探索Linux命名空间和控制组:实现资源隔离与管理的双重利器
介绍
Linux 命名空间(Namespace)
Linux 命名空间是一种隔离机制,允许将全局系统资源划分为多个独立的、相互隔离的部分,使得在不同的命名空间中运行的进程感知不到其他命名空间的存在。从而实现了对进程、网络、文件系统、IPC(进程间通信)等资源的隔离,减少了潜在的安全风险。例如,在容器中运行应用程序可以避免对主机系统的直接影响,从而提高了系统的安全性。
Linux 控制组(Cgroups)
控制组是一种资源管理机制,允许对进程组或任务组应用资源限制和优先级设置。它可以用来限制一组进程的资源使用,如 CPU、内存、磁盘 I/O 等,从而实现资源的分配和控制。
简单来说 Cgroups 可以理解为是房子的土地面积,限制了房子的大小 ,而 Namespace 是房子的墙,与邻居互相隔离。

通过使用命名空间和控制组,可以更有效地使用系统资源,避免资源浪费,并确保关键任务获得足够的资源支持,从而提高系统性能和效率。这些功能对于现代的云计算和容器化部署是至关重要的。最典型的容器技术 Docker 就是利用 namespace 和 cgroup 实现的。
Linux 命名空间(Namespace)
命名空间类型
下面是 Linux 提供的 Namespace 类型,通过这些命名空间的组合,可以实现复杂的隔离和虚拟化配置

PID 命名空间
Linux PID 命名空间是 Linux Namespace 的一种类型,用于隔离进程 ID。在一个 PID 命名空间中,每个进程拥有独立的进程 ID,这样在不同的命名空间中可以有相同的进程 ID,而不会产生冲突。每个子 PID 命名空间中都有 PID 为 1 的 init 进程,对应父命名空间中的进程,父命名空间对子命名空间运行状态是不隔离的,但是每一个子命名空间是互相隔离的。
如下图:在子命名空间 A 和 B 中都有一个进程 ID=1 的 init 进程,这两个进程实际上是父命名空间的 55 号和 66 号进程 ID,虚拟化出来的空间而已。

UTS 命名空间
Linux UTS 命名空间用于隔离主机名和域名。在 UTS 命名空间中,每个进程可以拥有独立的主机名和域名(nodename,domainname),这样可以在不同的命名空间中拥有不同的标识,从而实现了主机名和域名的隔离。
nodename: 是用于标识主机的独特名称,通常也被称为主机名。它用于在网络中唯一地标识一台计算机
domainname: 是主机的域名部分,通常用于标识所属的网络域。域名通常由多个部分组成,按照从右到左的顺序,每个部分之间用点号 "." 分隔。域名用于将主机名与特定的网络域关联起来,从而帮助在全球范围内定位和访问计算机
在容器技术中,利用 UTS Namespace 隔离后,容器内的进程可以拥有独立的主机名和域名,而不会与宿主系统或其他容器中的进程产生冲突。这样,容器内的应用程序可以认为它们在独立的主机中运行,从而更容易进行配
Mount 命名空间
Linux Mount Namespace 用于隔离文件系统挂载点。通过 Mount Namespace,不同的进程可以在不同的挂载点上看到不同的文件系统层次结构,即使在同一台主机上运行。这种隔离使得进程在一个 Mount Namespace 中的挂载操作对其他 Mount Namespace 中的进程不可见,从而实现了文件系统层面的隔离。
在容器技术中,利用 Mount Namespace 隔离后,容器内部的文件系统挂载与宿主系统和其他容器相互隔离。这样,每个容器可以拥有独立的文件系统视图,容器内的进程只能访问自己的文件系统层次结构,而无法访问其他容器或宿主系统的文件系统。
Network 命名空间
Linux Network Namespace 用于隔离网络栈。通过 Network Namespace,不同的进程可以拥有独立的网络设备、IP 地址、路由表、网络连接和网络命名空间中的其他网络资源。这种隔离使得进程在一个 Network Namespace 中的网络配置和状态对其他 Network Namespace 中的进程不可见,从而实现了网络层面的隔离。
在容器技术中,利用 Network Namespace 隔离后,容器内部的进程拥有独立的网络环境,从而使得容器在网络上彼此隔离。每个容器可以有自己的网络设备、IP 地址、路由表和网络连接,容器之间不会干扰彼此,也不会干扰宿主系统。
User 命名空间
Linux User Namespace 用于隔离用户和用户组 ID。通过 User Namespace,不同的进程可以拥有独立的用户和用户组 ID,这样可以在不同的命名空间中拥有不同的身份标识,从而实现了用户和用户组的隔离。
在容器技术中,利用 User Namespace 隔离后,容器内的进程可以拥有独立的用户和用户组 ID,而不会与宿主系统或其他容器中的用户产生冲突。这样,容器内的应用程序可以以普通用户身份运行,而不需要在宿主系统中创建相同的用户账号。
在 Docker 中默认是不启用 User Namespace 隔离的,主要是因为开启后需要做很多特殊的配合和管理,例如隔离后容器内的用户和宿主上的用户已经不是相同的身份了,那么可能会影响访问文件系统。
IPC 命名空间
Linux IPC 命名空间用于隔离进程间通信资源。在 IPC 命名空间中,每个命名空间都有独立的 IPC 资源,如消息队列、信号量和共享内存,使得不同命名空间中的进程无法直接访问其他命名空间的 IPC 资源,从而实现了 IPC 资源的隔离。
在容器技术中,利用 IPC Namespace 隔离后,容器内的进程拥有独立的 IPC 资源,从而避免不同容器之间的进程干扰和资源冲突。每个容器都可以有自己的 IPC 命名空间,使得容器内的进程在进行进程间通信时只能访问属于同一命名空间的 IPC 资源,而无法直接访问其他容器的 IPC 资源。
实战
创建和管理命名空间
在 Linux 系统中提供了以下几种常用的创建和管理命名空间的 API:
-
clone:使用 clone 系统调用创建一个新进程时可以通过指定一个或多个上面列出的命名空间标志参数来创建新的命名空间,并且新进程的子进程也会默认被包含在新的命名空间内
-
unshare:使用 unshare 系统调用将一个已存在的进程放入新的命名空间。它可以指定一个或多个上面列出的命名空间标志参数,创建具有指定类型的命名空间,并将当前进程或其他指定进程放入其中
-
setns: 使用 setns 系统调用允许进程将自己放入已经存在的命名空间中,而无需创建新的进程。通过 setns 系统调用,进程可以切换到指定类型的命名空间中,与其他已存在于该命名空间中的进程共享同一个隔离环境
隔离进程
在这段代码中执行 sh 命令,并设置了系统调用 clone flage 参数为 CLONE_NEWPID,意思是当执行 main 方法时会创建一个新的进程(sh)并创建了 PID 命名空间,使 sh 进程与 main 进程隔离。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWPID,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}当执行 go run main.go 后,打开新的 shell 页面,执行 ps aux 看一下启动的进程号=156

然后利用 pstree 看一下进程树,可以发现通过 main 调用起来的 sh 命令进程 ID=678

那么我们回到执行 go run main.go 的 shell 页面中,执行 ehco $$,可以发现当前进程 ID=1,这可以证明,在新的 PID 命名空间下进程 ID 1 映射的就是进程 ID 678 , 从而可以确认进程已经被成功隔离。

隔离网络
在上一段代码的基础上,我们只需要新增系统调用 clone flage 参数 CLONE_NEWNET,当执行 main 方法时会创建一个新的进程(sh)并创建了 PID 和 NET 命名空间,使 sh 进程与 main 进程&网络同时隔离。
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWPID | syscall.CLONE_NEWNET,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatal(err)
}
}当执行 go run main.go 后,打开新的 shell 页面,执行 ifconfig,可以看到网络相关的信息

然后在 go run main.go 运行的 shell 页面,执行 ifconfig,可以发现什么信息都没有,这说明网络也已经被隔离了。

Linux 控制组(Cgroups)
Cgroups 介绍
在 Linux 中,cgroups(Control Groups)是一种用于资源管理和限制进程资源使用的机制。它允许管理员将一组进程组织在一个或多个 cgroups 中,并为每个 cgroup 分配特定的资源限制,如 CPU、内存、磁盘 I/O、网络带宽等。通过 cgroups,可以更好地控制系统中各个进程的资源使用,实现资源隔离和公平共享,防止某些进程占用过多资源导致系统负载过高。
核心组件
Cgroups 主要有三个核心组件组成:
子系统(subsystem):子系统是用于管理特定类型资源的模块,每个子系统负责管理一类资源,例如 CPU、内存、磁盘 I/O、网络带宽等。
Cgroup Hierarchies(Cgroup 层级树):Hierarchies 是用于组织和管理 Cgroup 的结构。一个 Hierarchies 由一个或多个 subsystem 组成。Hierarchies 形成树状结构,每个节点都是一个 Cgroup,同一层级中的 Cgroup 之间是平级的。Hierarchies 允许 Cgroup 在不同的 subsystem 中进行组合和嵌套,形成多层的资源管理结构。系统会默认为每个 subsystem 创建一个默认的 Hierarchy。
Cgroups(控制组):Cgroup 是最终的资源管理单元,它是一组进程的集合,被组织在一个特定的 Cgroup 层级中,并受到该层级中控制器的资源限制和管理。
核心组件关系

关系说明如下:
-
默认系统会为所有的 subsystem 创建 Hierarchy 树,默认 cgroup 根路径在/sys/fs/cgroup 目录下,在/sys/fs/cgroup 下可以看到全部的 subsystem 对应的 Hierarchy 树
-
系统创建了新的 Hierarchy 后,默认所有进程都会加入到树中根节点的 cgroup 中,例如可以到/sys/fs/cgroup/cpu/tasks 文件中看到所有的进程列表
-
一个 subsystem 只能附加到一个 Hierarchy 树上
-
一个 Hierarchy 树可以对应多个 subsystem
-
一个进程可以作为多个 cgroup 的成员,但是这些 cgroup 必须在不同的 Hierarchy 树中
-
一个进程 fork 出子进程时,子进程和父进程默认是在同一个 cgroup 中的,也可以自行移动到其他 cgroup 中
subsystem(常见子系统)列表
cpu
用于管理 CPU 资源。它允许设置进程的 CPU 使用率和时间片配额,从而限制进程的 CPU 占用,以下是 cpu 子系统的一些常见控制文件:
-
cpu.cfs_quota_us:这个文件用于设置 cgroup 中进程的 CPU 配额。单位为微秒(μs),表示在每个cpu.cfs_period_us微秒内,cgroup 中的进程可以使用的 CPU 时间量。如果cpu.cfs_quota_us的值为 -1,则表示 cgroup 中的进程没有 CPU 使用限制。 -
cpu.cfs_period_us:这个文件用于设置 cgroup 中进程的 CPU 时间周期。单位为微秒(μs),表示在一个周期内,cgroup 中的进程可以使用的 CPU 时间总量。
cpuacct
cpuacct:用于统计和记录进程组(cgroup)中的 CPU 使用情况,以下是 cpuacct 子系统的一些常见统计文件:
-
cpuacct.usage: 这个文件记录了 cgroup 中所有进程的 CPU 使用时间总和,以纳秒为单位。可以通过读取这个文件来查看 cgroup 中的所有进程所消耗的 CPU 时间。 -
cpuacct.usage_percpu: 这个文件记录了 cgroup 中每个 CPU 核心的 CPU 使用时间,以纳秒为单位。如果系统有多个 CPU 核心,这个文件会显示每个核心的 CPU 使用时间。 -
cpuacct.stat: 这个文件提供了关于 CPU 使用时间的详细统计信息,包括用户态和内核态的 CPU 时间。
cpuset
用于管理 CPU 亲和性和节点分配。可以设置进程在哪些 CPU 核心上运行,以及可以使用哪些内存节点,以下是 cpuset 子系统的一些常见控制文件
-
cpuset.cpus:这个文件用于设置 cgroup 中进程可以使用的 CPU 核心。可以使用 CPU 核心的列表、范围(如 "0-2,4"),或使用特定的 CPU 标识符(如 "0-2,4,^1" 表示使用 0、2、4 号核心,但不使用 1 号核心) -
cpuset.mems:这个文件用于设置 cgroup 中进程可以使用的内存节点(NUMA Node)。可以使用节点的列表或范围,如 "0,1" 表示使用节点 0 和节点 1 -
cpuset.cpu_exclusive:这个文件用于设置是否将 cgroup 中的 CPU 分配限制为独占。设置为 1 表示独占,只有在没有其他 cgroup 使用时,才允许使用指定的 CPU 核心 -
cpuset.mem_exclusive:这个文件用于设置是否将 cgroup 中的内存节点分配限制为独占。设置为 1 表示独占,只有在没有其他 cgroup 使用时,才允许使用指定的内存节点。
memory
memory:用于管理和限制进程组(cgroup)中的内存资源使用。memory 子系统允许为每个 cgroup 设置内存限制,并控制进程在 cgroup 中使用的内存量。 以下是 memory 子系统的一些常见控制文件:
-
memory.limit_in_bytes:这个文件用于设置 cgroup 中进程的内存限制。可以设置一个整数值,表示 cgroup 中所有进程可使用的内存上限,单位为字节。超过该限制的内存请求将被拒绝,进程可能会受到 OOM(Out of Memory)事件的影响。 -
memory.soft_limit_in_bytes:这个文件用于设置 cgroup 中进程的软内存限制。软内存限制是一个较低的限制值,当系统内存不足时,它可以防止进程抢占过多的内存资源,但通常不会导致 OOM 事件 -
memory.memsw.limit_in_bytes:这个文件用于设置 cgroup 中进程的内存+交换空间(swap)的限制。可以设置一个整数值,表示 cgroup 中所有进程可使用的内存+swap 的上限,单位为字节。 -
memory.memsw.usage_in_bytes:这个文件记录了 cgroup 中所有进程当前的内存+swap 使用量,以字节为单位。
devices
用于管理和限制进程组(cgroup)中的设备访问权限。devices 子系统允许在 cgroup 中配置哪些设备可以被进程访问以及如何访问这些设备。 以下是 devices 子系统的一些常见控制文件:
-
devices.allow: 这个文件用于设置允许进程在 cgroup 中访问的设备列表。可以通过设备的主设备号和次设备号来指定具体的设备。例如,c 1:3 rwm表示允许进程在 cgroup 中读取、写入和执行设备号为 1:3 的字符设备 -
devices.deny: 这个文件用于设置不允许进程在 cgroup 中访问的设备列表。与devices.allow相反,管理员可以在这里指定不允许访问的设备。
net_cls
用于将进程组(cgroup)中的网络流量标记(classify)为特定的网络类别(class)。net_cls 子系统允许为 cgroup 中的进程设置一个网络类别标记,从而可以在 Linux 内核的网络层对网络流量进行分类和管理。 以下是 net_cls 子系统的常见控制文件:
-
net_cls.classid: 这个文件用于设置 cgroup 中进程的网络类别标记。网络类别标记是一个 32 位无符号整数,用于标识特定的网络类别。当进程发送或接收网络流量时,Linux 内核会根据这个标记来对网络流量进行分类。
net_cls子系统只负责将进程的网络流量标记为特定的网络类别,它本身并不限制网络带宽或执行其他网络控制。网络流量的实际控制需要依赖其他工具(如 tc)来完成。因此,在使用net_cls子系统时,需要结合其他网络管理工具来实现更全面的网络控制和管理。
net_prio
用于为进程组(cgroup)中的网络流量设置网络优先级(network priority)。net_prio 子系统允许管理员为 cgroup 中的进程设置特定的网络优先级,以控制其在网络传输中的优先级。 以下是 net_prio 子系统的常见控制文件:
-
net_prio.ifpriomap: 这个文件用于设置 cgroup 中进程的网络优先级映射(interface priority map)。通过配置映射关系,可以将 cgroup 中的进程的网络优先级映射到特定的网络接口(network interface)上。 -
net_prio.prioidx: 这个文件用于设置 cgroup 中进程的默认网络优先级索引(priority index)。优先级索引是一个整数值,表示进程的默认网络优先级。
net_prio子系统在容器技术中特别有用,当多个容器运行在同一主机上时,可以为每个容器的 cgroup 设置不同的网络优先级,以实现容器之间的网络隔离和资源控制。这样可以确保不同容器之间的网络传输不会相互干扰,提高系统的网络性能和稳定性。
blkio
用于管理和限制进程组(cgroup)中的块设备(Block Device)I/O(Input/Output)资源使用。blkio 子系统允许管理员为每个 cgroup 设置块设备的 I/O 限制和控制。以下是 blkio 子系统的常见控制文件:
-
blkio.weight: 这个文件用于设置 cgroup 中进程的块设备 I/O 权重。块设备 I/O 权重用于在多个 cgroup 之间进行块设备 I/O 资源的分配,权重越高的 cgroup 获得越多的块设备 I/O 资源。 -
blkio.time: 这个文件用于设置 cgroup 中进程的块设备 I/O 时间片(time slice)配额。可以限制 cgroup 中进程在一定时间内的块设备 I/O 操作 -
blkio.throttle.read_bps_device: 这个文件用于设置 cgroup 中进程的块设备读取速率限制。可以设置块设备的主设备号和次设备号以及读取速率的限制,防止进程过度读取设备。 -
blkio.throttle.write_bps_device: 这个文件用于设置 cgroup 中进程的块设备写入速率限制。可以设置块设备的主设备号和次设备号以及写入速率的限制,防止进程过度写入设备。
pids
用于限制进程组(cgroup)中的进程数量。pids 子系统允许管理员为每个 cgroup 设置允许的最大进程数,从而控制 cgroup 中可以运行的进程数量。pids 子系统只限制进程数量,并不限制其他资源, 以下是 net_prio 子系统的常见控制文件:
-
pids.max: 这个文件用于设置 cgroup 中允许的最大进程数。可以设置一个整数值,表示 cgroup 中可以运行的最大进程数量。 -
pids.current: 这个文件显示当前 cgroup 中的进程数量。
实战
创建和管理控制组
首先我们可以到/sys/fs/cgroup 目录下查看系统默认创建的 Hierarchy 树有哪些:

然后我们可以到/home 目录下创建一个自定义的 Hierarchy 树:
-
首先创建 cgroup-1 文件夹
-
挂载 Hierarchy 树到 cgroup-1 文件夹上
![]()
-
挂载后进入到 cgroup-1 文件夹中可以看到一些自动生成的文件

-
cgroup.clone_children: cpuset 的 subsystem 会读取这个配置文件,如果这个值是 I ( 默 认是 0),子 cgroup 才会继承父 cgroup 的 cpuset 的配置 。
-
cgroup.proc: 树中当前节点 cgroup 中的进程组 ID,现在的位置是在根节点,这个文 件中会有现在系统中所有进程组的 ID
-
cgroup.sane_behavior:这个文件只存在于root cgroup目录下,该文件控制了一个叫做CGRP_ROOT_SANE_BEHAVIOR的位。由于cgroup一直再发展,很多子系统有很多不同的特性,内核用CGRP_ROOT_SANE_BEHAVIOR来控制使能某些特性和关闭某些特性。
-
notify_on_release 和 release_agent: 两者结合使用,notify_on_release 表示当这个 cgroup 最后一个进程退出的时候是否执行了 relase_agent,release_agent 是个路径通常用作进程退出后自动清理掉不在使用的 cgroup
-
tasks:标识该 cgroup 下面的进程 ID,如果把一个进程写入到 tasks 文件中,则代表把对应进程加入到 cgroup 中 , 这里可以打开看一下 tasks 文件会发现如上面介绍所说:系统创建了新的 Hierarchy 后,默认所有进程都会加入到树中根节点的 cgroup 中
-
然后我们可以在 cgoup-1 Hierarchy 树创建两个子节点
![]()
-
然后进入到其中一个 cgroup-2 子 cgroup 节点中,可以发现同样会默认生成一些文件,子 cgroup 默认会集成父 cgroup 的属性。

注意在子 cgroup 中默认 tasks 文件中不会有任何进程 ID。下面我们将往 cgroup 中添加进程,来实现资源控制。
使用控制组限制资源
在 cgroup-2 文件夹中,我们输出当前进程 id 到 tasks 文件中,然后通过查看 proc 中对应的 cgroup 信息可以看到当前进程已经被添加到 cgroup-2 控制组下了。

不过到目前为止,我们自定义的 cgroup-1 Hierarch 树还没有绑定 subsystem,所以即使把当前进程加入到了 cgroup-1 树中的 cgroup-2 控制组下也不会有任何资源控制的效果。
那么我们接下来使用系统默认根据 subsystem 创建的 Hierarch 树来进行资源控制。
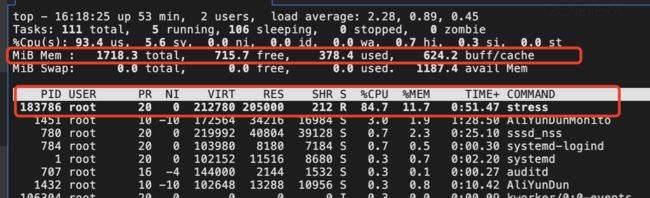
-
首先利用压测工具 stress 启动一个内存占用的进程
-
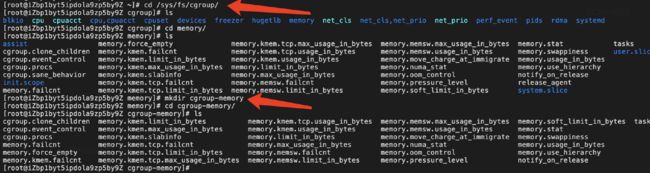
进入到/sys/fs/cgroup/memory 目录
-
创建 cgroup-memory cgroup
-
设置当前 cgroup 最大内存占用为 100M

-
将当前进程移动到 cgroup-memory 中
![]()
-
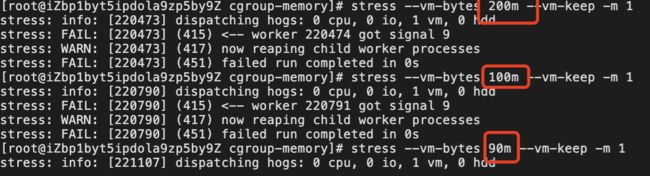
再次启动 stress,查看内存占用,发现占用 200M 程序启动时就报错了,当设置填充 90M 时程序才正常运行。由此可见内存资源限制生效了
应用场景
-
容器化部署:最典型的使用命名空间和控制组的场景就是容器化部署,如Docker
-
资源管理:在多租户或共享资源的环境中,使用命名空间和控制组可以实现对资源的细粒度管理,如按服务分级,对不同级别进程按级别划分资源,避免低优先级进程抢占高优先级进程资源。
-
安全隔离:防止恶意程序对系统的攻击。例如,将不可信的应用程序运行在特定的命名空间中,限制其访问敏感文件或系统资源,以确保主机系统的安全性。
-
进程侵入:命名空间的隔离特性使得进程可以在不同的命名空间中运行,这为进程的监控和调试以及故障注入提供了便利。可以在特定的命名空间中追踪和调试以及故障注入进程,而不会对其他命名空间的进程造成干扰(后面文章中会介绍的云原生故障注入,就是利用Cgroup和Namespace实现的)
-
很多其他场景...
总结
在本文中我们深入探讨了Linux命名空间(Namespace)和控制组(Cgroups)这两个关键技术。通过命名空间,我们可以实现对资源的隔离,让进程在独立的空间中运行,增强系统的安全性。而通过控制组,我们可以有效地管理和限制进程的资源使用,避免资源浪费,提高了系统性能。
作者介绍
张斌斌(Github 账号:binbin0325,公众号:柠檬汁Code)Sentinel-Golang Committer 、ChaosBlade Committer 、 Nacos PMC 、Apache Dubbo-Go Committer。目前主要关注于混沌工程、中间件以及云原生方向。
