深入浅出RPC:选取适合自己的RPC
文章目录
- 1、RPC概念&&背景
-
- 1.1、RPC背景
- 1.2、RPC是什么,什么时候需要用到?
- 2、进程间的通信 - IPC与RPC
-
- 2.1、什么是IPC
- 2.2、IPC与RPC联系
- 3、RPC的实现
-
- 3.1、RPC实现的基本思路
- 3.2、RPC实现的扩展方向
- 4、RPC的选择
1、RPC概念&&背景
1.1、RPC背景
RPC远程调用的概念最早可以追溯到20世纪80年代,当时Sun Microsystems公司提出了一种名为ONC RPC(Open Network Computing Remote Procedure Call)的协议,用于在NFS(Network File System)中进行远程过程调用。此后,RPC成为了分布式系统中的一种重要通信方式,被广泛应用于各种分布式系统和应用中。
可以看出RPC这个概念已经超过四十年时间,但在今天仍然可以在各种论坛、技术网站上时常遇见“什么是 RPC?”、“如何评价某某 RPC 技术?”、“RPC 更好还是 REST 更好?”之类的问题,仍然“每天”都有新的不同形状的 RPC 轮子被发明制造出来。而对于快速发展的互联网技术,这无异是稀奇的。而这主要的原因主要还是很多论坛上的开发这对于RPC 本身解决什么问题、怎么解决这些问题、为什么要这样解决都或多或少存在认知模糊,接下来本文会一一介绍。
1.2、RPC是什么,什么时候需要用到?
RPC(Remote Procedure Call)是一种远程过程调用协议,它允许一个程序调用另一个程序中的函数或方法,而无需了解底层的网络细节。因此RPC的出现使得分布式系统中的各个组件之间的通信变得更加简单、高效和可靠。
并且RPC协议提供了更加丰富和灵活的功能,例如支持不同的序列化格式、支持异步调用、支持自定义的错误处理等等(如:gRPC、Apache Thrift、CORBA…等),而平常普通的http请求等就很难实现。因此在为了需要自定义上述的的功能,亦或者在分布式系统中需要进行组件的通信时,就需要rpc。(但是这里RPC底层的传输协议其实是可以用HTTP协议的,这种方式被称为HTTP-RPC或者HTTP-based RPC。在这种方式中,HTTP协议被用来传输RPC请求和响应数据。)
上述提到HTTP协议,其实也可以扩展一下,对于分布式中的通信除了常见RPC协议,能够更快的提高数据传输效率,对于常见的HTTP协议来说也有对应的架构,这种架构则是我们常说的restful。
rest(Representational State Transfer)是一种基于HTTP协议的架构风格,用于设计和构建分布式系统。它强调系统中的资源和状态的概念,并使用HTTP动词(GET、POST、PUT、DELETE等)对资源进行操作,并使用URI(Uniform Resource Identifier)标识资源的位置。它相对于RPC的特点更多为:
- 基于HTTP协议: 使用HTTP协议进行通信,HTTP动词表示对资源的操作,URI表示资源的位置。
- 资源和状态: 将系统中的所有内容抽象为资源,每个资源都有一个URI标识和一个状态。
- 无状态: 每个请求都是独立的,不需要保存上下文信息。
- 可缓存: 支持缓存机制,提高性能和可扩展性。
因此rest的侧重点更多是灵活、易扩展、易缓存的场景。更多想了解的可以去看看凤凰架构中有对此更深的描述。
因此,在实现分布式系统中的通信时,想要提高网络传输效率使用专门的RPC协议会更加合适和可靠。但是而RPC具体是怎么能支持这些功能,还得从RPC的实现谈起。
2、进程间的通信 - IPC与RPC
在介绍RPC实现之前先来介绍下IPC,因为RPC在实现思想和背景上很多来自于IPC。
2.1、什么是IPC
IPC是一种在同一台计算机上的进程间通信方式,常见的IPC技术包括管道、消息队列、共享内存、信号量、套接字接口(Socket)等。IPC的主要作用是实现进程间数据的传输和共享,使得不同进程之间可以进行协调和互操作。
2.2、IPC与RPC联系
就如同开始强调的一样,rpc最初的目标只是为了让计算机能够跟调用本地方法一样去调用远程方法!! 在分布式系统中,不同组件之间可能需要进行本地进程间通信和远程过程调用,**这时就可以同时使用IPC和RPC来实现。**例如,在分布式系统中,一个组件可能需要调用另一个组件的本地函数或方法,这时可以使用IPC来实现本地进程间通信。而当两个组件位于不同的节点上时,就可以使用RPC来实现远程过程调用。此外,RPC的实现方式通常是基于网络协议和框架,而网络协议和框架中也使用了IPC的技术。例如,在TCP/IP协议中,就使用了IPC中的套接字(socket)技术来实现进程间通信。
这边要注意一个点在早先由于 Socket 是各个操作系统都有提供的标准接口,完全有可能把远程方法调用的通信细节隐藏在操作系统底层,从应用层面上看来可以做到远程调用与本地的进程间通信在编码上完全一致。但这这种透明的调用方法,容易造成滥用,而造成通信是无成本的假象,而导致了分布式系统下性能的下降。当然现在回来看通信是无成本的假象肯定是错的,毕竟分布式系统架构应是容错,一致性,高性能的trade off,而通信代价本就是性能中的一环。而在当时RPC这种观却是很盛行,对此Andrew Tanenbaum 教授曾发表了论文《A Critique of The Remote Procedure Call Paradigm》进行质疑,以及最终CM 和 Sun 院士Peter Deutsch、套接字接口发明者Bill Joy、Java 之父James Gosling等一众在 Sun Microsystems 工作的大佬们共同总结了现在分布式系统很著名的:通过网络进行分布式运算的八宗罪(8 Fallacies of Distributed Computing),有兴趣的可以去了解。
3、RPC的实现
3.1、RPC实现的基本思路
由上文可以知晓RPC的实现一开始是为了像本地方法那样调用远程方法,但是实际上远程调用中的 “远程” 的概念注定会有很多实现上的分歧,这也是本文的第二个内容,如何解决这些问题。
首先远程调用的大致链路其实都是大同小异的,大概如下图(图源来自论文Implementing Remote Procedure Calls):
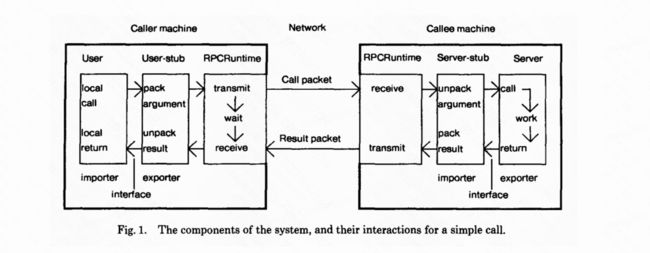
由图可以分解出以下几个步骤:
- 定义接口和数据类型: 首先需要定义接口和数据类型,包括接口方法名、参数类型、返回值类型等。这些定义通常使用IDL(Interface Definition Language)语言来描述,以便于不同语言之间的调用和序列化。
- 生成代码: 根据接口和数据类型的定义,生成客户端和服务器端的代码。这些代码通常包括序列化和反序列化方法、网络传输方法等,以便于客户端和服务器端进行数据交换和通信。
- 实现服务器端(被调用方): 在服务器端实现接口方法,根据客户端请求进行相应的处理,并将处理结果返回给客户端。服务器端还需要实现服务注册和发现、负载均衡、容错等机制,以提高系统的可用性和可靠性。
- 实现客户端(调用方): 在客户端调用远程接口方法,将参数序列化并通过网络发送给服务器端,然后等待服务器端返回处理结果,并将结果反序列化后返回给调用方。客户端还需要实现服务发现和选择、负载均衡、重试等机制,以提高系统的可用性和可靠性。
- 集成框架: 将生成的代码和实现的服务器端、客户端集成到RPC框架中,并提供相应的API和工具,以便于开发人员使用和集成。
- 测试和优化: 对实现的RPC框架进行测试和优化,包括性能测试、功能测试、安全测试等,以确保系统的稳定性、可靠性和安全性。
3.2、RPC实现的扩展方向
除了上面几个基本步骤,不同的RPC通常会在下列三个方向,去进行自己扩展。
- 如何表示数据 - 数据的序列化与反序列化的实现
- 如何传递数据- 确定数据传输时所采用的格式与规则( Wire Protocol )
- 如何统一方法调用- 确定请求端/接受端方法调用的方式
3.2.1 如何表示数据
对于如何表示数据的做法是将交互双方所涉及的数据转换为某种事先约定好的中立数据流格式来进行传输,将数据流转换回不同语言中对应的数据类型来进行使用,而这就是序列化协议的初衷,除此之外设计一个好的序列化协议还有以下几个作用:
- 跨语言和跨平台: 在分布式系统中,不同计算机可能使用不同的编程语言和操作系统,因此需要一种通用的数据格式,以便于跨语言和跨平台进行数据传输和交互。序列化协议可以将数据转换为一种通用的格式,使得不同计算机之间可以正确地对数据进行编码和解码。
- 数据压缩: 在网络传输过程中,数据的大小会影响网络带宽和传输速度,因此需要对数据进行压缩。序列化协议可以将数据压缩为更小的二进制格式,从而减少网络传输的数据量,提高网络传输效率。
- 数据安全: 在网络传输过程中,数据可能会被篡改或窃取,因此需要对数据进行加密和解密。序列化协议可以将数据转换为二进制格式,并进行加密和解密操作,从而保证数据的安全性和完整性。
数据可读性:在调试和排错过程中,需要查看网络传输的数据内容,以便于定位问题。序列化协议可以将数据转换为文本格式,使得数据更易于读取和理解。
也因此每种RPC都有其对应使用的序列化协议:
- ONC RPC : External Data Representation (XDR)
- gRPC: 使用Protocol Buffers作为默认的序列化协议,也支持JSON。
- Java RMI : Java Remote Message Protocol(JRMP,也支持RMI-IIOP)
- Web Service : XML Serialization
- CORBA: 支持多种序列化协议,包括GIOP(General Inter-ORB Protocol)、IIOP(Internet Inter-ORB Protocol)、RMI-IIOP和TAO。
- Apache Thrift: 支持多种序列化协议,包括二进制、压缩二进制、JSON、可扩展二进制和结构化数据格式(TJSON、TSV)。
3.2.2 如何传递数据
数据的传输并不是简单的约定好数据格式进行序列化反序列化就行,还需要考虑数据传输时需要的额外的信息譬如异常、超时、安全、认证、授权、事务,等等,都可能产生双方需要交换信息的需求,对这一类的行为则被称作Wire Protocol。而常见的Wire Protocol协议主要有:
- 两端都是http endpoint可以直接HTTP
- Java RMI 的Java Remote Message Protocol(JRMP,也支持RMI-IIOP)
- CORBA 的Internet Inter ORB Protocol(IIOP,是 GIOP 协议在 IP 协议上的实现版本)
- DDS 的Real Time Publish Subscribe Protocol(RTPS)
- Web Service 的Simple Object Access Protocol(SOAP)
- Wire Protoco通常是指应用层协议和传输层协议之间的协议。在OSI模型中,Wire Protocol可以被看作是第5层(会话层)和第6层(表示层)之间的协议。在TCP/IP协议栈中,Wire Protocol通常被认为是传输层协议和应用层协议之间的协议,例如HTTP、SMTP等应用层协议使用TCP或UDP作为传输层协议进行数据传输。
- 而上面提到的序列化反序列化序列化和反序列化通常是在应用层协议中实现的,因为它们是将高级语言对象转换为字节流的过程,这些对象通常在应用程序中定义和使用。例如,在Java中,序列化和反序列化通常使用Java对象序列化(Java Object Serialization)API来实现。
3.2.3 如何统一方法调用
-
在本地方法调用中方法调用并不是太大的问题,编译器或者解释器会根据语言规范,将调用的方法签名转换为进程空间中子过程入口位置的指针,但是远程调用可能则要考虑不同的语言,则在实现上需要考虑不同语言之间方法签名的差异。由于不同语言的方法调用方式和参数传递方式可能不同,因此在RPC中需要使用一种通用的方法来描述方法签名和参数列表,以便在客户端和服务器之间进行方法调用。
-
通常情况下,RPC实现会使用一种IDL(Interface Description Language,接口定义语言)来描述方法签名和参数列表,以便在客户端和服务器之间进行交互。IDL通常使用一种中立的语言来描述接口,例如CORBA中使用的IDL语言。在IDL中,可以定义接口、方法、参数类型、返回类型等信息,以便在不同语言之间进行交互。
-
在实际的RPC实现中,通常会使用代码生成工具来根据IDL文件自动生成客户端和服务器端的代码。这些生成的代码包含了方法调用的代码,以及将参数和返回值进行序列化和反序列化的代码,以便在不同语言之间进行方法调用。这样可以大大简化RPC实现的过程,同时也可以保证不同语言之间的方法调用是正确的。
值得一提的是IDL的实现有点类似寻找一个分布式id一样。如确定方法直接规定一个唯一的、在任何机器上都不重复的编号,调用的时候则不管这个方法签名是如何定义的,直接通过编号确定方法。而这个唯一但绝不重复的编码方案,这就是后来的UUID。
其他用于表示方法的协议还有:
- Android 的Android Interface Definition Language(AIDL)
- CORBA 的OMG Interface Definition Language(OMG IDL)
- Web Service 的Web Service Description Language(WSDL)
- JSON-RPC 的JSON Web Service Protocol(JSON-WSP)
因此其实RPC的很多实现思路都是可以从IPC上得到借鉴或启发,但是rpc随着发展早已不满足于简单的进行通信,早已还需要考量性能、通用等方面。
4、RPC的选择
经过的几十年的时间,rpc的发展并不是趋向一个统一的未来,因为随着多样化的需求、不断的技术发展和创建、以及需要跨语言和跨平台支持甚至包括生态的推动。现在的rpc已经成为一个百家争鸣之势如 RMI(Sun/Oracle)、Thrift(Facebook/Apache)、Dubbo(阿里巴巴/Apache)、gRPC(Google)、Motan1/2(新浪)、Finagle(Twitter)、brpc(百度/Apache)、.NET Remoting(微软)、Arvo(Hadoop)、JSON-RPC 2.0(公开规范,JSON-RPC 工作组)等等。
接下来会简单根据不同的场景建议选择不同的rpc框架并介绍其优缺点:
- gRPC:
- 优点: 高性能、低延迟、跨语言支持、多种通信协议、流式传输支持。
- 适用场景: 大规模分布式系统、跨语言通信、需要高性能和低延迟的实时通信场景。
- Dubbo:
- 优点: 丰富的服务治理功能、高度可扩展、支持大规模分布式系统、灵活的扩展机制。
- 适用场景: Java应用程序的分布式服务、需要服务治理功能的场景。
- Apache Thrift:
- 优点: 跨语言支持、多种序列化方式、代码生成工具、高效的数据传输。
- 适用场景: 跨语言通信、大数据分析、需要高效数据传输的场景。
- ZeroMQ:
- 优点: 轻量级、快速、异步消息传递、支持多种通信模式。
- 适用场景: 轻量级通信、需要快速和高效的消息传递的场景。
- MQTT:
- 优点: 轻量级、低功耗、支持发布-订阅模式。
- 适用场景: 物联网应用、需要低功耗和轻量级通信的场景。
- WebRTC:
- 优点: 支持实时音视频通信、低延迟、Web浏览器原生支持。
- 适用场景: 实时音视频通信、Web端的实时通信IM场景。
而大家平时搭建业务则一般就可以通过业务上所需要的通信特点进行去选择,例如如果是im场景下 WebRTC去提高通讯效率,如果是大型电商那种分布式系统的话可以使用gRPC,java则使用Dubbo,如果是搭建数据中心考虑跨语言则去选择Apache Thrift,当然如果最简单平常的也可以直接利用Springcloud中的Spring Cloud Netflix项目实现的多种组件,如Ribbon、Feign、Hystrix等,用于构建分布式系统中的服务通信和治理。
而想具体区分优缺点的则是可以从上面实现提到的序列化协议、传输协议实现入手:
-
gRPC:
传输协议: 默认使用HTTP/2作为底层传输协议,HTTP/2支持多路复用、头部压缩和服务器推送等特性,可以提高性能和效率。
序列化协议:默认使用Protocol Buffers(protobuf)作为序列化协议,protobuf是一种高效、紧凑的二进制序列化协议,适合高性能通信。 -
Dubbo:
传输协议: Dubbo支持多种传输协议,包括dubbo、rmi、http、hessian、webservice等,可以根据需求选择合适的协议。
序列化协议: Dubbo同样支持多种序列化协议,如hessian、json、protobuf等,可以根据需求选择合适的协议。 -
Apache Thrift:
传输协议: Thrift支持多种传输协议,包括二进制、压缩、JSON、XML等,可以根据需求选择合适的协议。
序列化协议: Thrift支持多种序列化协议,包括二进制、JSON、compact等,可以根据需求选择合适的协议。 -
ZeroMQ:
传输协议: ZeroMQ是一种异步通信库,支持多种传输协议,如TCP、IPC、inproc等,可以根据需求选择合适的协议。
序列化协议: ZeroMQ并不关心消息的格式和内容,用户可以自行定义消息的序列化方式。 -
WebRTC:
传输协议: WebRTC是一种用于实时通信的开放式技术,通常使用UDP作为底层传输协议,可以实现较低的延迟和更好的实时性。
序列化协议: WebRTC通常使用JSON或二进制格式来序列化和传输数据。
而这些使用的协议则会决定其底层存在的风险,并且在选择时也可以适当考虑是否社区还在维护,更新,生态是否完善等…
以下提供几个常见的rpc的地址:
- grpc中文文档:https://doc.oschina.net/grpc
- grpc官方文档:https://grpc.io/docs/
- dubbo官方文档:https://cn.dubbo.apache.org/zh-cn/overview/home/
- Apache Thrift官方文档:https://thrift.apache.org/
- WebRTC官方文档:https://webrtc.org/?hl=zh-cn
如有不足,欢迎指正~