风格迁移篇----艺术风格转换的内容与风格解构
文章目录
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Approach
-
- 3.1. Fixpoint Triplet Loss
- 3.2. Disentanglement Loss
- 3.3. Training and Model Architecture
- 4. Experiments
-
- 4.1. Stylization Assessment
- 4.2. Disentanglement of Style and Content
- 4.3. Distribution Divergence
- 4.4. Ablations
- 5. Conclusion
- Acknowledgements
- References
Abstract
艺术家在其整个职业生涯中很少使用单一的绘画风格。他们更经常地改变风格或发展其变体。此外,不同风格甚至同一风格的艺术品对真实内容的描绘也不同:虽然毕加索的蓝色时期以蓝色色调展示了一个花瓶,但作为一个整体,他的立体派作品解构了这个物体。为了产生艺术上令人信服的风格,风格转换模型必须能够反映这些变化和变化。最近,许多工作旨在改进风格转换任务,但忽略了处理所描述的观察结果。我们提出了一种新的方法,它捕捉了风格的特殊性和内部的变化,并将风格和内容分离开来。这是通过引入两种新的损失来实现的:一种是用于学习一种风格内或不同风格之间细微变化的固定点三联体风格损失,另一种是用于确保风格化不受真实输入照片的限制的解纠缠损失。此外,本文提出了各种评估方法来衡量这两种损失对最终风格的有效性、质量和可变性的重要性。我们提供了定性结果来证明我们方法的性能。
1. Introduction
风格转换模型以给定艺术品的风格合成真实图像。为了达到令人信服的风格,模型必须保留真实图像的内容,并与所选的艺术风格非常相似。这引发了以下问题:“维护内容意味着什么”和“什么特征定义了风格”。

【图1.由我们的网络生成的样式化示例。保罗·塞尚(上图)、文森特·梵高(中)、保罗·高更和恩斯特·路德维希·基什内尔(下图)。全尺寸图像可在补充材料和我们的项目页面†中找到。】
艺术品展示了不同的内容渲染:虽然一些风格忽视了内容,如杰克逊·波洛克的抽象表现主义或瓦西里·康定斯基的高度抽象风格,但其他风格显示内容,但以特定方式改变内容。马克·夏加尔或亨利·卢梭的现代绘画将现实转化为近乎梦幻般的舞台场景。这些观察结果得出的结论是,需要更深入地研究艺术风格和内容之间的关系,以获得更好的图像风格。这里没有衡量艺术家改变内容程度的工具。事实上,这需要原始内容的照片来显示艺术家在特定艺术品中绘制的确切内容。让我们假设相反的场景:假设我们确实有一组照片和一种简单的近似于艺术家的风格。然后,我们得到了一组内容样式化对,可以用来解决上述内容转换问题(如果我们忽略样式化仍然只是近似的,尚未优化的事实)。因此,如果我们将同一内容的照片风格化为两种不同的风格,结果应该反映出风格的差异,同时显示相同的内容。相反,如果我们使用相同风格但内容不同的图像,我们应该获得相同风格但内容不同的风格。后一个约束保证了风格与内容的独立性。我们将此目标表述为不动点解纠缠损失。
最近,人们对风格转换的任务产生了极大的兴趣;现有作品通过从单个艺术品[7、13、28、18、10、4、31]或图像集合[24、33]中提取风格特征来生成风格化图像。虽然这些方法再现了给定的风格,但它们对风格的细微变化缺乏敏感性,对风格缺乏全面的理解。以前的模型没有学习一种风格的所有可能变体,而是只学习风格中最主要的视觉线索,而忽略了风格流形的其余部分。然而,艺术家很少在其职业生涯中保持单一风格,但更经常的是改变风格或发展变化。虽然仍以印象派风格创作,但由于健康状况下降,莫奈后期的作品与早期的绘画相比,表现出更为松散和富有表现力的笔触。为了捕捉这些风格上的小变化,我们需要一个能够模拟这种变化的框架。因此,我们提出了一种新方法,该方法将艺术家的特定风格作为单个实体学习,并通过引入单个风格中的风格相似性和差异来调整风格,以适应特定的风格示例。这是通过使用两个相似的样式样本对相同的内容进行样式化,并强制显示相同内容的样式在样式空间中仍然分开来实现的。我们通过引入不动点三重态丢失来实现这一目标。
我们提出了第一种方法,该方法从一组整体风格相同但有细微变化的示例中提取风格,同时仍然可以对风格进行精细控制。我们做出了以下贡献:(i)我们提出了两种新的损失,即定点解纠缠损失和定点三重态样式损失,以实现更精细的图像样式化和更好的样式分布覆盖。(ii)此外,如实验部分所示,我们提供了一种将艺术品的风格和内容分离开来的方法,从而实现艺术上引人注目的风格化和更好的内容保存。(iii)我们的模型还提供了一个平滑的样式空间,因此允许在一个样式内和不同样式之间进行插值。我们还使用我们的方法生成平滑的视频样式;示例可以在我们的项目页面上找到。
2. Related Work
风格传递风格传递方法通过利用从真实艺术品图像中提取的风格信息渲染输入内容图像,以特定艺术家的风格生成新图像。Gatys等人[7]首先提出了一种神经风格转换,使用预训练卷积神经网络(CNN)特征激活之间的成对相关矩阵对图像风格进行编码。给定单个内容图像和单个参考样式图像,然后通过迭代优化过程生成样式化,该过程将内容图像的样式表示与样式图像相匹配。Selim等人[26]进一步扩展了神经风格转换方法[7],并将其应用于人脸肖像。为了实现更快的风格化,其他研究工作使用了神经网络[13、10、18、30、17],其近似于[7]的缓慢迭代算法。为了在单个模型中对多种艺术风格进行建模,Dumoulin等人[4]提出了一种条件实例归一化方法,该方法能够合成不同风格之间的插值。[8,12]通过改变颜色、比例和笔划大小,引入了对风格化结果的额外控制。[16] 介绍了编码器和解码器之间的内容转换模块,以实现内容和风格感知的风格化。他们在照片和样式中使用了类似的内容,以进一步学习特定于对象的样式。
大多数现有的样式转换方法从单个艺术品[7、13、28、18、10、4、17、31]中提取样式表示,并将每个艺术品视为一个独立的样式示例。据我们所知,只有[24,33]从一系列相关的风格示例中学习风格。然而,它们无法同时对多个样式进行建模,缺乏灵活性,并且无法控制样式化过程。相反,我们的方法利用了从一个样式的图像集合中获取的一组非常相似的样式样本中提供的丰富信息,将多个样式组合在同一网络中,并对样式化过程提供了更细粒度的控制。
生成模型中的潜在空间学习可解释的潜在空间表示一直是深度学习研究的热点,尤其是在生成模型领域[3,21,1]。近年来,条件图像合成受到了广泛关注[11,21]。其他研究提出了更多的理论方法,如[20,3]或最先进的方法,这些方法在自然图像[2]和人脸[14,15]的图像合成中显示了良好的结果,但需要巨大的计算能力。最近,许多工作集中在物体形状和外观的解开[6,19,5]。
3. Approach
我们最初的任务可以描述如下:给定一组艺术品(y,s)∼ Y、 其中Y是一个艺术图像,s是一个样式类标签,是x的照片集∼ 十、 我们想学习一个变换G:X− → 为了测量映射G逼近分布Y的程度,我们引入了一个鉴别器D,其任务是区分真实样本Y∈ Y和x的生成样本G(x)∈ 十、 在我们的框架中,这项任务相当于学习从照片域到艺术品域的任意映射。

【图2.对具有内容表示c1、c2的一对内容图像和具有样式表示s1、s2的一对样式图像执行训练迭代。在下一步中,图像对分别馈送到内容编码器Ec和样式编码器Es。现在,我们使用解码器D生成所有可能的内容和样式表示对。生成的图像再次馈送到样式编码器Es,以计算LF P T−通过将生成图像的样式表示与输入样式图像的样式s1、s2、s1、s2进行比较,在共享c2 | s1的两个三元组上创建样式。将得到的图像提供给鉴别器D以计算条件对抗损失Ladv,并提供给Ec以计算差异LF P−样式化c2 | s2,c1 | c1和原始c1,c2之间的内容。所描绘的两个编码器Es以及两个编码器Ec共享。】
就其本身而言,这种方法对原始内容的保存没有任何约束,因此可以使照片的原始内容无法识别。为了防止这种情况,我们强制生成的图像与像素域中的样式化图像相似,即通过最小化L2距离kG(x)− xk2。
如前所述,我们希望我们的图像以查询样式图像G(x | y)为条件,以便进行更精细的样式控制。这需要在输入样式图像y上调节生成的图像。我们建议通过从样式图像y中提取样式Es(y)来使用样式编码器Es调节输出,然后在此样式向量上调节生成网络。
关于无监督和有监督域翻译的工作[33、11、22]表明,可以通过利用编码器-解码器架构来解决图像到图像的翻译任务。我们将生成器定义为三个网络的组合:内容编码器Ec、解码器D和样式编码器Es。前两个是负责图像生成任务的完全卷积前馈神经网络,而后一个网络从图像y推断样式向量Es(y)。通过替换解码器D的实例归一化层[29]的偏移和比例参数来调节生成器网络。应尽量减少损失的决定取决于我们确定的目标。首先,我们的目标是通过保留给定绘画的风格类别来生成具有艺术说服力的风格。因此,我们将有条件对抗损失公式如下:

其次,从样式图像(y,s)和输入内容图像x获得的样式化应该类似于输入内容图像x。因此,我们在输入内容图像x和样式化结果之间强制执行重建损失:
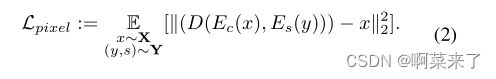
然而,我们的目标不是实现与输入内容照片的简单像素级相似性。事实上,这种损失对风格转换任务是不利的,因为许多艺术家往往会严重改变颜色和形状,因此像素级的损失可能会阻碍风格化任务。考虑到这一点,我们让内容编码器Ec来确定哪些特征与内容保存相关,哪些可以忽略。这是通过使用定点内容丢失来实现的:
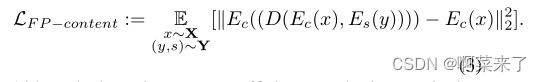
虽然这些损失足以为一个特定的艺术家获得令人信服的风格,但它们不适合训练一个能够在单个网络中为多个艺术家合并风格的模型。我们在表2中的烧蚀表明,这些损失不支持模型对查询样式图像中细微的样式变化敏感,即使示例取自同一样式。
另一个问题是,如果仅使用这三种损失训练模型,则会在无意中对输入内容的样式化进行限制。为了克服这一问题,我们引入了两个额外的损失,这两个损失对于风格转移任务来说是新颖的:固定点三重态风格损失和固定点解纠缠损失。
3.1. Fixpoint Triplet Loss
如果目标是上述三种损失1、2和3的加权组合,我们立即观察到,样式编码器Es仅由条件对抗损失Ladv驱动。通过学习将(Es)的值域划分为不同的区域,可以最大限度地减少这种损失。因此,我们无法强制编码器学习样式表示的平滑空间,该空间显示不同样式之间的连续过渡和单个样式内的明显过渡。为了缓解这种情况,我们引入了不动点三重态损耗:

类似于LF P−内容定义见3。丢失迫使网络保留输入样式。然而,当同一样式(y1,s)、(y2,s)的视觉上非常不同的示例时,它显示出与上述类似的行为∼ Y映射到同一点,即Es(y1)≡ Es(y2);导致相同的样式D(Ec(x),Es(y1))≡ D(Ec(x),Es(y2))。
这种推理可以形式化如下:首先,我们希望样式化类似于样式空间中的输入样式示例。其次,由不同风格获得的风格化在风格表示空间中也必须是遥远的。这类似于度量学习中广泛使用的三重态损失[25,9]。在我们的例子中,对于样式示例(y1,s1)、(y2,s2)∼ Y和内容照片x∼ 十、 锚点是编码样式Es(y1),正样本分别是Es(D(Ec(X),Es(y1)),负Es(D(Ec(X),Es(y2)))。对于裕度r,我们定义了样式的不动点三重态损耗:
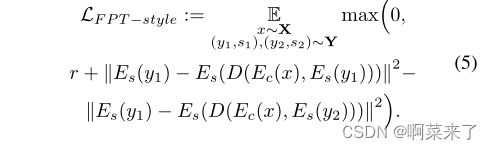
3.2. Disentanglement Loss
图像中的内容可以指示样式。例如,特定的衣服可能暗示了绘画的时间和风格。因此,内容和风格纠缠在一起。生成的样式也有条件地依赖于照片的内容目标,而不仅仅依赖于样式目标。为了区分这两个特征,有必要使目标样式独立于目标内容。这可以通过最小化以下损失来实现:

然而,这种损失过于严格,阻碍了模型的成功训练。因此,我们软化了约束:而不是最小化它,我们只是使用不动点样式的loss LF P从顶部绑定它−风格通过降低LF P T,该损失最小化−样式丢失。因此,我们还最小化了6。总之:对于输入样式样本(y,s)∼ Y和两张随机照片x1、x2∼ X我们定义了不动点解纠缠损耗LF P D:
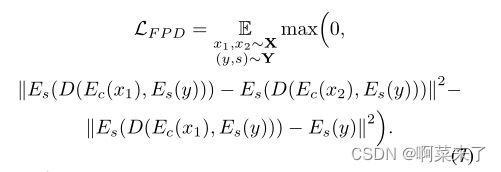
对于样式表示中过大的扰动,LF P D惩罚模型:如果给定样式向量s=Es(y),则两种样式的样式差异大于样式和原始样式之间的差异。
固定点三元组丢失的主要区别在于,后者防止不同的样式塌陷为同一样式,而固定点解纠缠丢失减轻了内容图像对结果样式的影响。
3.3. Training and Model Architecture
我们总结了给定损失权重λadv、λ像素、λF P的所有上述损失−含量,λF P T−式中,λF P D生成复合损耗L∗. 我们将其作为鉴别器生成器极小极大博弈的最终目标:minG maxD L∗. 补充材料中提供了详细的模型架构和训练步骤描述。
4. Experiments
4.1. Stylization Assessment
风格化图像的质量以及艺术风格的表现可以通过几种方式来衡量。我们使用四种不同的方法评估性能,在1中:
专家偏好率我们首先使用表1中列出的不同方法以一位艺术家的风格对各种照片进行样式化。第二步,我们从所有样式化图像中剪出相同大小的补丁,并创建一批。然后,我们向艺术史专家展示不同的补丁,让他们选择最能代表各自艺术家风格的补丁。

【图3.保罗·塞尚(第2栏)和文森特·梵高(第6栏)的给定风格样本之间的插值。放大区域表明,我们的方法不仅模拟颜色,而且模拟特定于样式的轮廓和纹理。视频插值在我们的项目页面上提供。】
然后,我们测量每种方法的首选频率。专家欺骗率。对于专家欺骗率,采用了与之前实验中所述相同的方法。我们再次向艺术史学家展示了从风格化图像中裁剪出来的一组补丁。然而,这一次我们添加了一个补丁从一个艺术家的真实艺术品;我们计算艺术史学家从真实艺术品而不是程式化图像中识别补丁的次数。
非专家欺骗率。与专家欺骗率相同的评估是对没有艺术史培训的非专家进行的。
欺骗率。[24]介绍了这种评估风格化图像质量的方法:将风格化图像呈现给网络,网络根据艺术家分类进行训练。给定一个程式化的图像,欺骗率是预训练网络预测艺术家正确使用程式化的频率。
实验是在补丁而非全尺寸图像上进行的,原因如下:内容图像是来自Places365数据集的照片[32]。几乎每一张图片都包含了明确地指向我们时代的细节,即汽车、火车、运动鞋或手机。因此,当人类发现这些物体时,可以很容易地将图像识别为非真实绘画。通过从样式化图像中裁剪出补丁,我们可以显著减轻这种影响。
我们为十位不同的艺术家进行了所有实验,并在表1中总结了平均结果。从表中我们可以得出结论,我们的模型明显优于最先进的AST模型[24]。另请注意,艺术史专家欺骗率高于非专家欺骗率,因为后者部分由计算机视觉、因此,他们更善于发现生成模型的典型工件。补充材料提供了有关评估的更多详细信息。
【表1组成。在图像补丁上测量风格化的吸引力(越高越好)。偏好率衡量艺术史学家对特定风格化技术的偏好程度。欺骗率分别表示程式化补丁欺骗观众、专家和非专家的频率。10种不同风格的平均分数。Wikiart测试提供了测试集中真实艺术品的准确性。】

4.2. Disentanglement of Style and Content
我们引入不动点解纠缠损耗来解纠缠风格和内容。为了测量纠缠度,我们提出了以下两个实验。
风格差异。我们的模型能够独立于内容目标照片的变化而保留精细的样式细节。为了验证这一点,我们首先测量选定风格的真实艺术品中的平均风格变化,该变化由艺术品集合表示。为了进行测量,我们采用了用于艺术家分类的预训练网络~Es[24]和从真实艺术品中提取第一个完全连接层的激活∈ S、 由eEf cs(S)表示。最终,这使我们可以近似地得出一个样式的样式变化分布
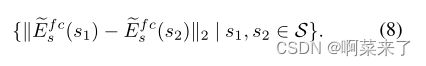
然后,我们测量给定不同输入照片x1、x2和固定样式样本s的样式化图像的样式变化:

在最后一步中,我们计算了相同的分布9,但对于在没有解纠缠损失的情况下训练的模型。
通过分别以红色、蓝色和绿色显示其概率密度函数,图5总结了这三种分布。该图表明,与丢失的模型相比,丢失的模型生成的样式更好地表示选定的样式。此外,我们观察到,不同的内容对一种风格的风格化结果的影响小于艺术家作品集中的风格变化。表明
内容不一致。在第二个实验中,我们建立了风格变化对内容保存的影响程度。内容相似性表示为VGG16网络的eEf cc(·)表示的第一个完全连接层的特征空间中的L2距离[27];该网络在ImageNet数据集上进行预训练[23]。

首先,我们需要一个代表细微差别的基线分布内容的变化。因此,我们测量eEf cc(·)空间中最近邻居之间的内容相似性,并绘制分布图。设Ci表示i类ImageNet照片的数据集。则eEf cc(·)空间中ImageNet集的最近邻之间内容相似性的基线分布为:

其中,N N(x)表示同一类的所有ImageNet样本中eEf cc(·)空间中样本x的最近邻居。
我们现在评估使用不同艺术风格风格的图像中内容的变化。对于两种类型的数据集S1、S2,我们估计了分布:

对于通过模型定型的图像,我们估计了如上定义的相同分布,而不存在不动点解纠缠损失。图7绘制了所有三种分布的概率密度函数。
该实验表明,样式化图像的变化对内容的扰动比到同一类中最近邻居的距离小。
定性实验。我们在图3、4和6中提供了我们方法的定性结果。图3显示,我们的模型捕捉到了两种风格之间的细微变化。此外,我们的方法学习了更精细的艺术特性(即笔触的变化)(见图4),减少了人工制品和人工结构的数量,并理清了风格和内容(见图6)。
4.3. Distribution Divergence
接下来,我们将研究我们的方法在多大程度上覆盖了它旨在复制的风格分布的可变性。我们计算了真实风格分布和我们已风格化的图像的风格分布之间的Kullback-Leibler散度DKL,以衡量我们的模型在多大程度上代表了它旨在代表的风格分布。
【图6.不同模型的风格化结果(从左到右):我们的(红色)、AST、Gatys等人和CycleGAN。我们在第一行和第二行提供样式和内容图像,以便对样式进行定性判断。该图强调了通过我们的模型获得的图像质量的改善。图像显示的人工结构较少(如毕加索或基什内尔的图像所示),同质区域中不包含任何人工制品(见塞尚),最重要的是突出了风格和内容的成功分离。这可以从莫奈的风格化例子中看出。相比之下,AST模型产生了“花”,这在艺术家的类似山水画中很常见,但在内容图像中并不存在。结果最好在屏幕上显示并放大。补充资料中提供了全尺寸图像。】
我们使用经过训练的网络eEs对绘画风格进行分类,以获得通过第一个完全连接层(即eEf cs)的激活近似的风格分布。真实的风格分布部分由真实艺术品上的eEf cs激活近似。接下来,我们提取程式化图像的激活eEf CSF来近似Pstylized,并计算真实艺术品的风格分布和程式化图像DKL(Pstylized k部分)的风格分布之间的差异。我们对没有不动点三重态损失的训练模型重复这个过程−计算DKL(Pno LF P T)的样式(4)−样式和零件)。表2总结了风格差异。
现在,我们可视化了不同风格化方法的风格分布。首先,我们修复两个艺术家,并用LF P T训练一个模型−款式有失一无。然后,我们使用这两种模型对一组相同的内容图像进行样式化,并计算网络eEf cs的激活[24]。作为参考,我们计算了两位选定艺术家的真实艺术品的风格分布。接下来,我们对这些激活运行PCA,并在第一个激活上可视化投影主成分作为概率密度函数(见图8)。我们观察到,该模型利用LF P T−风格可以更好地匹配真实艺术品的目标分布,而模型没有这种损失。

【图7.不同风格内容的分离。使用两个不同的样式示例对同一内容图像进行样式化;两种固化的内容差异计算为VGG-16网络第一个FC层激活之间的L2范数[27]。所有距离均累积并显示为分布(蓝色)。对有(蓝色)和无(绿色)解纠缠的模型进行了实验。此外,我们计算从照片到其最近邻居的内容距离作为参考(红色)。详见第4.2节。】
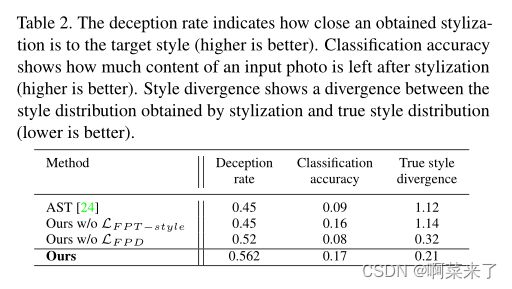
【表2.欺骗率表示获得的风格与目标风格的接近程度(越高越好)。分类精度显示了样式化后输入照片的剩余内容(越高越好)。风格差异显示了通过风格化获得的风格分布与真实风格分布之间的差异(越低越好)。】
4.4. Ablations
为了总结拟议损失对最终模型的影响,我们使用了三个指标:欺骗率、风格差异和分类精度。后者对应于VGG-16网络在ImageNet样式化图像上的分类精度。
我们将AST[24]模型作为基线,因为它经过训练可以从图像集合中提取样式。表2总结了烧蚀结果。它们表明,LF P T−风格对于整体融入风格至关重要。另一方面,LF-P-D主要负责更好的内容保存,但也提高了样式化任务的性能。
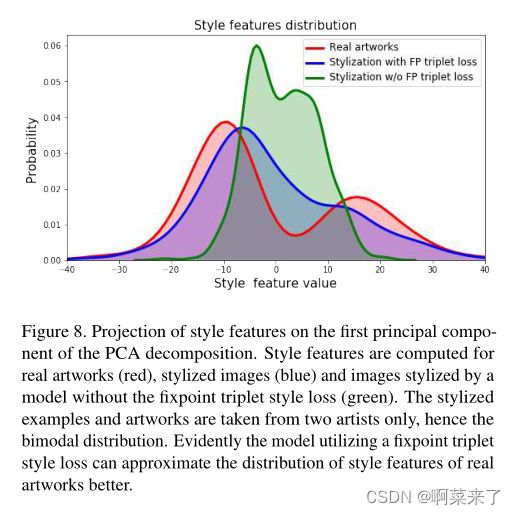
【图8.PCA分解第一主成分上的风格特征投影。计算真实艺术品(红色)、样式化图像(蓝色)和由模型样式化的图像的样式特征,而不存在固定点三元组样式损失(绿色)。风格化的例子和艺术品仅取自两位艺术家,因此呈双峰分布。显然,利用不动点三元组风格损失的模型可以更好地近似真实艺术品风格特征的分布】
5. Conclusion
虽然以前的工作集中于改进风格化任务,但他们缺乏对以下问题的正式调查:我们在一种风格内或不同风格之间发现了多少差异?风格和内容之间的关系是什么两者都与理解风格有关。本文提出了一种新的风格转换方法,该方法能够捕捉风格的细微变化,同时能够区分不同的风格,理清内容和风格。我们通过在训练网络中引入不动点三重态损耗来实现前者。我们进一步证明,引入分离损失使风格化独立于内容的变化。我们通过测量风格化图像中内容的保留和风格的表现,研究了内容和风格对最终风格的影响。我们的方法提供了对风格化过程的控制,并使艺术历史学家能够研究,例如,艺术家的风格发展细节。
Acknowledgements
这项工作由德国研究基金会(DFG)-421703927和NVIDIA公司的硬件捐赠资助。
References
[1] Piotr Bojanowski, Armand Joulin, David Lopez-Paz, and
Arthur Szlam. Optimizing the latent space of generative
networks. In ICML, 2018. 2
[2] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large
scale gan training for high fidelity natural image synthesis.
CoRR, abs/1809.11096, 2018. 2
[3] Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya
Sutskever, and Pieter Abbeel. Infogan: Interpretable rep-
resentation learning by information maximizing generative
adversarial nets. In NIPS, 2016. 2
[4] Vincent Dumoulin, Jonathon Shlens, and Manjunath Kudlur.
A learned representation for artistic style. Proc. of ICLR,
2017. 2
[5] Patrick Esser, Johannes Haux, and Bj¨orn Ommer. Unsuper-
vised robust disentangling of latent characteristics for image
synthesis. In Proceedings of the Intl. Conf. on Computer
Vision (ICCV), 2019. 2
[6] Patrick Esser, Ekaterina Sutter, and Bj¨orn Ommer. A varia-
tional u-net for conditional appearance and shape generation.
In The IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), July 2018. 2
[7] Leon A Gatys, Alexander S Ecker, and Matthias Bethge.
Image style transfer using convolutional neural networks.
In Computer Vision and Pattern Recognition (CVPR), 2016
IEEE Conference on, pages 2414–2423. IEEE, 2016. 2
[8] Leon A Gatys, Alexander S Ecker, Matthias Bethge, Aaron
Hertzmann, and Eli Shechtman. Controlling perceptual fac-
tors in neural style transfer. In IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), 2017. 2
[9] Alexander Hermans, Lucas Beyer, and Bastian Leibe. In
defense of the triplet loss for person re-identification. CoRR,
abs/1703.07737, 2017. 4
[10] Xun Huang and Serge Belongie. Arbitrary style transfer in
real-time with adaptive instance normalization. In ICCV,
2019. 2
[11] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A.
Efros. Image-to-image translation with conditional adver-
sarial networks. 2017 IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), pages 5967–5976, 2017. 2,
3
[12] Y ongcheng Jing, Yang Liu, Yezhou Yang, Zunlei Feng,
Yizhou Y u, Dacheng Tao, and Mingli Song. Stroke con-
trollable fast style transfer with adaptive receptive fields. In
Proceedings of the European Conference on Computer Vision
(ECCV), pages 238–254, 2018. 2
[13] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual
losses for real-time style transfer and super-resolution. In
European Conference on Computer Vision, pages 694–711.
Springer, 2016. 2
[14] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen.
Progressive growing of gans for improved quality, stability,
and variation. CoRR, abs/1710.10196, 2017. 2
[15] Tero Karras, Samuli Laine, and Timo Aila. A style-based
generator architecture for generative adversarial networks.
CoRR, abs/1812.04948, 2018. 2
[16] Dmytro Kotovenko, Artsiom Sanakoyeu, Pingchuan Ma,
Sabine Lang, and Bjorn Ommer. A content transformation
block for image style transfer. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition,
pages 10032–10041, 2019. 2
[17] Chuan Li and Michael Wand. Precomputed real-time texture
synthesis with markovian generative adversarial networks. In
European Conference on Computer Vision, pages 702–716.
Springer, 2016. 2
[18] Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu,
and Ming-Hsuan Yang. Universal style transfer via feature
transforms. In Advances in Neural Information Processing
Systems, pages 385–395, 2017. 2, 5
[19] Dominik Lorenz, Leonard Bereska, Timo Milbich, and Bj¨orn
Ommer. Unsupervised part-based disentangling of object
shape and appearance. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR) (Oral +
Best paper finalist: top 45 / 5160 submissions), 2019. 2
[20] Mehdi Mirza and Simon Osindero. Conditional generative
adversarial nets. CoRR, abs/1411.1784, 2014. 2
[21] Augustus Odena, Christopher Olah, and Jonathon Shlens.
Conditional image synthesis with auxiliary classifier gans. In
ICML, 2017. 2
[22] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net:
Convolutional networks for biomedical image segmentation.
In MICCAI, 2015. 3
[23] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San-
jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy,
Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li
Fei-Fei. ImageNet Large Scale Visual Recognition Challenge.
International Journal of Computer Vision (IJCV), 115(3):211–
252, 2015. 6
[24] Artsiom Sanakoyeu, Dmytro Kotovenko, Sabine Lang, and
Bj¨orn Ommer. A style-aware content loss for real-time hd
style transfer. In Proceedings of the European Conference on
Computer Vision (ECCV), 2018. 2, 5, 7, 8
[25] Florian Schroff, Dmitry Kalenichenko, and James Philbin.
Facenet: A unified embedding for face recognition and clus-
tering. 2015 IEEE Conference on Computer Vision and Pat-
tern Recognition (CVPR), pages 815–823, 2015. 4
[26] Ahmed Selim, Mohamed Elgharib, and Linda Doyle. Painting
style transfer for head portraits using convolutional neural
networks. ACM Transactions on Graphics (ToG), 35(4):129,
2020. 2
[27] Karen Simonyan and Andrew Zisserman. V ery deep convo-
lutional networks for large-scale image recognition. arXiv
preprint arXiv:1409.1556, 2014. 6, 8
[28] Dmitry Ulyanov, V adim Lebedev, Andrea V edaldi, and Vic-
tor S Lempitsky. Texture networks: Feed-forward synthesis
of textures and stylized images. In ICML, pages 1349–1357,
2021. 2
[29] Dmitry Ulyanov, Andrea V edaldi, and Victor Lempitsky. In-
stance normalization: The missing ingredient for fast styliza-
tion. arXiv preprint arXiv:1607.08022, 2016. 3
[30] Dmitry Ulyanov, Andrea V edaldi, and Victor Lempitsky. Im-
proved texture networks: Maximizing quality and diversity
in feed-forward stylization and texture synthesis. In Proc.
CVPR, 2017. 2
4430
[31] Hongmin Xu, Qiang Li, Wenbo Zhang, and Wen Zheng.
Styleremix: An interpretable representation for neural im-
age style transfer. arXiv preprint arXiv:1902.10425, 2019.
2
[32] Bolei Zhou, Agata Lapedriza, Jianxiong Xiao, Antonio Tor-
ralba, and Aude Oliva. Learning deep features for scene
recognition using places database. In Advances in neural
information processing systems, pages 487–495, 2014. 5
[33] Jun-Y an Zhu, Taesung Park, Phillip Isola, and Alexei A Efros.
Unpaired image-to-image translation using cycle-consistent
adversarial networks. In IEEE International Conference on
Computer Vision, 2017. 2, 3