SQL进阶理论篇(十):数据库中的锁
文章目录
- 简介
- 按照锁的粒度进行划分
- 从数据库管理的角度进行划分
- 从程序员的角度进行划分
- 为什么共享锁会发生死锁?
- 参考文献
简介
索引和锁,是数据库中的两个核心知识点。
索引的相关知识点,在之前的几章里我们已经介绍的差不多了。接下来我们会重点讲解一下锁的相关知识。
事务的隔离级别,在底层就是通过锁来实现的。而加锁的目的,就是为了保证数据的一致性。
本节我们将重点描述以下几个问题:
- 锁有哪些划分方式?
- 为什么共享锁会发生死锁?
- 乐观锁和悲观锁的思想是什么?乐观锁有哪两种实现方式?
- 多个事务并发,发生死锁时该如何解决?如何降低死锁发生的概率?
按照锁的粒度进行划分
锁是用来对数据进行锁定的。我们可以根据被锁定对象的粒度大小来对锁进行划分,即:行锁、页锁和表锁。
行锁,按照行粒度对数据进行锁定。由于锁定力度小,所以发生锁冲突的概率低,理论上可以实现的并发度很高。但是按行加锁,对资源的消耗太大了,而且加锁也比较慢,容易出现死锁现象。
页锁,就是在页的粒度上对数据进行锁定。因为一个页上可以有很多数据行,所以在使用页锁的时候,很容易会出现数据浪费的情况(即使只是想锁小部分数据,也得锁上一整页),但是这种浪费有限,顶多就是浪费个几页。页锁的开销介于行锁和表锁之间,会出现死锁,并发度一般。
表锁,就是对数据表进行锁定。其锁定粒度很大,出现锁冲突的概率也很高,对并发的影响较大。好处是加锁的开销小,加锁很快。
以上三类锁是数据库中相对常见的三种锁,除此之外其实还有区锁和数据库锁,分别针对区和数据库的粒度。
不同的数据库或者不同的引擎支持的锁粒度并不相通。以MySQL为例,InnoDB支持行锁和表锁,但MyISAM只支持表锁,BDB引擎则支持页锁和表锁。Oracle支持行锁和表锁,SQLServer同时支持行锁、页锁和表锁。教程里整理的图如下:
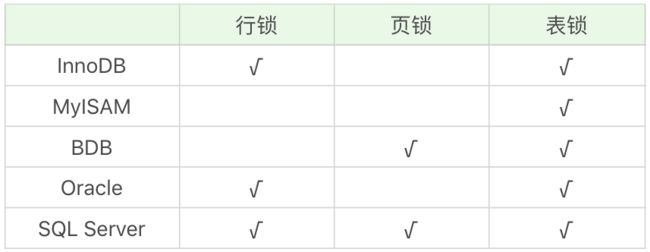
需要注意,在实际使用中,每个层级的锁数量是有限的,因为锁会占用内存空间,所以锁空间的大小是有限的。
当某个层级的锁数量超过了这个层级的阈值时,就会进行 锁升级。所谓的锁升级,就是将多个细粒度的锁升级成一个更大粒度的锁。比如说在InnoDB中,将多个行锁换成一个表锁,从而减少锁空间的内存占用,当然,代价是并行度降低了。
从数据库管理的角度进行划分
从数据库管理的角度来划分的话,就是我们经常会见到的两种锁:共享锁和排它锁。
共享锁,也叫做读锁或者S锁。共享锁锁定的数据可以被其他事务读取,但是不能修改。
在进行select的时候,就会把对象进行共享锁锁定,待到数据读取完毕后,才释放共享锁。这样子可以保证数据在读取时不会被修改。
我们也可以手动给某个对象加锁。
比如说给一个表加共享锁,可以使用:
LOCK TABLE product_comment READ;
这时候这张表就是只读模式了,如果此时再执行update语句,会提示:
ERROR 1099 (HY000): Table 'product_comment' was locked with a READ lock and can't be updated
解锁的话,可以使用:
UNLOCK TABLE product_comment;
如果是想给某一行加上共享锁,则可以写成这样:
SELECT comment_id, product_id, comment_text, user_id FROM product_comment WHERE user_id = 912178 LOCK IN SHARE MODE
排它锁,也叫做独占锁、写锁或者X锁。其锁定的数据只允许进行锁定的事务使用,其他事务无法对已锁定的数据进行读取或者修改。
比如给一个表添加排它锁,可以这么写:
lock table product_comment write;
此时,其他事务就不能在这张表上读或者更新了,有兴趣可以开两个MySQL客户端试一下。
释放锁的话,则是执行:
unlock table;
同样的,想在某个数据行上添加排它锁,可以写成这样:
SELECT comment_id, product_id, comment_text, user_id FROM product_comment WHERE user_id = 912178 FOR UPDATE;
当我们在对数据进行更新的时候,就是insert、delete或者update的时候,数据库就会自动使用排它锁,避免其他事务对该数据资源进行操作。
当我们想要获取某个数据表的排它锁的时候,需要先看下这张表里有没有已经上了排它锁。如果这个数据表中的某个数据行被上了行锁,我们就无法获取排它锁。这时候就引出来意向锁。
意向锁(Intent Lock),就是给更大一级的空间示意里面是否已经上过锁。在实际场景中,如果我们给某个数据行加上了排它锁,那么数据库会自动给更大一级的空间(比如说数据页或者数据表)加上一个意向锁,用来告知其它事务,这个数据页或数据表里已经有人上过排它锁了。其他事务再不需要一行一行去查看到底这个表里有没有锁。
于是,如果事务想要获取某些记录的共享锁,那么就会给整个表添加 意向共享锁 。同理,如果事务想要获取某些记录的排它锁,就会给整个表添加 意向排它锁。意向锁会告诉其他事务,有人已经锁定了部分记录,你无权进行某些全表扫描的操作了。
从程序员的角度进行划分
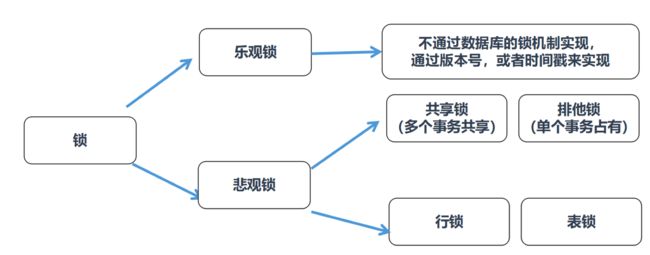
从程序员的角度来看待锁的话,可以把锁分为乐观锁和悲观锁。这两种锁实际上是两种不同的看待数据并发的思维方式,它们并不是锁。这个简单了解下就行。
乐观锁(Optimistic Locking),认为对同一数据的并发操作是属于小概率事件,可以忽略,因此不用每次都对数据进行加锁,也就是不采用数据库自身的锁机制,而是通过程序,采用版本号机制或者时间戳机制来实现。
什么是版本号机制呢?
就是在表里增加一个version字段,事务里第一次读的时候会先获取version字段的取值,接下来如果需要对数据做update,则会执行UPDATE ... SET version=version+1 WHERE version=刚刚的version取值。如果没有其他事务对这条数据做过修改,那么本次update就成功了,反之,本次update失败(因为version已经被其他事务修改过了,你保存的这个version值已经找不到数据了)。
什么是时间戳机制呢?
跟版本号一样,只不过添加的是一个时间戳字段,更新的时候判断时间戳字段跟之前读到的是不是一样,一样就成功更新,否则就失败。
所以乐观锁实际上就是程序员自己控制数据并发操作的权限,自行判断数据是否被并发修改过。
悲观锁(Pessimistic Locking),也是一种思想,对数据会被并发修改持保守态度,指代的是通过数据库本身的锁机制来保证数据一致性。
与行锁、共享锁等的关系如图:
乐观锁和悲观锁的适用场景:
- 乐观锁适合读操作多的场景,相对的写操作很少。其优点是不存在死锁问题。但是要完全排掉相关的数据库操作。
- 悲观锁则适合写操作多的场景。因为写操作的排它性,可以有效防止读写和写写的冲突。
为什么共享锁会发生死锁?
简单的说一个场景,就是事务A和B都对指定数据行进行了select查询,从而分别获取了对指定数据行的读锁,接着不提交事务,都各自对这条数据进行update。
对事务A来讲,其update会因为事务B持有读锁而失败,然后它会提示超时,重新执行事务。
而对事务B来讲,其update则会因为事务B持有读锁而失败,同样提示超时,重新执行事务。两边这就陷进死循环了,死锁发生。
当死锁发生的时候,只能让其它事务进行回滚,指定一个事务获取锁完成事务,然后将锁释放掉,再换下一个事务。
可以采取什么方式避免死锁的发生呢?
- 如果事务涉及多个表,各部分操作比较复杂,那么可以考虑一次性锁定所有资源,而不是逐步获取。比如说MyISAM引擎就是这样,总是一次性获取全部的锁,要么全部满足可以执行,要不就全部等待;
- 如果需要更新表中大部分数据,可以考虑使用表锁来代替行锁,即使用锁升级;
避免死锁,其实就是破坏产生死锁的四个必要条件:
- 互斥条件:同一时刻,资源只能被一个对象使用;
- 占有且等待条件:对象占有资源,同时在等待被其他对象占有的资源;
- 不可剥夺条件:已经分配的锁不能强制剥离,只能有持有该锁的事务主动释放;
- 循环等待条件:对象A占有对象B需要的资源,对象B占有对象A需要的资源。
以上条件必须同时具备,才能产生死锁。这个了解下就行。
参考文献
- 30丨锁:悲观锁和乐观锁是什么?