python的学习day_03
目录
元组:
元组的特点:
代码:
字符串:
代码:
输出的结果是:
总结:
(序列)的切片:
对字符串的切片代码:
输出的结果:
对list进行切片
输出的结果:
对tuple进行切片(倒着) :
运行的结果:
上的代码也可以更改为:
集合:{}
代码:
运行的结果是:
字典:
用法是:
字典的常用操作:
代码:
运行的结果:
数据容器的分类:
数据容器的通用操作
类型转换: 容器转列表:
代码:
输出的结果:
类型转换:容器转元组:
容器的排序:
代码:
运行结果:
小结:编辑
函数进阶:
函数的多返回值:
代码:
函数的多种传参方式:
位置参数 - 默认使用形式
代码:
关键字参数
代码:
缺省参数(默认值)
代码:
不定长参数
位置传参(*args)
代码:
运行的结果:
关键字传递:
代码:
运行的结果:
总结: 编辑
函数作为参数传递
代码:
运行的结果:
匿名函数:
代码:
元组:
元组和list最大的区别就是元组是不可以被修改的, 而list是可以被修改的,其里面的方法和list没多大区别
元组的特点:


代码:
# 定义元组
a = (1, 2, 3, 4, "code") # 是不可被修改的
for i in a:
print(i, end=" ")
# 定义空的元组
a2 = tuple() # 或者直接写 ()
# 注意 要是只有一个元素的话 一个元素的后面要加个 逗号
a3 = (1,)
print(type(a3))
# 元组的嵌套
a4 = ((1, 2, 3), (4, 5, 6))
print(a4[1][1]) # 输出的结果是 5
# index(元素)
a5 = (1, 2, 3)
print(f"1在元组里面的位置是: {a3.index(1)}")
# 遍历元组
i = 0
while i < len(a5):
print(a5[i], end=" ")
i += 1
print() # 换行
for i in range(0, len(a5)):
print(a5[i], end=" ")
字符串:
和其他语言里面的字符串几乎是一样的,是不可以被修改的
- 通过下标索引取值 其中 s[-1]表示的是最后一个元素 s[-2]表示的是倒数第二个元素
- index() 查找目标第一次出现的位置,注意下标从0开始的,可以查找字符串,也可以查找字符
- split() 和java里面的分割是一样的, 是按照什么进行分割的,字符串本身不变,而是得到了一个列表对象
- replace(字符串1, 字符串2) 将字符串中的全部字符串1,替换为字符串2,不是修改,是得到了一个新的字符串, 需要注意的是 直接输出s.replace("You", "me"),是会报错的
- strip(去前后指定的字符串),前后都是去去除指定的字符串,只到遇到不满足的再停下来,注意这里的去除是按照单个的字符,比如strip("12")表示的是字符串前后"1", "2"都会被去除掉
- count("字符串") 统计字符串出现的次数
- len() 统计字符串的长度
代码:
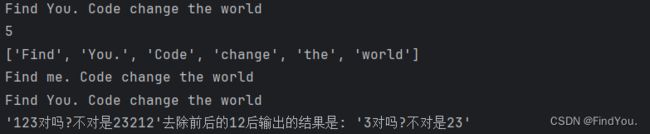
s = "Find You. Code change the world"
# 通过下标索引进行取值
for i in range(len(s)):
print(s[i], end="")
print()
# index方法 可以查找字符串也可以操作字符
print(s.index("You")) # 这个返回的也就是You中的Y的位置
# 字符串的分割 和java里面的一样 返回的是数组
print(s.split(" ")) # 输出的结果是 ['Find', 'You.', 'Code', 'change', 'the', 'world']
# 替换
new_s = s.replace("You", "me")
print(new_s) # 输出的结果是Find me. Code change the world
print(s) # s还是没有改变的
# 字符串的规整操作
t = "123对吗?不对是23212"
new_t = t.strip("12") # 只要满足12其中的一个我就一直删除 直到不满足我就立刻停下来
print(f"'{t}'去除前后的12后输出的结果是: '{new_t}'") # 输出的结果是3对吗?不对是23
输出的结果是:
总结:

(序列)的切片:


注意:结束下标是不包含的 也就是前闭后开
起始下标不写的话,默认从头开始,结束下标不写的话,默认截取到末尾(包括)
对字符串的切片代码:
s = "Find You."
# 我想要把You.给截取出来
start = s.index("You.")
end = start + len("You.")
new_s = s[start:end:1] # 步长不写默认是1
print(new_s)
输出的结果:
![]()
对list进行切片
对my_list进行切片,步长是2,也就是截取一个跳一个
# 对list进行切片
my_list = [1, 2, 3, 4, 5, 6]
# 我想把里面的偶数给切出来
my_new_list = my_list[1:len(my_list):2]
print(my_new_list)输出的结果:
![]()
对tuple进行切片(倒着) :
# 对tuple进行切片 倒着切
my_tuple = (1, 2, 3, 4, 5, 6)
my_new_tuple = my_tuple[-1:-1 * len(my_tuple) - 1:-1]
print(my_new_tuple)运行的结果:
![]()
注意:要是倒着切的话,开始的位置和结束的位置也要反向标
上的代码也可以更改为:
# 对tuple进行切片 倒着切
my_tuple = (1, 2, 3, 4, 5, 6)
my_new_tuple = my_tuple[::-1]
print(my_new_tuple)输出的结果是一样的
集合:{}
和其他容器最大的区别就是自带去重 也就是java里面的set,是无序的
- add() 添加新元素
- remove("目标元素") 移除元素
- pop() 随机取出元素,同时集合被修改,元素被取出
- clear() 清空集合
- 取两个集合的差集 集合1.difference(集合2) 集合1有而集合2没有的 但是不会影响集合本身
- 消除2个集合的差集 集合1.difference_update(集合2), 返回的是None 集合1被修改,集合2不变
- 集合的合并 集合1.union(集合2) 集合1和集合2的元素不变, 生成一个新的集合
代码:
# 不重复 是无序的
my_set = {"Find", "You.", "You."}
print(my_set)
# 定义空集合
my_set2 = set()
print(f"my_set2的类型是: {type(my_set2)}")
# 添加元素
my_set2.add(1)
my_set2.add("Find")
my_set2.add("You.")
print(my_set2)
# 移除元素
my_set2.remove(1)
print(my_set2) # 变为空了 返回的是set()
# 随机取出元素
print(my_set2.pop())
num1 = {1, 2, 4}
num2 = {1, 4, 3, 5}
print(num1.difference(num2)) # 输出的结果是2
print(num1)
num1.difference_update(num2) # 返回的是None
print(num1) # 输出的结果是2
print(num1.union(num2)) # 输出的结果是 {1, 2, 3, 4, 5}
运行的结果是:

字典:
这个和其他语言里面的map是一样的
用法是:
{key: value, key2: value2}

字典的常用操作:
- my_dict[key] = value, key存在就是更新,不存在就是增加
- 元素的删除 pop(key) 删除指定的元素
- 清空元素clear()
- 获取全部的key my_dict.keys()
- max(my_dict)比较的是每个key的value 返回的是key
代码:
my_dict = {"Find": 20, "You.": 12}
print(f"my_dict中的元素是: {my_dict}")
print(my_dict["Find"]) # 这个和其他语言里面的map是一样的
stu_score_dict = {
"Find": {
"语文": 99,
"数学": 88,
"英语": 99
}, "You": {
"语文": 90,
"数学": 91,
"英语": 92
}
}
print(f"Find的语文分数是: {stu_score_dict['Find']['语文']}")
# 获取字典里面的全部的key
keys = my_dict.keys()
# 遍历
for key in keys:
print(key, my_dict[key])运行的结果:

数据容器的分类:



数据容器的通用操作
类型转换: 容器转列表:
字符串转列表,是把每个元素都转换为列表
字典转列表,是把全部的key都转化为了列表,抛弃了value
代码:
my_list = [1, 2, 3, 4]
print(list(my_list))
my_tuple = (1, 2, 3, 4)
print(list(my_tuple))
my_string = "FindYou."
print(list(my_string))
my_dict = {"Find": 13, "You.": 14}
print(list(my_dict))
输出的结果:

类型转换:容器转元组:
和转列表没什么区别,只不过是[] 变为了()
总的来说是相互转换的,转换后的要符合转换后的容器的特点,比如转换为集合的时候,会变的去重,无序的
容器的排序:
sorted(容器, reverse=True or False) 第二个参数不写默认是 reverse=False 是从小到大的,我的;的理解是从小到大,还翻转吗?False,不翻转了,ok,就是从小到大 reverse=True是从大到小排序的,还是和其他语言一样,对字典进行排序的时候是按照value 进行排序的
代码:
# 对list进行排序
my_list = [1, 3, 2, 4]
my_list = sorted(my_list) # 默认是从小到大排序的
print(my_list)
# 翻转的方法一:
print(my_list[::-1])
# 翻转的方法二:
my_list = sorted(my_list, reverse=True)
print(my_list)
# 对字典进行排序 是按照value进行排序的 默认是从小到大
my_dic = {"Find": 13, "You.": 14, "Code": 11}
print(sorted(my_dic)) # 输出的结果是:['Code', 'Find', 'You.']
print(sorted(my_dic, reverse=True)) # 输出的结果是:['You.', 'Find', 'Code']
运行结果:

小结:
函数进阶:
函数的多返回值:
return 值1, 值2,..... 注意是用逗号隔开
代码:
def test_return():
return 1, 2 # 注意这里用逗号隔开的
x, y = test_return()
print(x, y) # 输出的是1 2函数的多种传参方式:
位置参数 - 默认使用形式
代码:
def user_info(name, age, gender):
print(f"姓名: {name}, 年龄: {age}, 性别: {gender}")
user_info("FindYou.", 20, "男")关键字参数
代码:
def user_info(name, age, gender):
print(f"姓名: {name}, 年龄: {age}, 性别: {gender}")
user_info(name="FindYou.", age=20, gender="男")
user_info(age=20, name="FindYou.", gender="男")
user_info("FindYou.", gender="男", age=20)缺省参数(默认值)
代码:
def user_info(name, age, gender="男"):
print(f"姓名: {name}, 年龄: {age}, 性别: {gender}")
user_info("FindYou.", 20, )
user_info("FindYou.", 20)
user_infor("FindYou.", 20, "?")不定长参数
位置传参(*args)
args你可以随便换,只不过这样写显得专业,用的是一个 * ,构成的是一个元组类型
![]()
代码:
# 位置传递 一个*
def user_info(*args): # 一般写args显得专业
print(args)
print(f"元素的类型是: {type(args)}")
user_info("FindYou.", 20, "男")
user_info("FindYou.")运行的结果:
注意,是元组,你看要是只有一个的话,最后会加个逗号

关键字传递:
![]()
代码:
# 关键字传递 两个** 需要满足key = value的形式 这样组成的是字典
def stu_score(**kwargs):
print(kwargs)
print(f"元素的类型是: {type(kwargs)}")
# 在 Python 中,不允许使用数字作为变量名或关键字参数名
stu_score(FindYou=100, FindYou2=110)
# 就相当于是你在函数里面命名了两个变量了 FindYou2 = 110 这就是为什么不允许传整数了,也不允许传 "FindYou"=110,Y因为就没有带引号的变量名
运行的结果:

总结:

函数作为参数传递
代码:
def test_func(add):
ret = add(1, 2)
print(f"add参数的类型是: {type(add)}")
print(ret)
def add(x, y):
return x + y
test_func(add)运行的结果:

匿名函数:

代码:
# lambda关键字, 可以定义匿名函数(无名称) 无法二次使用
def test_func(add):
ret = add(1, 2)
print(ret)
test_func(lambda x, y: x + y)
文件
文件的读取操作
open() 打开函数
