Render Graph 全网最细介绍(二)
图结构的优势
回顾
前文提到,RDG(Render Dependency Graph,简称RDG)是一个有向无环图,其中pass是类似于函数的处理节点,resource是资源节点,各个pass之间完全独立,不存在耦合,他们唯一的“联系”是作为pass纽带的resource。

延迟渲染的RDG表现
为什么要将渲染流程做成一个图结构呢?我们不就是将渲染过程做了一个解耦,将pass与resource分开处理了吗,我不采用图结构,是不是也可以达到同样的目的:对整帧的信息进行掌握,实现整帧优化。
接下来,我们看看图结构有什么优势。
资源的复用
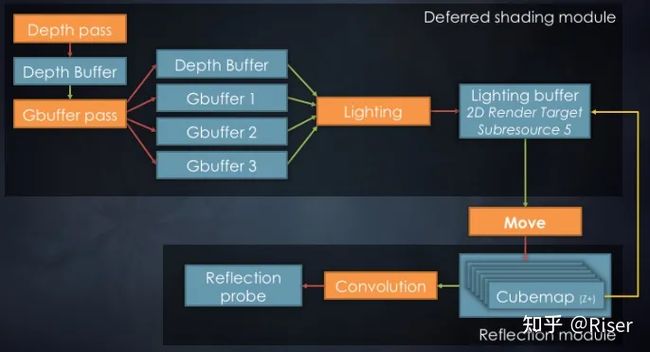
这个是Frostbite在GDC上的一个例子,从上图中我们看到,在我们经过Lighting这个pass之后,我们可能并不想将这个光照结果作为一帧图像显示在屏幕上,我们也可以将这个结果作为我们的反射场景,以制作反射探针。我们将光照计算结果映射到了一个立方体贴图上,然后进行了一个卷积操作,最后将结果输出到反射探针中。
关于反射探针,可以参考这篇文章:反射探针(Reflection Probe) - 知乎 (zhihu.com)
从上边这个例子中我们可以看出每个pass的输出不一定只有一个用处。这样就实现了资源的复用。因为pass并不关心resource从何方来,我的输出会被谁用到,pass与pass之间是完全透明的。
多分支
同时我们在之前介绍compile阶段的时候提到:Compile阶段会将未被引用的resource和pass给裁减掉,那我们是不是就可以添加多条渲染路线呢?我们只用告诉RenderGraph,我每次渲染想要走哪条路线就行了。
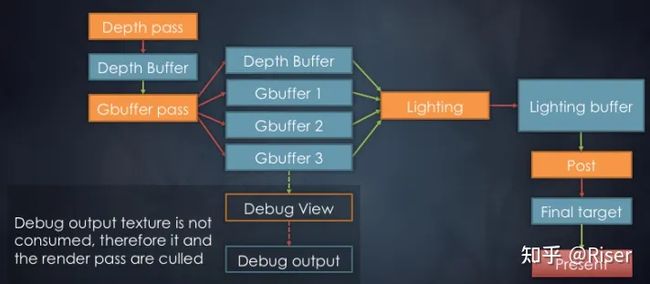
正常的延迟渲染流程

Debug 延迟渲染中的Gbuffer
这也是一个非常典型的例子,在某些时刻,我们真的非常想看看延迟渲染中的Gbuffer到底长什么样子呢?是否符合程序的预期?于是,我们可以在Gbuffer之后,再加一个Debug分支,只需要告诉RDG你这一次想要走哪一条分支就可以了,相比于传统程序,你不用经过删代码、加代码、编译的繁琐流程了。
Extensibility 解决
Debug
RDG还有一个非常强大的功能,就是非常易于Debug,它体现在哪里呢?
首先,它是一个图,就意味着我们可以通过图的遍历,将整个RDG直接给可视化出来,然后将每一次的渲染了解的明明白白。通过GraphViz(一个RDG可视化软件),我们可以将RDG的pass执行顺序、资源的生命周期等一帧内的信息可视化出来,以下是可视化的例子:

可视化RDG(有些糊)
图中,最上边的部分,是pass的执行顺序,下边是各个resource存在的生命周期。
利用图的特性,我们可以做出很多酷炫的东西出来,以下是知乎博主
@Ubp.a
做的一个自研引擎中将RDG可视化的例子:FrameGraph可视化

我们可以直接从编辑器中看到当前resource长什么样,非常易于debug。
debug 解决
Render Graph的多线程
现代GPU架构
这是最复杂的一部分,因为涉及到RDG与GPU之间的命令提交。首先我们来看看GPU中是如何应对多线程的,以及GPU多线程的意义是什么。
我们知道传统的GPU渲染管线分为以下若干部分:

GPU的渲染管线
其中绿色的部分,是我们能够通过写着色器进行编程控制的。GPU中的各个部分(顶点着色、光栅化、片元着色等)都是有专门的运算单元负责的。在渲染某一帧图像的时候,假如我们进行到光栅化的这个步骤,如果没有使用多线程,那么其他的单元的都没有被使用到。这样会导致GPU的利用率大大降低。
不同GPU有不同的硬件架构[1][2]。
于是现代GPU都采取了队列的方式进行指令处理,这里以Dx12为例:
Dx12将GPU分为三个engine:
- Copy engine[3]:负责资源的复制。GPU的每次Draw,都需要CPU将资源拷贝到GPU的显存中,但是GPU与CPU之间存在带宽差异,每一次GPU绘制完了,都需要CPU为他拷贝资源,从而导致GPU利用率降低。于是我们将资源拷贝的操作交给GPU,GPU可以实现异步读取资源,在进行进行计算的同时,就可以将下一步要用的资源拷贝好,方便下一次直接使用。
- Compute engine:负责片元着色器的计算。
- 3D engine:顶点着色器、光栅化等

现代GPU架构
将3D engine和Compute engine分开,是为了实现渲染管线上的并行性。例如,可以在光栅化的同时计算着色器,使GPU得到充分的利用。由此,两个engine可以将pass分为两类:
- Render pass:重在3D到2D的过程的渲染,绘制点、线、面。会涉及到坐标变换、光栅化等。
- Compute pass:重在着色器的计算上,例如后期处理、光照计算等。
例如延迟渲染中的Gbuffer pass就是一个render pass,因为它是从3D到2D的一个过程,而Lighting pass是一个compute pass,因为它只涉及到光照计算。
两种pass在逻辑上是完全并行执行的。
合理安排Pass
RenderGraph中的多线程是一种半自动的多线程。意思是需要由程序员决定想要哪一个pass进入异步队列,这个时候就是考验程序员的时候了,如果将两个对同种GPU资源利用率很高的pass放入异步队列中,他们很容易让GPU的某种资源的利用达到瓶颈,而其余资源处于空闲之中,导致GPU的资源利用率低。所以在RenderGraph中使用多线程时,一定要注意安排合理地安排pass进行多线程。
多线程中的资源的生命周期
上篇文章提到,我们需要资源的生命周期尽可能得短 ——“执行第一个用到该resource的时候再分配,最后一个用到该资源的pass执行完毕之后,立马进行回收”。
在多线程中,资源的生命周期会得到一定程度的延长,以下以SSAO(屏幕空间环境光遮蔽)[4]举例:

单线程中的SSAO
- 单线程:SSAO这个pass读取Depth Buffer,并写入Raw AO这个resource,然后SSAO Filter读取Raw AO,并写入Filtered AO。由于SSAO Filter pass之后,后续的pass都没有声明使用Raw AO,Raw AO在SSAO Filter使用完之后立马被回收。
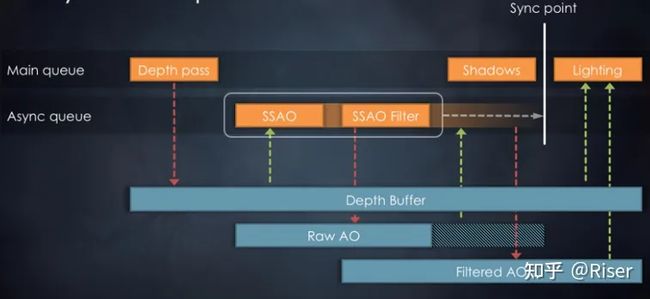
SSAO 与 SSAO Filter 异步执行
- 多线程:我们考虑将SSAO 与 SSAO Filter假如异步队列中异步执行,由于两个pass异步执行,我们就无法在异步执行的过程中对Raw AO进行回收(异步执行时,我们无法推导出什么时候是Raw AO的最后一次应用),那么什么时候进行回收呢?有异步就会有同步。
Render Graph会在第一个使用该异步执行的结果的pass之前添加一个“同步点”。
Lighting 这个pass使用了该异步执行的结果——Filtered AO,这说明异步结果产生了,那么异步过程中的资源就可以被回收了,这些资源的生命周期将会被延长到同步点处。
多线程的问题
- 内存的增加:添加“同步点”,会导致资源的生命周期的延长,导致资源不能及时地回收,从而使得GPU的内存占用增加。
- 滥用有可能降低性能:这种半自动化的多线程,需要手动地去决定pass是否进入异步队列,如果让两个对同种资源占用很高的pass进入异步队列,容易造成性能的降低。