LIMoE:使用MoE学习多个模态
文章链接:Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts
发表期刊(会议): NeurIPS 2022
目录
- 1.背景介绍
-
- 稀疏模型
- 2.内容摘要
-
- Sparse Mixture-of-Experts Models
- Contrastive Learning
- Experiment Analysis
- 3.文章总结
1.背景介绍
在实际应用中,多模态数据通常是高维度的,处理这样的数据可能会导致计算和存储开销巨大。稀疏模型可以帮助缓解这种问题,因为它们具有较少的参数,可以有效地处理高维数据。因此,将稀疏性考虑到多模态学习中,可以在减少计算和存储成本的同时,提高模型的性能和效率。
一些研究工作和实际应用尝试将多模态数据与稀疏模型相结合,以更好地处理来自不同传感器或数据源的信息。这种结合可能涉及将多模态数据转换为稀疏表示形式,或者在多模态模型的构建中引入稀疏性,以提高处理效率和性能。这种融合可以帮助解决处理大规模多模态数据时的挑战,并提供更高效的解决方案。稀疏模型可以作为处理多模态数据的一种方式,以降低计算和存储开销,并提高模型的效率和性能。在多模态学习的背景下,引入稀疏性可以是处理复杂数据的有效策略之一。
同时(多任务)或顺序(持续学习)学习许多不同任务的密集模型(dense model)通常会受到负面干扰:过多的任务多样性意味着最好为每个任务训练一个模型,灾难性遗忘意味着模型在早期任务中会随着新任务的添加而变得更差。
稀疏模型
稀疏模型(Sparse models)在深度学习未来最有前途的方法中脱颖而出。 采用条件计算的 Sparse models 不是模型的每个部分都处理每个输入(“dense” modeling),而是学习将各个输入 “route” 到潜在庞大网络中的不同 “experts” 。这有很多好处。
- 模型大小可以增加,同时保持计算成本不变。这是一种有效且更环保的模型缩放方式,也是高性能的关键。
- 稀疏性也自然地划分了神经网络。 稀疏模型有助于避免这两种现象通过不将整个模型应用于所有输入,模型中的“专家”可以专注于不同的任务或数据类型,同时仍然利用模型的共享部分。
Google Reaserch团队长期以来一直致力于稀疏性的研究。 今天的人工智能模型通常只接受训练做一件事。 Pathways 将使人们能够训练单个模型来完成数千或数百万件事情。Pathways 总结了构建一个大型模型的研究愿景,该模型可以勤奋地处理数千个任务和众多数据模式。
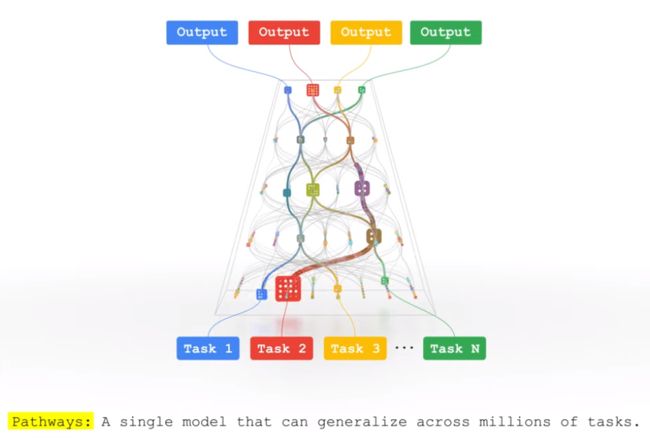
到目前为止,语言(Switch、Task-MoE、GLaM)和计算机视觉(Vision MoE)的稀疏单峰模型已经取得了相当大的进展。目前,谷歌团队通过研究大型稀疏模型,通过与模态无关的 “Router” 同时处理图像和文本,朝着 Pathways 愿景迈出了重要一步。 他们提出了多模态对比学习,它需要对图像和文本都有深入的理解,以便将图片与其正确的文本描述对齐。 迄今为止,解决此任务的最强大模型依赖于每种模式的独立网络(“two-tower”方法)。
2.内容摘要
本文提出了第一个使用MoE组合的大规模多模式架构
LIMoE。 它同时处理图像和文本,但使用稀疏激活的自然专业专家。 在零样本图像分类方面,LIMoE 的性能优于可比较的密集多模态模型和双塔方法。 最大的 LIMoE 零样本 ImageNet 准确率达到 84.1%,与更昂贵的 state-of-the-art 模型相当。 稀疏性使 LIMoE 能够优雅地扩展规模,并学会处理截然不同的输入,从而解决多面手和专才之间的紧张关系。
LIMoE 架构包含许多“专家”,“Router” 决定将哪些 token(图像或句子的一部分)发送给哪些专家。 经过专家层(灰色)和共享dense layer(棕色)处理后,最终输出层计算图像或文本的单个向量表示。
Sparse Mixture-of-Experts Models
Transformers 将数据表示为向量(或标记)序列。 虽然最初是为文本开发的,但它们可以应用于大多数可表示为标记序列的事物,例如图像、视频和音频。 最近的大规模 MoE 模型在 Transformer 架构中添加了专家层(例如自然语言处理中的 gShard 和 ST-MoE,以及用于视觉任务的 Vision MoE)。
标准 Transformer 由许多“块”组成,每个“块”包含各种不同的层。 其中一层是前馈网络 (FFN)。 对于 LIMoE 和上面引用的作品,这个单个 FFN 被包含许多并行 FFN 的专家层取代,每个 FFN 都是一个专家。 给定要处理的 token 序列,简单的 Router 会学习预测哪些专家应该处理哪些 token 。 每个 token 仅激活少量专家,这意味着虽然模型容量由于拥有如此多的专家而显着增加,但实际的计算成本是通过稀疏使用它们来控制的。 如果只激活一名专家,该模型的成本大致相当于标准Transformer 模型。
LIMoE 正是这样做的,每个示例激活一名专家,从而匹配密集基线的计算成本。 不同的是LIMoE Router 可能会看到图像或文本数据的标记。
当 MoE 模型尝试将所有 token 发送给同一位专家时,会出现一种独特的 failure。 通常,这是通过辅助损失和鼓励平衡专家使用的额外培训目标来解决的。 处理多种模式与稀疏性相互作用会导致现有辅助损失无法解决的新故障。 为了克服这个问题,本文开发了新的辅助损失(更多详细信息见论文)并在训练期间使用 Router 优先级(BPR),这两项创新产生了稳定且高性能的多模态模型。
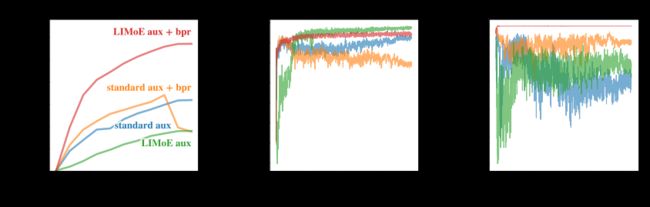
新的辅助损失(LIMoE aux) 和 Router 优先级(BPR) 稳定并提高了整体性能(左)并提高了路由行为的成功率(中和右)。 成功率低意味着路由器不会使用所有可用的专家,并且由于达到了单个专家的容量而丢弃了许多令牌,这通常表明稀疏模型学习得不好。 LIMoE 引入的组合可确保图像和文本的高路由成功率,从而显着提高性能。
Contrastive Learning
在多模态对比学习(Contrastive Learning)中,模型是根据成对的图像文本数据(例如照片及其标题)进行训练的。 通常,图像模型提取图像的表示,不同的文本模型提取文本的表示。 对比学习目标鼓励图像和文本表示对于相同的图像-文本对接近,而对于不同对的内容则远离。 这种具有对齐表示的模型可以适应新任务,无需额外的训练数据(“零样本”),例如,如果图像的表示比单词更接近单词“dog”的表示,则图像将被分类为狗 “猫”。 这个想法可以扩展到数千个类别,被称为零样本图像分类。
CLIP 和 ALIGN(都是双塔模型)扩展了这个过程,在流行的 ImageNet 数据集上实现了 76.2% 和 76.4% 的零样本分类精度。 本文研究计算图像和文本表示的单塔模型,发现这会降低 dense 模型的性能,可能是由于负面干扰或容量不足。 然而,计算匹配的 LIMoE 不仅比单塔密集模型有所改进,而且还优于双塔密集模型。 本文使用与 CLIP 类似的训练方案训练了一系列模型。 我们的密集 L/16 模型实现了 73.5% 的零射击精度,而 LIMoE-L/16 达到了 78.6%,甚至优于 CLIP 更昂贵的两塔 L/14 模型 (76.2%)。 如下所示,与同等成本的密集模型相比,LIMoE 对稀疏性的使用提供了显着的性能提升。
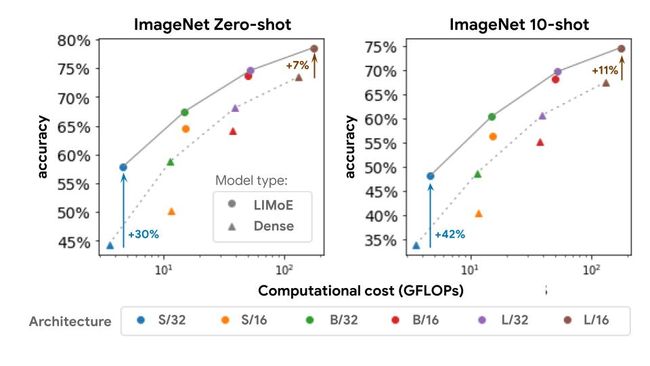 对于给定的计算成本(x 轴),
对于给定的计算成本(x 轴),LIMoE 模型(圆圈、实线)明显优于其密集基线(三角形、虚线)。 该架构指示底层Transformer的大小,从左 (S/32) 到右 (L/16) 增加。 S(小)、B(基本)和 L(大)指的是模型比例。 该数字指的是补丁大小,较小的补丁意味着较大的架构。
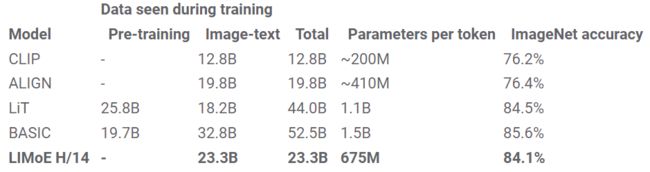
LiT 和 BASIC 将 dense two-tower model 的零样本精度分别提高到了 84.5% 和 85.6%。 除了缩放之外,这些方法还利用了专门的预训练方法,重新利用了已经具有极高质量的图像模型。 LIMoE-H/14 没有受益于任何预训练或特定于模态的组件,但仍然从头开始实现了可比的 84.1% 零样本精度训练。 这些模型的规模比较也很有趣:LiT 和 BASIC 分别是 2.1B 和 3B 参数模型。 LIMoE-H/14 总共有 5.6B 个参数,但通过稀疏性,每个 token 仅应用 675M 个参数,使其更加轻量级。
Experiment Analysis
LIMoE 的动机是稀疏条件计算使通用多模态模型仍然能够发展擅长理解每种模态所需的专业化。 本文分析了 LIMoE 的专家层并发现了一些有趣的现象。
-
模式专门化专家的出现。在实验的训练设置中,图像标记比文本标记多得多,因此所有专家都倾向于至少处理一些图像,但有些专家要么主要处理图像,要么主要处理文本,或两者兼而有之。
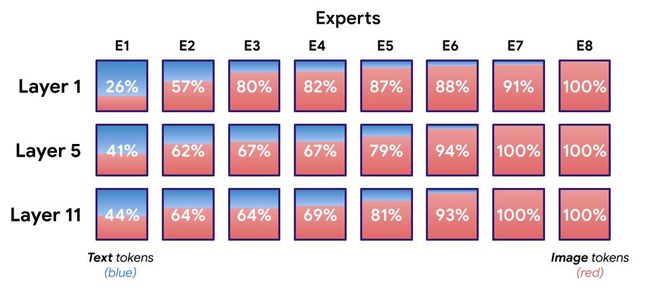 上图展示了
上图展示了 LIMoE八位专家的分配; 百分比表示专家处理的图像标记的数量。 有一到两名明显专门研究文本的专家(主要由蓝色专家表示),通常有两到四名图像专家(主要是红色),其余的则处于中间位置。 -
图像专家之间也存在一些清晰的定性模式。 例如,在大多数 LIMoE 模型中,都有一位专家处理所有包含文本的图像块。
在上面的示例中,有专家处理动物和绿色植物,也有专家处理人类双手。LIMoE为每个token选择一位专家。 在这里展示了 LIMoE-H/14 某一层上哪些图像token被发送给哪些专家。 尽管没有接受过这方面的培训,但能观察到专门研究植物或轮子等特定主题的语义专家的出现。
3.文章总结
处理许多任务的多模式模型是一条很有前途的前进道路,成功的关键因素有两个:1.规模;2.在利用协同效应的同时避免不同任务和模式之间干扰的能力。 稀疏条件计算是实现这两点的绝佳方法。 它支持高性能、高效的多面手模型,同时还具有出色完成单个任务所需的专业化能力和灵活性,正如 LIMoE 以更少的计算量实现的可靠性能所证明的那样。