JMUer-网络新技术课程期末考试复习整理
✏️write in front✏️
个人主页:陈丹宇jmu
欢迎各位→点赞 + 收藏⭐️ + 留言
联系作者by QQ:813942269
致亲爱的读者:很高兴你能看到我的文章,希望我的文章可以帮助到你,祝万事顺意️
✉️少年不惧岁月长,彼方尚有荣光在
⭐题型分布
| 题型 | 分值 | 备注 |
|---|---|---|
| 单选 | 10 x 1 | |
| 多选 | 10 x 3 | 少选,错选不得分 |
| 填空 | 10 x 1 | 五小题,每小题两个空 |
| 简答 | 10 | 开放性回答 |
| 计算题 | 2 x 15 | 基于原题,会变动数值 |
⭐知识点
空域彩色图像格式(BMP等)
每个像素(pixel)采用三个字节(3*8bit)表示红绿蓝三个分量。因此图像有三个通道。
每个字节表示该像素在该颜色分量上的强度,从(0~255)
BMP
BMP(Bitmap)是一种常见的空域彩色图像格式,也被称为Windows位图格式。它是一种无损的图像文件格式,支持存储真彩色图像以及其他颜色深度的图像。
Tip:BMP的基本认识
BMP格式的图像采用像素阵列来表示图像,每个像素由红、绿、蓝三种颜色通道的值组成。BMP图像可以存储24位真彩色图像,每个像素使用3字节(8位红色值、8位绿色值和8位蓝色值)表示。
此外,BMP还支持其他的颜色深度,如8位灰度图像和1位黑白图像等。
BMP格式的图像文件相对较大,因为它没有进行图像压缩。这使得BMP适用于需要保留图像质量和细节的场景,但同时也导致了占用更多的存储空间。
尽管BMP格式广泛支持,但在某些应用中可能会使用其他更高效的图像格式,如JPEG、PNG等,这些格式可以提供更好的压缩比和更小的文件大小。

灰度图像
-
如果是灰度图像,只需要一个通道表示其亮度就可以
-
如果用三通道表示,灰度图像的三个通道数据一样
Tip:灰度图像的基本认识
灰度图像使用8位(256级)灰度级别来表示亮度值,从0代表最暗的黑色,到255代表最亮的白色。通过去除彩色信息,灰度图像更侧重于显示图像的亮度与阴影变化,使得人们更容易观察和分析图像的细节。
-
如果用三通道表示,灰度图像的三个通道数据一样
这句话的意思是,如果将灰度图像转换为彩色图像,用三个颜色通道表示时,这三个通道中的数据值都会相同,即红、绿、蓝三个通道的数值都相等。
因为灰度图像只包含一个颜色通道,代表每个像素的亮度值,所以在转换为彩色图像时,需要将这个亮度值复制到三个通道中去,使得红、绿、蓝三个通道的数值相同,这样才能保持图像的灰度信息不变。因此,如果用三通道表示灰度图像,它们的数值必须相同,否则就失去了灰度图像的意义。
灰度图像像素灰度直方图
-
一般的灰度图像像素值为0~255
-
灰度图像像素灰度直方图是统计各个像素值在图像中出现的频率
-
该直方图有256个数据
颜色的表示方式
-
RGB
RGB(红、绿、蓝)模式:是一种基于三原色的表示方式,将颜色分解为红、绿、蓝三个通道的数值,每个通道的取值范围是0-255。通过调节三个通道的数值可以得到各种颜色。
-
YCbCr空间存储
维度:亮度,色调,饱和度。
Tip:YCbCr的基本认识
在YCbCr空间中,亮度(Y)表示图像的明亮程度,而色差蓝(Cb)和色差红(Cr)表示图像的颜色信息。
-
YCbCr典型应用:JPEG图像
JPEG图像是有损压缩格式的图像,采用YCbCr色彩空间存储,利用分块的2维DCT变换压缩,分块大小为8x8
中英互译(一道填空题)
基于内容的图像检索--CBIR
基于内容的图像检索英文为:CBIR(Content-Based Image Retrieval)
CBIR(Content-Based Image Retrieval)的中文为:基于内容的图像检索
CBIR
-
输入的图像数据-->query
-
检索结果为多个图像数据
-
尽可能把与检索条件较为相关的数据排在前面
Tip:CBIR系统的基本认识
CBIR系统的基本流程包括以下步骤:
特征提取:从图像中提取出能够描述图像内容的特征,常见的特征包括颜色、纹理、形状等。
特征表示:将提取到的特征表示为向量或特征描述符,用于后续的相似度计算。
相似度计算:根据不同的相似度度量方法(如欧氏距离、余弦相似度等),计算查询图像与数据库中图像之间的相似度。
检索与排序:根据相似度进行检索,并按照相似度大小对图像进行排序,将最相似的图像排在前面。
召回率和精度
如果对于一个检索图像X,图像数据库中共有N张图像,库中有n1张图像与X有关,而返回的K张结果,其中有n2张为正确结果。

| 召回率 | 找得全 |
| 精度 | 找得准 |
| 召回率和精度是此消彼长的矛盾关系 | |
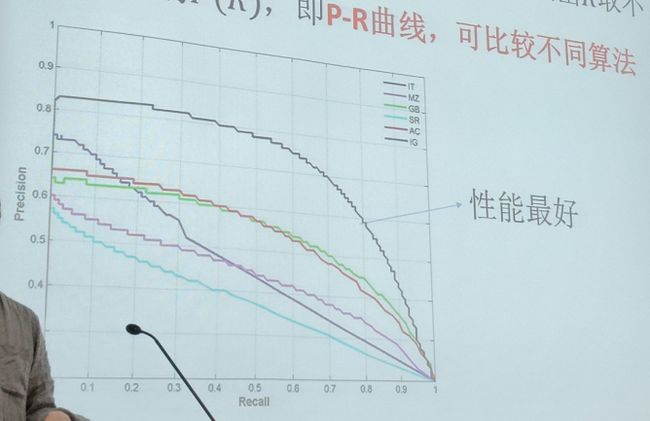
P(R)曲线
对于某个检索系统的某次检索,可以把precision视为recall的函数: P(R),画出R取不同值下的P(R),即P-R曲线,可比较不同算法
MAP指标
MAP指标:综合反应不同系统的P-R曲线的优良程度
对于第i次检索得到的P-R曲线pi(R),计算其曲线下覆盖的面积:
![]()
- 多次检索得到的AvePi的平均值即为MAP指标:
![]()
一般性的图像检索方法(非深度方法)
包含四个步骤:
-
提取图像局部描述子
-
对局部描述子编码
-
统计编码的直方图
-
检索相近样本
图像的局部描述子
-
图像的局部描述子一般具有检测子和描述子
-
对于图像局部内容的旋转、缩放、平移、仿射等具有一定的鲁棒性。
-
常用的局部描述子SIFT (Scale-Invariant Feature Transform,尺度不变特征变换),采用高斯差分金字塔图像描述方法,在图像局部范围内提取描述信息, 共128维
词袋模型
-
BOW称为“词袋模型”, 词袋模型忽略了图像局部信息相互之间的空间位置信息
-
词袋模型有一个“字典”,用于将局部描述子编码
-
字典往往是通过利用图像数据库的图像数据聚类学习得到
K-means聚类方法
K-means聚类方法根据样本点到各个聚类中心的距离来确定样本点的聚类归属。
Tip:K-means聚类方法的基本认识
K-means是一种常见的聚类方法,其基本思想是将数据分为K个簇,每个簇的中心点为该簇内所有点的平均值,然后不断迭代调整各个簇的中心点,直到簇中心点不再变化或达到预设的迭代次数。具体步骤如下:
随机选择K个中心点(可以从数据集中随机选择K个点作为中心点),将所有数据点分配到距离最近的中心点所在的簇中。
计算每个簇内所有数据点的平均值,将这些平均值作为新的中心点。
重复步骤1和2,直到中心点不再发生变化或达到预设的迭代次数。
K-means聚类的优点是算法简单,易于理解和实现;缺点是对初值比较敏感,可能会收敛到局部最优解,在处理噪声和异常数据时表现不佳。同时,K值的选择也需要一定的经验和技巧。
近似聚类方法:
-
层级聚类方法(HKM,hierarchical K-means)
-
AKM,使用KD树
Tip:近似K均值-AKM的基本认识
近似K均值(Approximate K-Means,AKM)是一种用于大规模数据集的聚类算法。它是对传统K均值算法的一种改进,旨在解决处理大规模数据时的效率和存储问题。
AKM算法的核心思想是通过近似的方式来计算K均值聚类,以减少计算和存储成本。它采用了一些近似技术,例如局部敏感哈希(Locality Sensitive Hashing,LSH),用来加速距离计算和聚类过程。这样可以在保持较高聚类质量的情况下显著减少计算成本,适用于处理大规模高维数据的情形。
在AKM中,数据点被分配到近似的簇中,而非精确的簇,从而在一定程度上牺牲了聚类的准确性以换取更高的效率。这使得AKM成为处理大规模数据集时的一个有吸引力的选择。
总的来说,近似K均值(AKM)算法是针对大规模数据集的K均值聚类问题提出的一种近似解决方案,它通过权衡计算成本和聚类质量,在大数据环境下取得了良好的应用效果。
Soft voting与hard voting
Soft voting与hard voting的区别点
-
Soft voting 对直方图每个维度都投票,
hard voting 只对其中的一个维度投票
-
Soft voting 对直方图投票值为实数值,与描述子到word的距离有关,
hard voting 每个描述子投票值永远为1
Soft voting与hard voting的相同点
-
都需要先生成包含word的vocabulay
-
最终生成的直方图维度都等于vocabulary中word的数量
Term Frequency(TF)
1, 单词在文档 J 中出现的频率
![]()
2, 一个文档语料库D,根据D计算单词 i 的IDF值定义为:
![]()
图像检索中的TF-IDF模型可能会有Burstness问题
近似最近邻方法
近似最近邻方法具有:
-
KD树方法
-
局部敏感哈希方法(LSH)方法
-
谱哈希
-
迭代量化哈希方法
后三者都是哈希方法,其中:
- 局部敏感哈希方法(LSH)方法不需要学习训练,
- 而谱哈希和迭代量化哈希方法需要。
KD树的节点分裂规则
-
每次使用当前分支对应的数据的方差最大的维度作为分支条件。
-
数据的每个维度可以重复在多个分支节点使用
-
每个分支节点把数据其所在的空间进一步划分为两个部分
LSH
Tip:LSH 的基本认识
LSH(Locality Sensitive Hashing)是一种用于高维数据的近似最近邻搜索技术。它利用哈希函数将相邻的数据点映射到相同的桶中,从而使得在桶中查询操作可以在常数时间内完成。
常规Hashing尽可能减少碰撞,而LSH使得距离相近的数据尽可能哈希值一样或相近。
LSH编码尽可能使得距离近的样本哈希值一样,但衡量样本距离不同的定义下,LSH编码函数的形式不尽相同。
常见的距离有Jaccob距离,汉明距离,余弦距离,L2范数距离(俗称欧氏距离)
倒排索引
倒排索引:建立关键词到文件ID的映射,由检索词找到对应的文件列表

卷积神经网络
卷积神经网络可能包含的层的类型具有: 卷积层、激活函数层、池化层、全连接层
其中,卷积层可以提取图像局部信息激活函数层使得网络具有非线性能力
卷积神经网络采用损失函数作为指导进行训练, 采用随机梯度下降法搜索最小化损失函数的参数,每次随机梯度下降的迭代只使用部分祥本参与训练
用于训练分类的春积神经网络的机失函数一般是交叉熵

Faster RCNN
Faster RCNN
基于Faster RCNN的检索方法根据图像全局信息(image-wise pooling)和物体局部区域信息(Region-wise pooling)进行检索
-
Faster RCNN具有生成proposal的RPN网络分支,以及预测proposal物体类别和位置的网络分支,两者共享卷积层。
-
Faster RCNN使用ROI pooling
-
RPN网络输出三种尺度,三种比例共9种
-
RPN往往会产生很多很多具有大幅度重叠的proposal,这时候要用非极大值抑制(NMS)
Triple loss 损失函数
Tip:Triple Loss的基本认识
Triple Loss是深度学习中的一种损失函数,主要用于训练差异较小的样本,如人脸、细粒度分类等。在训练目标是得到样本的embedding任务中,Triple Loss也经常使用,比如文本、图片的embedding。
Triple Loss三元组
Triple Loss的原理是:损失函数公式输入是一个三元组,包括:
- a 锚(Anchor)示例
- p 正(Positive)示例
- n 负(Negative)示例
通过优化锚示例与正示例的距离小于锚示例与负示例的距离,实现样本之间的相似性计算。其中,a代表锚示例,p代表与a是同一类别的样本,n代表与a是不同类别的样本,
margin是一个大于0的常数。最终的优化目标是拉近a和p的距离,拉远a和n的距离。

LSB隐写术
LSB隐写术概述
LSB图像隐写
LSB全称为Least Significant Bit(最低有效位), LSB替换隐写方法将图像数据的最低比特位替换为需要嵌入的信息。
Tip:LSB隐写术的基本认识
在LSB隐写技术中,将隐藏信息的二进制数插入到每个像素的最低有效位中,这样就可以在不影响图像的正常显示的情况下将隐藏信息嵌入到图像中。
LSB隐写术的特点
LSB隐写术:
特点:容量大,抗检测性好,无鲁棒性或鲁棒性很弱。
用途:用于隐蔽通信,隐私保护等。
Tip:鲁棒性的基本认识
鲁棒是Robust的音译,也就是健壮和强壮的意思。它是在异常和危险情况下系统生存的能力。比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。
Tip:隐写术不具备鲁棒性的原因
隐写术是一种将消息隐藏在其他看似无关的信息中,以保证消息的机密性和隐私的技术。与加密技术不同,隐写术并不改变消息本身,而是将消息嵌入到其他媒介中,例如图像、音频、视频或文本等。然而,隐写术并不具备鲁棒性,原因如下:
隐写术容易被检测和破解。虽然隐写术可以将消息隐藏在其他信息中,但是这种技术并不是完美的。有些隐写术可能会改变媒介的统计特征、频率分布或结构,从而引起注意。此外,一些先进的隐写术检测方法,例如使用机器学习算法或深度神经网络,可以很容易地检测出隐写信息。
隐写术对数据的修改不具备鲁棒性。由于隐写术需要将消息嵌入到其他媒介中,因此会对媒介进行修改或调整。这些修改可能会破坏媒介的完整性和准确性,导致数据损坏或无法还原。此外,对于某些敏感数据,例如医疗影像或法律文件,即使微小的修改也可能会产生严重的后果。
隐写术不具备抵抗攻击和意外损坏的能力。如果媒介遭受攻击或意外损坏,隐写信息也可能无法恢复或被破坏。此外,某些攻击手段,例如裁剪、压缩或转码等,可能会导致隐写信息丢失或无法提取。
因此,隐写术作为一种保护数据隐私和机密性的技术,应该谨慎使用,并与其他安全措施结合使用,以提高数据安全和可靠性。
LSB替换的问题
LSB替换的问题是,对像素值(或系数值)为奇数的像素(或系数)修改时只-1,而对偶数值只+1,
因此造成图像像素直方图变形具有较强的规律性(直方图中相邻成对的维度平均化)。
解决办法
LSB匹配方法需要修改时随机选择+1和-1,避免了LSB替换的问题
数字水印
数字水印概述
数字水印是一种在数字媒体(如图像、音频、视频)中嵌入隐藏信息的技术,以提供版权保护、身份验证和完整性验证等功能。
数字水印的特点
特点:数字水印:容量较小,易于被检测,具备抗击广泛攻击的鲁棒性,嵌入容量低。
用途:主要用于版权保护,内容完整性认证等。
数字水印的攻击
数字水印可能面临的攻击有:剪切,亮度修改,旋转,中值滤波,放大缩小,加噪声等。
Tip:数字水印基础知识
数字水印是一种在数字媒体(如图像、音频、视频)中嵌入隐藏信息的技术,以提供版权保护、身份验证和完整性验证等功能。相对于隐写术,数字水印具备比较好的鲁棒性,原因如下:
隐蔽性:数字水印通常是以微小的、不可察觉的方式嵌入到媒体中,不会引起人眼或人耳的注意。仅通过观察或听取媒体本身,很难察觉到存在数字水印。
容错性:数字水印在嵌入过程中采用了一定的冗余和错误纠正机制,以提高容错性。即使媒体经过压缩、裁剪、滤波等处理,数字水印仍然能够部分或完全提取出来。
抵抗攻击:数字水印对一些常见的攻击手段具有一定的抵抗能力,例如图像或音频的剪切、缩放、旋转、加噪声、压缩等。即使在受到这些攻击后,数字水印仍然能够被检测和提取出来。
鲁棒性调节:数字水印可以根据应用需求进行鲁棒性调节。通过调整嵌入强度、密度和位置等参数,可以控制数字水印的鲁棒性。在需要更高鲁棒性的场景下,可以选择较强的嵌入参数;而在对鲁棒性要求较低的场景下,可以选择较弱的嵌入参数。
可提取性:数字水印只有在合法的解码算法下才能被提取出来,其他未授权的用户无法获得隐藏的信息。这样可以保证数字水印的安全性和机密性。
尽管数字水印具备较好的鲁棒性,但仍然存在一些限制和挑战。例如,对于某些复杂的攻击手段或恶意修改,数字水印可能会受到破坏或无法提取。因此,在实际应用中,仍需要综合考虑鲁棒性、安全性和可靠性等因素,并采取适当的安全措施来保护数字水印的有效性。
数字水印方法
-
量化索引调制(QIM) :
使用不同量化器对数据量化以使得量化后的数据落在 不同的量化区间,从而嵌入信息
-
扩频(spread specrum):
调制不同的随机串嵌入到多个频带数据中。
数字指纹
数字指纹技术基本原理:
通过数字水印技术,在数字文件的每份拷贝中隐式嵌入唯一的标识信息 (被称为数字指纹),使得不同用户获取到的数据拷贝都互不相同。
数字指纹的要求与特性
●唯一性(uniqueness)
●隐蔽性(Invisibilility)
●稳健性(Robustness)
●合谋容忍性(Collusion Tolerance)
⭐简答题
简述信息隐藏技术在隐私保护,版权保护,隐蔽通信等方面的应用前景(开放式问题)
计算题一

计算题二

欢迎各位→点赞 + 收藏⭐️ + 留言
写给读者:很高兴你能看到我的文章,希望我的文章可以帮助到你,祝万事顺意️