MobileNetV2: Inverted Residuals and Linear Bottlenecks(待补,2018提交2019最后修改此前所有都以最后修改时间为准)

文章目录
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Preliminaries, discussion and intuition
-
- 3.1. Depthwise Separable Convolutions
- 3.2. Linear Bottlenecks(AAA)
- 3.3. Inverted residuals
- 3.4. Information flow interpretation
- 4. Model Architecture
- 5. Implementation Notes
-
- 5.1. Memory efficient inference
- 6. Experiments
- 7. Conclusions and future work
原文链接
Abstract
在本文中,我们描述了一种新的移动架构,MobileNetV2,它提高了移动模型在多个任务和基准测试以及不同模型尺寸范围内的最新性能。我们还描述了在我们称为SSDLite的新框架中应用这些移动模型进行对象检测的有效方法。此外,我们还演示了如何通过DeepLabv3的简化形式(我们称之为mobile DeepLabv3)构建移动语义分割模型
它是基于一个反向残余结构,其中的捷径连接是在薄瓶颈层之间。中间扩展层使用轻量级深度卷积来过滤作为非线性源的特征。此外,我们发现为了保持表征能力,在窄层中去除非线性是很重要的。我们证明,这提高了性能,并提供了导致这种设计的直觉
最后,我们的方法允许从转换的表达性中解耦输入/输出域,这为进一步分析提供了方便的框架。我们在ImageNet[1]分类、COCO目标检测[2]、VOC图像分割[3]上进行了性能测试。我们评估了准确性、通过乘法-加法(MAdd)测量的操作数量、实际延迟和参数数量之间的权衡
1. Introduction
神经网络已经彻底改变了机器智能的许多领域,使具有挑战性的图像识别任务具有超人的准确性。然而,提高准确性的动力往往是有代价的:现代最先进的网络需要高计算资源,超出了许多移动和嵌入式应用程序的能力
本文介绍了一种新的神经网络架构,它是专门为移动和资源受限环境量身定制的。我们的网络推动了移动定制计算机视觉模型的最新发展,在保持相同精度的同时显著减少了所需的操作和内存数量
我们的主要贡献是一种新颖的层模块:具有线性瓶颈的倒残差。该模块将低维压缩表示作为输入,首先将其扩展到高维并使用轻量级深度卷积进行过滤。特征随后通过线性卷积投影回低维表示。官方实现可以在[4]中作为TensorFlow-Slim模型库的一部分获得
该模块可以在任何现代框架中使用标准操作有效地实现,并允许我们的模型使用标准基准在多个性能点上击败最先进的技术。此外,这个卷积模块特别适合于移动设计,因为它允许在推理过程中显著减少所需的内存占用,而无需完全实现大的中间张量。这减少了许多嵌入式硬件设计中对主存储器访问的需求,这些设计提供了少量非常快速的软件控制缓存
2. Related Work
调整深度神经结构以在精度和性能之间取得最佳平衡是过去几年活跃研究的一个领域。人工架构搜索和训练算法的改进,由许多团队进行,已经导致了早期设计的巨大改进,如AlexNet [5], VGGNet [6], GoogLeNet[7]。,和ResNet[8]。近年来,在算法架构探索方面取得了很多进展,包括超参数优化[9,10,11],以及各种网络修剪方法[12,13,14,15,16,17]和连通性学习[18,19]。大量的工作也致力于改变内部卷积块的连接结构,如ShuffleNet[20]或引入稀疏性[21]等[22]
在本文中,我们追求的目标是开发关于神经网络如何运作的更好的直觉,并使用它来指导最简单的网络设计。我们的方法应该被看作是对[23]和相关工作中描述的方法的补充。在这方面,我们的方法类似于[20,22]所采取的方法,并允许进一步提高性能,同时提供其内部操作的一瞥。我们的网络设计基于MobileNetV1[27],保留了其简单性,不需要任何特殊的操作员,同时显着提高了其准确性,实现了移动应用程序的多种图像分类和检测任务的最新状态
3. Preliminaries, discussion and intuition
3.1. Depthwise Separable Convolutions
深度可分离卷积是构建高效神经网络架构的关键[27,28,20],其基本思想是用分解后的卷积算子替换完整的卷积算子,将卷积分解为两个独立的层。第一层称为深度卷积,它通过对每个输入通道应用单个卷积滤波器来执行轻量级滤波。第二层是1 × 1的卷积,称为点向卷积,它负责通过计算输入通道的线性组合来构建新的特征
与传统层相比,有效的深度可分离卷积几乎减少了k^2的计算量。MobileNetV2使用k = 3 (3×3深度可分离卷积),因此计算成本比标准卷积小8到9倍,而精度只有很小的降低
3.2. Linear Bottlenecks(AAA)

考虑一个由n层组成的深度神经网络,每一层都有一个激活张量,维度为hi × w i × di。在本节中,我们将讨论这些激活张量的基本性质,我们将把它们视为具有2d维的h × wi“像素”的容器。非正式地说,对于真实图像的输入集,我们说层激活集(对于任何层L i)形成了一个“感兴趣的流形”。长期以来,人们一直认为神经网络中的流形可以嵌入到低维子空间中。换句话说,当我们查看深度卷积层的所有单独的d通道像素时,这些值中编码的信息实际上存在于一些流形中,这些流形反过来又可嵌入到低维子空间中
乍一看,这样的事实可以通过简单地降低层的维数从而降低操作空间的维数来捕获和利用。MobileNetV1已经成功地利用了这一点[27],通过宽度乘法器参数有效地在计算和精度之间进行权衡,并已被纳入其他网络的有效模型设计中[20]。根据这种直觉,宽度乘数方法允许人们减少激活空间的维度,直到感兴趣的流形跨越整个空间。然而,当我们回想起深度卷积神经网络实际上具有非线性的每坐标变换(如ReLU)时,这种直觉就失效了。例如,将ReLU应用于一维空间中的直线会产生一条“射线”,而在R^n空间中,它通常会产生一条具有n个关节的分段线性曲线。

嵌入高维空间的低维流形的ReLU变换的例子。在这些例子中,初始螺旋被嵌入到n维空间中,使用随机矩阵T,然后是ReLU,然后使用T的逆投影回二维空间。在上面n = 2的例子中,3会导致流形的某些点相互坍缩而导致信息丢失,而对于n = 15到30的变换是高度非凸的
很容易看出,一般来说,如果层变换ReLU(Bx)的结果具有非零体积S,则映射到内部S的点是通过输入的线性变换B得到的,从而表明输入空间中对应于全维输出的部分被限制为线性变换。换句话说,深度网络只在输出域的非零体积部分具有线性分类器的能力。我们参考补充材料作更正式的声明

另一方面,当ReLU折叠通道时,它不可避免地会丢失该通道中的信息。然而,如果我们有很多通道,并且激活流形中有一个结构,那么信息可能仍然保留在其他通道中。在补充材料中,我们证明了如果输入流形可以嵌入到激活空间的显著低维子空间中,那么ReLU变换在保留信息的同时将所需的复杂度引入可表达函数集
总之,我们强调了两个性质,它们表明了感兴趣的流形应该位于高维激活空间的低维子空间的要求:
1. 如果感兴趣的流形在ReLU变换后体积不为零,则对应于线性变换
2. ReLU能够保留输入流形的完整信息,但前提是输入流形位于输入空间的低维子空间中
这两个见解为优化现有的神经结构提供了经验提示:假设感兴趣的流形是低维的,我们可以通过在卷积块中插入线性瓶颈层来捕获它。实验证据表明,使用线性层是至关重要的,因为它可以防止非线性破坏太多的信息。在第6节中,我们从经验上表明,在瓶颈中使用非线性层确实会损害几个百分点的性能,进一步验证了我们的假设3。我们注意到,在[29]中也有类似的报告,其中非线性从传统残差块的输入中去除,从而提高了CIFAR数据集的性能

在本文的剩余部分,我们将使用瓶颈卷积。我们将输入瓶颈的尺寸与内部尺寸之间的比率称为扩展比
3.3. Inverted residuals
瓶颈块看起来类似于剩余块,每个块包含一个输入,然后是几个瓶颈,然后是扩展[8]。然而,根据瓶颈实际上包含所有必要信息的直觉,而扩展层仅仅作为伴随张量的非线性变换的实现细节,我们直接在瓶颈之间使用捷径
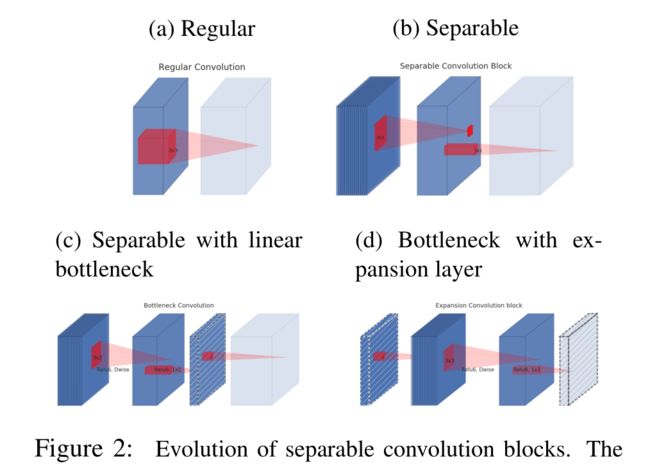
可分离卷积块的演化。对角线孵化的纹理表示不包含非线性的层。最后一层(浅色)表示下一个块的开始。注意:2d和2c在堆叠时是等效的块。最好以彩色观看。
图3提供了设计差异的可视化示意图。插入捷径的动机与经典残差连接的动机相似:我们希望提高梯度在乘法器层间传播的能力。然而,反向设计的内存效率要高得多(详见第5节),并且在我们的实验中效果略好
残差块[8,30]与倒残差的区别。对角孵化的层不使用非线性。我们使用每个块的厚度来表示其通道的相对数量。注意经典残差如何连接具有大量通道的层,而反向残差连接瓶颈。最好以彩色观看
瓶颈卷积的运行时间和参数计数
基本实现结构如表1所示。对于大小为h × w的块,扩展因子t和核大小k随d ‘输入通道和d ’‘输出通道,多层加所需的总数量是h·w·d ‘ ·t(d’+ k2 + d ‘’). 与(1)相比,这个表达式有一个额外的项,因为我们确实有一个额外的1 × 1卷积,但是我们网络的性质允许我们使用更小的输入和输出维度。在表3中,我们比较了MobileNetV1、MobileNetV2和ShuffleNet之间每种分辨率所需的大小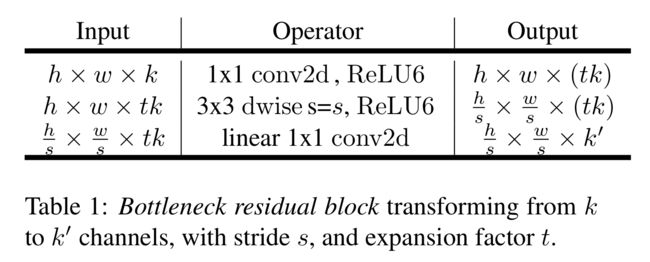
3.4. Information flow interpretation
我们架构的一个有趣的特性是,它提供了构建块(瓶颈层)的输入/输出域与层转换之间的自然分离——这是一个将输入转换为输出的非线性函数。前者可以看作是网络在每一层的容量,而后者则是网络的表现力。这与传统的卷积块形成对比,它们都是规则的和可分离的,其中表达性和容量都纠缠在一起,是输出层深度的函数
特别是,在我们的例子中,当内层深度为0时,由于快捷连接,底层卷积是恒等函数。当扩展比小于1时,这是一个经典的残差卷积块[8,30]。然而,为了达到我们的目的,我们展示了大于1的扩展比是最有用的
这种解释使我们能够将网络的表达性与其能力分开研究,我们相信,对这种分离的进一步探索将有助于更好地理解网络的特性
4. Model Architecture
我们的体系结构。如前一节所讨论的,基本构件是带有残差的瓶颈深度可分卷积。该块的详细结构如表1所示。MobileNetV2的架构包含有32个滤波器的初始全卷积层,然后是表2所示的19个剩余瓶颈层。我们使用ReLU6作为非线性是因为它在使用低精度计算时具有鲁棒性[27]。我们总是使用内核大小3×3作为现代网络的标准,并在训练期间使用dropout和批处理归一化
MobileNetV2:每行描述1个或多个相同(模跨距)层的序列,重复n次。相同序列中的所有层具有相同数量的输出通道c。每个序列的第一层有一个步幅s,所有其他层都使用步幅1。所有空间卷积都使用3 × 3核。扩展因子t总是应用于输入尺寸,如表1所示
除了第一层,我们在整个网络中使用恒定的扩展率。在我们的实验中,我们发现扩展率在5到10之间会产生几乎相同的性能曲线,较小的网络在较小的扩展率下表现更好,而较大的网络在较大的扩展率下表现更好
对于我们所有的主要实验,我们使用扩展因子为6应用于输入张量的大小。例如,瓶颈层取64通道输入张量,产生128通道张量,则中间扩展层为64·6 = 384通道
Trade-off hyper parameters
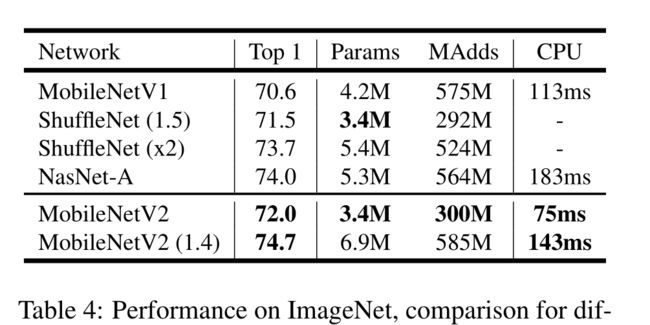
正如在[27]中,我们通过使用输入图像分辨率和宽度乘法器作为可调超参数来定制我们的架构,以适应不同的性能点,可以根据所需的精度/性能权衡进行调整。我们的主要网络(宽度乘法器1,224 × 224)的计算成本为3亿次乘法,并使用340万个参数。我们探索了性能权衡,输入分辨率从96到224,宽度乘数为0.35到1.4。网络计算成本从7倍加法到585M MAdds不等,模型尺寸在1.7M ~ 6.9M参数之间。
与[27]实现的一个小区别是,对于乘法器小于1,我们将宽度乘法器应用于除最后一个卷积层之外的所有层。这提高了小型模型的性能
5. Implementation Notes
5.1. Memory efficient inference
反向剩余瓶颈层允许特别有效的内存实现,这对移动应用程序非常重要。一个标准的高效推理实现,例如使用TensorFlow[31]或Caffe[32],构建一个有向无环计算超图G,由代表操作的边和代表中间计算张量的节点组成。计算的安排是为了最小化需要存储在内存中的张量的总数。在最一般的情况下,它搜索所有可能的计算顺序Σ(G),并选择最小的一个
式中R(i,π,G)是与π i…π n个节点,|A|表示张量A的大小,size(i)是操作i期间内部存储所需的内存总量
对于只有平凡并行结构的图(如残余连接),只有一个非平凡可行的计算顺序,因此可以简化计算图G上推理所需的总量和内存的界限:
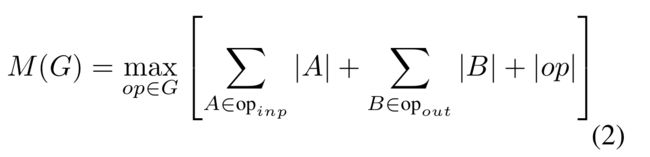
或者换句话说,内存量就是所有操作中组合输入和输出的最大总大小。在接下来的内容中,我们表明,如果我们将瓶颈剩余块视为单个操作(并将内部卷积视为一次性张量),则内存总量将由瓶颈张量的大小决定,而不是瓶颈内部张量的大小(并且更大)
Bottleneck Residual Block

如图3b所示的瓶颈阻塞算子F(x)可以表示为三个算子的组合:F(x) = [A◦N◦B]x
其中A是一个线性变换A: R s×s×k→R s×s×n, N是一个非线性的单通道变换N: R s×s×n→R s’×s ‘×n
B又是一个到输出域的线性变换B: R s ’×s ‘×n→R s ’‘×s ’‘×k ’
对于我们的网络N = ReLU6◦dwise◦ReLU6,但结果适用于任何单通道转换。假设输入域的大小为|x|,输出域的大小为|y|,那么计算F(x)所需的内存可以低至|s 2 k | + |s ‘ 2 k ’| + O(max(s 2,s ‘2))
这个算法是基于这样一个事实,即内张量I可以被表示为t个张量的串联,每个张量的大小为n/t我们的函数可以被表示为
通过累加总和,我们只需要在内存中始终保留一个大小为n/t的中间块。使用n = t,我们最终必须始终只保留中间表示的单个通道。使我们能够使用这个技巧的两个约束是(a)内部变换(包括非线性和深度)是每个通道的事实,以及**(b)连续的非每个通道操作符具有输入大小与输出大小的显着比例**。对于大多数传统的神经网络,这种技巧不会产生显著的改进
我们注意到,使用t-way分割计算F(X)所需的乘加运算符的数量与t无关,但是在现有的实现中,我们发现用几个较小的矩阵乘法替换一个矩阵乘法会由于缓存丢失增加而损害运行时性能。我们发现,当t是2到5之间的一个小常数时,这种方法最有用。它显著降低了内存需求,但仍然允许人们利用深度学习框架提供的高度优化的矩阵乘法和卷积算子所获得的大部分效率。特殊框架级别的优化是否会导致进一步的运行时改进还有待观察。

不同结构下卷积块的比较。ShuffleNet使用群卷积[20]和洗牌,它也使用传统的残差方法,其中内部块比输出更窄
6. Experiments


7. Conclusions and future work
我们描述了一个非常简单的网络架构,使我们能够建立一系列高效的移动模型。我们的基本构建单元有几个特性,使其特别适合移动应用程序。它允许非常高效的内存推理,并依赖于所有神经框架中存在的标准操作。
对于ImageNet数据集,我们的架构在广泛的性能点上提高了技术水平。对于目标检测任务,我们的网络在准确率和模型复杂性方面都优于COCO数据集上最先进的实时检测器。值得注意的是,我们的体系结构与SSDLite检测模块相结合,比YOLOv2减少了20倍的计算量和10倍的参数
在理论方面:提出的卷积块具有独特的属性,允许将网络表达性(由扩展层编码)与其容量(由瓶颈输入编码)分开。探索这一点是今后研究的重要方向。