hive企业级调优策略之分组聚合优化
测试用表准备
hive企业级调优策略测试数据
(阿里网盘下载链接):https://www.alipan.com/s/xsqK6971Mrs
订单表(2000w条数据)
表结构
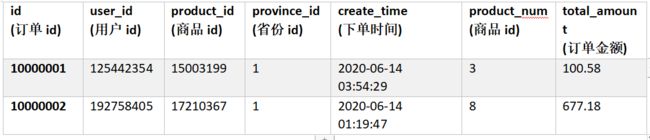
建表语句
drop table if exists order_detail;
create table order_detail(
id string comment '订单id',
user_id string comment '用户id',
product_id string comment '商品id',
province_id string comment '省份id',
create_time string comment '下单时间',
product_num int comment '商品件数',
total_amount decimal(16, 2) comment '下单金额'
)
comment '订单表'
partitioned by (dt string)
row format delimited fields terminated by '\t'
数据装载
将order_detail.txt文件上传到HDFS,并执行以下导入语句。
注:文件较大,请耐心等待。
load data inpath 'hdfs://flinkv1:8020/input/order_detail.txt' overwrite into table order_detail partition(dt='2020-06-14');
支付表(600w条数据)
表结构

建表语句
drop table if exists payment_detail;
create table payment_detail(
id string comment '支付id',
order_detail_id string comment '订单明细id',
user_id string comment '用户id',
payment_time string comment '支付时间',
total_amount decimal(16, 2) comment '支付金额'
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
数据装载
将payment_detail.txt文件上传HDFS,并执行以下导入语句。
注:文件较大,请耐心等待。
load data inpath 'hdfs://flinkv1:8020/input/payment_detail.txt' overwrite into table payment_detail partition(dt='2020-06-14');
商品信息表(100w条数据)
表结构

建表语句
drop table if exists product_info;
create table product_info(
id string comment '商品id',
product_name string comment '商品名称',
price decimal(16, 2) comment '价格',
category_id string comment '分类id'
)
row format delimited fields terminated by '\t';
数据装载
将product_info.txt文件上传到HDFS,并执行以下导入语句。
load data local inpath '/opt/module/hive/datas/product_info.txt' overwrite into table product_info;
省份信息表(34条数据)
表结构

建表语句
drop table if exists province_info;
create table province_info(
id string comment '省份id',
province_name string comment '省份名称'
)
row format delimited fields terminated by '\t';
数据装载
将province_info.txt文件上传到HDFS,并执行以下导入语句。
load data inpath 'hdfs://flinkv1:8020/input/province_info.txt' overwrite into table province_info;
优化说明
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
map-side 聚合相关的参数如下:
启用map-side聚合
set hive.map.aggr=true;
用于检测源表数据是否适合进行map-side聚合,根据设置的比例系数进行检测,如果设置为1将不在进行检测,所有数据都进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,例如根据主键ID进行分组,那么map端即时聚合也没有作用,反而多此一举浪费资源,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
–用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
如果统计数据远大于分组值(例如100000条数据,计算每个省份的条数,省份可以确认34个,那么统计条数远大于分组值)我们可以直接把检测比例系数设置为1,检测源表数据设置为0;免去检测直接进行map-side聚合。
set hive.map.aggr.hash.min.reduction=1;
set hive.groupby.mapaggr.checkinterval=1;
map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。(默认不需要调整,出现问题在进行调整)
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
优化案例
(1)示例SQL
select
province_id,
count(*)
from order_detail
group by province_id;
关闭map-side优化:
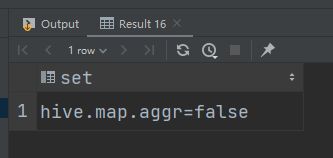

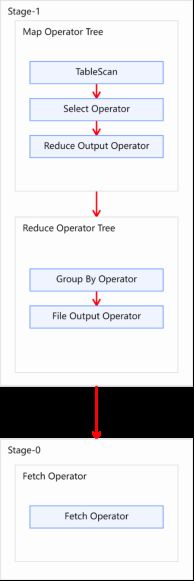
(2)优化前
未经优化的分组聚合,执行计划如下图所示:
(3)优化思路
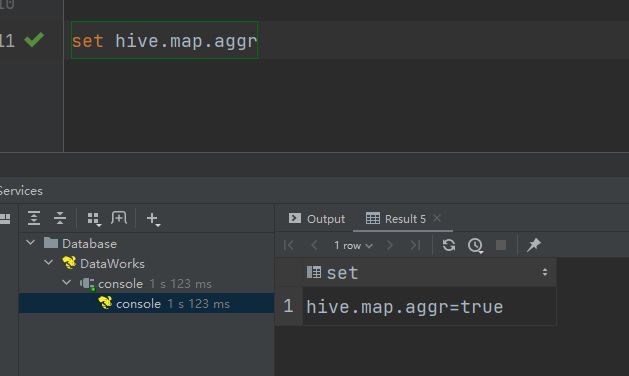
可以考虑开启map-side聚合,配置以下参数:
–启用map-side聚合,默认是true
set hive.map.aggr=true;
用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=1;
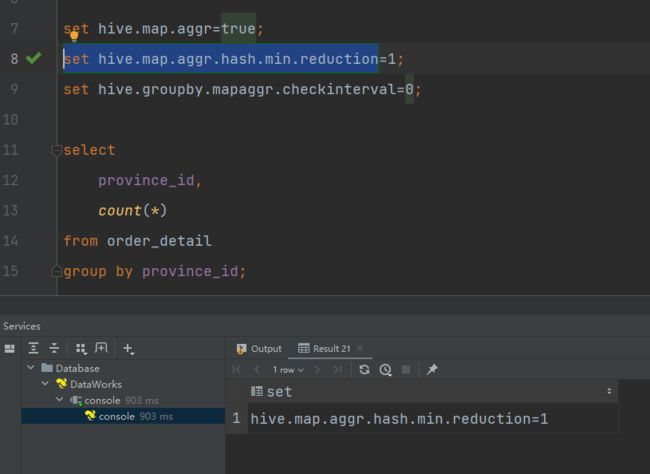
–用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=0;
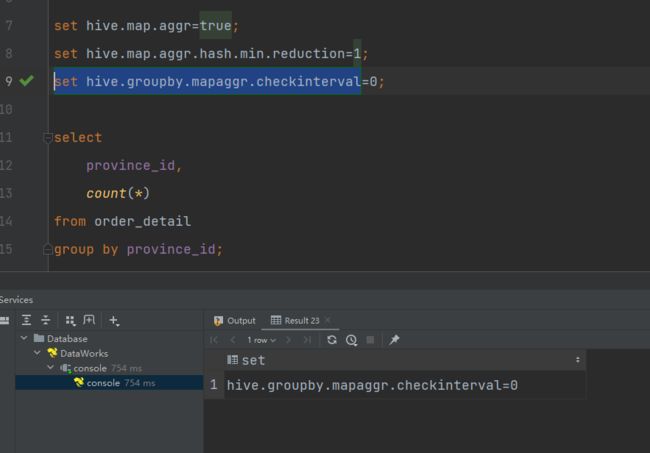
–map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
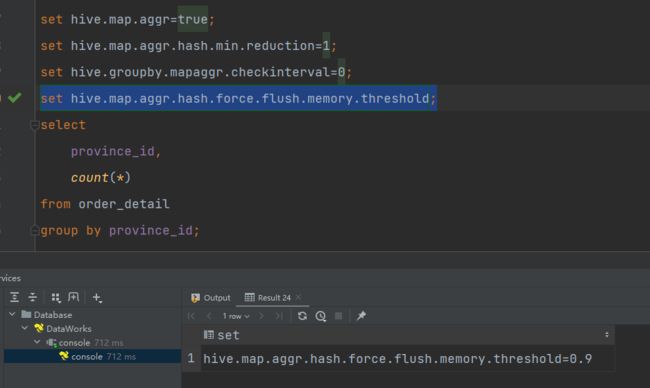
再次执行,耗时显而易见减少。

优化后的执行计划如图所示:
