【具身智能评估7】ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
论文标题:ProcTHOR: Large-Scale Embodied AI Using Procedural Generation
论文作者:Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, Roozbeh Mottaghi
论文原文:https://arxiv.org/abs/2206.06994
论文出处:–
论文被引:69(12/18/2023)
论文代码:https://github.com/allenai/procthor,183 star
项目主页:https://procthor.allenai.org/
Abstract
海量数据集和大容量模型推动了计算机视觉和自然语言理解领域的许多最新进展。这项工作提供了一个平台,使具身人工智能也能取得类似的成功。我们提出的 PROCTHOR 是一个程序化生成具身人工智能环境的框架。PROCTHOR 使我们能够对多样化、交互式、可定制和高性能虚拟环境的任意大型数据集进行采样,以训练和评估导航、交互和操作任务中的具身智能体。我们通过 10,000 个生成的房屋样本和一个简单的神经模型展示了 PROCTHOR 的功能和潜力。在 PROCTHOR 上仅使用 RGB 图像训练的模型,在没有显式映射和人类任务监督的情况下,在导航、重新排列和手臂操纵等 6 项具身人工智能基准测试中取得了最先进的结果,其中包括目前正在进行的 Habitat 2022、AI2-THOR Rearrangement 2022 和 RoboTHOR 挑战赛。我们还通过在 PROCTHOR 上进行预训练,而不对下游基准进行微调,在这些基准上展示了强大的 零样本结果,击败了以前使用下游训练数据的最先进系统。
1 Introduction
通过使用大规模训练数据,计算机视觉和自然语言处理模型变得越来越强大。最近的模型,如 CLIP [ 93 ]、DALL-E [ 95 ]、GPT-3 [ 10 ] 和 Flamingo [ 3 ],都使用了大量与任务无关的数据来预训练大型神经架构,这些架构在下游任务(包括零样本和少镜头设置)中表现出色。相比之下,Embodied AI(E-AI)研究界主要是在场景少得多的模拟器中训练智能体[ 94 , 63 , 27 ]。由于任务的复杂性和需要较长的规划时间,表现最好的 E-AI 模型在有限的训练场景中仍会过拟合,因此对未知环境的泛化能力较差。
近年来,E-AI 模拟器的功能越来越强大,支持物理、机械手、物体状态、可变形物体、流体和真实模拟对等[63, 101 , 104 , 37 , 124],但将其扩展到数以万计的场景仍然具有挑战性。现有的 E-AI 环境要么是人工设计的 [63, 37],要么是通过真实结构的3D扫描获得的 [101, 94]。前一种方法需要3D艺术家花费大量时间设计3D资产,在大型空间中合理地布置它们,并在这些环境中仔细配置合适的纹理和照明。后者则需要在许多真实世界环境中移动专用摄像机,然后将生成的图像拼接在一起,形成场景的3D重建。这些方法都不具备可扩展性,将现有场景库扩大数倍也不现实。
现有的 E-AI 环境分为两类:
- 专家手动设计:AI2-THOR,ThreeDWorld
- 真实环境扫描:Habitat,HM3D

我们介绍的 PROCTHOR 是一个基于 AI2-THOR [63 ]的框架,用于为 E-AI 研究程序化地生成完全交互的物理环境。给定一个房间规格(例如,一栋有 3 个卧室、3 个浴室和 1 个厨房的房子),PROCTHOR 就能生成符合这些要求的大量不同的平面图(图 1)。
- 由 108 种物体类型和 1633 个完全可交互实例组成的大型资产库用于自动填充每个平面图,确保物体的摆放合理、自然和逼真。
- 用户还可以改变每个场景中照明元素(人工照明和模拟 skybox)的强度和颜色,以模拟室内照明和一天中时间的变化。
- 资产(如家具和水果)和较大的结构(如墙壁和门)可以分配各种颜色和纹理,这些颜色和纹理是从每类资产的合理颜色和材料集中抽取的。
- 布局、资产、位置和照明的多样性共同构成了一个任意庞大的环境集,使 PROCTHOR 的规模远远超出了目前模拟器所支持的场景数量。
- 此外,PROCTHOR 还支持动态材料随机化(dynamic material randomizations),每次将环境加载到内存中进行训练时,都可以对单个资产的颜色和材料进行随机化。
- 重要的是,与使用3D扫描生成的环境不同,PROCTHOR 生成的场景包含的物体既支持各种不同的物体状态(如打开、关闭、破碎等),又具有完全的交互性,因此可以由使用机械臂的智能体进行实际操作。
我们还展示了由艺术家设计的3D建筑 ARCHITECTHOR,这是一套由 10 座高质量的全交互式房屋组成的3D模型,旨在作为家庭环境研究的测试环境。与 AI2-iTHOR(单个房间)和 RoboTHOR(视觉多样性较低)环境相比,ARCHITECTHOR 包含更大、更多样和更逼真的房屋。
我们通过对包含 10,000 所房屋(命名为 PROCTHOR-10K)的环境进行采样,展示了 PROCTHOR 的易用性和有效性,该环境由各种布局组成,小到 1 个房间的房屋,大到 10 个房间的房屋。我们在 PROCTHOR-10K 上使用非常简单的神经架构(CNN+RNN)训练智能体(没有深度传感器,仅使用 RGB 通道,没有明确的映射,也没有人类任务监督),并在多个导航和交互基准上生成了最先进的(SoTA)模型。截至太平洋时间 2022 年 6 月 14 日上午 10 点,我们获得了 :
-
1)RoboTHOR ObjectNav Challenge [5]
- 零样本的性能优于之前使用 RoboTHOR 训练场景的 SoTA
- 通过微调,SPL 比以前的 SoTA 提高了 8.8 分;
-
2)Habitat ObjectNav Challenge 2022 [ 79 ]
- 成绩名列前茅,SPL 比下一个最好的提交作品提高了 3 分以上;
-
3)1-phase Rearrangement Challenge 2022 [ 4 ]
- 成绩名列前茅,Prop Fixed Strict 从 0.19 提高到 0.245;
-
4)AI2-iTHOR ObjectNav
- 零样本性能已经超过了之前基于 AI2-iTHOR 训练的模型,经过微调,成功率达到了 77.5%;
-
5)ArmPointNav [ 33 ]
- 使用 RGB 时,零样本性能数字超过了之前的 SoTA 结果;
-
6)ArchitecTHOR ObjectNav
- 成功率从 18.5% 大幅提高到 31.4%。
- 最后,消融分析清楚地显示了从 10 个场景到 100 个场景再到 1K 个场景,最后到 10K 个场景的优势,并表明通过调用 PROCTHOR 生成更大的环境可以获得进一步的改进。
总之,我们的贡献包括:
- 1)PROCTHOR,一个允许以程序化方式生成无限数量的多样化、完全交互式模拟环境的框架;
- 2)ARCHITECTHOR,一套由3D艺术家设计的新房屋,用于 E-AI 评估;
- 3)六项 E-AI 基准的 SoTA 结果,涵盖操作和导航任务,包括强大的 0-shot 结果。PROCTHOR 将开源,并将发布这项工作中使用的代码。
2 Related Work
Embodied AI platforms.
在过去几年里,人们开发了各种具身人工智能平台[ 63 , 101 , 104 , 124 , 37, 121 ]。这些平台针对不同的设计目标。
- AI2-THOR[63]及其变体(ManipulaTHOR[33]和RoboTHOR[27])是在Unity游戏引擎中构建的,重点关注智能体与物体之间的交互、物体状态变化以及精确的物理模拟。
- 与 AI2-THOR 不同,Habitat[101] 提供由房屋3D扫描构建的场景,但物体和场景不可交互。
- iGibson [ 104 ] 包含逼真的场景,但只有有限的交互(如推)。
- iGibson 2.0 [ 69 ] 扩展了 iGibson,重点关注合成场景中的家务劳动和物体状态变化,并包含虚拟现实接口。
- ThreeDWorld [37] 以高保真物理仿真为目标,如液体和可变形物体仿真。
- VirtualHome [92] 是为通过程序模拟人类活动而设计的。
- RLBench [53]、RoboSuite [133] 和 Sapien [124] 的目标是细粒度操作。
- PROCTHOR的主要优势在于,我们可以程序化地生成各种交互场景,从而在具身人工智能(Embodied AI,E-AI)的背景下,对数据增强和大规模训练进行研究。
Large-scale datasets.
大规模数据集已在不同领域取得重大突破,如图像分类 [28 , 67]、视觉与语言 [18 , 111]、3D理解 [ 14 , 125 ]、自动驾驶 [11 , 107 ] 和机器人物体操纵 [ 91, 82 ]。然而,用于E-AI 研究的交互式大规模数据集并不多。PROCTHOR 包含程序化生成的交互式房屋。因此,该框架中的场景数量非常庞大。与我们最接近的作品有 [94, 90, 72]。
- HM3D [94] 是一个最新的框架,其中包含 1000 个使用真实环境的 3D 扫描生成的场景。PROCTHOR 有几个主要区别:
- 1)HM3D 包含静态场景,而 PROCTHOR 不同,它的场景是交互式的,即物体可以移动和改变状态,物体的光照和纹理可以改变,物理引擎可以决定场景的未来状态;
- 2)HM3D 需要扫描房屋并清理数据,因此扩大 HM3D 的规模具有挑战性,而我们可以程序化地生成更多房屋;(3) HM3D 只能用于导航任务(因为没有物理模拟和物体交互),而 PROCTHOR 可用于导航以外的任务。
- OpenRooms [ 72] 在数据来源(3D扫描)和数据集大小方面与 HM3D 相似。不过,OpenRooms 是交互式的。OpenRooms 还局限于扫描的房屋集,而且注释一个新场景需要花费大量时间(例如,为一个物体标注材料需要 1 分钟),而 PROCTHOR 则不存在这些问题。
- Megaverse [ 90 ] 是另一个大规模的具身人工智能平台,其中包括程序化生成的环境。虽然它模拟速度快,但它只包含外观简化的类似游戏的环境。相比之下,PROCTHOR 在外观、物理和物体交互的复杂性方面都模仿了现实世界中的房屋。
Scene generation.
计算机视觉和图形学界对室内场景合成进行了广泛的研究。
- [16, 17, 13] 解决了从文本描述生成3D场景的问题。
- [120 , 47 , 85] 学习生成房屋平面图。
- [98, 129 , 20, 113 , 56 , 70] 使用生成模型生成室内场景。
- [131 , 100] 为室内场景中的查询位置提出潜在物体。
- 还有人使用程序生成[57 , 31]和无监督学习[29]为AI合成网格世界环境。
PROCTHOR 是专为具身人工智能研究而设计的,它具有以下特点:
- 1)所有场景都是交互式的,具有物理功能,物体的摆放尊重世界的物理特性(例如,没有两个物体会互相穿过);
- 2)有各种形式的场景增强,例如,在遵循某些常识性规则的情况下,物体摆放的随机化、物体和结构外观的变化以及光照的变化。
3 PROCTHOR
PROCTHOR 是一个程序化生成 E-AI 环境的框架。它扩展了 AI2-THOR,因此继承了 AI2-THOR 的大型资产库、机器人智能体和精确的物理模拟。与 AI2-THOR 中设计人员精心创建的场景一样,PROCTHOR 中的环境也是完全交互式的,支持导航、物体操作和多智能体交互。

图 2 显示了 PROCTHOR 生成场景的高级程序示意图。给定一个房间规格(如带 1 间卧室和 1 间浴室的房子),PROCTHOR 使用多阶段条件采样来反复生成平面图(floor plans)、创建外墙结构、采样照明和门,然后采样包括大型、小型和墙面物体在内的资产,挑选颜色和纹理,并确定资产在场景中的适当位置。有关程序生成和采样机制的详情,请参阅附录:多样性、交互性、可定制性、规模和效率。
Diversity
PROCTHOR 可以创建丰富多样的环境。在视觉和 NLP 领域,使用多样化数据对模型进行预训练取得了成功,与此相对应,我们在多个 E-AI 任务中展示了这种多样性的实用性。PROCTHOR 中的场景在多个方面都表现出了多样性:
平面图(floor plans)的多样性。给定房间规格后,我们首先采用迭代边界切割(iterative boundary cutting)获得外部场景布局(从简单的矩形到复杂的多边形)。然后使用 Lopes 等人[73] 的递归布局生成算法将场景划分为所需的房间。最后,我们使用一组用户定义的约束条件来确定房间之间的连通性。这些程序会产生自然的房间布局(例如,卧室通常通过一扇门与相邻的浴室相连,浴室通常只有一个入口等)。如图 3 所示,PROCTHOR 使用这种程序生成了多种多样的平面图。

资产的多样性。PROCTHOR 从其数据库中收集了 108 个类别的 1633 件家庭资产(图 4 中的示例),在场景中填充了大大小小的资产。虽然许多资产继承自 AI2-THOR,但我们也引入了新的资产,如门窗和台面,这些都是由3D平面设计师手工设计的。资产实例分为训练/验证/测试子集,并且可以交互,即可以在场景中挑选和放置物体,有些物体有多种状态(如灯可以开或关),还有一些物体由具有刚体运动的部件组成(如微波炉上的门)。

材料多样性。墙壁有两种材料:40 种纯色(流行色)或 122 种墙壁纹理(如砖和瓷砖)。我们还提供 55 种地板材料。整栋房屋的天花板材料是从墙壁材料中抽取的。PROCTHOR 还提供了随机化物体材料的功能。材料只在类别内随机化,这样可以确保物体的外观和行为与它们所代表的类别一致。

物体摆放的多样性。资产类别有多种软注释(soft annotations),有助于将它们真实地放置在房屋内。这些软注释包括房间分配(例如,沙发放在客厅而不是浴室)和位置分配(例如,冰箱沿着墙壁,电视机不在地板上)。我们还提出了语义资产组(Semantic Asset Group,SAG)的概念,即通常共同出现的资产组(如餐桌和四把椅子),因此必须使用从属采样(dependent sampling)进行采样和放置。
- 给定布局后,对位于地面上的单个资产和 SAG 进行采样并反复放置,确保房间有足够的地面空间供智能体导航和操作物品。
- 然后,放置窗户和油画等墙面物体。
- 最后,放置表面物体(位于其他资产之上的物体),例如厨房台面上的杯子。
通过这种取样,可以在任何布局中选择和放置大量不同的物体。图 6 展示了这种变化。

照明的多样性。PROCTHOR 支持单个定向光源(类似太阳)和多个点光源(类似灯泡)。通过改变这些光源的颜色、强度和位置,我们可以模拟出不同的人工照明,通常是在房屋内以及一天中的不同时间。如图 7 所示,照明对渲染图像有很大影响。

Interactivity
PROCTHOR 的一个关键特性是能够与物体互动,改变其位置或状态(图 8)。这种能力是许多E-AI任务的基础。像HM3D[94]这样通过静态3D扫描创建的数据集则不具备这种能力。PROCTHOR 支持带有手臂的智能体,它们能够操纵物体并相互交互。

Customizability
PROCTHOR 支持多种房间、资产、材料和照明规格。只需几行简单的说明,就能轻松生成客户感兴趣的环境。图 9 展示了这些不同场景(教室、图书馆和办公室)的示例。

Scale and Efficiency
PROCTHOR 目前使用 16 种不同的场景规范作为场景生成过程的种子。这些规范可产生超过 1,000 亿个布局。PROCTHOR 使用 18 种不同的语义资产组和 1633 种资产。这可以产生大约 2000 万个独特的资产组。每个资产都可以放置在多个位置。此外,每栋房屋都会按比例缩放,并使用各种照明。这种布局、资产、材料、位置和照明的多样性使我们能够生成任意庞大的房屋集——既可以静态生成并存储为数据集,也可以在每次迭代训练时动态生成。场景以 JSON 格式有效表示,并在运行时加载到 AI2-THOR,从而使存储房屋的内存开销变得异常高效。此外,场景生成过程是全自动且快速的,PROCTHOR 可为 E-AI 模型的训练提供高帧频(详见第 4 章)。
4 PROCTHOR-10K
我们使用第 3 节中描述的程序生成过程获得的 10,000 套完全交互式房屋样本来展示 PROCTHOR 的功能和潜力,我们将其命名为 PROCTHOR -10K。另外还有 1,000 套验证房屋和 1,000 套测试房屋可供评估。附录中详细说明了训练/验证/测试的资产分配情况。所有房屋都是完全可浏览的,允许智能体在没有任何交互的情况下穿越每个房间。就规模而言,PROCTHOR -10K 是最大的具身人工智能交互式家庭环境集之一。
- AI2-iTHOR [63] 包含 120 个场景
- RoboTHOR [27] 有 89 个场景
- iGibson [104] 有 15 个场景
- Habitat Matterport 3D [94] 有 1,000 个静态(非交互式)场景
- Habitat 2.0 [109] 有 105 个场景布局
将规模扩展到 10K 房屋以上既简单又便宜。这组 10K 房屋是在配备 4 个英伟达 RTX A5000 GPU 的本地工作站上于 1 小时内生成的。图 11 显示了 PROCTHOR-10K 中以自我为中心和自上而下的房屋视图示例。

Scene statistics
PROCTHOR -10K 中的房屋是根据 16 种不同的房间规格生成的。房间规格示例如下 该数据集中的房屋少则 1 间,多则 10 间。图 10 显示了这些生成房屋的面积分布(中)和房间数量(右)。通过使用房间规格,我们可以非常容易地改变房屋的大小和复杂程度。PROCTHOR -10K 比 AI2-iTHOR [ 63 ] 和 ROBOTHOR [27](偏重于房间大小的场景)以及 Gibson [ 123 ] 和 HM3D [94](偏重于大型房屋)涵盖了更广泛的场景。

这些房屋中的每个房间都包含 95 个不同类别的物体,包括冰箱、台面、床、马桶和室内植物等常见家居物体,以及门道和窗户等结构物体。图 10(左)显示了每栋房屋每个房间的物品数量分布情况,从中可以看出 PROCTHOR -10K 中的房屋都有很多物品。它们还包含通过 18 个不同语义资产组采样的物体。语义资产组(SAG)的示例包括带 4 把椅子的餐桌或带 2 个枕头的床。考虑到我们庞大的资产库和 SAG,我们可以创建 1930 万种组实例组合。
Rendering speed
大规模训练的一个关键要求是高渲染速度,因为训练算法需要数百万次迭代才能收敛。表 1 显示了这些统计数据。实验在配有 8 个英伟达 Quadro RTX 8000 GPU 的服务器上运行。在使用 1 个 GPU 的实验中,我们使用了 15 个进程,而在使用 8 个 GPU 的实验中,我们使用了 120 个进程,平均分配给各个 GPU。PROCTHOR 尽管有更大的房子,却能提供与 iTHOR 和 RoboTHOR 环境相当的帧速率(详见附录),因此它的速度足以在合理的时间内训练数亿步的大型模型。

5 Experiments
Tasks
我们现在介绍在 PROCTHOR -10K 上预先训练的模型在几个导航和操作基准上的结果,以证明大规模训练的好处。我们考虑了ObjectNav(指向特定物体类别的导航):
- PROCTHOR
- ARCHITECTHOR
- RoboTHOR[27]
- HM3D[94]
- AI2-iTHOR[63]
我们还考虑了两个基于操作的任务:
- ArmPointNav[33]:智能体使用机械臂将物体从源位置移动到3D坐标框架中指定的目标位置。
- 1-phase Room Rearrangement[115]:目标是移动物体或改变其状态,以达到目标场景状态。
Models
我们用于所有任务的模型都由一个 CNN(编码视觉信息)和一个 GRU(捕捉时间信息)组成。
- 我们特意在所有任务中使用了简单的架构,以展示大规模训练的优势。
- 我们的 ObjectNav 和 Rearrangement 模型使用了 [58] 基于 CLIP 的架构。
- 我们的 ArmPointNav 模型使用了一个更简单的视觉编码器,包含 3 个卷积层;我们发现这比 CLIP 编码器更有效。
- 所有模型均采用 AllenAct [116] 框架进行训练,训练详情请参见附录。
Results
我们展示了两种情况下的结果:在下游基准所提供的训练场景上进行零样本和微调后的结果。
- 零样本实验展示了在 PROCTHOR 基础上训练的模型对新环境的泛化能力;
- 微调实验展示了从 PROCTHOR 中学习到的表征是否可以作为快速调优的良好初始化。
在所有实验中,我们只使用 RGB 图像(不使用深度和其他模式)。
与 PROCTHOR 相比,其他环境具有不同的外观统计、布局和物体分布,因此零样本尤其具有挑战性。
- ARCHITECTHOR 和 AI2-iTHOR [63] 是艺术家设计的高保真场景,具有高质量的阴影和照明。
- HM3D 由房屋的 3D 扫描构建而成,与合成环境有很大差异。
- RoboTHOR [27] 房屋使用的墙板和地板具有非常特殊的纹理。
零样本迁移结果。仅在 PROCTHOR 上训练并进行了零样本评估的模型在 3 个基准上的表现优于之前的 SoTA 模型(参见表 2 中的零样本行)。这些结果非常出色,因为这些模型不仅可以泛化到未见过的物体和场景,还可以泛化到不同的外观和布局统计。
微调结果。利用每个基准的训练数据对模型进行进一步微调后,在所有基准上都取得了最先进的结果(参见表 2 的微调行)。值得注意的是,截至太平洋时间 2022 年 6 月 14 日上午 10 点,我们的模型在三个公开排行榜上排名第一:Habitat 2022 ObjectNav challenge、AI2-THOR Rearrangement 2022 challenge 和 RoboTHOR ObjectNav challenge。值得注意的是,我们的模型仅使用了非常简单的架构和 RGB 图像就取得了这些成绩。其他技术通常使用更复杂的架构,包括映射或视觉里程测量模块,并使用深度图像等额外的感知传感器。

表 2: 在 ProcTHOR 上训练的模型的结果,以及在多个 E-AI 基准上进行的零样本评估和微调。a)EmbCLIP [58] 在 ROBOTHOR 上训练,b)EmbCLIP [58] 在 AI2-iTHOR 上训练,c)在 Habitat 2022 ObjectNav 排行榜[79]上提交 。 d)对于 HM3D,我们给出了使用标准 EmbCLIP 架构(使用 CLIP 预训练的 ResNet50 主干网)和 Large 模型(使用更大的 CLIP 主干网 CNN 和更宽的 RNN)进行预训练的结果,详见补充资料。 e)使用了[33]中的模型,但在带有 RGB 输入的完整 iTHOR 数据上进行了重新训练。粉色背景的是零样本结果,即模型在 PROCTHOR -10K 上进行预训练,不使用评估基准的任何训练数据。
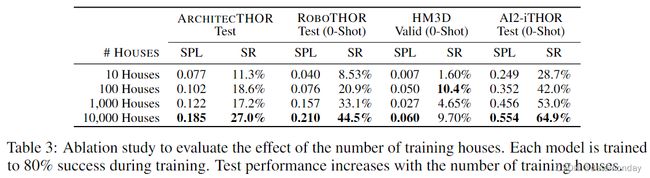
Scale ablation
为了评估规模的影响,我们在 10、100、1,000 和 10,000 座房屋上对模型进行了训练。在这项实验中,我们没有使用任何材料增强。如表 3 所示,当我们使用更多房屋进行训练时,模型的性能就会提高,这证明了大规模数据对具身人工智能任务的益处。
6 Conclusion
我们提出了 PROCTHOR,这是一个程序化生成任意大型交互式物理房屋集的框架,用于具身人工智能研究。我们对生成的 10,000 所房屋进行了简单模型的预训练,并在 6 个具身导航和操作基准测试中展示了最先进的结果,其中 3 个基准测试的结果甚至超过了之前的最先进水平。
Acknowledgements
我们要感谢该项目中使用的开源包背后的团队,包括AI2-THOR[63]、AllenAct[116]、Habitat[101]、Datasets[68]、NumPy[45]、PyTorch[88]、Pandas[78]、Wandb[8]、Shapely[41]、Hydra[126]、SciPy[112]、UMAP[77]、NetworkX[44]、EvalAI[127]、TensorFlow[1]、OpenAI Gym[9]、Seaborn[114]、PySAT[50]和Matplotlib[49]。
A ProcTHOR Assets

B House Generation
B.4 Connecting Rooms

B.8 Object Placement
B.8.1 Assets
ProcTHOR资产数据库由108种物体类型的1633种交互式家庭资产组成(更多详细信息,请参阅附录A)。大部分资产来自AI2-THOR。窗户、门和台面都建在AI2-THOR房间的外部,这使我们无法将房间作为独立资产生成。因此,我们还手工制作了21扇窗户、20扇门和33个台面。

B.8.2 Semantic Asset Groups (SAGs)
语义资产组(SAG)提供了一种灵活多样的方式来编码哪些物体可能出现在彼此附近。SAG的力量在于其支持随机资产和轮换采样的能力。通过我们用户友好的拖放式web界面,SAG可以在几秒钟内创建和导出。

图 26 举例说明了我们如何构建一个将两把椅子推到餐桌边上的 SAG。SAG 包括两个椅子采样器和一个餐桌采样器。资产采样器包含一组可采样的唯一 3D 建模资产实例。当 SAG 实例化时,每个资产采样器会随机选择其中一个实例。资产采样器也可以链接,即多个采样器每次对同一资产实例进行采样。在这里,通过链接可以将同一把椅子的多个实例放置在餐桌上,而不是每个取样器独立取样不同的椅子。
在 SAG 中随机采样资产的能力具有惊人的表现力。例如,考虑一个包含电视柜、电视、沙发和扶手椅采样器的 SAG。如果每个采样器都能从 30 个不同的 3D 建模资产实例中采样,那么就有超过 800K 种独特的实例组合可以从 SAG 中采样。
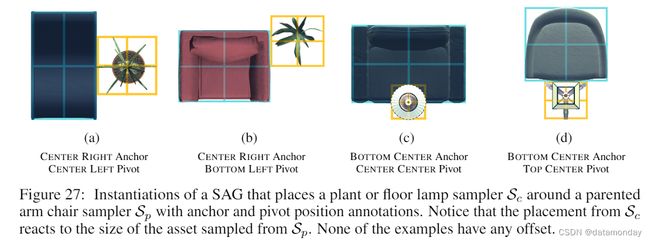
资产采样器定义了资产之间的相对位置。SAG 是通过资产采样器自上而下的正交图像来构建的,如图 26a 所示。在这里,两个椅子取样器都是餐桌取样器的父取样器。每个子资产采样器与其父资产采样器垂直锚定在 V = {上、中、下},水平锚定在 H = {左、中、右}。例如,在图 26a 中,两个椅子采样器都与父采样器垂直固定在顶部,水平固定在中心。但是,左侧椅子取样器的枢轴位置垂直于中心,水平于右侧,而右侧椅子取样器的枢轴位置垂直于中心,水平于左侧。图 27 举例说明了如何将植物或落地灯取样器放置在扶手椅取样器周围。每个子资产采样器都有一个 (x, y) 偏移量,即从父采样器锚点到子采样器枢轴位置的距离。
对资产采样器进行相对定位的目的是防止网格之间相互剪切。例如,以图 26a 中的 SAG 为例,如果餐桌采样器采样的餐桌尺寸是当前餐桌的两倍,会发生什么情况?椅子不会停留在固定的全局位置,也不会与新的餐桌发生碰撞,而是会反应性地向后移动,并重新定位,使其保持在较大餐桌的下方。此外,考虑到从资产采样器中采样的实例尺寸往往大不相同。例如,一张桌子可能是方形的,而另一张桌子则是长条形的。如果我们只使用 CENTER CENTER 枢轴和偏移量,就无法可靠地将包含不同大小物体的资产采样器直接放置在彼此旁边而不会造成剪切。

虽然设置锚点和枢轴位置可以解决很多网格剪切问题,但仍可能出现一些情况。图 28 显示了一个例子,如果我们的餐桌采样器采样的是一张短餐桌,那么它可能会夹到某些椅子上。这种问题在实践中并不多见,但物体剪切会导致房屋的逼真度和交互性降低。为了解决剪切问题,我们使用拒绝采样对 SAG 中的资产进行重新采样,直到采样资产的三维网格都不发生剪切。
在 PROCTHOR -10K 中,我们构建了 18 个 SAG,这些 SAG 可通过超过 2,000 万种独特的资产组合进行实例化。其中包括桌子周围的椅子、床顶上的枕头、沙发和扶手椅、电视柜顶上的电视、水槽顶上的水龙头以及带椅子的书桌等语义资产组。
B.8.3 Floor Object Placement

图29:详细说明地板物体如何放置在房间中的示意图。首先,我们通过从每个角点绘制水平和垂直分隔符,将房间开放式平面图的自上而下视图矩形化。然后,我们构造在分隔符内形成的所有可能的矩形。然后,我们对其中一个矩形进行采样,并将物体放置在该矩形内。采样物体的自上而下边界框(带边距)显示为蓝色。然后从打开的楼层平面中减去边界框,然后再次重复该过程。

图30:放置在房间的边缘、角落和中间时对象的有效旋转。放置在房间边缘或角落的对象始终背对墙。场景中间的对象可以在任何方向上旋转。通过约束对象的旋转,我们可以确保房间边缘的对象(如冰箱或抽屉)仍然可以打开。
B.8.4 Wall Object Placement

B.8.5 Surface Object Placement

B.12 Limitations and Future Work
ProcTHOR-10K仅使用一层房屋。我们计划在ProcTHORv2.0中支持多层房屋。这将使我们能够捕捉更广泛的房屋,并提供更好的微调结果。此外,我们计划通过利用许多开源3D资产数据库来扩大我们的资产数据库,如ABO[26]、PartNet[81]、ShapeNet[15]、谷歌扫描对象[30]和CO3D[97]等。
C PROCTHOR Datasheet
创建该数据集是为了能够在更加多样化的环境中训练模拟的具身智能体。
数据集可以用于哪些(其他)任务?
在AI2-THOR中可以执行的任何任务都可以在ProcTHOR中执行。例如,在E-AI中,房屋可用于:
- 导航[58,89,118,132,117,128,74,130]
- 多智能体交互[51,52,2]
- 重排和交互[115,36,39,23,106]
- 操纵[33,86,32,122]
- Sim2Real transfer[27,54,66]
- EVL [105,87,48,65,42,55]
- 视听导航[22,38,21]
- 虚拟现实交互[119,83,46]
在更广泛的计算机视觉领域,数据集可用于研究:
- 物体检测[64]
- NeRFs[80,110,43,71]
- 分割、深度和最佳流量估计[35,43]
- 生成建模[59,62,61]
- 遮挡推理[34]
- 姿态估计[19]
我们从JSON规范加载程序生成房屋的框架还可以研究场景杂乱的生成,构建更逼真的程序生成房屋,以及开发综合生成空间,以训练工厂[84]、办公室、杂货店[76]和完整的程序生成城市中的具体代理。
D ARCHITECTHOR
E Input Modalities
F Experiment details
G Performance Benchmark
为了计算 "分析 "部分所示的 FPS 性能基准,我们将房屋分为小型房屋(1-3 个房间的房屋)和大型房屋(7-10 个房间的房屋)。对于导航基准,我们执行移动和旋转操作。在交互基准中,我们执行了推动物体的操作。在查询环境数据时,我们会在每个时间步从环境中获取一个不常提供的元数据(例如,检查智能体的尺寸)。在每个时间步骤,我们都会从智能体的自我中心视角渲染一张 3 × 224 × 224 RGB 图像。实验在配有 8 个英伟达 Quadro RTX 8000 GPU 的服务器上进行。我们在单 GPU 测试中使用了 15 个进程,在 8 GPU 测试中使用了 120 个进程,平均分配给各个 GPU。表 11 显示了与 AI2-iTHOR 和 RoboTHOR 的比较。
