BP神经网络
BP神经网络概述
BP神经网络即误差反馈神经网络算法。无需事先确定输入输出之间映射关系的数学方程,仅通过自身的训练,学习某种规则,在给定输入值时得到最接近期望输出值的结果。它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方差为最小。包括信号的正向传播和误差的反向传播两个过程,即计算机误差输出时按从输入到输出的方向进行,从而调整权重和阈值时按从输出到输入的方向进行。
通俗的讲,BP神经网络模型就是模型加上一个误差修正的函数,每一次的训练得到的结果与真实结果进行比较,从而修改权值和阈值两个参数,从而趋于跟真实结果一样。
举个例子
你在饭店吃了一个菜后觉得好吃,然后回家想自己把这个菜做出来,但是你一开始做出来的菜跟你在饭店实际上吃的菜的味道差很多,你就开始改变你的做法,比如说第一次做感觉比饭店的咸了,你就少放点盐,第二次做感觉比饭店的甜了,你就少放点糖。从而进行一步步尝试,最终做出来的菜跟饭店的菜味道差不多相似。
单个神经元介绍

树突是自神经元胞体伸出的较短而分支多的突起。树突接受来自其他神经元的冲动,因此它的分布范围可代表该神经元接受刺激的范围。树突内所含细胞器与神经元胞体相似。树突的分支上有树突棘或叫树突小芽, 与其他神经元末梢形成突触。
轴突在近终末处反复分支,末端在中枢内可形成终扣或终足,与另一神经元的表面形成突触,在周围部可终于各种类型的神经末梢器官。轴突传递自神经元发出的冲动。
突触是指一个神经元的冲动传到另一个神经元或传到另一细胞间的相互接触的结构。 突触是神经元之间在功能上发生联系的部位,也是信息传递的关键部位。突触与其他神经元的树突相连,当兴奋达到一定阈值时,突触前膜向突触间隙释放神经传递的化学物质,实现神经元之间的信息传递。人工神经网络中的神经元就是模仿了生物神经元这一特性,利用激活函数将输入结果映射到一定范围,若映射的结果大于阈值,则神经元被激活。
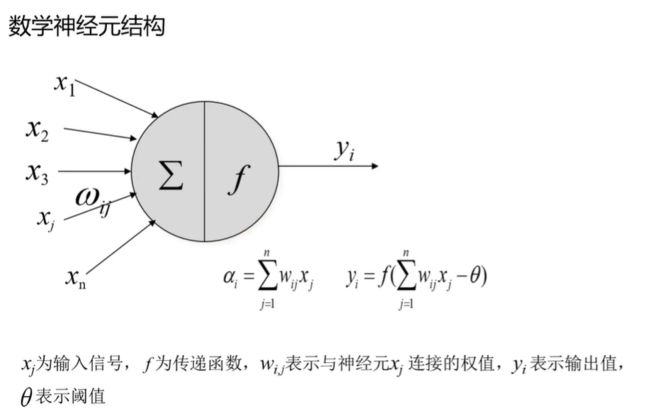
生物神经元会接受到很多的刺激,而在人工神经网络当中,这些刺激可以当作是样本的输入或则和是自变量,用x表达,一个样本可能有多个x,也就是有多个自变量,所以神经元是有多个输入的。在数字神经元当中,传输进来的输入并不是直接进行相加的,是有个加权的操作,它会对每个输入加一个权值,权值有w表示,加权求和后就会得到一个神经元,i表示第i个神经元,得到的神经元会减去一个阈值,减去阈值之后会把结果放到一个激活函数f当中去,通过这个激活函数操作,就会产生输出,这个输出就是单个神经元的输出,单个神经元的输出会继续往下传递,要么传送给下一次的神经元细胞,要么直接输出,成为神经网络的输出。
网络结构介绍
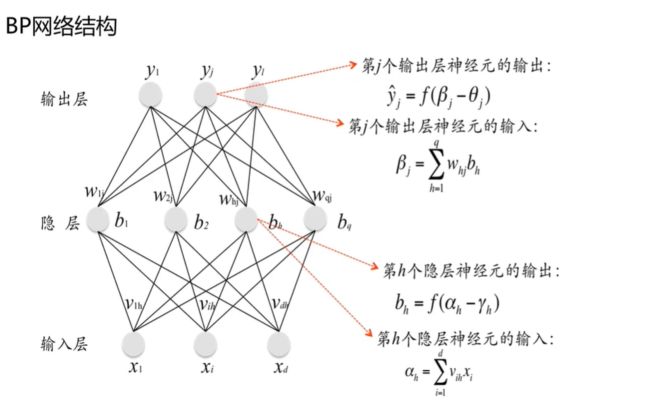
上述神经网络分为了输入层,隐层和输出层三层。
输入层其实就是将样本的输入值传送给各个隐层,输入层不会对输入值做任何的处理。
每个隐层的神经元都会接受输入层的所有输入,隐层接受输入层的所有输入后,隐层的操作就跟上述单个神经元的操作是一样的,进行加权求和的操作,求和后会减去一个阈值,再把得到的结果放到激活函数当中去,得到一个输出,然后会把这个输出给到所有的输出层。
输出层的操作跟隐层类似,输出的的输入就是所有的隐层的输出,输出层会接受隐层的所有输入后,同样会进行加权求和后减去阈值,使用激活函数进行输出,对于上述神经网络而言,输出层的输出就是整个神经网络的输出。
整个神经网络由输出层的阈值,输出层的神经元的权重,隐层的阈值,隐层神经元的权重和激活函数来决定的。
梯度下降法
梯度下降法是一个一阶最优化算法,通常也称为最速下降法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。
举个例子,就是一个人想要下山,但是他的可见度很差,并不能一眼看到下山的道路,要想下山的距离变快或者最短,所走的道路就是越陡峭越好,刚好这个人具有能看到当前范围中最陡峭方向的能力,所以他每次都会选择最陡峭的方向进行下山,每走一段距离进行一次测量,直到走下山。
既然神经网络由输出层的阈值,输出层的神经元的权重,隐层的阈值,隐层神经元的权重和激活函数来决定的。为了是预测值不断接近真实值,需要调整输出层的阈值,输出层的神经元的权重,隐层的阈值,隐层神经元的权重这四个值。一开始四个值都是随机值。
先构造一个误差比较的公式

当E=0的时候,误差为0。
对该公式进行求偏导

再选取一个激活函数

接下来就可以对四个参数进行调整。
调整公式结果为




其中 为学习速率,也是步长系数,意思是移动的范围,步长越大,学习速度越快,但是可能会错过最优的解法,从而影响精度,步长越小,学习速度越慢,但会减少错过最优解法的可能性。
为学习速率,也是步长系数,意思是移动的范围,步长越大,学习速度越快,但是可能会错过最优的解法,从而影响精度,步长越小,学习速度越慢,但会减少错过最优解法的可能性。
公式计算结果为
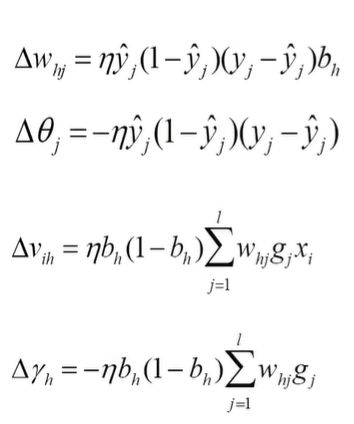
其中g为

网络训练过程
输入训练集数据,学习速率
然后开始循环四步:根据网络输入和当前的参数计算输出,计算输出层梯度,计算隐层梯度,更新权值和阈值。
直到样本输出满足标准,又或者训练轮数达到了最大值,最后输出权值和阈值。
权值和阈值时网络的核心,虽然激活函数也影响网络,但是激活函数时提前指定好的,不会发生变化的,所以网络训练的目的就是找到最佳的权值和阈值。
常用激活函数
sigmoid函数,是很常见的激活函数,sigmoid函数也叫Logistic函数,用于隐藏层的输出,输出在(0,1)之间,它可以将一个实数映射到(0,1)的范围内,可以用来做二分类。表达式为
![]()
双曲正切函数,也称为tanh函数,取值范围为[-1,1],双曲正切函数在特征相差明显的时候效果会好,在循环过程中,会不断的扩大特征效果,常用作隐层单元。表达式为
![]()
线性整流函数,也成为relu函数,更常用来处理隐含层,rule函数可以生成大而且平滑的梯度,有助于梯度学习,表达式为
![]()
BP神经网络的优缺点
优点:
1.具有较强的非线性映射能力。
2.具有高度自学习和自适应的能力。
3.具有将学习成果应用于新知识的能力,很好的泛化能力。
4.具有一定的容错能力。
缺点:
1.容易使算法陷入局部极值,权值收敛到局部极小点,从而训练失败。
2.收敛速度慢。
3.神经网络难以解决应用问题的实例规模和网络规模间的矛盾问题,其涉及到网络容量的可能性与可行性的关系问题,即学习复杂性问题。
BP神经网络代码
from sklearn.neural_network import MLPClassifier #MLPClassifier为分类器,MLPRegressor为回归器
clf = MLPClassifier(hidden_layer_sizes=(10,),learning_rate_init=0.1,max_iter=200)#hidden_layer_sizes隐层神经元个数,learning_rate_init学习速率,max_iter迭代次数
clf.fit(x_train, y_train)
res = clf.predict(x_test)
代码函数及参数说明见
https://scikit-learn.org.cn/view/713.html