RocketMQ Schema——让消息成为流动的结构化数据
本文作者:许奕斌,阿里云智能高级研发工程师。
Why we need schema
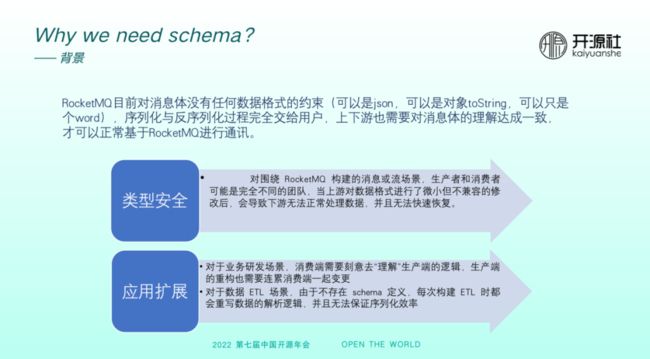
RocketMQ 目前对于消息体没有任何数据格式的约束,可以是 JSON ,可以是对象 toString ,也可以只是 word 或一段日志,序列化与反序列化过程完全交给用户。业务上下游也需要对于消息体的理解达成一致,方可基于 RocketMQ 进行通讯。而以上现状会导致两个问题。
首先,类型安全问题。假如生产者或消费者来自完全不同的团队,上游对数据格式进行了微小但不兼容的改动,可能导致下游无法正常地处理数据,且恢复速度很慢。
其次,应用扩展问题。对于研发场景,虽然 RocketMQ 实现了链路上的解耦,但研发阶段的上游与下游依然需要基于消息理解做很多沟通和联调,耦合依然较强,生产端的重构也需要连累消费端一起变更。对于数据流场景,如果没有 schema 定义,每次在构建ETL时需要重写整个数据解析逻辑。

RocketMQ schema 提供了对消息的数据结构托管服务,同时也为原生客户端提供了较为丰富的序列化/反序列化 SDK ,包括 Avro、JSON、PB等,补齐了 RocketMQ 在数据治理和业务上下游解耦方面的短板。
如上图所示,在商业版 Kafka 上创建 topic 时,会提醒维护该 topic 相关 schema。如果维护了 schema ,业务上下游看到该 topic 时,能够清晰地了解到需要传入什么数据,有效提升研发效率。
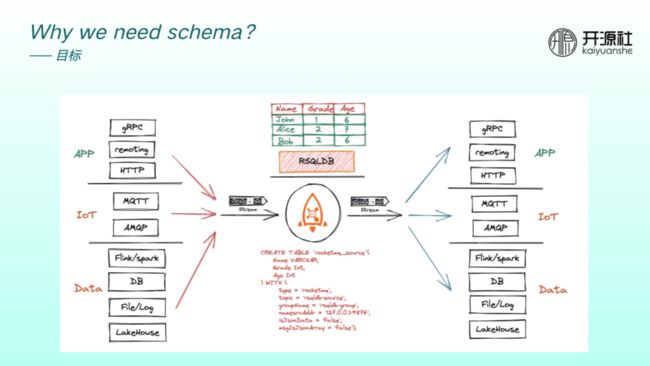
我们希望 RocketMQ 既能够面向 App 业务场景,也能够面向 IoT 微消息场景,还能面向大数据场景,以成为整个企业的业务中枢。
加入 RSQLDB 之后,用户可以用 SQL 方式分析 RocketMQ 数据。RocketMQ 既可以作为通信管道,具备管道的流特性,又可以作为数据沉淀,即具备数据库特性。如果 RocketMQ 要同时向流式引擎和 DB 引擎靠近,其数据定义、规范以及治理变得异常重要。
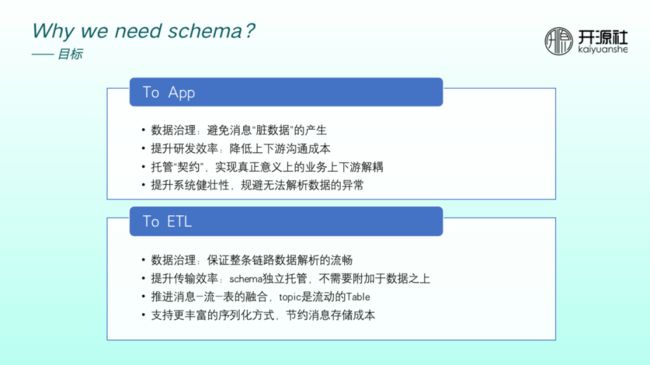
面对业务消息场景时, 我们期望 RocketMQ 加入 schema 之后能够拥有以下优势:
①数据治理:避免消息脏数据产生,避免 producer 产生格式不规范的消息。
②提升研发效率:业务上下游研发阶段或联调阶段沟通成本降低。
③托管“契约”:将契约托管后,可以实现真正意义上的业务上下游解耦。
④提升整个系统的健壮性:规避下游突然无法解析等数据异常。
面对流场景,我们期望 RocketMQ 具备下列优势:
①数据治理:能够保证整条链路数据解析的流畅性。
②提升传输效率:schema 独立托管,无需附加到数据之上,提升了整个链路传输的效率。
③推进消息-流-表的融合,topic 可以成为动态表。
④支持更丰富的序列化方式,节约消息存储成本。当前大部分业务场景均使用 JSON 解析数据,而大数据场景常用的 Avro 方式更能节省消息存储成本。
整体架构
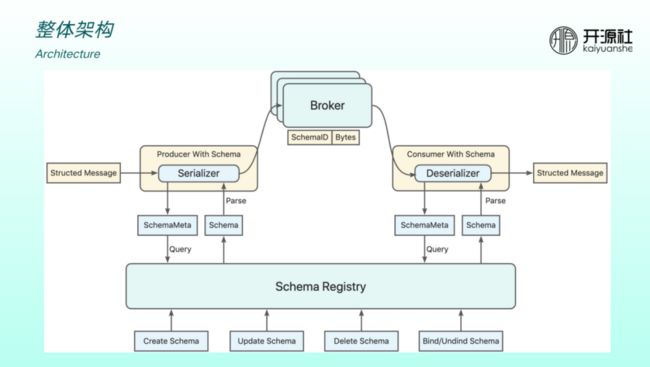
引入了 Schema Registry 后的整体架构如上图所示。在原有最核心的 producer 、broker 和 Consumer 架构下引入 Schema Registry 用于托管消息体的数据结构。
下层是 schema 的管理 API ,包括创建、更新、删除、绑定等。与 producer 和 Consumer 的交互中,producer 发送给 broker 之前会做序列化。序列化时会向 registey 查询元数据然后做解析。Consumer 侧可以根据 ID 、topic 查询,再做反序列化。RocketMQ 的用户在收发消息时只需要关心结构体,无需关心如何将数据序列化和反序列化。
服务端

Schema Registry 的部署方式与 NameServer 类似,与 broker 分离部署,因此 broker 不必强依赖于 Schema Registry ,采用了无状态部署模式,可以动态扩缩容。持久化方面,默认使用 Compact Topic5.0 新特性,用户也可自行实现存储插件,比如基于MySQL 或 Git 。管理接口上提供 Restful 接口做增删改查,也支持 schema 与多个 topic 绑定\解绑。
应用启动之后,提供了自带 Swagger UI 做交互版本演进,提供 SchemaName 维度的版本演进和相应的兼容性校验,支持七种兼容性策略。元信息方面,每一个 schema 版本都会向用户暴露全局唯一 RecordID,用户获取到 RecordID 后可以到 registry 查找唯一 schema 版本。
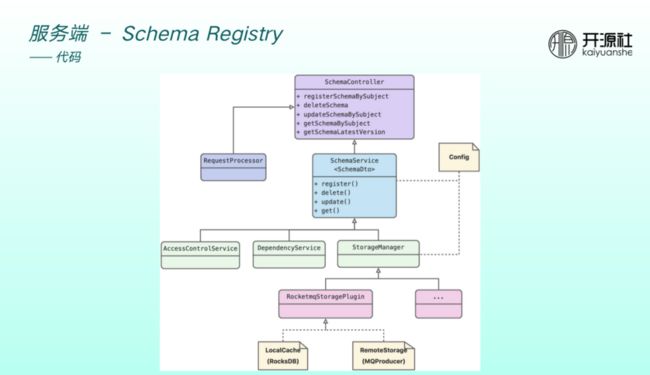
代码设计如上图。主要为 spring boot 应用,暴露出一个 restful 接口。Controller 底下是 Service 层,涉及到权限校验、jar 包管理、StoreManager,其中 StoreManager 包括本地缓存和远端持久化。

Schema Registry 的核心概念与 RocketMQ 内核做了对齐。比如 registry 有 cluster 概念,对应内核中的 cluster,Tenant 对应 NameSpace 概念, subject 对应内核中的 topic。每一个 schema 有唯一名称 SchemaName,用户可以将自己应用的 Java 类名称或全路径名称作为 SchemaName ,保证全局唯一即可,可以绑定到 subject 上。每一个 schema 有唯一 ID ,通过服务端雪花算法生成。SchemaVersion 的每一次更新都不会改变 ID,但是会生成单调递增的版本号,因此一个 schema 可以具备多个不同版本。
ID 和 version 叠加在一起生成了一个新概念 record ID ,暴露给用户用于唯一定位某一个 schema 版本。SchemaType 包括 Avro、Json、Protobuf等常用序列化类型,IDL用于具体描述 schema 的结构化信息。
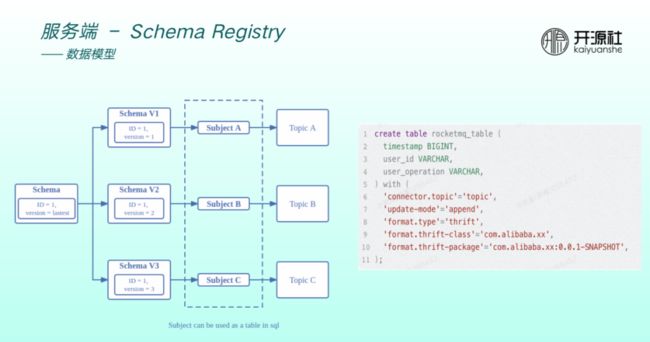
每一个 schema 有一个 ID,ID 保持不变,但可以有版本迭代,比如从 version 1 到 version 2 到 version 3,每一个 version 支持绑定不同的 subject 。Subject 可以近似地理解为 Flink table 。比如右图为 使用Flink SQL 创建一张表,先创建 RocketMQ topic 注册到 NameServer。因为有表结构,同时要创建 schema 注册到 subject 上。因此,引入 schema 之后,可以与 Flink 等数据引擎做无缝兼容。
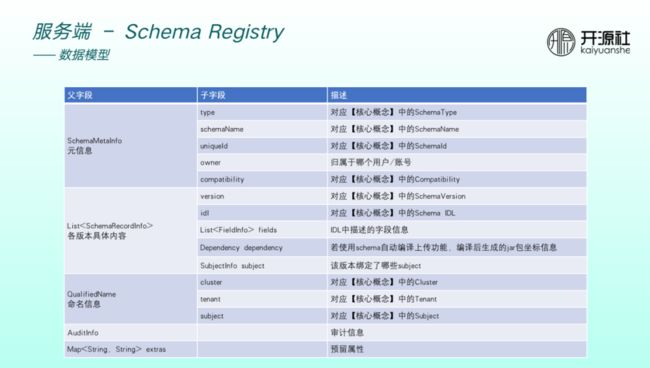
Schema 主要存储以下类型的信息。
-
元信息:包括类型、名称、 ID 、归属于以及兼容性。
-
个版本具体内容:包括版本号、IDL、IDL中字段、jar包信息、绑定的 subject。
-
命名信息:包括集群、租户、 subject。
-
审计信息。
-
预留属性。
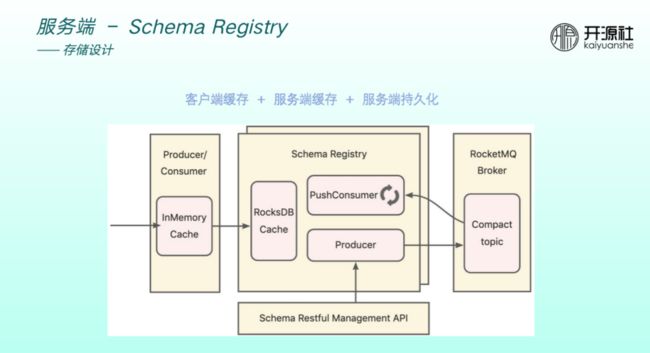
具体存储设计分为三层。
客户端缓存:如果 producer Consumer 每一次收发消息都要与 registy 交互,则非常影响性能和稳定性。因此RocketMQ实现了一层缓存,schema 更新频率比较低,缓存可以满足大部分收发消息的请求。
服务端缓存:通过 RocksDB 做了一层缓存。得益于 RocksDB,服务重启和升级均不会影响本身的数据。
服务端持久化:远端存储通过插件化方式实现,使用 RocketMQ5.0 的 compact topic 特性,其本身能够支持 KV 存储的形式。
远端持久化与本地缓存同步通过 registey 的 PushConsumer 做监听和同步。
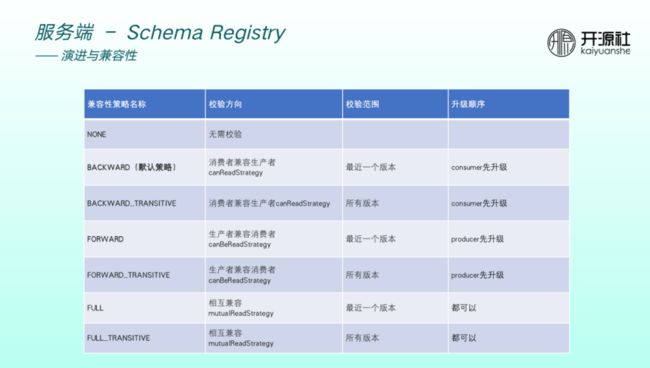
目前 Schema Registry 支持7种兼容性策略。默认为 backward ,小米公司内部实践也验证了默认策略基本够用。校验方向为消费者兼容生产者,即演进了 schema 之后,是需要先升级Consumer ,Consumer 的高版本可以兼容生产者的低版本。
如果兼容策略是 backward_transative ,则可以兼容生产者的所有版本。
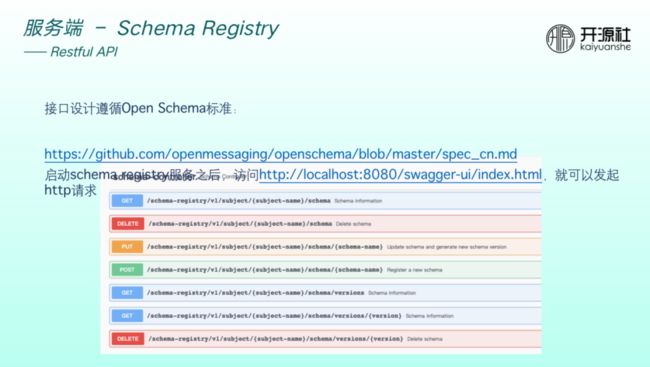
接口设计均遵循 Open Schema 标准,启动 registry 服务之后,只要访问 local host 的 swagger UI 页面即可发起http请求,自己做 schema 管理。
客户端设计
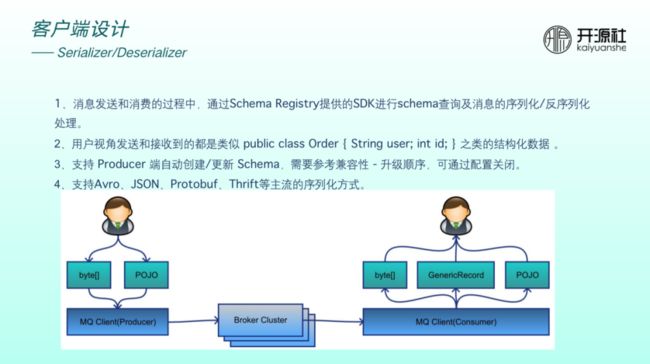
客户端在消息收发过程中,需要提供 SDK 做 schema 查询以及消息的序列化和反序列化处理。
如上图,以前用户在发送时传递字节数组,接收时也是字节数组。现在我们希望发送端关心一个对象,消费端也关心一个对象。如果消费端没有感知到对象属于什么类,也可以通过 generate record 等通用类型理解消息。因此,用户视角发送和接收到的均为类似于 public class Order 等结构化数据。
Producer 也可以支持自动创建和更新 schema ,也支持 Avro、JSON 等主流的序列化方式。

设计原则为不入侵原客户端代码,不使用 schema 则消息收发完全不受影响,用户不感知 schema ,感知的是序列化和反序化类型。且支持在序列化过程中按最新版本解析、按指定 ID 解析。另外,为了满足 streams 等非常强调轻量的场景,还支持了without Schema Registry 的消息解析。
上图代码为 schema 核心 API 序列化和反序列化。参数非常简单,只要传入 topic 、原始消息对象,即可序列化为 message body 格式。反序列化同理,传入 subject 和原始字节数组,即可将对象解析并传递给用户。
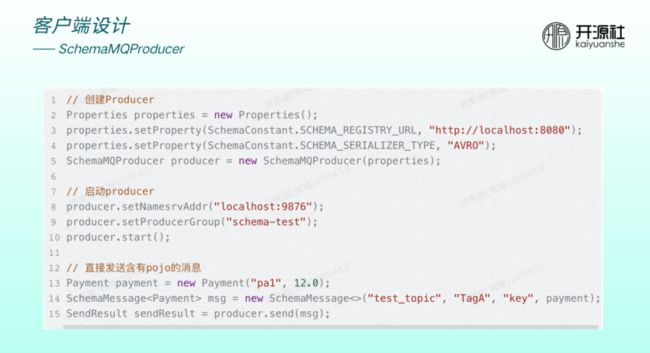
上图为集成了 schema 之后的 producer 样例。创建 producer 需要传入registry URL和序列化类型。发送时传入的并非字节数组,而是原始对象。
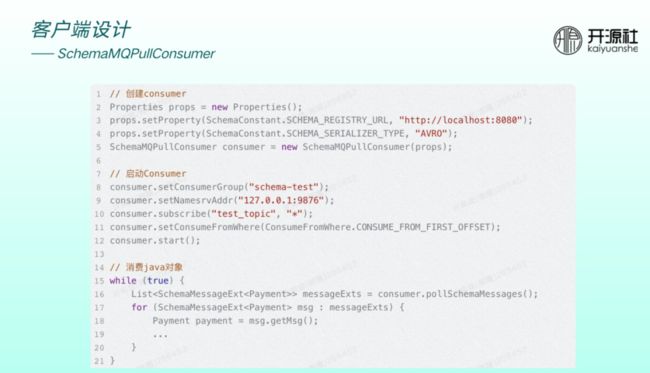
消费端创建时,需指定 registry URL 和序列化类型,然后通过 getMessage 方法直接获取泛型或实际对象。
ETL场景落地

RocketMQ flink catlog 主要用于描述 RocketMQ Flink 的Table、Database等元数据,因此基于 Schema Registry 实现时需要天然对齐一些概念。比如 catalog 对应 cluster , database 对应 Tenant, subject 对应 table 。
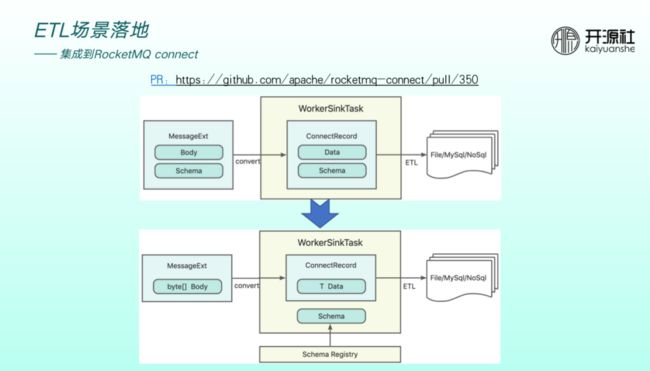
异构数据源的转化过程中,非常重要的一个环节为异构数据源 schema 如何做转换,涉及到 converter 。ConnectRecord 会将 data 和 schema 放在一起做传输,如果converter 依赖 registry 做 schema 的第三方托管,则ConnectRecord 无需将原来的 data 和 schema 放于一起,传输效率将会提高,这也是 connect 集成 Schema Registry 的出发点。
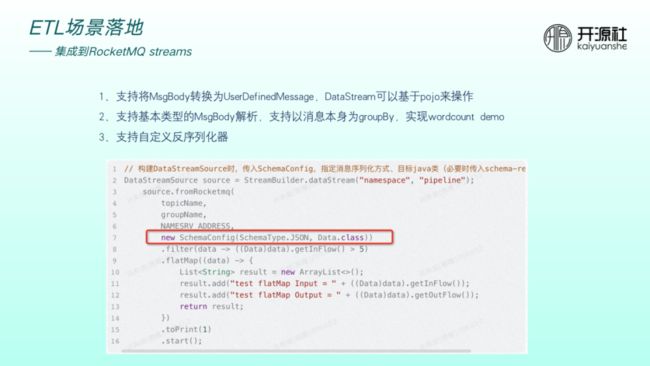
集成到 RocketMQ streams 场景的出发点在于希望RocketMQ streams API 的使用可以更加友好。没有集成 schema 时,用户需要主动将数据转化成 JSON 。集成后,在流分析时,要靠近 Flink 或 streams 的使用习惯可以直接通过对象操作,用户使用更友好。
上图代码中新增了参数 schemaConfig 用于配置 schema ,包括序列化类型、目标 java 类,之后的 filter、map 以及 window 算子的计算均可基于对象操作,非常方便。
另外,集成 streams 目前还可支持基本类型解析、消息本身做 group by 操作以及自定义反序列化优化器。
后续规划

未来,我们将在以下结果方面持续精进。
第一,社区SIG发展:小组刚经历了从 0 到 1 的建设,还有很多 todo list 尚未实现,也有很多 good first issue 适合给社区新人做尝试。
第二,强化Table概念。RocketMQ想要靠近流式引擎,需要不断强化 table 概念。因此,引入 schema 之后是比较好的契机,可以将RocketMQ 的topic 概念提升至table 的概念,促进消息和流表的深度融合。
第三,No-server 的 schema 管理。引入了 registry 组件后增加了一定的外部组件依赖。因此一些强调轻量化的场景依然希望做 no-server 的 schema 管理。比如直接与RocketMQ 交互,将信息持久化到 compact topic 上,做直接读、直接写或基于 Git 存储。
第四,列式查询。集成到 streams 之后,我们发现可以按照字段去消费消息、理解消息。当前的 RocketMQ 消息按行理解,解析计算时需要消费整个消息体。streams 目前按照字段消费消息已经基本实现,后续期望能够实现按照条件查询消息、按字段查询消息,将 RocketMQ 改造成查询引擎。
第五,数据血缘/数据地图。当 RocketMQ 通过分级存储等特性延长消息的生命周期,它将可以被视为企业的数据资产。目前的痛点在于 RocketMQ 提供的 dashboard 上,业务人员很难感知到 topic 背后的业务语义。如果做好数据血缘、理清数据 topic 上下游关系,比如谁在生产数据、被提供了哪些字段、哪些信息,则整个 dashboard 可以提供消息角度的业务大盘,这其实具有很大的想象空间。
加入 Apache RocketMQ 社区
十年铸剑,Apache RocketMQ 的成长离不开全球接近 500 位开发者的积极参与贡献,相信在下个版本你就是 Apache RocketMQ 的贡献者,在社区不仅可以结识社区大牛,提升技术水平,也可以提升个人影响力,促进自身成长。
社区 5.0 版本正在进行着如火如荼的开发,另外还有接近 30 个 SIG(兴趣小组)等你加入,欢迎立志打造世界级分布式系统的同学加入社区,添加社区开发者:rocketmq666 即可进群,参与贡献,打造下一代消息、事件、流融合处理平台。