《MetaGPT智能体开发入门》学习手册 第四章课程任务
Github Trending 实现
Action 1:根据第四章 3.2.1和3.2.2的指引,独立实现对Github Trending(https://github.com/trending)页面的爬取,并获取每一个项目的 名称、URL链接、描述
方法:使用chatgpt进行实现
chatgpt交流过程
总结
- 使用F12 找到对应模块的代码,找其中的两个模块代就可以。
- 描述让chatgpt根据代码,写出beautiful提取元素代码
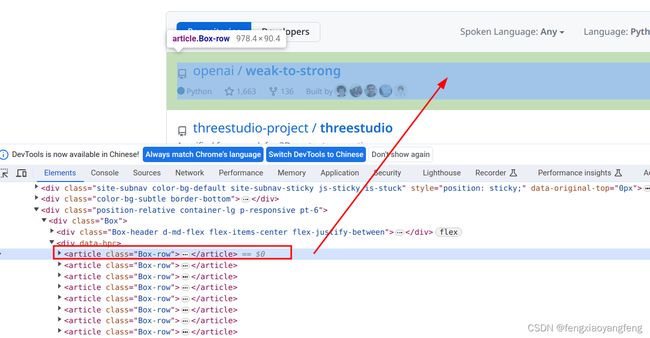
3.代码全文:
import aiohttp
from bs4 import BeautifulSoup
from metagpt.actions.action import Action
from metagpt.config import CONFIG
class GithubCrawl(Action):
async def run(self, url: str = "https://github.com/trending"):
async with aiohttp.ClientSession() as session:
async with session.get(url, proxy=CONFIG.global_proxy) as response:
html = await response.text()
soup = BeautifulSoup(html, 'html.parser')
# repos = soup.find_all('article', class_='Box-row')
repos = soup.select('article.Box-row')
data = []
for repo in repos:
# 提取仓库名和 URL
name_tag = repo.select_one('h2.h3.lh-condensed a')
name = name_tag.get_text(strip=True)
repo_url = "https://github.com" + name_tag['href']
# 提取描述
description_tag = repo.select_one('p.col-9.color-fg-muted.my-1.pr-4')
description = description_tag.get_text(strip=True) if description_tag else ''
# 提取 Star 数和 Fork 数
stars_tag = repo.select_one('a[href*="/stargazers"]')
stars = stars_tag.get_text(strip=True) if stars_tag else ''
forks_tag = repo.select_one('a[href*="/forks"]')
forks = forks_tag.get_text(strip=True) if forks_tag else ''
# 提取编程语言
language_tag = repo.select_one('span[itemprop="programmingLanguage"]')
language = language_tag.get_text(strip=True) if language_tag else ''
# 提取今日 Star 数
stars_today_tag = repo.select_one('span.d-inline-block.float-sm-right')
stars_today = stars_today_tag.get_text(strip=True) if stars_today_tag else ''
data.append({
'name': name,
'url': repo_url,
'description': description,
'stars': stars,
'forks': forks,
'language': language,
'stars_today': stars_today
})
# data 包含了所有提取的信息
return data
Huggingface Papers action实现
- Action 2:独立完成对Huggingface Papers
- (https://huggingface.co/papers)页面的爬取,先获取到每一篇Paper的链接(提示:标题元素中的href标签),并通过链接访问标题的描述页面(例如:https://huggingface.co/papers/2312.03818),在页面中获取一篇Paper的 标题、摘要
- 整体和第一个github类似,这里多了一个步骤,要进行子页面的访问,描述清除就可以。
- 提示词:
你是一个精通python的爬虫工程师,需要使用aiohttp爬取https://huggingface.co/papers,获取所有paper的标题和paperhref。
然后构造正确的paper访问链接,通过每一篇paper链接访问标题的描述页面,paper(例如:https://huggingface.co/papers/2312.03818),在页面中获取一篇Paper的摘要。
- 代码全文:
import aiohttp
from bs4 import BeautifulSoup
from metagpt.config import CONFIG
from metagpt.actions import Action
from metagpt.roles import Role
from metagpt.schema import Message
from metagpt.logs import logger
import asyncio
class Fetchpaper(Action):
async def fetch_paper_details(self, paper_url):
async with aiohttp.ClientSession() as session:
async with session.get(paper_url,proxy=CONFIG.global_proxy) as response:
paper_html = await response.text()
soup = BeautifulSoup(paper_html, 'html.parser')
abstract_tag = soup.find('h2', string="Abstract").find_next_sibling('p')
abstract = abstract_tag.get_text(strip=True) if abstract_tag else 'No abstract found'
return abstract
async def run(self,url: str, *args, **kwargs):
base_url = "https://huggingface.co"
async with aiohttp.ClientSession() as session:
async with session.get(url,proxy=CONFIG.global_proxy) as response:
html = await response.text()
soup = BeautifulSoup(html, 'html.parser')
papers = soup.find_all('article', class_='flex flex-col overflow-hidden rounded-xl border')
paper_data = []
for paper in papers:
title_tag = paper.find('h3').find('a')
title = title_tag.get_text(strip=True)
paper_href = title_tag['href']
paper_url = base_url + paper_href
abstract = await self.fetch_paper_details(paper_url)
paper_data.append({
'title': title,
'url': paper_url,
'abstract': abstract
})
return paper_data
class Crawler(Role):
def __init__(self, name: str = "Crawler", profile: str = "Crawler", **kwargs):
super().__init__(name, profile, **kwargs)
self._actions = [Fetchpaper()]
async def _act(self):
todo = self._rc.todo
msg = self.get_memories(k=1)[0] # find the most recent messages
code_text = await todo.run(msg.content)
msg = Message(content=code_text, role=self.profile,
cause_by=type(todo))
return msg
async def main():
msg = "https://huggingface.co/papers"
role = Crawler()
logger.info(msg)
result = await role.run(msg)
logger.info(result)
asyncio.run(main())
资讯文档实现
1.要求: 参考第三章 1.4 的内容,重写有关方法,使你的Agent能自动生成总结内容的目录,然后根据二级标题进行分块,每块内容做出对应的总结,形成一篇资讯文档;
2.问题:token超过限制
- 解决方法:
- 使用langchain
- 换更长的模型
3.代码实现:
- 结合langchain进行实现。
import asyncio
from metagpt.logs import logger
from metagpt.roles import Role
from metagpt.schema import Message
from metagpt.utils.file import File
from datetime import datetime
from metagpt.const import TUTORIAL_PATH
from typing import Dict
from metagpt.utils.common import OutputParser
from metagpt.actions import Action
import aiohttp
from bs4 import BeautifulSoup
from metagpt.config import CONFIG
import time
import openai
class Fetchpaper(Action):
async def fetch_paper_details(self, paper_url):
async with aiohttp.ClientSession() as session:
async with session.get(paper_url,proxy=CONFIG.global_proxy) as response:
paper_html = await response.text()
soup = BeautifulSoup(paper_html, 'html.parser')
abstract_tag = soup.find('h2', string="Abstract").find_next_sibling('p')
abstract = abstract_tag.get_text(strip=True) if abstract_tag else 'No abstract found'
return abstract
async def run(self,url: str, *args, **kwargs):
base_url = "https://huggingface.co"
async with aiohttp.ClientSession() as session:
async with session.get(url,proxy=CONFIG.global_proxy) as response:
html = await response.text()
soup = BeautifulSoup(html, 'html.parser')
papers = soup.find_all('article', class_='flex flex-col overflow-hidden rounded-xl border')
paper_data = []
for paper in papers:
title_tag = paper.find('h3').find('a')
title = title_tag.get_text(strip=True)
paper_href = title_tag['href']
paper_url = base_url + paper_href
abstract = await self.fetch_paper_details(paper_url)
paper_data.append({
'title': title,
'url': paper_url,
'abstract': abstract
})
return paper_data
class WriteDirectory(Action):
"""Action class for writing tutorial directories.
Args:
name: The name of the action.
language: The language to output, default is "Chinese".
用于编写教程目录的动作类。
参数:
name:动作的名称。
language:输出的语言,默认为"Chinese"。
"""
def __init__(self, name: str = "", language: str = "Chinese", *args, **kwargs):
super().__init__(name, *args, **kwargs)
self.language = language
async def run(self, paper_content: str, *args, **kwargs) -> Dict:
COMMON_PROMPT = """
You're a senior editor at huggingface. Interested in AI & ML.
You will need to generate a detailed summary report based on the content of the paper provided.
The summary report is divided into two steps: the first step generates the report outline,
and the second step generates the content according to the report outline.
Now let's do step one:`generate the outline of the summary report`
###paper_content:
'''{paper_content}'''
"""
DIRECTORY_PROMPT = COMMON_PROMPT + """
Please provide the specific outline of the summary report strictly following the following requirements:
1. The output must be strictly in the specified language, {language}.
2. Answer strictly in the dictionary format like {{"title": "xxx", "directory": [{{"dir 1": ["sub dir 1", "sub dir 2"]}}, {{"dir 2": ["sub dir 3", "sub dir 4"]}}]}}.
3. The directory should be as specific and sufficient as possible, with a primary and secondary directory.The secondary directory is in the array.
4. Do not have extra spaces or line breaks.
5. Each directory title has practical significance.
"""
prompt = DIRECTORY_PROMPT.format( paper_content=paper_content, language=self.language)
resp = await self._aask(prompt=prompt)
return OutputParser.extract_struct(resp, dict)
class WriteContent(Action):
"""Action class for writing tutorial content.
Args:
name: The name of the action.
directory: The content to write.
language: The language to output, default is "Chinese".
"""
def __init__(self, name: str = "", directory: str = "", language: str = "Chinese", *args, **kwargs):
super().__init__(name, *args, **kwargs)
self.language = language
self.directory = directory
async def run(self, paper_content: str, *args, **kwargs) -> str:
COMMON_PROMPT = """
You're a senior editor at huggingface. Interested in AI & ML.
You will need to generate a detailed summary report based on the content of the paper provided.
The summary report is divided into two steps: the first step generates the report outline,
and the second step generates the content according to the report outline.
The first step is complete,Now let's do step two:`generates the content according to the report outline`
"""
CONTENT_PROMPT = COMMON_PROMPT + """
Now I will give you the module directory titles for the summary report.
Please output the detailed principle content of this title in detail based on the {paper_content}.
The module directory titles for the summary report is as follows:
{directory}
###paper_content:
'''{paper_content}'''
Strictly limit output according to the following requirements:
1. Follow the Markdown syntax format for layout.
2. If there are code examples, they must follow standard syntax specifications, have document annotations, and be displayed in code blocks.
3. The output must be strictly in the specified language, {language}.
4. Do not have redundant output, including concluding remarks.
"""
prompt = CONTENT_PROMPT.format(
paper_content=paper_content, language=self.language, directory=self.directory)
return await self._aask(prompt=prompt)
class ReportAssistant(Role):
"""Report assistant, based on the provided paper contents to generate a summary report document in markup format.
Args:
name: The name of the role.
profile: The role profile description.
goal: The goal of the role.
constraints: Constraints or requirements for the role.
language: The language in which the tutorial documents will be generated.
"""
def __init__(
self,
name: str = "Stitch",
profile: str = "Tutorial Assistant",
goal: str = "Generate tutorial documents",
constraints: str = "Strictly follow Markdown's syntax, with neat and standardized layout",
language: str = "Chinese",
):
super().__init__(name, profile, goal, constraints)
self._init_actions([Fetchpaper,WriteDirectory(language=language)])
self.topic = ""
self.main_title = ""
self.total_content = ""
self.language = language
self.paper_content = ""
self.url = ""
async def _think(self) -> None:
"""Determine the next action to be taken by the role."""
logger.info(self._rc.state)
logger.info(self,)
if self._rc.todo is None:
self._set_state(0)
return
if self._rc.state + 1 < len(self._states):
self._set_state(self._rc.state + 1)
else:
self._rc.todo = None
async def _handle_directory(self, titles: Dict) -> Message:
"""Handle the directories for the report document.
Args:
titles: A dictionary containing the titles and directory structure,
such as {"title": "xxx", "directory": [{"dir 1": ["sub dir 1", "sub dir 2"]}]}
Returns:
A message containing information about the directory.
"""
self.main_title = titles.get("title")
directory = f"{self.main_title}\n"
self.total_content += f"# {self.main_title}"
actions = list()
for first_dir in titles.get("directory"):
actions.append(WriteContent(
language=self.language, directory=first_dir))
key = list(first_dir.keys())[0]
directory += f"- {key}\n"
for second_dir in first_dir[key]:
directory += f" - {second_dir}\n"
self._init_actions(actions)
self._rc.todo = None
return Message(content=directory)
async def _act(self) -> Message:
"""Perform an action as determined by the role.
Returns:
A message containing the result of the action.
"""
todo = self._rc.todo
if type(todo) is Fetchpaper:
msg = self.get_memories(k=1)[0]
self.url = msg.content
self.paper_content = await todo.run(url=self.url)
elif type(todo) is WriteDirectory:
# msg = self._rc.memory.get(k=1)[0]
# self.topic = msg.content
resp = await todo.run(paper_content=self.paper_content)
logger.info(resp)
return await self._handle_directory(resp)
else:
try:
resp = await todo.run(paper_content=self.paper_content)
time.sleep()
logger.info(resp)
if self.total_content != "":
self.total_content += "\n\n\n"
self.total_content += resp
return Message(content=resp, role=self.profile)
except openai.error.RateLimitError:
# 在速率限制错误时等待一段时间
await asyncio.sleep(60) # 等待 60 秒
# 可能需要重新尝试请求或采取其他措施
async def _react(self) -> Message:
"""Execute the assistant's think and actions.
Returns:
A message containing the final result of the assistant's actions.
"""
while True:
await self._think()
if self._rc.todo is None:
break
msg = await self._act()
root_path = TUTORIAL_PATH / datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
await File.write(root_path, f"{self.main_title}.md", self.total_content.encode('utf-8'))
return msg
async def main():
msg = "https://huggingface.co/papers"
role = ReportAssistant()
logger.info(msg)
result = await role.run(msg)
logger.info(result)
asyncio.run(main())
Agent定时发送资讯文档
- 内容:自定义Agent的SubscriptionRunner类,独立实现Trigger、Callback的功能,让你的Agent定时为通知渠道发送以上总结的资讯文档(尝试实现邮箱发送的功能,这是加分项)
2.由于资讯文档未实现langchain功能,所有直接把文档扔给gpt,根据提示词进行总结
3.实现渠道:discord,微信,163邮箱。
-
discord: 参考教程
https://discordpy.readthedocs.io/en/stable/discord.html -
通过下面设置,得到url,然后访问进行授权,最后到前台页面,就能拿到channel_id:
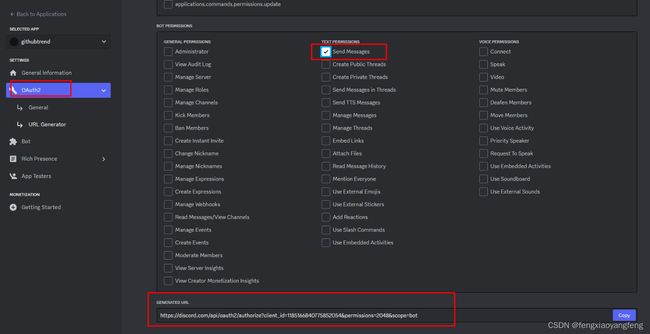
-
DISCORD_CHANNEL_ID 是下图052结尾的那个,
开始我以为是第1个,实际不是。

- DISCORD_TOKEN 如下图,要reset_token一下才能获取。

不要和client_id,client_secret,APPLICATION ID,PUBLIC KEY混淆了,这些都不是。
4.提示词:
TRENDING_ANALYSIS_PROMPT = """# Requirements
1.You're a senior editor at huggingface. Interested in AI & ML.
2.You will need to generate a detailed summary report based on the content of the paper provided.
3.the output language should be in {language}.
# format
Strictly limit output according to the following requirements:
1. the outline has appropriate summary headings
2.the outline has a suitable number of level 1 key points
3.each level 1 point has 3 level 2 points.
4.Follow the Markdown syntax format for layout.
#paper_content:
{paper_content}
# Format Example
## level 1 point
### level 1 subpoint
### level 1 subpoint
### level 1 subpoint
"""
- 完整代码:
import asyncio
import os
from typing import Any, AsyncGenerator, Awaitable, Callable, Optional
import aiohttp
import discord
from aiocron import crontab
from bs4 import BeautifulSoup
from pydantic import BaseModel, Field
from pytz import BaseTzInfo
from metagpt.actions.action import Action
from metagpt.config import CONFIG
from metagpt.logs import logger
from metagpt.roles import Role
from metagpt.schema import Message
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import os
from typing import Optional
# 订阅模块,可以from metagpt.subscription import SubscriptionRunner导入,这里贴上代码供参考
class SubscriptionRunner(BaseModel):
"""A simple wrapper to manage subscription tasks for different roles using asyncio.
Example:
>>> import asyncio
>>> from metagpt.subscription import SubscriptionRunner
>>> from metagpt.roles import Searcher
>>> from metagpt.schema import Message
>>> async def trigger():
... while True:
... yield Message("the latest news about OpenAI")
... await asyncio.sleep(3600 * 24)
>>> async def callback(msg: Message):
... print(msg.content)
>>> async def main():
... pb = SubscriptionRunner()
... await pb.subscribe(Searcher(), trigger(), callback)
... await pb.run()
>>> asyncio.run(main())
"""
tasks: dict[Role, asyncio.Task] = Field(default_factory=dict)
class Config:
arbitrary_types_allowed = True
async def subscribe(
self,
role: Role,
trigger: AsyncGenerator[Message, None],
callback: Callable[
[
Message,
],
Awaitable[None],
],
):
"""Subscribes a role to a trigger and sets up a callback to be called with the role's response.
Args:
role: The role to subscribe.
trigger: An asynchronous generator that yields Messages to be processed by the role.
callback: An asynchronous function to be called with the response from the role.
"""
loop = asyncio.get_running_loop()
async def _start_role():
async for msg in trigger:
resp = await role.run(msg)
await callback(resp)
self.tasks[role] = loop.create_task(_start_role(), name=f"Subscription-{role}")
async def unsubscribe(self, role: Role):
"""Unsubscribes a role from its trigger and cancels the associated task.
Args:
role: The role to unsubscribe.
"""
task = self.tasks.pop(role)
task.cancel()
async def run(self, raise_exception: bool = True):
"""Runs all subscribed tasks and handles their completion or exception.
Args:
raise_exception: _description_. Defaults to True.
Raises:
task.exception: _description_
"""
while True:
for role, task in self.tasks.items():
if task.done():
if task.exception():
if raise_exception:
raise task.exception()
logger.opt(exception=task.exception()).error(f"Task {task.get_name()} run error")
else:
logger.warning(
f"Task {task.get_name()} has completed. "
"If this is unexpected behavior, please check the trigger function."
)
self.tasks.pop(role)
break
else:
await asyncio.sleep(1)
# Actions 的实现
TRENDING_ANALYSIS_PROMPT = """# Requirements
1.You're a senior editor at huggingface. Interested in AI & ML.
2.You will need to generate a detailed summary report based on the content of the paper provided.
3.the output language should be in {language}.
# format
Strictly limit output according to the following requirements:
1. the outline has appropriate summary headings
2.the outline has a suitable number of level 1 key points
3.each level 1 point has 3 level 2 points.
4.Follow the Markdown syntax format for layout.
#paper_content:
{paper_content}
# Format Example
## level 1 point
### level 1 subpoint
### level 1 subpoint
### level 1 subpoint
"""
class Fetchpaper(Action):
async def fetch_paper_details(self, paper_url):
async with aiohttp.ClientSession() as session:
async with session.get(paper_url,proxy=CONFIG.global_proxy) as response:
paper_html = await response.text()
soup = BeautifulSoup(paper_html, 'html.parser')
abstract_tag = soup.find('h2', string="Abstract").find_next_sibling('p')
abstract = abstract_tag.get_text(strip=True) if abstract_tag else 'No abstract found'
return abstract
async def run(self,url: str="https://huggingface.co/papers", *args, **kwargs):
base_url = "https://huggingface.co"
async with aiohttp.ClientSession() as session:
async with session.get(url,proxy=CONFIG.global_proxy) as response:
html = await response.text()
soup = BeautifulSoup(html, 'html.parser')
papers = soup.find_all('article', class_='flex flex-col overflow-hidden rounded-xl border')
paper_data = []
for paper in papers:
title_tag = paper.find('h3').find('a')
title = title_tag.get_text(strip=True)
paper_href = title_tag['href']
paper_url = base_url + paper_href
abstract = await self.fetch_paper_details(paper_url)
paper_data.append({
'title': title,
'url': paper_url,
'abstract': abstract
})
return paper_data[:-5]
class Reportsummary(Action):
async def run(
self,
paper_content: Any,
language: str = "Chinese"
):
return await self._aask(TRENDING_ANALYSIS_PROMPT.format(paper_content=paper_content,language=language))
# Role实现
class OssWatcher(Role):
def __init__(
self,
name="hugger",
profile="OssWatcher",
goal="Generate a detailed summary report based on the content of the paper provided.",
constraints="Only analyze based on the provided hugging face paper content.",
):
super().__init__(name, profile, goal, constraints)
self._init_actions([Fetchpaper, Reportsummary])
self._set_react_mode(react_mode="by_order")
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self._rc.todo}")
# By choosing the Action by order under the hood
todo = self._rc.todo
msg = self.get_memories(k=1)[0] # find the most k recent messages
result = await todo.run(msg.content)
msg = Message(content=result, role=self.profile, cause_by=type(todo))
self._rc.memory.add(msg)
return msg
# Trigger
class HuggingCronTrigger():
def __init__(self, url: str = "https://huggingface.co/papers"):
self.url = url
self.started = False
def __aiter__(self):
return self
async def __anext__(self):
if self.started:
raise StopAsyncIteration
self.started = True
return Message(self.url)
# callback
async def discord_callback(msg: Message):
intents = discord.Intents.default()
intents.message_content = True
client = discord.Client(intents=intents, proxy=CONFIG.global_proxy)
token = os.environ["DISCORD_TOKEN"]
channel_id = int(os.environ["DISCORD_CHANNEL_ID"])
async with client:
await client.login(token)
channel = await client.fetch_channel(channel_id)
lines = []
for i in msg.content.splitlines():
if i.startswith(("# ", "## ", "### ")):
if lines:
await channel.send("\n".join(lines))
lines = []
lines.append(i)
if lines:
await channel.send("\n".join(lines))
class Mailwangyi:
def __init__(self):
"""
sender_email : "发件邮"
nickname: "草地上看小说的羊"
authorize_code : "授权码 需要163设置那申请"
smtp_server : "smtp.163.com"
server_port : 25
receiver_email: "收件箱"
"""
# 初始化设置
self.sendFromAddress = os.getenv('sender_email')
self.sendFromNICKNAME = "草地上看小说的羊"
self.password = os.getenv('authorize_code')
self.smtp_server = "smtp.163.com"
self.smtp_server_port = 25
self.sendToAddress = os.getenv('receiver_google_email')
# 创建SMTP服务器连接
self.server = smtplib.SMTP(self.smtp_server, self.smtp_server_port)
self.server.login(self.sendFromAddress, self.password)
def send_message(self, content, subject: Optional[str] = None):
msg = MIMEText(content, 'plain', 'utf-8')
msg['Subject'] = Header(subject, 'utf-8')
msg['From'] = f"{self.sendFromAddress}"
# msg['From'] = f"{self.sendFromNICKNAME}<{self.sendFromAddress}>"
msg['To'] = self.sendToAddress
# 发送邮件
try:
self.server.sendmail(self.sendFromAddress, [self.sendToAddress], msg.as_string())
print("邮件发送成功")
except Exception as e:
print(f"邮件发送失败: {e}")
finally:
self.server.quit()
async def _request(self, method, url, **kwargs):
async with aiohttp.ClientSession() as session:
async with session.request(method, url, **kwargs) as response:
response.raise_for_status()
return await response.json()
async def wangyi163_callback(msg: Message, subject: str = "hugging face paper info"):
client = Mailwangyi()
client.send_message(msg.content, subject=subject)
class WxPusherClient:
def __init__(self, token: Optional[str] = None, base_url: str = "http://wxpusher.zjiecode.com"):
self.base_url = base_url
self.token = token or os.environ["WXPUSHER_TOKEN"]
async def send_message(
self,
content,
summary: Optional[str] = None,
content_type: int = 1,
topic_ids: Optional[list[int]] = None,
uids: Optional[list[int]] = None,
verify: bool = False,
url: Optional[str] = None,
):
payload = {
"appToken": self.token,
"content": content,
"summary": summary,
"contentType": content_type,
"topicIds": topic_ids or [],
"uids": uids or os.environ["WXPUSHER_UIDS"].split(","),
"verifyPay": verify,
"url": url,
}
url = f"{self.base_url}/api/send/message"
return await self._request("POST", url, json=payload)
async def _request(self, method, url, **kwargs):
async with aiohttp.ClientSession() as session:
async with session.request(method, url, **kwargs) as response:
response.raise_for_status()
return await response.json()
async def wxpusher_callback(msg: Message):
client = WxPusherClient()
await client.send_message(msg.content, content_type=3)
# 运行入口,
async def main( discord: bool = True, wxpusher: bool = True,mailpusher: bool = True):
callbacks = []
if discord:
callbacks.append(discord_callback)
if wxpusher:
callbacks.append(wxpusher_callback)
if mailpusher:
callbacks.append(wangyi163_callback)
if not callbacks:
async def _print(msg: Message):
print(msg.content)
callbacks.append(_print)
async def callback(msg):
await asyncio.gather(*(call(msg) for call in callbacks))
runner = SubscriptionRunner()
await runner.subscribe(OssWatcher(), HuggingCronTrigger(), callback) # 移除spec参数
await runner.run()
if __name__ == "__main__":
import fire
fire.Fire(main)
# print(os.environ["WXPUSHER_TOKEN"])
# print(os.environ["WXPUSHER_UIDS"])
# print(os.environ["DISCORD_TOKEN"])
# print(os.environ["DISCORD_CHANNEL_ID"])
discord实现效果
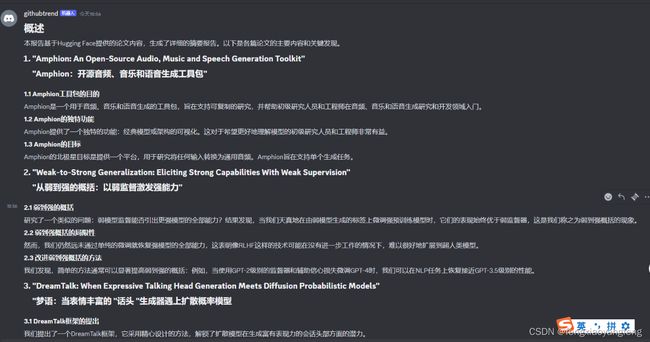
微信实现效果

邮箱实现效果
注意事项
不同邮箱 发件箱的格式可能不同
标准库 smtplib 不支持异步操作,所以下面不能加await
async def wangyi163_callback(msg: Message, subject: str = "hugging face paper info"):
client = Mailwangyi()
client.send_message(msg.content, subject=subject)
# 如果是await client.send_message...会报错
msg['From'] = f"{self.sendFromAddress}" # 谷歌邮箱
# msg['From'] = f"{self.sendFromNICKNAME <{self.sendFromAddress}>" # 163邮箱

相关阅读
《MetaGPT智能体开发入门》学习手册 第三章课程任务
《MetaGPT智能体开发入门》学习手册 第一 二章学习总结