大数据Flink电商实时数仓实战项目流程全解(三)
DWD层日志数据分离
在数仓搭建过程中,对日志数据做分离是非常有必要而且有意义的,我们可以通过把日志分为启动、隔离、曝光、异常、页面等日志,可以计算获取访客数量、独立访客数量、页面跳转、页面跳出等统计指标数据;
那么在实时数仓和离线数仓中,这里有什么不同点呢?
异同点分析
在离线数仓的搭建过程中,我们可以获取一段时间内的离线日志数据,然后将日志数据进行过滤和分离,但是在实时数仓中,我们需要得到实时的流数据信息,如果按照离线数仓的方式进行,就不会得到一个实时的日志数据了。对此,我们将实时生成的日志数据发送到ODS层之后,根据Flink框架来对日志数据做一个实时分流;
项目思路:
//主要任务:
1 接收 Kafka 数据,并进行转换
读取kafka中的数据,并转化成为JSON格式,再来处理(这里JSON格式数据更方便处理)
2 修复新老访客状态
本身客户端业务有新老用户的标识,但是不够准确,需要用实时计算再次确认(不涉及业务操作,只是单纯的做个状态确认)。
is_new:1表示新用户,is_new:0表示老用户;但是可能存在数据状态丢失的问题;
同时如果是新访客且没有访问记录的话,会写入首次访问时间。同时比较日志数据中的is_new赋值是否正确,不对则进行更正;
(这里实际上是对脚本数据的一个修复,但是在实际做项目的时候,这里我都注释掉了,不然最后出来的数据全部是旧访客,导致最后的可视化效果非常差)
3 利用侧输出流实现数据拆分
根据日志数据内容,将日志数据分为 3 类, 页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流,
曝光日志输出到曝光日志侧输出流;(通过数据中的JSONObject来判断,启动日志和曝光日志关键词分别为"start"、"displays";
注意:在之前的Flink版本中,可以通过Split方法来把流进行分离,但在Flink1.12版本中取消了Split方法;
4 将分流后的数据写回到kafka的DWD层
(三个接收主题:
private static final String TOPIC_START = "dwd_start_log";
private static final String TOPIC_DISPLAY = "dwd_display_log";
private static final String TOPIC_PAGE = "dwd_page_log";
)
具体代码部分见项目中代码,这里就不列举了;这里主要讲一讲代码中需要注意的部分:
1.并行度的问题:
//1.2 设置并行度
env.setParallelism(1);
这里把并行度设置为1的主要目的是因为后续上传到Flink集群中的时候,Task Slot的数量不一定足够,所以尽量设置得低一点,但这不是必须,也可以在平常测试的过程中抬高这个数值。
2.检查点的设置:
//1.3设置checkpoint
//这里开启checkpoint的情况下,运行时必须开启HDFS;
//需要先开启hdfs根目录写入授权:hdfs dfs -chmod -R 777 /;
//或者设置好hadoop的用户名
//System.setProperty("HADOOP_USER_NAME","chenxu");
//每5000ms开启一次checkpoint
// env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// //超过1分钟失效
// env.getCheckpointConfig().setCheckpointTimeout(60000);
// //设置状态后端,这里用文件系统;
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall/checkpoint/baselogApp"));
要注意的是,如果要开启检查点,一点要现在HDFS中先创建好对应目录,不然检查点无法使用;在平常测试过程中,我都注释掉了这一部分内容;
3.kafka工具类的编写
//获取FlinkKafkaConsumer
public static FlinkKafkaConsumer<String> getKafkaSource(String topic, String groupId) {
//groupId代表消费者组
//Kafka连接的一些属性配置
Properties props = new Properties();
//消费者组信息
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//Bootstrap-server相关信息
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_SERVER);
//new SimpleStringSchema()反序列化类型;
//返回的就是kafka的consumer对象;
return new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(), props);
}
//封装FlinkKafkaProducer
public static FlinkKafkaProducer<String> getKafkaSink(String topic) {
//返回的就是kafka的producer对象;
return new FlinkKafkaProducer<String>(KAFKA_SERVER, topic, new SimpleStringSchema());
}
这就是把kafka的producer和consumer的生成封装到了一起,根据自己想要哪一种来自定义;注意这个工具类的最后一种producer生成方法不是这里使用的;
有了工具类之后,我们需要做的就是对日志数据进行分离;这里要注意原本数据生成的格式,建议先做一个小测试,在console中把数据打印出来看看格式:
//页面日志:
"common":{"ar":"420000","uid":"17","os":"Android 11.0","ch":"wandoujia","is_new":"0","md":"Honor 20s","mid":"mid_17","vc":"v2.1.134","ba":"Honor"},
"page":{"page_id":"cart","during_time":5649,"last_page_id":"good_detail"},
"ts":1625884881000
}
//启动日志:
{"common":{"ar":"370000","uid":"13","os":"Android 11.0","ch":"xiaomi","is_new":"1","md":"Xiaomi 9","mid":"mid_18","vc":"v2.1.132","ba":"Xiaomi"},
"start":{"entry":"icon","open_ad_skip_ms":0,"open_ad_ms":8833,"loading_time":12922,"open_ad_id":16},
"ts":1625884882000}
//错误日志:
{"common":{"ar":"370000","uid":"49","os":"iOS 13.2.3","ch":"Appstore","is_new":"1","md":"iPhone Xs Max","mid":"mid_15","vc":"v2.1.134","ba":"iPhone"},
"err":{"msg":" Exception in thread \\ java.net.SocketTimeoutException\\n \\tat com.atgugu.gmall2020.mock.log.bean.AppError.main(AppError.java:xxxxxx)","error_code":3653},
"page":{"page_id":"search","during_time":8270,"last_page_id":"home"},
"ts":1625884875000}
曝光日志(比较长,截取):
{"common":{"ar":"230000","uid":"36","os":"iOS 13.3.1","ch":"Appstore","is_new":"0","md":"iPhone 8","mid":"mid_19","vc":"v2.1.132","ba":"iPhone"},
"page":{"page_id":"home","during_time":17009},
"displays":[{"display_type":"activity","item":"2","item_type":"activity_id","pos_id":1,"order":1}...
"ts":1625884834000}
所以在做日志分离的时候,如果日志中包含start关键字,那么应该归为启动日志,从侧输出流中输出;否则即为页面日志,要注意:页面日志中包含了曝光日志,即包含了displays以及错误日志,但是错误日志在后续过程中不会对统计产生影响,所以这里只对displays做了一个额外的处理,因为displays部分数据中没有page_id字段,但是我们后续要通过这个字段做关联构建宽表,所以这里要给它加上,获取方法即从page字段中去获取;然后把获取到的数据从侧输出流中输出,页面日志从主流中输出;
最后把对应的流中的数据发送到dwd层对应的kafka主题中,这样dwd层的日志数据就处理完了;
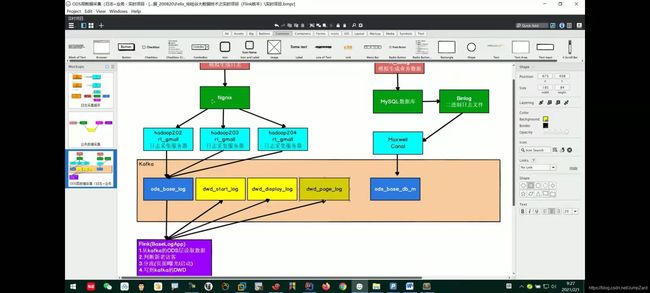
流程图如图所示: