C++——引用变量
目录
一、创建引用变量
二、将引用作为函数参数
三、引用的属性和特别处
四、临时变量、引用参数和const
五、返回引用
六、何使用引用参数
七、参考书籍
引用变量是C++新增的一种复合类型。引用是已定义的变量的别名(另一个名字,但两个名字都是表示同一个变量,就好像 爹、爸都是表示父亲的意思)。例如,a = 5,如果将 b 作为 a 变量的引用,则可以交替使用 a 和 b 表示该变量(即 a 和 b 都可以表示 5)。引用有指针的作用,但它比指针使用起来更加方便。
那么引用变量是来做什么的呢——引用变量的主要用途是用作函数的形参。通过将引用变量用作参数,函数将使用原始的数据,而不是其副本(类似指针)。
一、创建引用变量
引用变量是用 & 符号来声明的。如果学过C语言的同学,可能知道 & 可以获取变量的地址,但是C++给 & 符号赋予了另一个函数——声明引用变量。例如,要将 b 作为 a 变量的别名,可以这么做:
int a;
int &b = a; // b 是 a 变量的别名其中,&不是地址运算符,而是类型标识符的一部分。就类似声明 char* 指的是指向 char 的指针一样, int &指的是指向 int 的引用。
上述引用声明完后,a和b就指向相同的值和内存单元(即b是a变量的别名)。
#include
using namespace std;
int main()
{
int a = 5;
int& b = a;
cout << "a = " << a << ", a address: " << &a << endl;
cout << "b = " << b << ", a address: " << &b << endl;
return 0;
} ![]()
上述程序输出表明了,引用声明的变量 b 和 变量a 是同一个变量,在同一块内存中(b是a的别名)。
注:下面的语句中的 & 运算符不是地址运算符,而是将 b 的类型声明为 int &,即指向 int 变量的引用:
int &b = a;但是下述中的&运算符是地址运算符,其中&b表示 b 引用的变量的地址:
cout << "b = " << b << ", a address: " << &b << endl;如果将 b 自增 1 将影响这两个变量(因为b是a的别名,两者指向相同的内存单元一致),即 这两个变量都会加一。
b++;
cout << "a = " << a << ", b = " << b << endl; 如果咱们学过C语言,我们很快会想到指针,因为指针也有这种效果,但是是指针和引用这两者之间还是有区别的。例如,可以创建指向 a 的引用和指针:
如果咱们学过C语言,我们很快会想到指针,因为指针也有这种效果,但是是指针和引用这两者之间还是有区别的。例如,可以创建指向 a 的引用和指针:
int a = 5;
int& b = a;
int* c = &a;这样,表达式 b 和 *c 都可以同 a 互换(都表示5),而表达式 &b 和 c 都可以和&a互换(都指向同一块内存)。从这一点上看,引用看上去很像伪装表示的指针(其中,*解除引用运算符被隐式理解,即引用少了个解引操作)。但实际上,引用还是不同与指针,除了表示法不同外(引用声明需要用到 & 运算符,指针声明需要用到 * 运算符),还有其他的差别。差别之一,必须在声明引用时,将其初始化,不能像指针一样,先声明,再赋值:
int a;
int &b;
b = a; // 不能这么做,编译器会报错![]()
注:必须在声明引用变量时进行初始化。
引用更接近 const 指针,必须在创建时进行初始化,一旦与某个变量关联起来,就将一直效忠于它。也就是说:
int &b = a;
类似于下面代码的表示:
int * const pr = &a;其中,引用 b 扮演的角色与表达式 *pr相同(即pr不能指向别处,只指向a)。
如果试图改变引用(即从引用初始化的变量,修改为引用别的变量),将会发生情况,如下面这个程序,试图将 a 变量的引用改成 c 变量的引用。
#include
using namespace std;
int main()
{
int a = 5;
int& b = a;
cout << "a = " << a << ", a address: " << &a << endl;
cout << "b = " << b << ", n address: " << &b << endl;
int c = 10;
b = c; // 试图改变 b 的指向,从指向a 变为 指向c
cout << "c = " << c << ", c address: " << &c << endl;
cout << "a = " << a << ", c address: " << &a << endl;
cout << "b = " << c << ", c address: " << &b << endl;
return 0;
} 程序输出:

最初, b 引用的是 a,但上面的程序试图将 b 作为 c 的引用:
b = c;
乍一看,这种意图暂时是成功的,因为 b 的值从 5 变为了 10.但仔细研究将发现,a 也变成了 10,同时 a 和 b 的地址相同,但该地址与 c 的地址不同。由于 b 是 a 的别名,因此上述赋值语句相当于下面的这条语句:
a = c; // 重新给a赋值总结:通过初始化声明来设置引用,但不能通过赋值来设置。
可能有些人会试图这样做:
声明一个指针 c 来指向 a,然后将 b 引用 *pr,再通过改变 pr 的指向,使其指向 c ,来做到将 b 引用 c。
#include
using namespace std;
int main()
{
int a = 5;
int* pr = &a;
int& b = *pr;
cout << "a = " << a << ", a address: " << &a << endl;
cout << "*pr = " << *pr << ", pr = " << pr << endl;
cout << "b = " << b << ", b address: " << &b << endl;
int c = 10;
pr = &c;
cout << "c = " << c << ", c address: " << &c << endl;
cout << "a = " << a << ", a address: " << &a << endl;
cout << "*pr = " << *pr << ", pr = " << pr << endl;
cout << "b = " << b << ", b address: " << &b << endl;
return 0;
} 程序输出:

但还是改变不了,b 引用的是 a。如上图,b = 5,并没有变为 c = 10,并且 a 和 b指向的内存单元一致。
二、将引用作为函数参数
引用经常被用作函数的参数,这是引用的典型用途,使得被调用函数中的变量名成为调用函数函数的别名。这种传递参数的方法称为按引用传递。按引用传递允许被调用函数能够访问调用函数的变量(即可以对调用函数的变量进行操作,如重新赋值)。C++新增的这项特性是对C语言的超越。
咱们通过交换两个变量的值,来对使用引用和使用指针来做下区别。交换函数必须能够修改调用函数中的变量的值。这就是说按值传递变量不管用,因为函数交换原始变量副本的内容,而不是变量本身的内容。但传递引用时,函数可以使用原始数据。另一种方法是,传递指针来访问原始数据。
按值传递示意图:

按引用传递示意图:
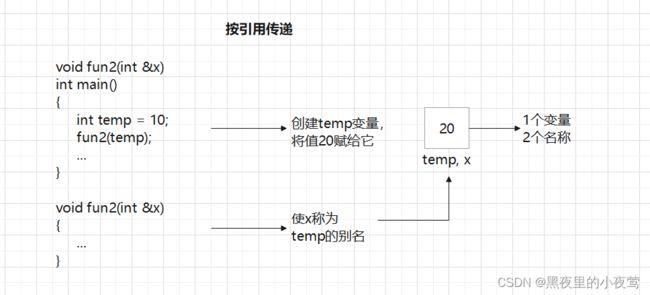
#include
void swap1(int& a, int& b);
void swap2(int* a, int* b);
void swap3(int a, int b);
int main()
{
using namespace std;
int a = 5;
int b = 10;
cout << "未交换前: a = " << a << ", b = " << b << endl;
swap1(a, b);
cout << "调用引用参数函数后: a = " << a << ", b = " << b << endl;
swap2(&a, &b);
cout << "调用指针参数函数后: a = " << a << ", b = " << b << endl;
swap3(a, b);
cout << "使用传值函数后: a = " << a << ", b = " << b << endl;
return 0;
}
void swap1(int& a, int& b)
{
int temp;
temp = a;
a = b;
b = temp;
}
void swap2(int* a, int* b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
void swap3(int a, int b)
{
int temp;
temp = a;
a = b;
b = temp;
} 程序输出:

咱们比较一下这几个函数:
void swap1(int& a, int& b);
void swap2(int* a, int* b);
void swap3(int a, int b);按引用传递(swap1(a, b))和按值传递(swap3(a, b))(调用它们) 看起来相同,只能通过函数原型或函数定义才知道swap1()是按引用传递。但它们还是有区别的。
外在区别是函数声明函数的参数方式不同:
void swap1(int &a, int &b);
void swap3(int a, int b);内在区别:在swap1()中,变量 a和b 是函数main()中的 a和b 别名,所以交换 a和b 的值相当于交换main()中 a和b 的值;但在swap3()中,变量 a和b 复制了 main中 a和b 的值的新变量,所以交换 a和b 的值不会影响 main()中 a和b 的值。
函数swap1()(传递引用)和 swap2() (传递指针),在调用时传递指针函数swap2()需要用到&运算符将地址传入函数,但swap1()却不用,调用时可以一目了然知道函数参数是指针还是引用,但两者还是有差别:
声明函数参数的方式不同,引用需要用到 &运算符,指针需要用到 *运算符。
void swap1(int &a, int &b);
void swap2(int *a, int *b);另一个区别是,指针函数在使用 a 和 b 的整个过程中使用解除引用运算符 *。
三、引用的属性和特别处
例如,需要用两个函数计算参数的平方,其中一个函数接受double类型的参数,另一个接受double引用。
#include
using namespace std;
double sq1(double a);
double sq2(double& ra);
int main(void)
{
double x = 3.0;
cout << "x的平方为:" << sq1(x) << ", 此时x = " << x << endl;
cout << "x的平方为:" << sq2(x) << ", 此时x = " << x << endl;
return 0;
}
double sq1(double a)
{
a *= a;
return a;
}
double sq2(double& ra)
{
ra *= ra;
return ra;
} 程序输出:
![]()
sq2()函数修改了main()中的x值,但sq1()没有,这提醒我们为何通常按值传递。变量a 位于sq1()中,它被初始化为 x 的值,但修改a并不会影响x。但sq2()使用引用参数,因此修改ra实际上就是修改了x。如果只是让函数使用传递给它的信息,而不对这些信息进行修改,同时又想使用引用,则应该使用常量引用:
double sq2(const double &ra);如果这样做了,当编译器发现代码修改了ra的值时,将发生错误信息。
按值传递的函数,如上面的sq1(),可以使用多种类型的实参。如下面的调用都是合法的:
double z = sq1(x + 2.0);
z = sq1(8.0);
int k = 10;
z = sq1(k);
double yo[3] = {2.2, 3.3, 4.4}
z = sq1(yo[2]);但传递引用的限制很严格。毕竟ra是一个变量的别名,则实参应是该变量。下面代码不合理,因为表达式 x + 3.0并不是变量:
double x = sq2(x + 3.0);
例如,不能将值赋给该表达式:
x + 3.0 = 5.0;但有些情况下,仍然可以这样做。这样做的结果 如下:由于 x + 3.0 不是double类型的变量,因此程序将创建一个临时的无名变量,并将其初始化为表达式 x+3.0 的值。然后,ra将成为该临时变量的引用。下面详细讨论这种临时变量,看看什么时候创建它们,什么时候不创建。
四、临时变量、引用参数和const
如果实参与引用参数不匹配,C++将生成临时变量。当前,仅当参数为const引用时,C++才允许这样做,如果不是则将报错,如下图。
![]() 首先,什么时候创建临时变量呢?如果引用参数是const,则编译器将在下面两种情况下生成临时变量:
首先,什么时候创建临时变量呢?如果引用参数是const,则编译器将在下面两种情况下生成临时变量:
- 实参的类型正确,但不是左值;
- 实参的类型不正确,但可以转换为正确的类型
左值参数是可以被引用的数据对象,例如,变量、数组元素、结构成员、引用和解除引用的指针都是左值。
非左值包括字面常量(用引号括起来的字符串除外,它们是由地址表示)和包含多项的表达式。
回到上面的示例,重新定义sq2(),使其接受一个常量引用参数:
double sq2(const double &ra)
{
return ra*ra;
}现在考虑下面的代码:
double side = 3.0;
double *pd = &side;
double &rd = side;
long edge = 5L;
double lens[4] = {2.0, 5.0, 10.0, 12.0};
double c1 = sq2(side); // ra是side的别名
double c2 = sq2(lens[2]) // ra是lens[2]的别名
double c3 = sq2(rd);
double c4 = sq2(*pd) // ra是side的别名,*pd = side
double c5 = sq2(edge) // ra是临时变量
double c6 = sq2(7.0) // ra是临时变量
double c7 = sq2(side + 10.0) // ra是临时变量参数side、lens[2]、rd 和 *pd都是有名称的、double类型的数据对象,因此可以为其创建引用,而不需要临时变量。
edge虽然是变量,类型却不正确,double引用不能指向long。另一方面,参数7.0 和 side+10.0 的类型都正确,但没有名称,在这些情况下,编译器都将生成一个临时匿名变量,并让ra指向它。这些临时变量只在函数调用期间存在,此后编译器变可以随意将其删除。
测试程序:
#include
using namespace std;
void print(const int& a);
int main()
{
long edge = 5L;
cout << "edge = " << edge << ", edge address: " << &edge << endl;
print(edge);
return 0;
}
void print(const int& a)
{
cout << "a = " << a << ", a address: " << &a << endl;
} 程序输出:
![]()
edge和a的地址不一致,说明当类型不一致时,会创建临时变量,a会指向这个临时变量。
为什么对于常量引用,这种行为是可行的,其他情况却不行呢。对于上面实例的函数swap1():
void swap1(int& a, int& b)
{
int temp;
temp = a;
a = b;
b = temp;
}
如果在早期C++较宽松的规则下,指行下面操作将发生什么情况呢?
long a = 3, b = 5;
swap1(a, b);这里类型不匹配,因此编译器将创建两个临时变量,将它们初始化为 3 和 5,然后交换临时变量的内容,而 a 和 b 保持不变。

简而言之,如果接受引用参数的函数的意图是修改作为参数传递的变量,则创建临时变量将阻止这种意图的实现。 解决方法是,禁止创建临时变量,现在C++标准正是这样做的(然而,在默认情况下,有些编译器仍将发出警告,而不是错误信息,因此如果看到了有关临时变量的警告,请不要忽略)。
现在看来sq2()函数。该函数的目的只是使用传递的值,而不是修改它们,因此临时变量不会造成任何不利的影响,反而会是函数在可处理的参数种类方面更通用。
因此,如果声明将引用指定为 const,C++将在必要时生成临时变量。实际上,对于形参为const引用的C++函数,如果实参不匹配,则其行为类似于按值传递,为确保原始数据不被修改,将使用临时变量来存储值。
注:如果函数调用的参数不是左值或与相应的const引用参数的类型不匹配,则C++将创建类型正确的匿名变量,将函数调用的参数的值传递给该匿名变量,并让参数来引用该变量。
应尽可能使用const
将引用参数声明为常量数据的引用的理由有三个:
- 使用const可以避免无意中修改数据的编程错误;
- 使用const使函数能处理const 和 非const实参,否则将只能接受非 const数据;
- 使用const引用使函数能够正确生成并使用临时变量。
因此,应尽可能将引用形参声明为const。
C++11新增了另一种引用——右值引用(rvalue reference)。这种引用可指向右值,是使用&&声明:
double j = 15.0;
double && jref = 2.0 * j + 18.5; // 不允许使用double &
cout << jref << endl;新增右值引用的主要目的是,让库设计人员能够提供有些操作的更有效实现。还可以使用右值引用来实现移动语义(move semantics)。以前的引用(使用&声明的引用)现在称为左值引用。
五、返回引用
#include
using namespace std;
struct Average
{
float a;
float b;
float average;
};
void display(const Average& ft);
Average& accumulate(Average& a, const Average& b);
int main()
{
Average one = { 1.0, 1.0, 1.0 };
Average two = { 4.0, 4.0, 4.0 };
Average three = one;
display(one);
display(two);
accumulate(one, two);
display(one);
accumulate(one, two) = three;
display(one);
display(accumulate(one, two));
return 0;
}
void display(const Average& ft)
{
cout << "a = " << ft.a << ", b = " << ft.b << ", average = "
<< ft.average << endl;
}
Average& accumulate(Average& a, const Average& b)
{
a.a += b.a;
a.b += b.b;
a.average = (a.a + a.b) / 2;
return a;
} 咱们来分析这个程序,首先初始化了多个结构对象,然后调用函数display(),来显示结构的内容,而不修改它,因此这个函数使用了一个const引用参数。就这个函数而言,也可按值传递结构,但与复制原始结构拷贝相比,使用引用可以节省内存和时间。
下一个函数调用如下:
accumulate(one, two);函数accumulate()接收两个结构参数,并将第二个结构的成员 a 和 b的数据添加到第一个结构的相应成员中。只修改了第一个结构,因此第一参数为引用,而第二个参数为const引用:
Average& accumulate(Average& a, const Average& b);返回值呢?当前讨论的函数没有使用它,就目前而言,原本可以将返回值声明为void,但请看下述函数调用:
display(accumulate(one, two));上述代码的意思是,首先,将结构对象one作为第一个参数传递给了accumulate()。这意味着在函数accumulate()中,a指向的是 one。函数accumulate()修改了one,再返回指向它的引用,注意返回值语句如下:
return a;光看这条语句并不知道返回的是引用,但函数头和原型指出了这点:
Average& accumulate(Average& a, const Average& b);如果返回类型被声明为 Average 而不是 Average&,上述返回语句将返回a(也就是one) 的拷贝。但返回类型为引用,这意味着返回的是最初传递给accumulate()的one对象。
接下来,将accumulate()的返回值作为参数传递给了display(),这意味着将one传递给了display()。display()的参数为引用,这意味着函数display()中的 ft 指向的是one,因此将显示one的内容。所以,下述代码:
display(accumulate(one, two));与下面的代码等效:
accumulate(one, two);
display(one);程序以独特的方式使用了accumulate():
accumulate(one, two) = three;这条语句将值赋给函数调用,这是可行的,因为函数的返回值是一个引用(相当于重新赋值,和前面想改变引用的指向类似)。如果函数accumulate()按值返回,这条语句将不能通过编译。由于返回的是指向one的引用,因此上述代码和下面代码等效:
accumulate(one, two);
one = three;其中第二条语句消除了第一条语句所做的工作,因此在原始赋值语句中使用accumulate()的方式并不好。
为何要返回引用?
下面更深入地讨论返回引用与传统返回机制的不同之处。传统返回机制与按值传递函数参数类似:计算关键字return后面的表达式,并将结果返回给调用函数。从概念上说,这个值被复制到一个临时位置,而调用程序将使用这个值,如下面代码:
double m = sqrt(16.0);
cout << sqrt(25.0);在第一条语句中,值4.0被复制到一个临时位置,然后被复制给m。在第二条语句中,值5.0被复制到一个临时位置,然后被传递给cout。
 现在看下面这条语句:
现在看下面这条语句:
three = accumulate(one, two);如果accumulate()返回一个结构,而不是指向结构的引用,将把整个结构复制到一个临时位置,再将这个拷贝复制给three。但在返回值为引用是,将直接把one复制到three,其效率更高。
注:返回引用的函数实际上是被引用的变量的别名。
返回引用时需要注意的问题
返回引用时最重要的一点是,应避免返回函数终止时不再存在的内存单元引用,例如:
const Average &clone(Average &ft)
{
Average newguy;
nweguy = ft;
return newguy;
}该函数返回一个指向临时变量(newguy)的引用,函数运行完毕后它将不再存在。同样,也应避免返回指向临时变量的指针。
为了避免这种问题,最简单的方法是,返回一个作为参数传递给函数的引用。作为参数的引用将指向调用函数使用的数据,因此返回的引用也将指向这些数据。上面的accumulate()函数就是这样做的。
将const用于引用返回类型
看下面代码:
accumulate(one, two) = three;其效果如下:首先将two的数据添加到one中,再使用three的内容覆盖one的内容。
这条语句为何能通过编译?在赋值语句中,左边必须是可修改的左值。也就是说,在赋值表达式中,左边的子表达式必须标识一个可修改的内存块。在这里,函数返回指向one的引用,它确实标识的是一个这样的内存块,因此这条语句合法。
假设你要使用引用的返回值,但又不允许指行像上面给accumulate()赋值这样的操作,只需要将返回类型声明为const引用:
const Average& accumulate(Average& a, const Average& b);现在返回类型为const,是不可修改的左值,因此下面的赋值语句不合法:
accumulate(one, two) = three;常规(非引用)返回类型是右值——不能通过地址访问的值。这种表达式可出现在赋值语句的右边,但不能出现在左边。其他右值包括字面值(如10)和表达式(x+y)。显然,获取字面值(如10)的地址没有意义,但为何常规函数返回值是右值呢?这是由于返回值位于临时内存单元中,运行到下一条语句时,它们可能不再存在。
六、何使用引用参数
使用引用参数的主要原因有两个:
- 能够修改调用函数中的数据对象(类似指针,但用起来比指针方便)。
- 通过传递引用而不是整个数据对象,可以提高程序的运行速度。
当数据对象较大时(如结构和类对象),第二个原因最重要。这些也是使用指针参数的原因。引用参数实际上是基于指针的代码的另一个接口。
那么什么时候应使用引用、什么时候应使用指针呢?什么时候应按值传递?下面是一些指导原则:
对于使用传递的值而不作修改的函数:
- 如果数据对象很小,如内置数据类型(int,float等)或小型结构,则按值传递。
- 如果数据对象是数组,则使用指针,因为这是唯一的选择,并将指针声明为指向const的指针。
- 如果数据对象是很大的结构,则使用const指针或const引用,以提高程序的效率。这样可以节省复制结构所需的时间和空间。
- 如果数据对象是类对象,则使用const引用。类设计的语义常常要求使用引用,这是C++新增这项特性的主要原因。因此,传递类对象参数的标准方式是按引用传递。
对于修改调用函数中数据的函数:
- 如果数据对象是内置数据类型,则使用指针。如果看到诸如 fixit(&x) 这样的代码(其中x是int),则很明显,该函数将修改x。
- 如果数据对象是数组,则只能使用指针。
- 如果数据对象是结构,则使用引用或指针。
- 如果数据对象是类对象,则使用引用。
七、参考书籍
《C++ Primer Plus》