【Apache-StreamPark】Flink 开发利器 StreamPark 的介绍、安装、使用
【Apache-StreamPark】Flink 开发利器 StreamPark 的介绍、安装、使用
- 1)框架介绍与引入
-
- 1.1. 什么是 StreamPark
- 1.2. Features
- 1.3. 组成部分
- 1.4.引入 StreamPark
- 2)安装部署
-
- 2.1.环境要求
- 2.2.Hadoop
- 2.3.Kubernetes
- 2.4.安装
- 2.5.启动
- 2.6.系统登录
- 2.7.系统配置
-
- 2.7.1.System Setting
- 2.7.2.Alert Setting
- 2.7.3.Flink Home
- 2.7.4.Flink Cluster
- 3)StreamPark 使用
1)框架介绍与引入

1.1. 什么是 StreamPark

1.2. Features

1.3. 组成部分
StreamPark 核心由 streampark-core 和 streampark-console 组成
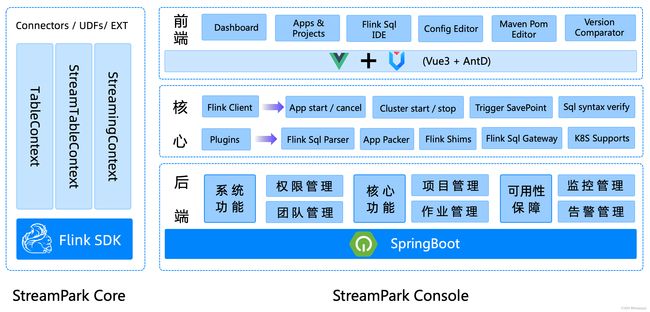

1.4.引入 StreamPark
之前我们写 Flink SQL 基本上都是使用 Java 包装 SQL,打 jar 包,提交到服务器上。通过命令行方式提交代码,但这种方式始终不友好,流程繁琐,开发和运维成本太大。我们希望能够进一步简化流程,将 Flink TableEnvironment 抽象出来,有平台负责初始化、打包运行 Flink 任务,实现 Flink 应用程序的构建、测试和部署自动化。StreamPark 对 Flink 的支持比较完善且强大。
2)安装部署
StreamPark 总体组件栈架构如下, 由 streampark-core 和 streampark-console 两个大的部分组成 , streampark-console 是一个非常重要的模块, 定位是一个综合实时数据平台,流式数仓平台, 低代码 ( Low Code ),Flink & Spark 任务托管平台,可以较好的管理 Flink 任务,集成了项目编译、发布、参数配置、启动、savepoint,火焰图 ( flame graph ),Flink SQL,监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案
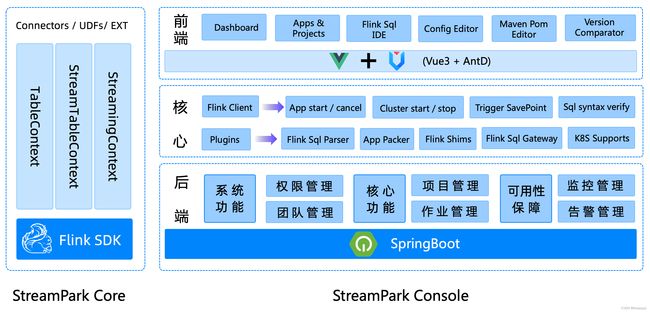
2.1.环境要求
streampark-console 提供了开箱即用的安装包,安装之前对环境有些要求,具体要求如下:

目前 StreamPark 对 Flink 的任务发布,同时支持 Flink on YARN 和 Flink on Kubernetes 两种模式。
2.2.Hadoop
使用 Flink on YARN,需要部署的集群安装并配置 Hadoop 的相关环境变量,如你是基于CDH 安装的 hadoop 环境, 相关环境变量可以参考如下配置:
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop #hadoop 安装目录
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HIVE_HOME=$HADOOP_HOME/../hive
export HBASE_HOME=$HADOOP_HOME/../hbase
export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs
export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce
export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn
2.3.Kubernetes
使用 Flink on Kubernetes,需要额外部署/或使用已经存在的 Kubernetes 集群,请参考条目: StreamPark Flink-K8s 集成支持。
2.4.安装
1、下载 streampark 安装包,解包后安装目录如下
.
streampark-console-service-1.2.1
├── bin
│ ├── startup.sh //启动脚本
│ ├── setclasspath.sh //java 环境变量相关的脚本 ( 内部使用,用户无需关注 )
│ ├── shutdown.sh //停止脚本
│ ├── yaml.sh //内部使用解析 yaml 参数的脚本 ( 内部使用,用户无需关注 )
├── conf
│ ├── application.yaml //项目的配置文件 ( 注意不要改动名称 )
│ ├── flink-application.template //flink 配置模板 ( 内部使用,用户无需关注 )
│ ├── logback-spring.xml //logback
│ └── ...
├── lib
│ └── *.jar //项目的 jar 包
├── client
│ └── streampark-flink-sqlclient-1.0.0.jar //Flink SQl 提交相关功能 ( 内部使用,用户无需关注 )
├── script
│ ├── schema
│ │ ├── mysql-schema.sql // mysql的ddl建表sql
│ │ └── pgsql-schema.sql // pgsql的ddl建表sql
│ ├── data
│ │ ├── mysql-data.sql // mysql的完整初始化数据
│ │ └── pgsql-data.sql // pgsql的完整初始化数据
│ ├── upgrade
│ │ ├── 1.2.3.sql //升级到 1.2.3版本需要执行的升级sql
│ │ └── 2.0.0.sql //升级到 2.0.0版本需要执行的升级sql
│ │ ...
├── logs //程序 log 目录
├── temp //内部使用到的临时路径,不要删除
2、初始化表结构
目前支持 mysql、pgsql、h2(默认,不需要执行任何操作),sql 脚本目录如下:
├── script
│ ├── schema
│ │ ├── mysql-schema.sql // mysql的ddl建表sql
│ │ └── pgsql-schema.sql // pgsql的ddl建表sql
│ ├── data
│ │ ├── mysql-data.sql // mysql的完整初始化数据
│ │ └── pgsql-data.sql // pgsql的完整初始化数据
│ ├── upgrade
│ │ ├── 1.2.3.sql //升级到 1.2.3版本需要执行的升级sql
│ │ └── 2.0.0.sql //升级到 2.0.0版本需要执行的升级sql
如果是初次安装,需要连接对应的数据库客户端依次执行 schema 和 data 目录下对应数据库的脚本文件即可,如果是升级,则执行对应的版本号的sql即可。
3、修改配置
安装解包已完成,接下来准备数据相关的工作
- 修改连接信息
进入到 conf 下,修改 conf/application.yml,找到 spring 这一项,找到 profiles.active 的配置,修改成对应的信息即可,如下:
spring:
profiles.active: mysql #[h2,pgsql,mysql]
application.name: StreamPark
devtools.restart.enabled: false
mvc.pathmatch.matching-strategy: ant_path_matcher
servlet:
multipart:
enabled: true
max-file-size: 500MB
max-request-size: 500MB
aop.proxy-target-class: true
messages.encoding: utf-8
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
main:
allow-circular-references: true
banner-mode: off
在修改完 conf/application.yml 后, 还需要修改 config/application-mysql.yml 中的数据库连接信息:
Tips: 由于Apache 2.0许可与Mysql Jdbc驱动许可的不兼容,用户需要自行下载驱动jar包并放在 $STREAMPARK_HOME/lib 中,推荐使用8.x版本,下载地址 apache maven repository
spring:
datasource:
username: root
password: xxxx
driver-class-name: com.mysql.cj.jdbc.Driver # 请根据mysql-connector-java版本确定具体的路径,例如:使用5.x则此处的驱动名称应该是:com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/streampark?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8
- 修改workspace
进入到 conf 下,修改 conf/application.yml,找到 streampark 这一项,找到 workspace 的配置,修改成一个用户有权限的目录
streampark:
# HADOOP_USER_NAME 如果是on yarn模式( yarn-prejob | yarn-application | yarn-session)则需要配置 hadoop-user-name
hadoop-user-name: hdfs
# 本地的工作空间,用于存放项目源码,构建的目录等.
workspace:
local: /opt/streampark_workspace # 本地的一个工作空间目录(很重要),用户可自行更改目录,建议单独放到其他地方,用于存放项目源码,构建的目录等.
remote: hdfs:///streampark # support hdfs:///streampark/ 、 /streampark 、hdfs://host:ip/streampark/
2.5.启动
进入到 bin 下直接执行 startup.sh 即可启动项目,默认端口是10000,如果没啥意外则会启动成功,打开浏览器 输入http://$host:10000 即可登录
cd streampark-console-service-1.0.0/bin
bash startup.sh
相关的日志会输出到 streampark-console-service-1.0.0/logs/streampark.out 里
2.6.系统登录
经过以上步骤,即可部署完成,可以直接登录系统

提示:
默认密码: admin / streampark
2.7.系统配置
进入系统之后,第一件要做的事情就是修改系统配置,在菜单**/StreamPark/Setting** 下,操作界面如下:

主要配置项分为以下几类:
System Setting
Alert Setting
Flink Home
Flink Cluster
2.7.1.System Setting
当前系统配置包括:
-
Maven配置
-
Docker环境配置
-
警告邮箱配置
-
k8s Ingress 配置
2.7.2.Alert Setting
Alert Email 相关的配置是配置发送者邮件的信息,具体配置请查阅相关邮箱资料和文档进行配置
2.7.3.Flink Home
这里配置全局的 Flink Home,此处是系统唯一指定 Flink 环境的地方,会作用于所有的作业
提示:
特别提示: 最低支持的 Flink 版本为 1.12.0, 之后的版本都支持
2.7.4.Flink Cluster
Flink 当前支持的集群模式包括:
-
Standalone 集群
-
Yarn 集群
-
Kubernetes 集群
3)StreamPark 使用
详细使用请参考 StreamPark 中文官网