其质量,并给出一个数值奖励。
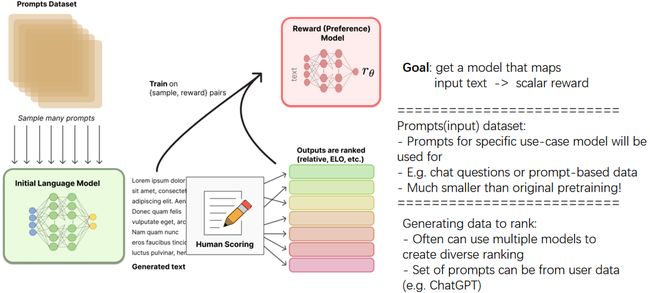
- 目标(Goal): 训练出一个能够将输入文本映射到一个标量奖励的模型。
- 提示(input)数据集: 这些提示是为特定用例模型准备的,并且是原始预训练数据集的一个子集,可能是聊天问题或基于提示的数据。
- 生成数据排名(Generating data to rank): 可以使用多个模型生成不同的排名以增加多样性,提示集可以来源于用户数据(例如ChatGPT)。
loss函数
在Reward model training中,loss函数如下定义
l o s s ( θ ) = − E ( x , y j , y k ) ∼ D [ l o g ( σ ( r θ ( x , y j ) − r θ ( x , y k ) ) ) ] loss(\theta) = -E_{(x,y_j,y_k)\sim D}[log(\sigma(r_\theta(x, y_j) - r_\theta (x,y_k)))] loss(θ)=−E(x,yj,yk)∼D[log(σ(rθ(x,yj)−rθ(x,yk)))]
该公式描述了一个用于优化奖励模型参数的损失函数。这里的损失函数是预期的对数损失,用于对比两个输出 y_j和y_k的奖励预测r_θ。
θ:奖励模型的参数。E(x,y_j,y_k)~D:期望是在数据分布D上计算的,这个分布包括输入x和一对输出y_j和y_k。σ:Sigmoid函数,它将实数映射到(0, 1)区间,通常用于二分类问题中。r_θ(x, y_j)和r_θ(x, y_k):奖励模型对于给定输入x和输出y_j或y_k的奖励预测。
损失函数的目标是最大化正确输出相对于不正确输出的对数概率。换句话说,如果y_j是比y_k更好的输出(基于人类评价),那么奖励模型应该给y_j一个更高的奖励预测值。
loss函数的代码实现如下
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(inputs_ids=inputs["inputs_ids_j"], attention_mask=inputs["attention_mask_j"])
rewards_k = model(inputs_ids=inputs["inputs_ids_k"], attention_mask=inputs["attention_mask_k"])
loss = -nn.functional.logsigmoid(reward_j - reward_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return loss
我们定义了一个类 RewardTrainer,它继承自 Trainer 类,其中包含一个方法 compute_loss 用于计算上述损失函数。
compute_loss方法接收模型和输入,不返回模型输出(return_outputs=False)。model(input_ids_j, attention_mask_j)和model(input_ids_k, attention_mask_k)分别计算对应于输入j和k的奖励值。loss计算两个奖励值的对数sigmoid差的均值,这与上面的损失函数公式相匹配。
if return_outputs: 条件判断是否需要返回模型输出。如果是,那么除了返回损失值外,还会返回每个输入的奖励值。
Fine-tuning with RL
这张图展示了使用强化学习(RL)进行微调(Fine-tuning)的过程,它结合了奖励模型和KL散度(Kullback-Leibler divergence)来优化语言模型的策略
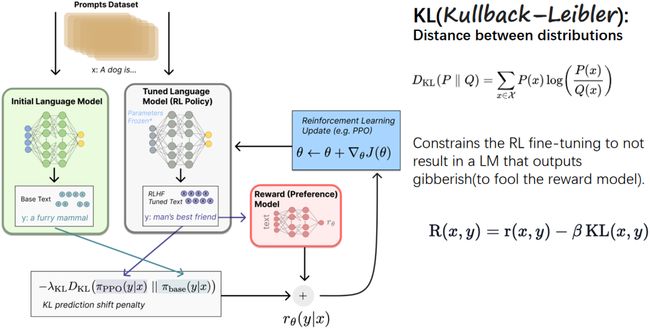
-
初始语言模型(Initial Language Model):我们从一个训练过的初始语言模型开始。这个模型已经能够生成基础的文本。例如,对于提示“a dog is”,它可能生成“a furry mammal”,这是一个准确的描述。
-
调整语言模型(Tuned Language Model (RL Policy)):通过强化学习,特别是通过一种称为PPO(Proximal Policy Optimization)的算法,语言模型得到了微调,以生成更符合特定目标的文本。例如,对于同样的提示,“a dog is”,经过微调的模型可能会生成“man’s best friend”,这是一个更具情感色彩和人类视角的描述。
-
奖励(偏好)模型(Reward (Preference) Model):奖励模型用来评估生成文本的质量,并给出一个奖励值。这个模型基于之前的反馈学习判断哪些输出是优质的。
-
KL散度(KL Divergence):KL散度是一个衡量两个概率分布差异的指标。在这个上下文中,它被用来确保微调过程不会导致语言模型生成无意义的内容(gibberish),即避免愚弄奖励模型。通过这个机制,模型被约束在生成有意义的、与初始模型的输出相似度较高的文本。
D K L ( P ∥ Q ) = ∑ x ∈ X P ( x ) log ( P ( x ) Q ( x ) ) D_{KL}(P \parallel Q) = \sum_{x \in \mathcal{X}} P(x) \log\left(\frac{P(x)}{Q(x)}\right) DKL(P∥Q)=x∈X∑P(x)log(Q(x)P(x))
其中P和Q是两个概率分布,x是事件的集合。
-
最终的奖励函数(Final Reward Function):
R ( x , y ) = r ( x , y ) − β K L ( x , y ) R(x, y) = r(x, y) - \beta KL(x, y) R(x,y)=r(x,y)−βKL(x,y)
这个函数结合了奖励模型给出的奖励值r(x,y)和KL散度项KL(x,y)。这样做的目的是在奖励生成好的回答的同时,通过KL项惩罚那些偏离初始模型行为太多的输出。参数β控制了KL散度项的权重。
在图中的流程示例中,初始模型生成了基本的描述“a furry mammal”,而细调后的模型生成了更具情感色彩的“man’s best friend”。然后,这些生成的文本被奖励模型评估,同时考虑到它们与初始模型的偏差(通过KL散度)。最终,这个综合考虑了奖励和KL散度的函数用来更新语言模型的参数,以生成更优质的文本。
总结一下使用强化学习(Reinforcement Learning, RL)来优化语言模型(LM)的过程
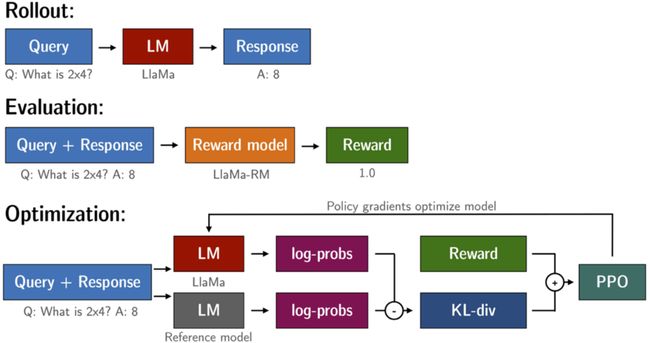
-
Rollout:首先,有一个查询(Query),比如一个数学问题“2x4是多少?”(Q: What is 2x4?)。这个查询被输入到语言模型(例如LaMa),语言模型产生一个回应(Response),比如“8”(A: 8)。
-
Evaluation:接着,这个查询和它的响应一起被用来评估。它们被送入奖励模型(例如LaMa-RM),奖励模型会评估这个回应的质量,并给出一个奖励(Reward),在这个例子中是1.0。这意味着模型生成的回答是正确的。
-
Optimization:最后,优化过程开始。查询和响应再次被输入到语言模型,产生log-probabilities(log-probs),这是模型评估每个可能输出概率的对数值。同时,有一个参考模型(Reference model),它也产生对同一输出的log-probs。这两个log-probs被用来计算KL散度(KL-div),它是两个概率分布之间差异的度量。
然后,通过策略梯度方法(如PPO算法)结合奖励和KL散度来优化模型。PPO会推动模型产生高奖励的回应,同时通过KL散度来保证生成的回应不会偏离原始模型太远,以防止模型学到产生无意义的输出。
在这个特定的例子中,“2x4”问题的正确回答“8”被奖励模型评估为正面的,这将被用来通过RL进一步优化语言模型,使其更可能在未来产生正确的答案。
TRL微调实战
https://github.com/huggingface/trl
import torch
from tqdm import tqdm
import pandas as pd
tqdm.pandas()
from transformers import pipeline, AutoTokenizer
from datasets import load_dataset
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
from trl.core import LengthSampler
Configuration
config = PPOConfig(
model_name="lvwerra/gpt2-imdb",
learning_rate=1.41e-5,
log_with="wandb",
)
sent_kwargs = {"return_all_scores": True, "function_to_apply": "none", "batch_size": 16}
import wandb
wandb.init()
You can see that we load a GPT2 model called gpt2_imdb. This model was additionally fine-tuned on the IMDB dataset for 1 epoch with the huggingface script (no special settings). The other parameters are mostly taken from the original paper “Fine-Tuning Language Models from Human Preferences”. This model as well as the BERT model is available in the Huggingface model zoo here. The following code should automatically download the models.
Load data and models
Load IMDB dataset
The IMDB dataset contains 50k movie review annotated with “positive”/“negative” feedback indicating the sentiment. We load the IMDB dataset into a DataFrame and filter for comments that are at least 200 characters. Then we tokenize each text and cut it to random size with the LengthSampler.
model_name = '../../gpt2-imdb/'
dataset_name = '../../imdb/'
# 由于huggingface国内被墙,我这里采用本地加载
def build_dataset(model_name = '../../gpt2-imdb/', dataset_name="../../imdb/", input_min_text_length=2, input_max_text_length=8):
"""
Build dataset for training. This builds the dataset from `load_dataset`, one should
customize this function to train the model on its own dataset.
Args:
dataset_name (`str`):
The name of the dataset to be loaded.
Returns:
dataloader (`torch.utils.data.DataLoader`):
The dataloader for the dataset.
"""
# 加载预训练模型的 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置 pad token 为 eos token
# 加载 IMDb 数据集
ds = load_dataset(dataset_name, split="train") # 加载数据集,这里数据集已在本地
ds = ds.rename_columns({"text": "review"}) # 重命名列名 'text' 为 'review'
ds = ds.filter(lambda x: len(x["review"]) > 200, batched=False) # 过滤,只保留长度超过200的评论
# 随机选择输入文本的长度
input_size = LengthSampler(input_min_text_length, input_max_text_length)
def tokenize(sample):
# 对样本进行分词
sample["input_ids"] = tokenizer.encode(sample["review"])[: input_size()]
sample["query"] = tokenizer.decode(sample["input_ids"])
return sample
# 对数据集应用分词函数
ds = ds.map(tokenize, batched=False)
ds.set_format(type="torch") # 设置数据集格式为 PyTorch
return ds
# 创建数据集
dataset = build_dataset()
def collator(data):
# 数据整合器,用于整合批次数据
return dict((key, [d[key] for d in data]) for key in data[0])
dataset
### Output:
### Dataset({
### features: ['review', 'label', 'input_ids', 'query'],
### num_rows: 24895
### })
Load pre-trained GPT2 language models
We load the GPT2 model with a value head and the tokenizer. We load the model twice; the first model is optimized while the second model serves as a reference to calculate the KL-divergence from the starting point. This serves as an additional reward signal in the PPO training to make sure the optimized model does not deviate too much from the original language model.
# 加载预训练的因果语言模型(含价值头)
model = AutoModelForCausalLMWithValueHead.from_pretrained(model_name)
# 加载参考模型
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained(model_name)
# 加载 tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # 设置 pad token 为 eos token
Initialize PPOTrainer
The PPOTrainer takes care of device placement and optimization later on:
# 创建 PPO 训练器
ppo_trainer = PPOTrainer(config, model, ref_model, tokenizer, dataset=dataset, data_collator=collator)
Load BERT classifier
We load a BERT classifier fine-tuned on the IMDB dataset.
device = ppo_trainer.accelerator.device
if ppo_trainer.accelerator.num_processes == 1:
device = 0 if torch.cuda.is_available() else "cpu" # to avoid a `pipeline` bug
sentiment_pipe = pipeline("sentiment-analysis", model="../../distilbert-imdb", device=device)
The model outputs are the logits for the negative and positive class. We will use the logits for positive class as a reward signal for the language model.
text = "this movie was really bad!!" sentiment_pipe(text, **sent_kwargs) ### Output: ### [[{'label': 'NEGATIVE', 'score': 2.3350484371185303}, ### {'label': 'POSITIVE', 'score': -2.726576566696167}]]text = "this movie was really good!!" sentiment_pipe(text, **sent_kwargs) ### Output: ### [[{'label': 'NEGATIVE', 'score': -2.294790029525757}, ### {'label': 'POSITIVE', 'score': 2.557040214538574}]]
Generation settings
For the response generation we just use sampling and make sure top-k and nucleus sampling are turned off as well as a minimal length.
gen_kwargs = {
"min_length": -1, # 设置生成文本的最小长度。这里设置为-1可能表示不设置最小长度限制。
"top_k": 0.0, # Top-K 采样的K值。设置为0表示不使用 Top-K 采样。
"top_p": 1.0, # 核采样(Nucleus Sampling)的P值。设置为1表示包含全部词汇,即不使用核采样。
"do_sample": True, # 设置为True表示在生成时进行随机采样。这使得生成的文本更具随机性和多样性。
"pad_token_id": tokenizer.eos_token_id # 设置填充(padding)标记的ID。这里将其设置为结束符(EOS)的ID。
}
Optimal model
Training loop
The training loop consists of the following main steps:
- Get the query responses from the policy network (GPT-2)
- Get sentiments for query/responses from BERT
- Optimize policy with PPO using the (query, response, reward) triplet
Training time
This step takes 2h on a V100 GPU with the above specified settings.
# 设置生成文本的最小和最大长度
output_min_length = 4
output_max_length = 16
output_length_sampler = LengthSampler(output_min_length, output_max_length)
# 配置生成文本的参数
generation_kwargs = {
"min_length": -1, # 最小长度设置为 -1,表示不限制
"top_k": 0.0, # 不使用 Top-K 采样
"top_p": 1.0, # 不使用核采样
"do_sample": True, # 使用随机采样
"pad_token_id": tokenizer.eos_token_id, # 填充标记 ID 设置为 EOS
}
# 训练循环
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
query_tensors = batch["input_ids"] # 获取查询的张量表示
# 用gpt2生成响应
response_tensors = []
for query in query_tensors:
gen_len = output_length_sampler() # 根据采样器确定生成长度
generation_kwargs["max_new_tokens"] = gen_len # 设置最大生成令牌数
response = ppo_trainer.generate(query, **generation_kwargs) # 生成响应
response_tensors.append(response.squeeze()[-gen_len:]) # 取生成的最后 gen_len 个令牌
batch["response"] = [tokenizer.decode(r.squeeze()) for r in response_tensors] # 解码响应
# 计算奖励(例如情感得分)
texts = [q + r for q, r in zip(batch["query"], batch["response"])] # 组合查询和响应
pipe_outputs = sentiment_pipe(texts, **sent_kwargs) # 计算情感分数
rewards = [torch.tensor(output[1]["score"]) for output in pipe_outputs] # 提取分数作为奖励
# 执行 PPO 步骤
stats = ppo_trainer.step(query_tensors, response_tensors, rewards) # 执行 PPO 更新
ppo_trainer.log_stats(stats, batch, rewards) # 记录统计信息
response = ppo_trainer.generate(query, **generation_kwargs) # 生成响应
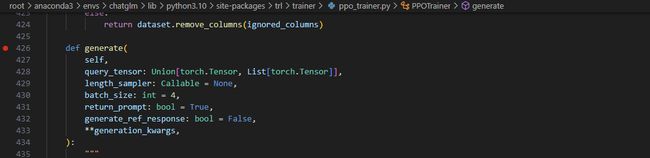
def generate( self, query_tensor: Union[torch.Tensor, List[torch.Tensor]], # 查询张量或张量列表 length_sampler: Callable = None, # 用于决定生成文本长度的可调用对象 batch_size: int = 4, # 批处理大小 return_prompt: bool = True, # 是否返回原始查询文本 generate_ref_response: bool = False, # 是否生成参考响应 **generation_kwargs, # 生成函数的其他参数 ): # 如果需要生成参考响应 if generate_ref_response: # 选择合适的模型进行生成(根据是否是 PEFT 模型) ref_model = self.model if self.is_peft_model else self.ref_model # 如果 query_tensor 是一个列表(处理多个查询) if isinstance(query_tensor, List): # 调用 _generate_batched 生成响应 response = self._generate_batched( self.model, query_tensor, length_sampler=length_sampler, batch_size=batch_size, return_prompt=return_prompt, **generation_kwargs, ) # 如果需要生成参考响应 if generate_ref_response: with self.optional_peft_ctx(): ref_response = self._generate_batched( ref_model, query_tensor, length_sampler=length_sampler, batch_size=batch_size, return_prompt=return_prompt, **generation_kwargs, ) else: # 如果 query_tensor 是单个张量 if len(query_tensor.shape) == 2: raise ValueError( "query_tensor must be a tensor of shape (`seq_len`) or a list of tensors of shape (`seq_len`)" ) # 设置生成长度 if length_sampler is not None: generation_kwargs["max_new_tokens"] = length_sampler() # 生成响应 response = self.accelerator.unwrap_model(self.model).generate( input_ids=query_tensor.unsqueeze(dim=0), **generation_kwargs ) # 生成参考响应(如果需要) if generate_ref_response: with self.optional_peft_ctx(): ref_response = ref_model.generate(input_ids=query_tensor.unsqueeze(dim=0), **generation_kwargs) # 如果不需要返回原始查询文本 if not return_prompt and not self.is_encoder_decoder: response = response[:, query_tensor.shape[0] :] if generate_ref_response: ref_response = ref_response[:, query_tensor.shape[0] :] # 返回生成的响应,如果需要,也返回参考响应 if generate_ref_response: return response, ref_response return responsestats = ppo_trainer.step(query_tensors, response_tensors, rewards) # 执行 PPO 更新
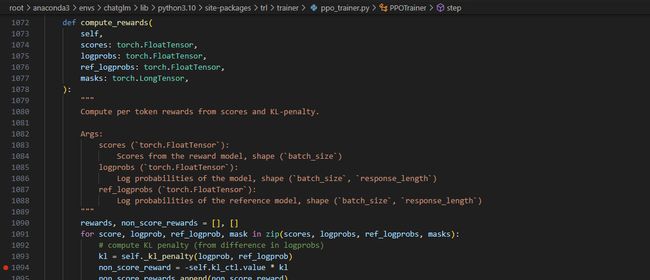
def step(self, queries, responses, scores, response_masks=None): # 初始化批处理大小 bs = self.config.batch_size # 检查输入数据的一致性 queries, responses, scores, response_masks = self._step_safety_checker( bs, queries, responses, scores, response_masks ) scores = torch.tensor(scores, device=self.current_device) # 如果使用分数缩放 if self.config.use_score_scaling: ... # 标准化分数 ... if self.config.score_clip is not None: # 对分数进行裁剪 ... # 准备数据输入 model_inputs = self.prepare_model_inputs(queries, responses) # 执行前向传播,获取模型和参考模型的输出 with torch.no_grad(): all_logprobs, logits_or_none, values, masks = self.batched_forward_pass( self.model, ... ) with self.optional_peft_ctx(): ref_logprobs, ref_logits_or_none, _, _ = self.batched_forward_pass( self.model if self.is_peft_model else self.ref_model, ... ) # 计算奖励和优势(Advantages) with torch.no_grad(): ... rewards, non_score_reward = self.compute_rewards(...) ... values, advantages, returns = self.compute_advantages(values, rewards, masks) # 准备训练数据 batch_dict = { ... } batch_dict.update(model_inputs) # 执行 PPO 训练的多个迭代 all_stats = [] early_stop = False for _ in range(self.config.ppo_epochs): if early_stop: break ... for backward_batch_start in range(0, bs, self.config.backward_batch_size): ... for mini_batch_start in range(0, self.config.backward_batch_size, self.config.mini_batch_size): ... # 对每个小批量进行训练 with self.accelerator.accumulate(self.model): ... train_stats = self.train_minibatch(...) # 检查是否需要提前停止训练 if self.config.early_stopping: ... # 收集和汇总训练统计信息 train_stats = stack_dicts(all_stats) stats = self.record_step_stats(...) if self.is_distributed: stats = self.gather_stats(stats) stats = stats_to_np(stats) # 更新 KL 散度控制器 self.kl_ctl.update(stats["objective/kl"], ...) # 更新学习率 if self.lr_scheduler is not None: self.lr_scheduler.step() return statsrewards, non_score_reward = self.compute_rewards(…)
def compute_rewards(self, scores, logprobs, ref_logprobs, masks): """ Args: scores (torch.FloatTensor): 从奖励模型得到的分数,形状为 (batch_size)。 logprobs (torch.FloatTensor): 模型的对数概率,形状为 (batch_size, response_length)。 ref_logprobs (torch.FloatTensor): 参考模型的对数概率,形状为 (batch_size, response_length)。 masks (torch.LongTensor): 掩码,用于标识响应中的有效标记。 """ rewards, non_score_rewards = [], [] for score, logprob, ref_logprob, mask in zip(scores, logprobs, ref_logprobs, masks): # 计算 KL 惩罚(基于对数概率的差异) kl = self._kl_penalty(logprob, ref_logprob) non_score_reward = -self.kl_ctl.value * kl non_score_rewards.append(non_score_reward) reward = non_score_reward.clone() last_non_masked_index = mask.nonzero()[-1] # 奖励是偏好模型分数加上 KL 惩罚 reward[last_non_masked_index] += score rewards.append(reward) return torch.stack(rewards), torch.stack(non_score_rewards)在这个函数中,每个响应的奖励由两部分组成:
- 非分数奖励(non_score_reward):这部分是基于模型生成的对数概率和参考模型生成的对数概率之间的 KL 散度计算的。KL 散度表示两个概率分布之间的差异,这里用来衡量模型输出和参考输出之间的差异。
- 总奖励(reward):在非分数奖励的基础上,将偏好模型(如情感分析模型或其他评估模型)给出的分数加到最后一个非掩码标记的奖励上。这样,奖励既考虑了模型生成与参考生成的一致性,又考虑了响应的整体质量。
这个函数的输出是一个奖励张量,它将用于 PPO 训练过程中,以指导模型学习生成更高质量的文本。

Training progress
If you are tracking the training progress with Weights&Biases you should see a plot similar to the one below. Check out the interactive sample report on wandb.ai: link.

Figure: Reward mean and distribution evolution during training.
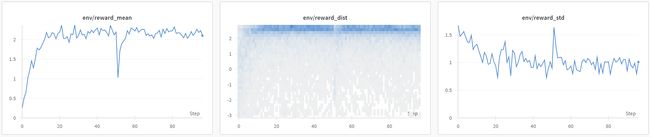
One can observe how the model starts to generate more positive outputs after a few optimisation steps.
Note: Investigating the KL-divergence will probably show that at this point the model has not converged to the target KL-divergence, yet. To get there would require longer training or starting with a higher initial coefficient.
Model inspection
Let’s inspect some examples from the IMDB dataset. We can use model_ref to compare the tuned model model against the model before optimisation.
# 设置批次大小
bs = 16
game_data = dict()
dataset.set_format("pandas")
df_batch = dataset[:].sample(bs) # 从数据集中随机抽取一个批次的数据
game_data["query"] = df_batch["query"].tolist() # 获取查询文本
query_tensors = df_batch["input_ids"].tolist() # 获取查询的张量表示
response_tensors_ref, response_tensors = [], []
# 对每个查询生成响应
for i in range(bs):
gen_len = output_length_sampler() # 确定生成响应的长度
# 使用参考模型生成响应
output = ref_model.generate(
torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device), max_new_tokens=gen_len, **gen_kwargs
).squeeze()[-gen_len:]
response_tensors_ref.append(output)
# 使用当前模型生成响应
output = model.generate(
torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device), max_new_tokens=gen_len, **gen_kwargs
).squeeze()[-gen_len:]
response_tensors.append(output)
# 解码生成的响应
game_data["response (before)"] = [tokenizer.decode(response_tensors_ref[i]) for i in range(bs)]
game_data["response (after)"] = [tokenizer.decode(response_tensors[i]) for i in range(bs)]
# 进行情感分析
# 情感分析查询和参考模型的响应组合
texts = [q + r for q, r in zip(game_data["query"], game_data["response (before)"])]
game_data["rewards (before)"] = [output[1]["score"] for output in sentiment_pipe(texts, **sent_kwargs)]
# 情感分析查询和当前模型的响应组合
texts = [q + r for q, r in zip(game_data["query"], game_data["response (after)"])]
game_data["rewards (after)"] = [output[1]["score"] for output in sentiment_pipe(texts, **sent_kwargs)]
# 将结果存储到数据框架中
df_results = pd.DataFrame(game_data)
df_results

Looking at the reward mean/median of the generated sequences we observe a significant difference.
print("mean:")
display(df_results[["rewards (before)", "rewards (after)"]].mean())
print()
print("median:")
display(df_results[["rewards (before)", "rewards (after)"]].median())
### Output:
### mean:
### rewards (before) 1.026937
### rewards (after) 1.958725
### dtype: float64
###
### median:
### rewards (before) 0.869565
### rewards (after) 2.554209
### dtype: float64
Save model
Finally, we save the model and push it to the Hugging Face for later usage.
model.save_pretrained("gpt2-imdb-pos-v2")
tokenizer.save_pretrained("gpt2-imdb-pos-v2")