PPINN Parareal physics-informed neural network for time-dependent PDEs
论文阅读:PPINN Parareal physics-informed neural network for time-dependent PDEs
- PPINN Parareal physics-informed neural network for time-dependent PDEs
-
- 简介
- 方法
-
- PPINN
- 加速分析
- 实验
-
- 确定性常微分方程
- 随机常微分方程
- Burgers 方程
- 扩散反应方程
- 总结
PPINN Parareal physics-informed neural network for time-dependent PDEs
简介
在涉及偏微分方程长时间积分的建模问题中,大量的时空自由度导致训练 PINN 所需的数据量很大。这将要求 PINN 解决长期的物理问题,而这在计算上可能是令人望而却步的。为此,本文提出了一种准现实物理信息神经网络(PPINN),将一个长期问题分解为许多独立的短期问题,并由廉价/快速的粗粒度(CG)求解器监督,该求解器受到原始并行算法和监督并行算法的启发。由于训练 DNN 的计算成本随着数据集的大小而快速增加,因此该 PPINN 框架能够最大限度地利用小数据集训练神经网络的高计算效率的优势。更具体地说,使用小数据集训练 PINN 比直接处理大数据集有双重好处,即,使用小数据训练单个 PINN 的速度要快得多,而训练精细 PINN 的速度可以更快。很容易在多个 GPU-CPU 核心上并行化。因此,与原始的 PINN 方法相比,所提出的 PPINN 方法可以在解决长时间物理问题方面实现显着的加速;这将通过一维和二维非线性问题的基准测试来验证。这种有利的加速将取决于一个好的监督者,该监督者将由预计提供合理精度的粗粒度(CG)求解器代表。
方法
PPINN
对于涉及 t ∈ [ 0 , T ] t \in [0, T] t∈[0,T] 的偏微分方程长时间积分的瞬态问题,PPINN 不是直接在一个时域中求解该问题,而是将 [ 0 , T ] [0, T] [0,T] 拆分为 N N N 个长度相等的子域 Δ T = T / N \Delta T = T/N ΔT=T/N。然后,PPINN 使用两个传播器,即下述算法中由 G ( u i k ) \mathcal G(u^k_i ) G(uik) 表示的串行 CG 求解器,以及下述算法中由 F ( u i k ) \mathcal F(u^k_i ) F(uik) 表示的 N N N 个精细 PINN 并行计算。这里, u i k u^k_i uik 表示近似第 k k k 次迭代中 t i t_i ti 时刻的精确解。由于 CG 求解器在时间上是串行的,而精细 PINN 并行运行,为了获得最佳计算效率,本文将简化的 PDE (sPDE) 编码到 CG 求解器中作为预测传播器,而真实的 PDE 则编码在精细 PINN 中作为校正传播者。使用这种预测校正策略,期望 PPINN 解在几次迭代后收敛到真实解。

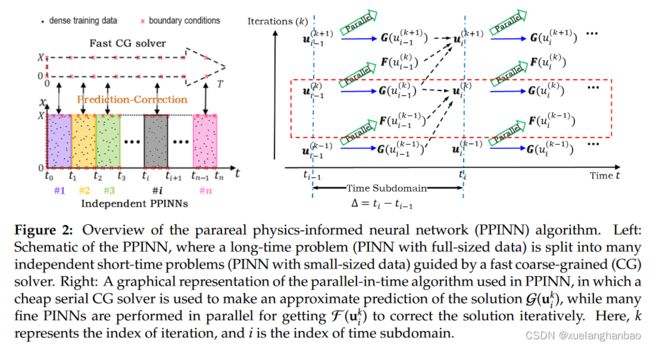
上图展示了 PPINN 方法的细节,下面将逐步解释:
首先,简化由 CG 求解器求解的 PDE。例如,可以替换后面实验中展示的扩散方程中的非线性系数。用常数去除变量/多尺度系数。例如,可以使用 CG PINN 作为快速 CG 求解器,但也可以探索标准的快速有限差分求解器。
其次,采用CG PINN对整个时域的sPDE进行串行求解,得到初始解。由于我们可以使用更少的残差点以及更小的神经网络来求解 sPDE 而不是原始 PDE,因此可以显着降低 CG PINN 中的计算成本。
第三,将时域分解为 N N N 个子域。假设 u i k u^k_i uik 已知为 t k ≤ t i ≤ t N t_k \le t_i \le t_N tk≤ti≤tN(包括 k = 0 k = 0 k=0,即初始迭代),将其用作并行运行 N N N 个精细 PINN 的初始条件。一旦获得所有 t i t_i ti 处的精细解,就可以计算 t i t_i ti 处粗解和精细解之间的差异,如算法 1 中的步骤 3(b) 所示。然后连续运行 CG PINN 以更新两个相邻子域之间每个接口的解 u u u ,即 u i + 1 k + 1 u^{k+1}_{i+1} ui+1k+1(算法 1 中的预测和细化)。迭代执行算法1中的步骤3,直到满足以下条件:
E = ∑ i = 0 N − 1 ∥ u i k + 1 − u i k ∥ 2 ∑ i = 0 N − 1 ∥ u i k + 1 ∥ 2 < E t o l , E=\frac{\sqrt{\sum_{i=0}^{N-1}\|\mathbf{u}_i^{k+1}-\mathbf{u}_i^k\|^2}}{\sqrt{\sum_{i=0}^{N-1}\|\mathbf{u}_i^{k+1}\|^2}}
其中 E tol E_\text{tol} Etol是用户定义的容差,在本研究中设置为 1 1% 1。
加速分析
PPINN 的时间开销可以表示为 T P P I N N = T c 0 + ∑ k = 1 K ( T c k + T f k ) T_{PPINN} = T^0_c + \sum ^K_{k=1}(T^k_c + T^k_f ) TPPINN=Tc0+∑k=1K(Tck+Tfk),其中 K K K 是迭代总数, T c 0 T^0_c Tc0 表示 CG 求解器初始化所花费的时间开销, T c k T^k_c Tck 和 T f k T^k_f Tfk 分别表示粗略传播器和精细传播器在第 k k k 次迭代时所用的时间开销。令 τ c k \tau_{c}^k τck 和 τ f k \tau^k_f τfk 为 CG 求解器和精细 PINN 在第 k 次迭代时针对一个子域使用的时间开销, T c k T^k_c Tck 和 T f k T^k_f Tfk 可以表示为:
T c k = N ⋅ τ c k , T f k = τ f k T_{c}^{k}=N\cdot\tau_{c}^{k},\quad T_{f}^{k}=\tau_{f}^{k} Tck=N⋅τck,Tfk=τfk
其中 N N N 是子域的数量。因此,PPINN 的时间开销为:
T P P I N N = T c 0 + ∑ k = 1 K ( N ⋅ τ c k + τ f k ) = N ⋅ τ c 0 + ∑ k = 1 K ( N ⋅ τ c k + τ f k ) . T_{PPINN}=T_{c}^{0}+\sum_{k=1}^{K}\left(N\cdot\tau_{c}^{k}+\tau_{f}^{k}\right)=N\cdot\tau_{c}^{0}+\sum_{k=1}^{K}\left(N\cdot\tau_{c}^{k}+\tau_{f}^{k}\right). TPPINN=Tc0+k=1∑K(N⋅τck+τfk)=N⋅τc0+k=1∑K(N⋅τck+τfk).
此外,精细 PINN 连续求解同一偏微分方程的时间表示为 T P I N N = N ⋅ T f 1 T_{PINN} = N·T^1_f TPINN=N⋅Tf1 。于是,可以得到PPINN的加速比为:
S = T P I N N T P P I N N = N ⋅ T f 1 N ⋅ τ c 0 + ∑ k = 1 K ( N ⋅ τ c k + τ f k ) S=\frac{T_{PINN}}{T_{PPINN}}=\frac{N\cdot T_f^1}{N\cdot\tau_c^0+\sum_{k=1}^K\left(N\cdot\tau_c^k+\tau_f^k\right)} S=TPPINNTPINN=N⋅τc0+∑k=1K(N⋅τck+τfk)N⋅Tf1
上式可以重写为:
S = N ⋅ τ f 1 N ⋅ τ c 0 + τ f 1 + N ⋅ K ⋅ τ c k + ( K − 1 ) ⋅ τ f k S=\frac{N\cdot\tau_f^1}{N\cdot\tau_c^0+\tau_f^1+N\cdot K\cdot\tau_c^k+(K-1)\cdot\tau_f^k} S=N⋅τc0+τf1+N⋅K⋅τck+(K−1)⋅τfkN⋅τf1
此外,考虑到两次相邻迭代( k ≥ 2 k \ge 2 k≥2)的每个子域中的解不会发生显着变化,在每个精细 PINN 中, k ≥ 2 k \ge 2 k≥2 的训练过程比 k = 1 k = 1 k=1 的训练过程收敛得快得多,即 τ f k ≪ τ f 1 \tau_{f}^{k}\ll\tau_{f}^{1} τfk≪τf1 。因此, S S S 的下界可以表示为:
S m i n = N ⋅ τ f 1 N ⋅ τ c 0 + N ⋅ K ⋅ τ c k + K ⋅ τ f 1 S_{min}=\frac{N\cdot\tau_f^1}{N\cdot\tau_c^0+N\cdot K\cdot\tau_c^k+K\cdot\tau_f^1} Smin=N⋅τc0+N⋅K⋅τck+K⋅τf1N⋅τf1
这表明,如果 τ c 0 ≪ τ f 1 \tau_{c}^{0}\ll\tau_{f}^{1} τc0≪τf1, S S S 随 N N N 增加,这表明使用的子域越多,PPINN 的加速比就越大。
实验
下文首先展示确定性和随机常微分方程 (ODE) 的两个简单示例来详细解释该方法。然后给出伯格斯方程和二维扩散反应方程的结果。
确定性常微分方程
考虑如下确定性常微分方程:
d u d t = a + ω cos ( ω t ) \frac{du}{dt}=a+\omega\cos(\omega t) dtdu=a+ωcos(ωt)
其中两个参数是 a = 1 a = 1 a=1 和 ω = π / 2 \omega = \pi/2 ω=π/2。给定初始条件 u ( 0 ) = 0 u(0) = 0 u(0)=0,该 ODE 的精确解为 u ( t ) = t + sin ( π t / 2 ) u(t) = t + \sin(\pi t/2) u(t)=t+sin(πt/2)。感兴趣的时域长度为 T = 10 T = 10 T=10。
在 PPINN 方法中,将时域 t ∈ [ 0 , 10 ] t \in [0, 10] t∈[0,10] 分解为 10 个子域,每个子域的长度 Δ t = 1 \Delta t = 1 Δt=1。对于 CG 求解器,使用简化的 ODE (sODE) d u / d t = a du/dt = a du/dt=a ,初始条件为 u ( 0 ) = 0 u(0) = 0 u(0)=0,并使用精确的 ODE d u / d t = a + ω cos ( ω t ) du/dt = a + \omega \cos(\omega t) du/dt=a+ωcos(ωt) ,初始条件为 u ( 0 ) = 0 u(0) = 0 u(0)=0,训练十个优秀的 PINN。特别是,首先使用 CG PINN 作为快速求解器。
令 [ N I ] + [ N H ] × D + [ D O ] [N_I] + [N_H] × D + [D_O] [NI]+[NH]×D+[DO] 表示 DNN 的架构,其中 N I N_I NI 是输入层的宽度, N H N_H NH 是隐藏层的宽度,D 是隐藏层的深度, N O N_O NO 是输出层的宽度。 CG PINN 被构造为使用大小为 $[1] + [4] × 2 + [1] $ 的DNN,同时使用 d u / d t = a du/dt = a du/dt=a ,初始条件为 u ( 0 ) = 0 u(0) = 0 u(0)=0 进行编码,而每个精细 PINN 被构造为 [ 1 ] + [ 16 ] × 3 + [ 1 ] [1] + [16] × 3 + [1] [1]+[16]×3+[1] 的 DNN ,并使用精确的 ODE d u / d t = a + ω cos ( ω t ) du/dt = a + \omega \cos(\omega t) du/dt=a+ωcos(ωt) ,初始条件为 u ( 0 ) = 0 u(0) = 0 u(0)=0 进行编码。
在第一次迭代中,使用 Adam 算法,以 α = 0.001 \alpha = 0.001 α=0.001 的学习率训练 CG PINN 5, 000 个 epoch,并获得解 G ( u ( t ) ) ∣ k = 0 \mathcal G(u(t))|_{k=0} G(u(t))∣k=0 的粗略预测。
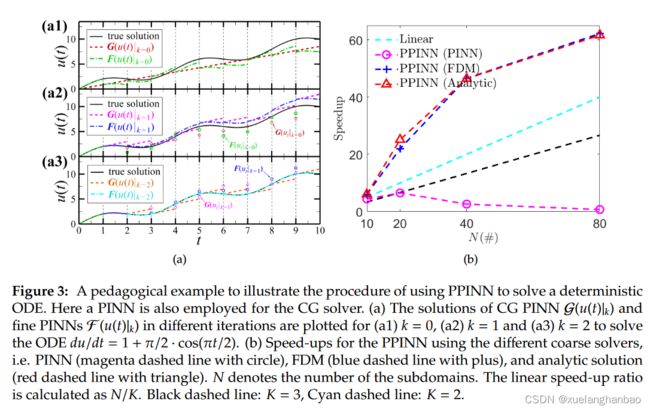
设 t i = i ( i = 0 , 1 , . . . , 9 ) t_i = i(i = 0, 1, ..., 9) ti=i(i=0,1,...,9) 为块 i + 1 i+1 i+1 中每个精细 PINN 的开始时间。为了计算 CG PINN 的损失函数,使用均匀分布在每个子域 [ t i , t i + 1 ] [t_i, t_{i+1}] [ti,ti+1] 中的 20 个残差点来计算残差 MSE R \text{MSE}_R MSER。随后,利用 CG PINN 解,除了第一个子域之外,每个精细 PINN 的初始条件由 t = t i t = t_i t=ti 时的预测值 G ( u ( t ) ) ∣ k = 0 \mathcal G(u(t))|_{k=0} G(u(t))∣k=0 给出。与训练 CG PINN 类似,使用 Adam 算法并行训练 10 个单独的精细 PINN,学习率为 α = 0.001 \alpha = 0.001 α=0.001 。如果每个精细 PINN 损失 l o s s = MSE R + MSE IC < 1 0 − 6 loss = \text{MSE}_R + \text{MSE}_\text{IC} < 10^{−6} loss=MSER+MSEIC<10−6,则接受 PINN 解,其中使用均匀分布在 [ t i , t i + 1 ] [t_i, t_{i+1}] [ti,ti+1] 中的 101 个残差点来计算残差 MSE R \text{MSE}_R MSER。可以在下图中观察到,精细 PINN 解正确地捕获了精确解的形状,但由于 G ( u ( t ) ) ∣ k = 0 \mathcal G(u(t))|_{k=0} G(u(t))∣k=0 给出的初始条件质量较差,它们的大小明显偏离精确解。
PPINN 解与精确解的偏差通过 l 2 l_2 l2 相对误差范数来量化:
l 2 = ∑ p ( u p k − u ^ p ) 2 ∑ p u ^ p 2 l_2=\frac{\sum_p(u_p^k-\hat{u}_p)^2}{\sum_p\hat{u}_p^2} l2=∑pu^p2∑p(upk−u^p)2
其中 p p p 表示残差点的索引。第一次迭代后的PPINN解出现了明显的偏差。
在第二次迭代中,给定 G ( u i ) ∣ k = 0 \mathcal G(u_i)|_{k=0} G(ui)∣k=0 和 F ( u i ) ∣ k = 0 \mathcal F(u_i)|_{k=0} F(ui)∣k=0 的解,将 CG PINN 的初始条件设置为 G \mathcal G G。然后再次训练 CG PINN 5, 000 个 epoch ,学习率为 α = 0.001 \alpha = 0.001 α=0.001,得到块 2 到 10 的解 G ( u ( t ) ) ∣ k = 1 \mathcal G(u(t))|_{k=1} G(u(t))∣k=1。第二个块的精细 PINN 的初始条件由下式给出 u ~ ( t = t 1 ) = F ( u 1 ) k = 1 \tilde{u}(t=t_{1})=F(u_{1})_{k=1} u~(t=t1)=F(u1)k=1,块 3 到 10 的精细 PINN 的初始条件由 G ( u ( t ) ) ∣ k = 0 , F ( u ( t ) ) ∣ k = 0 G(u(t))|_{k=0},\mathcal{F}(u(t))|_{k=0} G(u(t))∣k=0,F(u(t))∣k=0 以及 G ( u ( t ) ) ∣ k = 1 G(u(t))|_{k=1} G(u(t))∣k=1 的组合给出,且在 t = t i = 2 , 3... , 9 t = t_i=2,3...,9 t=ti=2,3...,9 时,即 u ~ ( t = t i ) = G ( u i ) ∣ k = 1 − [ F ~ ( u i ) ∣ k = 0 − G ( u i ) ∣ k = 0 ] \tilde{u}(t=t_i)=G(u_i)|_{k=1}-[\tilde{\mathcal{F}}(u_i)|_{k=0}-G(u_i)|_{k=0}] u~(t=ti)=G(ui)∣k=1−[F~(ui)∣k=0−G(ui)∣k=0]。使用这些初始条件,使用 Adam 算法并行训练 9 个单独的精细 PINN(块 2 到 10),学习率为 α = 0.001 \alpha = 0.001 α=0.001,直到每个精细 PINN 的损失函数降至 1 0 − 6 10^{−6} 10−6 以下。可以发现第二次迭代中的精细 PINN 收敛速度比第一次迭代快得多,平均 epoch 为 4836,而第一次迭代为 11524。加速的训练过程受益于上一次迭代中执行的训练结果。第二次迭代后每个块的 PPINN 解具有显着改进,相对误差 l 2 = 9.97 % l_2 = 9.97\% l2=9.97%。使用相同的方法,进行第三次迭代,PPINN 解收敛到精确解,相对误差 l 2 = 0.08 % l_2 = 0.08\% l2=0.08% 。
继续研究 PPINN 的计算效率。正如先前所提到的。 如果粗略求解器足够高效,就可以获得一个加速比,该加速比随着子域的数量线性增长。首先使用 PINN 作为粗略求解器来测试 PPINN 的加速效果。这里测试四种不同的子域分解,即 10、20、40 和 80。对于粗略求解器,为每个子域分配一个 PINN (CG PINN, [ 1 ] + [ 4 ] × 2 + [ 1 ] [1] + [4] × 2 + [1] [1]+[4]×2+[1]),并且每个子域中使用 10 个随机采样的残差点。此外,使用一个 CPU(Intel Xeon E5-2670)串行运行所有 CG PINN。对于精细求解器,再次为每个子域使用一个 PINN(精细 PINN)来求解方程。每个子域分配给一个CPU(Intel Xeon E5-2670)。残差点总数为40万个,全域随机采样并将均匀分布在每个子域中。同时,对于前两种情况(即 10 和 20 个子域),每个子域中精细 PINN 的架构为 [ 1 ] + [ 20 ] × 2 + [ 1 ] [1] + [20] × 2 + [1] [1]+[20]×2+[1],对于最后两种情况(即 40 和 80 子域)将其设置为 [ 1 ] + [ 10 ] × 2 + [ 1 ] [1]+[10 ]×2+[1] [1]+[10]×2+[1]。加速比如下图(b)(洋红色虚线)所示,可以观察到,当 N ≤ 20 N \le 20 N≤20 时,加速比首先随着 N N N 的增加而增加,然后随着 N N N 的增加而减少。进一步研究这种情况下的计算时间。
如下表所示,可以发现 CG PINN 所花费的计算时间随着子域数量的增加而增加。特别是,当 N ≥ 40 N \ge 40 N≥40 时,超过 90% 的计算时间被粗略求解器占用,这表明 CG PINN 的效率低下。为了使用 PPINN 获得满意的加速,应使用更高效的粗略求解器。
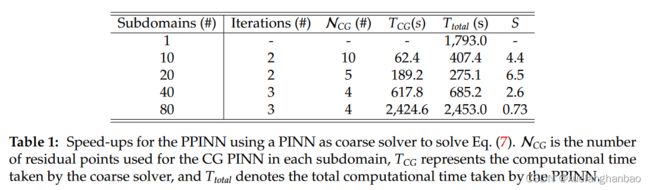
考虑到简化的 ODE 可以解析求解,因此可以直接使用粗求解器的解析解,没有成本。此外,精细 PINN 中的所有参数都与之前使用的参数保持相同。为了验证,再次使用 PPINN 中的 10 个子域来求解方程。经过两次迭代后,预测解和解析解之间的 l 2 l_2 l2 相对误差为 1.252 × 1 0 − 5 1.252×10^{−5} 1.252×10−5,这证实了 PPINN 的准确性。此外,四种情况的加速如上图(b) 所示(带三角形的红色虚线)。有趣的是,PPINN 可以在这里实现超线性加速。

上表中进一步列出了每次迭代的计算时间。可以看到,与总计算时间相比,粗略求解器所花费的计算时间现在可以忽略不计。由于精细 PINN 在第一次迭代后收敛得更快,因此可以获得 PPINN 的超线性加速。
除了解析解之外,还可以使用其他有效的数值方法作为粗略求解器。出于演示目的,随后使用有限差分法 (FDM) 作为粗略求解器来呈现结果。整个域被离散成 1,000 个均匀元素,然后均匀分布到每个子域。同样,也使用 10 个子域进行验证。同样需要2次迭代才能收敛, l 2 l_2 l2 相对误差为 1.257 × 1 0 − 5 1.257×10^{−5} 1.257×10−5。此外,由于FDM的效率,还可以获得与使用解析解的情况非常相似的超线性加速比。
随机常微分方程
除了确定性 ODE 之外,我们还可以应用这个思想来求解随机 ODE。在这里,考虑以下随机 ODE:
d u d t = β [ − u + β sin ( π 2 t ) + π 2 cos ( π 2 t ) ] , t ∈ [ 0 , T ] \frac{du}{dt}=\beta\left[-u+\beta\sin(\frac\pi2t)+\frac\pi2\cos(\frac\pi2t)\right],t\in[0,T] dtdu=β[−u+βsin(2πt)+2πcos(2πt)],t∈[0,T]
其中 T = 10 、 β = β 0 + ϵ 、 β 0 = 0.1 , ϵ T = 10、\beta = \beta_0 + \epsilon、\beta_0 = 0.1, \epsilon T=10、β=β0+ϵ、β0=0.1,ϵ是从均值为零、标准差为 0.05 的正态分布得出的。此外,方程的初始条件是 u ( 0 ) = 1 u(0) = 1 u(0)=1。在当前的 PPINN 中,对粗略求解器采用确定性 ODE,如下所示:
d u d t = − β 0 u , t ∈ [ t 0 , T ] \frac{du}{dt}=-\beta_0u,t\in[t_0,T] dtdu=−β0u,t∈[t0,T]
给定初始条件 u ( t 0 ) = u 0 u(t_0) = u_0 u(t0)=u0,可以获得方程的解析解为 u = u 0 exp ( − β 0 ( t − t 0 ) ) u = u_0 \exp(−\beta_0(t − t_0)) u=u0exp(−β0(t−t0))。对于精细求解器,使用准蒙特卡罗方法为 β \beta β 绘制 100 个样本,然后通过精细 PINN 进行求解。类似地,对粗略求解器使用三种不同的方法,即 PINN、FDM 和解析解。
出于验证目的,首先将时域分解为 10 个统一的子域。对于 FDM,将整个域离散为 1,000 个均匀元素。对于精细 PINN,在整个时域使用 400,000 个随机采样的残差点,这些点均匀分布到所有子域。为每个子域采用一个精细的 PINN 来求解 ODE,其架构为 [ 1 ] + [ 20 ] × 2 + [ 1 ] [1] + [20] × 2 + [1] [1]+[20]×2+[1]。最后,粗略求解器的每个子域中的简化 ODE 被串行求解,而精细求解器的每个子域中的精确 ODE 被并行求解。
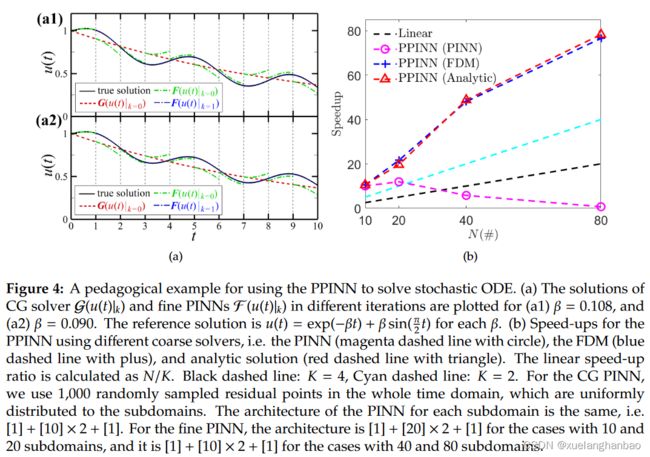
在上图(a) 中展示了两个代表性 β \beta β(即 β \beta β = 0.108 和 0.090)下的预测解和精确解之间的比较。可以看到预测解在两次迭代后收敛到精确解,这证实了 PPINN 求解随机 ODE 的有效性。 PPINN 与其他两个不同粗略求解器(即 PINN 和解析解)的解也与参考解非常吻合,但此处未列出。此外,还展示了使用四种不同数量的子域(即上图(b)中的 10、20、40 和 80)的 PPINN 的计算效率。很明显,如果使用 FDM 或解析解等高效的粗略求解器,PPINN 仍然可以实现超线性加速。使用 PINN 作为粗略求解器的 PPINN 的加速与先前的结果类似,即加速比首先随着子域数量 N ≤ 20 N \le 20 N≤20 略有增加,然后随着 N N N 的增加而减小。最后,使用 FDM 粗求解器的 PPINN 的加速比几乎与具有解析解粗求解器的 PPINN,与先前的结果类似此处不再详细讨论。
总之,PPINN 既适用于确定性 ODE,也适用于随机 ODE。另外,使用PINN作为粗略求解器可以保证求解ODE的精度,但加速比由于 PINN 的低效率,可能会随着子域数量的增加而减少。如果选择更高效的粗略求解器,例如解析解、有限差分法等,就可以获得高精度和良好的加速比
Burgers 方程
现在考虑如下粘性伯格斯方程:
∂ u ∂ t + u ∂ u ∂ x = ν ∂ 2 u ∂ x 2 \frac{\partial u}{\partial t}+u\frac{\partial u}{\partial x}=\nu\frac{\partial^2u}{\partial x^2} ∂t∂u+u∂x∂u=ν∂x2∂2u
这是粘性流、气体动力学和交通流的数学模型,其中 u u u 表示流体的速度, ν \nu ν 表示运动粘度, x x x 表示空间坐标, t t t 表示时间。给定域 x ∈ [ − 1 , 1 ] x \in [−1, 1] x∈[−1,1] 中的初始条件 u ( x , 0 ) = − sin ( π x ) u(x, 0) = − \sin(\pi x) u(x,0)=−sin(πx),并且 t ∈ [ 0 , 1 ] t \in [0, 1] t∈[0,1] 的边界条件 u ( ± 1 , t ) = 0 u(\pm 1, t) = 0 u(±1,t)=0,想要求解的偏微分方程为方程粘度为 ν = 0.03 / π \nu = 0.03/\pi ν=0.03/π。
在 PPINN 中,时域 t ∈ [ 0 , 1 ] t \in [0, 1] t∈[0,1] 被分解为 10 个均匀的子域。每个子域的时间长度 Δ t = 0.1 \Delta t = 0.1 Δt=0.1。 CG PINN 的简化 PDE 也是 Burgers 方程,它使用相同的初始条件和边界条件,但具有更大的粘度 ν c = 0.05 / π \nu_c = 0.05/\pi νc=0.05/π。众所周知,随着时间的推移,粘度较小的 Burgers 方程的解会出现陡峭的梯度。增加的粘度将导致更平滑的解决方案,可以使用更少的计算成本来捕获该解决方案。在这里,对 CG 和每个子域内的精细 PINN 使用相同的 NN ,即 3 个隐藏层,每层 20 个神经元。学习率也设置为相同,即 1 0 − 3 10^{−3} 10−3。在最后一种情况下,没有使用单一优化器,而是使用两种不同的优化,即,首先使用 Adam 优化器(一阶收敛率)训练 PINN,直到损失小于 1 0 − 3 10^{−3} 10−3,然后继续使用 L-BFGS-B 方法进一步训练神经网络。 L-BFGS是一种准牛顿方法,具有二阶收敛速度,可以增强训练的收敛性。
对于每个子域中的 CG PINN,使用 300 个随机采样的残差点来计算 MSE R \text{MSE}_R MSER,而每个子域的精细 PINN 中使用 1, 500 个随机残差点。此外,采用 100 个均匀分布的点来计算每个子域的 MSE IC \text{MSE}_\text{IC} MSEIC,并使用 10 个随机采样点来计算 CG 和精细 PINN 中的 MSE BC \text{MSE}_\text{BC} MSEBC。对于这种特殊情况,只需 2 次迭代即可满足收敛标准,即 E t o l = 1 % E_{tol} = 1\% Etol=1%。每次迭代中 u u u 的分布如下图所示。
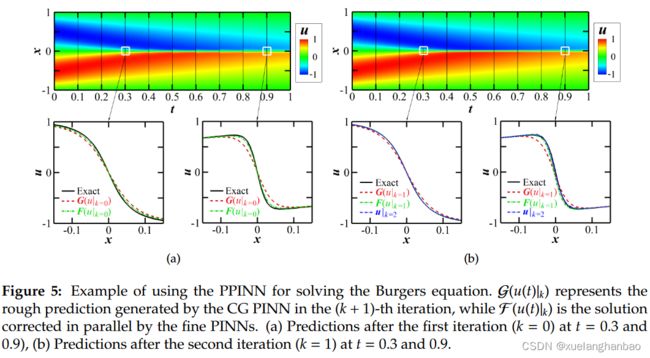
如上图(a) 所示,精细 PINN ( F ( u ∣ k = 0 ) \mathcal F (u|_{k=0}) F(u∣k=0)) 的解与精确解不同,但观察到差异很小。还观察到,CG PINN 的解比精细 PINN 的解更平滑,特别是对于大时间的解,例如 t = 0.9 t = 0.9 t=0.9。此外,由于第一次迭代时每个子域的初始条件不准确,两个相邻子域之间界面处的速度不连续。在第二次迭代中(上图(b)),精炼步骤的解(即 u ∣ k = 2 u|_{k=2} u∣k=2)与精确解几乎没有什么区别,这证实了 PPINN 的有效性。此外,两个相邻子域之间的不连续性显着减少。最后,有趣的是,第一次迭代时每个子域的训练步骤数从十到数十万,但在第二次迭代时减少到几百。类似的结果也在前文中报告和分析过,这里不再赘述。
为了测试 PPINN 的灵活性,进一步在粗略求解器中使用两个更大的粘度,即 ν c = 0.09 / π \nu_c = 0.09/\pi νc=0.09/π 和 0.12 / π 0.12/\pi 0.12/π,它们分别是精确粘度的 3× 和 4×。这两种情况下的所有参数(例如,PINN 的架构、残差点的数量等)与 ν c = 0.05 / π \nu_c = 0.05/\pi νc=0.05/π 的情况保持相同。

如上表所示,有趣的是,这三种情况的计算误差是相当的,但迭代次数随着粗略求解器中使用的粘度而增加。因此,为了获得选择 CG 求解器的最佳策略,必须考虑 CG 求解器可以获得的精度与 PPINN 收敛所需的迭代次数之间的权衡。
扩散反应方程
接下来考虑以下二维扩散反应方程:
∂ l C = ∇ ⋅ ( D ∇ C ) + 2 A sin ( π x l ) sin ( π y l ) , x , y ∈ [ 0 , l ] , t ∈ [ 0 , T ] , C ( x , y , t = 0 ) = 0 , C ( x = 0 , y = 0 , t ) = C ( x = 0 , y = l , t ) = C ( x = l , y = 0 , t ) = C ( x = l , y = l , t ) = 0 , \begin{aligned} \partial_lC&=\nabla\cdot(D\nabla C)+2A\sin(\frac{\pi x}l)\sin(\frac{\pi y}l),x,y\in[0,l],t\in[0,T],\\C(x,y,t&=0)=0,\\C(x=0,y=0,t)&=C(x=0,y=l,t)=C(x=l,y=0,t)=C(x=l,y=l,t)=0, \end{aligned} ∂lCC(x,y,tC(x=0,y=0,t)=∇⋅(D∇C)+2Asin(lπx)sin(lπy),x,y∈[0,l],t∈[0,T],=0)=0,=C(x=0,y=l,t)=C(x=l,y=0,t)=C(x=l,y=l,t)=0,
其中 l = 1 l = 1 l=1 是计算域的长度, C C C是溶质浓度, D D D是扩散系数, A A A是常数。这里 D D D 取决于 C C C,如下所示:
D = D 0 exp ( R C ) D=D_0\exp(R C) D=D0exp(RC)
其中 D 0 = 1 × 1 0 − 2 D_0 = 1 × 10^{−2} D0=1×10−2。
首先设置 T = 1 、 A = 0.5511 T = 1、A = 0.5511 T=1、A=0.5511 和 R = 1 R = 1 R=1,以验证二维情况下提出的算法。在 PPINN 中,将 PINN 用于粗略求解器和精细求解器。时域被分为 10 个统一的子域,每个子域的 Δ t = 0.1 \Delta t = 0.1 Δt=0.1。对于粗略求解器,使用相同初始条件和边界条件求解以下简化 PDE: ∂ t C = D 0 ∇ 2 C + 2 A sin ( π x / l ) sin ( π y / l ) \partial_{t}C=D_{0}\nabla^{2}C+2A\sin(\pi x/l)\sin(\pi y/l) ∂tC=D0∇2C+2Asin(πx/l)sin(πy/l)。 粗略求解器的扩散系数大约比精细求解器中的最大 D D D 小 1.7 倍。每个子域的粗略求解器和精细求解器中采用的 NN 架构保持相同,即 2 个隐藏层,每层 20 个神经元。所采用的学习率以及优化方法与前文中应用的相同。
使用 2,000 个随机残差点来计算粗略求解器每个子域中的 MSE R \text{MSE}_R MSER。还使用 1,000 个随机点来计算每个边界的 MSE BC \text{MSE}_\text{BC} MSEBC,并使用 2,000 个随机点来计算 MSE IC \text{MSE}_\text{IC} MSEIC。对于每个精细 PINN,使用 5,000 个随机残差点进行 MSE R \text{MSE}_R MSER,而边界和初始条件的训练点数保持与粗略求解器中使用的相同。需要两次迭代才能满足收敛标准,即 E t o l = 1 % E_{tol} = 1\% Etol=1%。 PPINN 解以及每次迭代在三个代表性时间(即 t = 0.4 、 0.8 t = 0.4、0.8 t=0.4、0.8 和 1 1 1)的扩散系数分布如下图所示。
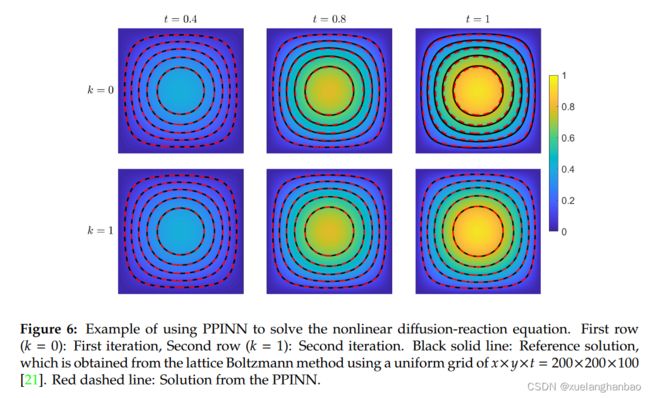
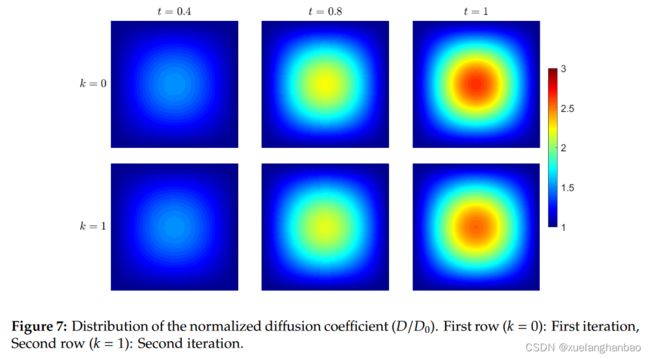
可以看到,第一次迭代后, t = 0.4 t = 0.4 t=0.4 时的解与参考解非常吻合,而 PPINN 和参考解之间的差异随着时间的推移而增加,这可以在上图的第一行 t = 0.8 t = 0.8 t=0.8 和 1 1 1 时观察到。 这是合理的,因为每个子域的初始条件的误差会随着时间的推移而增加。此外,解决方案位于三个代表性时间与第二次迭代后的参考解非常吻合。所有上述结果再次证实了本方法的准确性。
使用 PINN 作为粗略求解器进一步研究 PPINN 的加速。这里 T = 10 , A = 0.1146 , R = 0.5 T = 10,A = 0.1146,R = 0.5 T=10,A=0.1146,R=0.5,使用五个不同的子域,即 1 、 10 、 20 、 40 1、10、20、40 1、10、20、40 和 50 50 50。并行代码在多个CPU(Intel Xeon E5-2670)上运行。粗解器中残差点总数为20000个,均匀划分为 N N N 个子域。每个边界上的边界条件训练点数为10000个,也是统一分配给每个子域的。此外,初始条件采用2000个随机采样点。每个子域中CG PINN的架构和其他参数(例如学习率、优化器等)与精细PINN相同,如下表所示。

代表性案例的加速比如下表所示. 可以注意到加速并不随着子域的数量单调增加。相反,加速比随着子域数量的增加而降低。这一结果表明,CG PINN 的成本不仅与训练数据的数量有关,而且还受到超参数数量的影响。 CG PINN 中的总超参数随着子域数量的增加而增加,导致 PPINN 的时间开销随着子域数量的增加而增加。
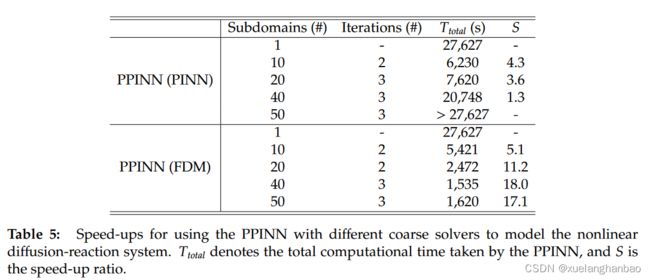
为了验证上述假设,将粗略求解器的 PINN 替换为有限差分法(FDM,网格大小: x × y = 20 × 20 x × y = 20 × 20 x×y=20×20,时间步 δ t = 0.05 \delta t = 0.05 δt=0.05),其效率比PINN高得多 。与精细的 PINN 相比,每个子域中 FDM 的运行时间可以忽略不计。如上表所示,加速比现在与预期的子域数量成正比。
总结
本文提出了一种并行计算时间依赖PINN的方法。通过粗求解器求解简化PDE来为不同时间片上的独立PINN提供初始解,同时根据训练的进行不断调整初始解,以获得最终的精确解。同时,由于简化的PDE可以使用有限元求解或直接获得解析解,因此可以获得超线性的加速比。
文章中简化的PDE在形态上都与真实PDE较为相似,在这一点上类似于课程学习。但在现实中由于解的形态未知,因此如何简化PDE似乎是个难以确定的问题。
相关链接:
- 原文:PPINN: Parareal physics-informed neural network for time-dependent PDEs - ScienceDirect
- 原文代码:XuhuiM/PPINN: Demo code for PPINN paper: https://www.sciencedirect.com/science/article/pii/S0045782520304357 (github.com)